Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
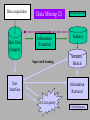
Data mining Satellite images indexation Feature Selection Marine Campedel 5 février 2004 Data Mining (1) • “Fouille de données”, ECD, KDD,… • Automatic process giving access to raw data in the context of a given application ; • Necessity because of databases increasing sizes -> find the “relevant” information ; • Indexation : automatic process that associates a set of labels to a raw data. 2 Data acquisition Raw Data (images) Data Mining (2) Information Extraction Supervised learning User Interface Off-line process Features Semantic Models Information Retrieval User query On-line process 3 Data Mining (3) Information Extraction – From raw data and a priori knowledge (unsupervised) – Between raw data and application-based knowledge (supervised) Information Retrieval – Goal : get relevant examples (raw images) corresponding to any user query (‘find frozen woods area’) in a specified application (‘satellite image retrieval’) 4 Data acquisition Raw Data (images) Features Selection (1) Any a priori knowledge from data type or final application ? Information Extraction Features • Computation cost and storage capacity reduce the number of features (dimension) ; • Reduce redundancy while maintaining noise robustness and discriminative power ; Feature selection algorithm is needed 5 Features Selection (2) Domain a priori knowledge ? Compute all a priori features (colour, texture, shape features,…) Raw Data (images) Predefined properties ? Construct new features (PCA, ICA,…) Feature Selection Relevance definition ? Relevant features 6 Features Selection (3) Unsupervised • Quantization • Define selection criterion from a priori knowledge (‘filter’ approach) • Typical use of correlation coeffs, mutual information,… and thresholding • Traditional drawback : cannot evaluate set of features Supervised • Define selection criterion according to the final application (‘wrapper’ or ‘embedded’ approach) • Typical use of labelled databases and classifiers • Traditional drawback : computation cost 7 Supervised Features Selection • Inputs : labelled database + classification task + exhaustive feature library • Goal : select the features set that achieves the best classification score • Pbs : selection of the inputs (database, classifier type, feature library are chosen from a priori knowledge) 8 Constraints • The (hand-)labelled database size is limited by the acquisition process (hundreds to thousands ?) • The features library size can be huge (hundreds ?) The classifier must be able to train from a limited number of data in high dimensional space, ensuring strong generalization property 9 SVM choice • Support Vector Machine • Parametric classifier; • Support vectors : examples that define the limits of each class; • Designed to be robust to outliers; • Tractable with high dimensional data; • Lots of recent literature and tools on the web (matlab: SPIDER, C-C++: svmlib, svmlight, Java: WEKA). 10 SVM principle (1/4) • 2 classes linear SVM without error Labelled training patterns ( y1 , x1 )( y L , x L ), with yi 1,1 Linearly separable if there exists w (weights) and b (bias) such that y (w.x b) 1, i 1,, L i i • The optimal hyperplane separates the data with the maximal margin (determines the direction w/|w| where the distance between the projections of two different classes data is maximal) 11 SVM principle (2/4) w 0 .x b0 0 hyperplan w.x w.x 2 distance min m ax x: y 1 w x: y 1 w w0 • Support vectors • SVM problem : min w w ,b yi (w.x i b) 1 2 2 subject to yi ( w.x i b) 1 12 SVM principle (3/4) • Dual problem L 1 L max i i j yi y j ( x i .x j ) i 2 i , j 1 i 1 L subject to : i 1 • Kernel i yi 0, i 0 k ( xi , x j ) ( xi ).( x j ) 13 SVM principle (4/4) • Soft margin L q min w 2 C i w ,b i 1 subject to yi ( w.x i b) 1 i , i 0 2 • Multi-classes : 1-vs-all and MC-SVM 14 Selection algorithms using SVM • RFE (Recursive Feature Elimination) [Guyon, 2002] – Iteratively eliminates features corresponding to small weights until the desired number of features is reached. • Minimize L0 norm of feature weights (minimize the number of non-zero weights) [Weston, 2003] – Iterative process using linear SVM ; – Update data by multiplying by the estimated weights. 15 Proposed experiment • Database : synthetic or Brodatz (texture images) or satellite image database • Feature library : using Gabor, orthogonal wavelets, co-occurrence matrices, basic local stats,…with several neighbourhoods sizes (scales) • Classifier : SVM • Goal : compare performance of different selection algorithms (supervised + unsupervised ones) • Robustness to database modification ? to classifier parameter modification ? 16 Spider example : 2-classes and 2-relevant dimensions synthetic linear problem The 2 first dimensions are relevant (uniform distribution) The next 6 features are noisy versions of the two first dimensions The 42 other one are independent uniformly distributed variables (noise) 400 examples, 50 dimensions Evaluation using crossvalidation (train on 80% of the data, test on 20%, 5 attempts) Score = classification error rate 17 Spider example Number of Features Fisher Fisher+SVM L0 RFE 2 0.79 ± 0.05 0.27 ± 0.08 0.00 ± 0.00 0.00 ± 0.00 5 0.82 ± 0.03 0.19 ± 0.03 0.02 ± 0.01 0.01 ± 0.01 10 0.95 ± 0.02 0.05 ± 0.02 0.03 ± 0.01 0.03 ± 0.01 all 0.95 ± 0.02 0.09 ± 0.02 0.09 ± 0.02 0.09 ± 0.02 • Results confirm the selection process gain • Correlation-based selection algorithm performs poorly compared to the proposed ‘wrapper’ methods 18 Conclusion and what next ? • Subject : feature selection algorithms Determine an automatic procedure for selecting relevant features in the context of satellite image indexing Applicable to any data indexing ? (Is the datatype a-priori knowledge concentrated in the feature library design ?) • Experiment in progress… 19 Bibliography • [Elisseeff, 2003] “Technical documentation of the multi-class SVM”,2003. • [Guyon,2002] “Gene selection for cancer classification using support vector machines”, I.Guyon, J.Weston, S.Barnhill and V.Vapnik Machine Learning 46(1-3) 389-422, 2002. • [Guyon,2003] “An introduction to Variable and Feature selection”, I.Guyon, A.Elisseeff, JMLR 3, 1157-1182, 2003. • [Schoelkopf and Smola,2002] “Learning with Kernels-Support Vector Machines, Regularization, Optimization and Beyond”, B.Schoelkopf and A.J.Smola, MIT press, 2002. • [Weston,2003] “Use of the Zero-Norm with Linear Models and Kernel Methods”, Weston, Elisseff, Schoelkopf and Tipping, JMLR 3, 14391461,2003. 20