Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
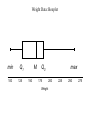
Class Two Before Class Two Chapter 8: 34, 36, 38, 44, 46 Chapter 9: 28, 48 Chapter 10: 32, 36 Read Chapters 1 & 2 For Class Three: Chapter 1: 24, 30, 32, 36, 44 Chapter 2: 26, 28, 38, 42, 50 Complete Quiz #1 Read Chapters 3, 4 & 5 Objectives for Class Two • Identify categorical and quantitative variables. • Represent data graphically using: – bar charts – pie charts – histograms – stem plots – box plots – time plots • Describe the distribution of a variable in terms of overall pattern and identify potential exceptions or outliers • Compute standard measures of the center and spread of a distribution and interpret their values. Answering the question: Will? Making sense of what you’ve got. • Now that you have designed and completed your study or experiment you must make sense of all of the data that you have collected before it can be interpreted. This process is called: Exploratory Data Analysis. • The purpose of this process is to organize the data to determine what statistical tools we may use to make predictions or decisions about the population the data was collected from and to give us some basic insights into the content of the data. • Organizing Data – – – – Group and count each variable Look for relationships between/among variables or groups Create simple graphs Create numerical summaries Answering the question: Will? continued • Remember the two types of variables are: – categorical (words) – quantitative (numbers) • Distribution: describes the value of a variable and the frequency with which it appeared in the data set. – For categorical variables the value of the variable will be the specific word(s) you use to describe the individuals and the frequency is a count of how many individuals are described by the word. – For quantitative variables the value of the variable will be the number(s) you collected on an individual and the frequency is a count of how many individuals are described by the number. – Sometimes it is necessary with quantitative variables to make closely related groups of numerical values and then your frequency is a count of how many individuals have a number in your group. Answering the question: Will? Working with categorical variables. • identify/calculate the distribution of each categorical variable – count: the number of individuals in that category – percent: the ratio of the number of individuals in that category to the total of all individuals in all the categories – round-off error occurs when each category is rounded separately from the total of all categories • select a graphical display that will convey the importance of the relationships – pie charts give a good visual comparison of percentages but are poor ways to communicate counts – bar graphs provide a good visual comparison of counts – make sure that all diagrams are clearly labeled so that the viewer easily understands the information and relationships being displayed – make sure to include an other category for pie charts if the categories do not total to 100% Data Table Year Count Percent Freshman 18 41.9% Sophomore 10 23.3% Junior 6 14.0% Senior 9 20.9% Total 43 100.1% Pie Chart Senior 20.9% Freshman 41.9% Junior 14.0% Sophomore 23.3% 45.0% 41.9% Bar Graph 40.0% 35.0% Percent 30.0% 23.3% 25.0% 20.9% 20.0% 14.0% 15.0% 10.0% 5.0% 0.0% Freshman Sophomore Junior Year in School Senior Answering the question: Will? Working with quantitative variables • Display distribution of quantitative variables with either a histogram, a stem plot or a time plot. – A histogram is like a bar graph only instead of the x-axis being labeled with categories it is labeled with groups of closely related values. It is used to diagram cross-sectional data from a fixed moment in time. – A stem plot is a chart that saves time and space by writing numbers with the same first digits, called stems, in rows followed by a list of the last digits, called leaves. • Often it is easy to convert a stem plot into a histogram by using the stems as your groupings. – A time plot allows the data to be tracked over time and reveal trends that would not be evident if only a single moment were analyzed. Creating a Histogram • Choose classes: divide the range of the data into classes of equal width – as the eye scans the histogram it responds to the area of each rectangle as a function of its height since all of the bases are of equal size. – too few classes will give a “skyscraper” effect – too many will give a “pancake” effect • Count the individuals in each class • Draw the histogram: note Microsoft Excel® will label the classes on the x-axis differently than the histograms in your text. Excel will center the bar over the value of your class, grouping individuals based on whether they are below or equal to the class value but greater than the next lower class. Weight Data 192 152 135 110 128 180 260 170 165 150 110 120 185 165 212 119 165 210 186 100 195 170 120 185 175 203 185 123 139 106 180 130 155 220 140 157 150 172 175 133 170 130 101 180 187 148 106 180 127 124 215 125 194 Weight Data: Frequency Table Weight Group 100 - <120 120 - <140 140 - <160 160 - <180 180 - <200 200 - <220 220 - <240 240 - <260 260 - <280 Count 7 12 7 8 12 4 1 0 1 Weight Data: Histogram 14 Number of students 12 10 8 6 Frequency 4 2 0 100 120 140 160 180 200 Weight 220 240 260 280 * Left endpoint is included in the group, right endpoint is not. Interpreting Histograms • Look for the overall pattern as well as any striking deviations from the pattern. • Overall pattern is described using words for: – shape: give the number of peaks and whether it is skewed right (lots of low bars on the right), skewed left (lots of low bars on the left), symmetric (roughly bell shaped), or has clusters of bars each with their own shape, center and spread. – center: midpoint (middle) of the values, the category or group where half of the observations are below and half are above – spread: give the smallest and largest values usually excluding outliers • Deviations are known as outliers because they lie outside the overall pattern. Shape: Symmetric Bell-Shaped Shape: Symmetric Mound-Shaped Shape: Symmetric Uniform Shape: Asymmetric Skewed to the Left Shape: Asymmetric Skewed to the Right Creating a Stem Plot • Separate each observation into a stem, consisting of all but the final (rightmost) digit, and a leaf, the final digit. Stems may have as many digits as needed, but each leaf contains only a single digit. • Write the stems in a vertical column with the smallest at the top, and draw a vertical line at the right of this column. Do not skip and stem values even if there is no data with that particular stem. • Write each leaf in a row to the right of its stem, in increasing order out from the stem. If there are no leaves for a stem leave the area next to it blank. • Special Circumstances: – rounding: if data have more than three digits sometimes it is better to round numbers to three significant digits before creating the stem plot – split stems: each stem can be split into two with leaves 0-4 appearing on the first stem and leaves 5-9 appearing on the second stem – back-to-back stems are helpful when comparing two distributions Weight Data 192 152 135 110 128 180 260 170 165 150 110 120 185 165 212 119 165 210 186 100 195 170 120 185 175 203 185 123 139 106 180 130 155 220 140 157 150 172 175 133 170 130 101 180 187 148 106 180 127 124 215 125 194 Weight Data: Stemplot (Stem & Leaf Plot) Key 20|3 means 203 pounds Stems = 10’s Leaves = 1’s 10 11 12 13 5 14 15 2 16 17 18 19 2 20 21 22 23 24 25 26 192 152 135 Weight Data: Stemplot (Stem & Leaf Plot) Key 20|3 means 203 pounds Stems = 10’s Leaves = 1’s 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 0166 009 0034578 00359 08 00257 555 000255 000055567 245 3 025 0 0 Creating a time plot • Time plots are used for quantitative variables that are measure at regular intervals over time. • Time is always the variable plotted on the x-axis. • Connecting the data points with line segments will often emphasize the trend over time. Class Make-up on First Day (Fall Semesters: 1985-1993) Class Make-up On First Day 70% 60% Percent of Class That Are Freshman 50% 40% 30% 20% 10% 0% 1985 1986 1987 1988 1989 1990 Year of Fall Semester 1991 1992 1993 Average Tuition (Public vs. Private) Numbers as a measure of center • Mean ( x ): an arithmetic average found by finding the sum of all of the data and dividing by the number of data. It is NOT a resistant measure of center, meaning outliers will pull the mean towards themselves; therefore we only use the mean with symmetric data. n 1 x1 x 2 ... x n xi x n i 1 n • Median (M): the midpoint of the data. It is a resistant measure of center, meaning it is effected little by outliers; therefore we use the median with skewed data. – arrange the data in order by size from least to greatest – if n is odd then M is the center of the ordered list or it is (n+1)/2 observations from the beginning of the list – if n is even then M is the mean of the two center positions • Mode: is the most frequent observation Comparisons of Measures of Center • Symmetric Distributions: the mean and the median will be close together. If the distribution is perfectly symmetrical then the mean and the median will have the exact same value. • Skewed Distributions: the mean will be pulled along the tail of the distribution towards any outliers. Basic Measures of Spread • Range: the difference between the maximum and minimum observations (usually outliers are omitted) • Quartiles: mark out the middle half of the data – 1st quartile (Q1) is one-quarter of the way up the list or is larger than 25% of the list – 2nd quartile (M) is the median, half of the way up the list or is larger than 50% of the list – 3rd quartile (Q3) is three-quarters of the way up the list or is larger than 75% of the list • Interquartile Range (IQR): is the difference between the 1st and 3rd quartiles or Q3 - Q1 = IQR Weight Data: Sorted 100 101 106 106 110 110 119 120 120 123 124 125 127 128 130 130 133 135 139 140 148 150 150 152 155 157 165 165 165 170 170 170 172 175 175 180 180 180 180 185 185 185 186 187 192 194 195 203 210 212 215 220 260 10 11 Weight Data: 12 Quartiles first quartile 13 14 15 16 median or second quartile 17 third quartile 18 19 20 21 22 23 24 25 26 0166 009 0034578 00359 08 00257 555 000255 000055567 245 3 025 0 0 Five-Number Summary • • • • • minimum = 100 Q1 = 127.5 M = 165 Q3 = 185 maximum = 260 Interquartile Range (IQR) = Q3 Q1 = 57.5 IQR gives spread of middle 50% of the data Diagramming the Basic Measures of Spread • Five Number Summary: includes the minimum observation, Q1, M, Q3, and the maximum observation • The five number summary is diagrammed using a box plot sometimes also known as a box and whisker plot. – a central box (IQR) spans the quartiles Q1 and Q3 – a line marks the median – lines (whiskers) extend from the box out to the minimum and maximum values of the observations – Any whisker that is longer then 1.5 times the IQR(the box) indicates the presence of outliers. Weight Data: Boxplot min 100 Q1 125 M 150 Q3 175 Weight max 200 225 250 275 More Measures of Spread • Variance (s2): is the average of the squares of the deviations of the observations from the mean x x x 2 x s2 1 2 2 n 1 ... x n x 2 1 n 2 s x x i n 1 i 1 2 • Standard Deviation (s): is the square root of the variance s x1 x 2 x 2 x 2 ... x n x 2 n 1 • degrees of freedom: is equal to n – 1 2 1 n s x x i n 1 i 1 Usefulness of Standard Deviation • s measures the spread about the mean and should only be used when the mean is chosen as the measure of center • s = 0 only when there is no spread. This happens only when all of the observations have the same value. Otherwise s > 0. As the observations become more spread out about the mean, s gets larger. • s has the same units of measure as the original observations. • s is NOT resistant. Strong skewness or a few outliers can greatly increase s. Choosing Descriptive Statistics • Use the five number summary and box plots for distributions with skewness or outliers • Use mean and standard deviation for distributions that are symmetric • Always plot your data; remember a picture is worth a thousand words. Keep in mind that bar graphs and pie charts are best for categorical variables and histograms, time plots and stem plots are best for quantitative variables. Objectives for Class One • Identify categorical and quantitative variables. • Represent data graphically using: – bar charts – pie charts – histograms – stem plots – box plots – time plots • Describe the distribution of a variable in terms of overall pattern and identify potential exceptions or outliers • Compute standard measures of the center and spread of a distribution and interpret their values. Next Week Class Three To Be Completed Before Class Two: Chapter 1: 24, 30, 32, 36, 44 Chapter 2: 26, 28, 38, 42, 50 Complete Quiz #1 Read Chapters 3, 4 & 5