Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Scale space wikipedia , lookup
Convolutional neural network wikipedia , lookup
Dewey Decimal Classification wikipedia , lookup
Image segmentation wikipedia , lookup
Histogram of oriented gradients wikipedia , lookup
K-nearest neighbors algorithm wikipedia , lookup
Scale-invariant feature transform wikipedia , lookup
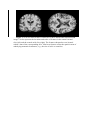
Original article Volumetric MRI Classification for Alzheimer’s Diseases Based on Kernel Density Estimation of Local Features YAN Hao, WANG Hu, WANG Yong-hui and ZHANG Yu-mei School of Foreign Languages, Xidian University, Xi’an 710071, China (Yan H) School of Psychology, Shaanxi Normal University, Xi’an 710062, China (Yan H and Wang YH) Institute of Automation, Chinese Academy of Sciences, Beijing, 100190, China (Wang H) Department of Neurology, Beijing Tiantan Hospital affiliated with Capital Medical University, Beijing 100050, China (Zhang YM) Correspondence to: Dr. Zhang Yumei, Department of Neurology, Beijing Tiantan Hospital affiliated with Capital Medical University, Beijing 100050, China (Tel: 010-67098316. Fax: 010-67098316. E-mail: [email protected]) This work was supported by the Fundamental Research Funds for the Central University, the National Natural Science Foundation of China (grant numbers 81071217, 31171073); the Beijing Nova program (grant number Z111101054511116); the National Science and Technology Major Project of China (2011BAI08B02), and Beijing Natural Science Foundation (grant number 4122082), Major Project of National Social Science Foundation (11&ZD186). There is no conflict of interests. Keywords: Classification; Inter-subject variability; Local feature; Kernel density estimation; Alzheimer’s disease Background Classification of Alzheimer’s disease (AD) from magnetic resonance images is challenged by the lack of effective and reliable biomarkers due to inter-subject variability. This paper presents a classification method for AD based on kernel density estimation of local features. Methods First, a large number of local features are extracted from stable image blobs to represent various anatomical patterns for potential effective biomarkers. Based on distinctive descriptors and locations, the local features are robustly clustered in order to identify correspondences of the same underlying patterns. Then, the kernel density estimation is used to estimate distribution parameters of the correspondences by weighting contributions according to their distances. Thus, biomarkers could be reliably quantified by reducing the effects of further away correspondences which are more likely noises from inter-subject variability. Finally, the Bayes classifier is applied on the distribution parameters for the classification of AD. Results Experiments were performed on different divisions of a publicly available database to investigate the accuracy and the effects of age and AD severity. Our method achieved an equal error classification rate of 0.85 for subject aged 60-80 years exhibiting mild AD, and outperformed a recent local-feature based work regardless of both effects. Conclusions We proposed a volumetric brain MRI classification method for neurodegenerative disease based on statistics of local features using kernel density estimation. The results demonstrate that the method may be potentially useful for the computer-aided diagnosis in clinical settings. INTRODUCTION Increasing neuroimaging researches have proved that certain neuroanatomical structures may be preferentially modified by particular cognitive skills, genes or diseases1,2. Morphological analysis of medical images is therefore used in a variety of research and clinical studies that detect and quantify spatially complex and often subtle abnormal imaging patterns of pathology. In neurodegenerative diseases (i.e. the Alzheimer’s disease, AD), the pattern of brain pathology evolves as the disease progresses-starting mainly in the hippocampus and entorhinal cortex, and subsequently spreading throughout most of the temporal lobe and the posterior cingulate, finally involving extensive brain regions3,4. It is inferred that some neurodegenerative changes starts much earlier before symptomatic disease are observable. Thus, a recent upsurge of interests has made in developing both diagnostic and prognostic biomarkers that can predict which individuals are relatively more likely to progress clinically. Quantifying inter-individual anatomical variability within a population is very important to the medical imaging, as it becomes the prerequisite to obtain reliable statistical results. Several methods have been developed to deal with the one-to-one correspondence by adopting inter-subject registration or image modeling5. The majority of them intended to quantify appearance and geometry between subjects or between a model and a subject6,7. However, the assumption of one-to-one correspondence can only be operative at a local scale, and cannot effectively represent multiple and distinct modes of appearance even in the same local anatomical area8. Provided that anatomical variability exists in brain morphology of different subjects, particularly in highly variable areas with different cortical folding patterns, the one-to-one correspondence is hard to obtain. However, local features provide a solution to effectively address the situation where one-to-one inter-subject correspondence does not exist in all subjects9-11. One-to-one correspondence indicates that every corresponding unit for morphometric analysis, such as the voxel or the regional element, can be identified in all subjects to represent the same anatomical structures. It is different from the inter-subject variability. The inter-subject variability means that the underlying anatomical structures vary in geometry and appearance from one subject to another.Based on the scales-space theory, anatomical structures can be modeled and identified by a large number of distinctive local and scale-invariant features, other than at arbitrarily global or voxel-level12. Local features are distinctive and informative so as to represent group-related morphology patterns. It can also obviate nonlinear inter-subject registration since features at different coordinates could also be well-matched, and local group-informative image patterns could be largely preserved. Registration error still exists due to inter-subject variability, particularly in the highly variable cortices, and it is difficult to guarantee that images are not being over-aligned. Furthermore, it doesn’t require segmenting images into tissues and regions, which is generally time-consuming and may introduce some residual components. Probabilistic models based on correspondences of local features have been constructed, and their distribution parameters are used to quantify informativeness of anatomical patterns with respect to groups in recent studies12. The method has shown good performance to identify group-related structures with different occurrence likelihoods. However, it could not explain what kind of specific morphological differences has happened to the structures, e.g., atrophy or enlargement as showed in traditional morphometry method. The distribution parameters for classification are not reliable and accurate enough due to the following reasons. First, only the frequencies of correspondences are utilized to estimate distribution parameters. Such kind of immature estimation neglects the information of distances between local features which would be useful to eliminate noises from inter-subject anatomical variability. Moreover, its estimator has jumps at the edge and zero derivatives everywhere else13. As a result, noises which may be significant at the edge of similar anatomical patterns lead to the reduction of reliability of the distribution parameters. Second, nearby model features from training subjects are used to estimate the distribution parameters for local features from a test subject. However, a local feature and its nearby model feature may sometimes arise from different underlying anatomical patterns due to variability, thus the accuracy of the estimation is affected. Although correspondences are identified according to the distinctiveness of local features, two type of error may still occur due to inter-subject variability. False positives (FP) occur when local features arising from different underlying anatomical structures are accepted as correspondences, and false negatives (FN) occur when local features arising from the same structure are rejected as non-correspondences. In this paper, we present a new classification method for AD based on kernel density estimation of local features from volumetric MR images. The current study builds upon previous work12, but emphasizes the accuracy and reliability of the probabilistic modeling for quantification of the informativeness of anatomical patterns with respect to groups. The modeling procedure first identifies clusters of correspondences from a large number of local features using robust measures of geometric and appearance similarity. Then the clusters are used to estimate the probabilistic densities of the local feature via the kernel density estimation (KDE)14. KDE is a nonparametric technique to estimate the probability density function without any assumptions of the underlying distribution15,16. Its estimator not only includes the frequency information in the clusters, but also relates with their distances which are weighted by a specified kernel function. With the kernel function, the estimator becomes continuous, and its smoothing degree could be adjusted to deal with different noise levels from the inter-subjects anatomical variability. As such, we could improve the accuracy and reliability of the probabilistic modeling, and further enhance the performance of the classification method. METHODS Subjects In order to validate the performance of the proposed classification method, we tested the method on a large, freely available, cross-sectional dataset from OASIS project18 (http://www.oasis-brains.org/). The dataset includes MRI data from 100 suspected Alzheimer’s disease (AD) subjects and 98 normal control (NC) subjects. The probable AD subjects are diagnosed clinically from very mild to moderate dementia characterized using the Clinical Dementia Rating (CDR) scales18. All subjects in the dataset are right-handed, with approximately equal age distributions for both NC and AD subjects ranging from 60 years to 96 years with means of 76/77 years. The dataset was divided into three different divisions according to both ages and CDRs the same as that used in12. Therefore the classification performance with the effect of age and the severity of clinical diagnosis could be evaluated. The details about the three divisions were listed as follows: 1) Subjects aged 60–80 years, CDR=1 (66 NC, 20 AD); 2) Subjects aged 60–96 years, CDR=1 (98 NC, 28 AD); 3) Subjects aged 60–80 years, CDR=0.5 and 1 (66 NC, 70 AD). Data acquisition For each subject, at least three T1-weighted magnetization-prepared rapid gradient echo (MP-RAGE) images were obtained according to the following protocol: 128 sagittal slices, matrix = 256 × 256, TR = 9.7 ms, TE = 4 ms, flip angle = 10°, resolution = 1 mm × 1 mm × 1.25 mm. The images were gain-field-corrected and averaged in order to improve the ratio of signal to noise. Then, images from all subjects were aligned within the Talairach reference frame (voxel size = 1× 1 × 1 mm3) via the affine transform T, and their skulls were masked out18. After abnormal intensities such as highlight intensities from residual skull were adjusted to normal levels via a histogram analysis, the histogram equalization was applied to normalize the intensity ranges to [0, 1] in all images. Classification method The proposed volumetric MRI classification method predicts the group (e.g., control/patient) to which an unlabeled volumetric MR image belongs according to a training set. It involves four steps: linear registration, scale-invariant feature transform, probabilistic modeling, and Bayes classification. Linear registration This step removes uncorrelated environment information including body-location differences in image acquisition and the uninterested affine parameters. Thus we could focus on the remaining appearance and geometric variability of local anatomical patterns. In addition, due to the approximate alignment of same underlying patterns, correspondences between subjects could be first constrained by their locations. Scale-invariant feature transform Given that the anatomical patterns of human brain are naturally characterized by different scales, e.g., width of ventricles or thickness of cortices, local features are desired to be adaptive to scales, other than at arbitrary global or voxel-level11,19,20. The efficient scale-invariant feature transform (SIFT) based on the scale-space theory21-23 is applied to extract such features24-26. For each volumetric image, SIFT first builds a Gaussian pyramid with incrementally blurred versions of the original image. Then, the Difference of Gaussian (DoG) space is constructed by subtracting two nearby images in Gaussian pyramid, and its local extrema are selected as candidate feature points. In order to improve their stability for further corresponding, these points are refined at sub-voxel level by interpolation in the DoG space27. These points could not be reliably localized in all spatial directions, and could be identified via an analysis of the 3 3 Hessian matrix24. Fig. 1 illustrates examples of scale-invariant features extracted in a volumetric image. Probabilistic modeling After the SIFT procedure, each volumetric image is modeled as a collage of local features. The probabilistic modeling aims at robustly quantifying the anatomical variability and informativeness of local features based on such statistical regularity in a training set. In the present study, the unlabeled image that needs classification is modeled as a set of local features as: F fi , i 1,...N , (1) where N is the total number of local features extract from the unlabeled image, and each individual feature is represented as fi ai , gi . ai is the appearance descriptor representing the measurements of a local image appearance pattern of f i , and gi xi , i represents the geometry of f i in terms of image location xi and scale i . In order to quantify the informativeness of f i , we use the following likelihood ratio12: dlr ( fi ) p( f i | C , T ) , p( f i | C , T ) (2) where p( fi | C , T ) represents the conditional probability density of a feature f i given (C, T). C is a discrete random variable of groups from which the unlabeled image may sample, and T represents the linear registration transform that approximately aligns images into normalized space. In order to ensure that the ratio in Eq. (2) is well defined even when the denominator is zero, the Dirichlet regularization which adds small artificial counts to both the numerator and the denominator of the ratio is applied28. To estimate the conditional probability density p( fi | C , T ) for likelihood ratios, several issues are taken into considerations here. Firstly, local features that do occur with f i in the training set are the basis of the density estimation. Secondly, the underlying distribution of a local feature is complex and unknown as a prior due to the various anatomical patterns. Finally, the inter-subject anatomical variability may introduce much noise into the distribution and thereby disturbing the statistic regularity of the occurrences. Let F f j , j 1,...M represent a training set of M local features that are extracted from the training images. The local feature f j is identified as an occurrence of f i if they are similar in terms of geometry and appearance. Thus, we could express the occurrence cluster Si as: Si Gi Ai , (3) where Gi represents a geometry set whose elements are similar with f i in terms of geometry, and Ai represents a appearance set whose elements are similar with f i in terms of appearance. The geometry set Gi is determined by a binary measure of geometrical similarity where feature f j is said to be similar with f i if the distances of their locations and scales are less than certain thresholds: Gi f j : xi x j x ln i , j (4) where xi and x j represent the location of f i and f j respectively, and their distance is measured by Euclidean norm; i and j represent the scale of f i and f j respectively23. x and represent the location threshold and the scale threshold, and reflect the maximum acceptable deviations of the location and the scale of a local feature occurring in different images respectively. It is also noted that the location threshold x is generally multiplied by the scale i in previous study, so as to make the binary measure for geometry scale-independent13. This part is determined by the resampling rate i of the octave where f i locates. Therefore, we set the location threshold as: x x 2 i . (5) Such location threshold makes the measure for geometry similarity adaptive to octaves with different resampling rates. Next, the appearance set Ai is determined by a binary measure of appearance similarity where local feature f j is said to be similar with f i if their Euclidean distance of appearance descriptors is less than the threshold ai : Ai ( ai ) f j : ai a j ai , (6) where ai and a j represent the location of f i and f j respectively. The threshold ai represents the maximum acceptable deviation of the appearance descriptor of a local feature occurring in different images. A key issue of clustering is to determine the three thresholds x , , ai , as improper thresholds may increase the false-positive or false-negative occurrences. The optimal value for ai is automatically determined as: a sup a [0, ) : Ai ( a ) Gi Ai ( a ) Gi . i (7) The optimal values for thresholds x and are selected via cross-validation on a training set. After the identification of the cluster of occurrences for each local feature, the next step is to estimate the probability density of f i based on the spatial distribution of the occurrences. KDE is appropriate for this situation, as it can estimate the probability density function without any assumptions of the underlying distribution16,17,29. Given the cluster of occurrences Si , p( f i C , T ) can be estimated as: 2 i ai a 1 1 pˆ ( fi | C , T ) exp , d 2 2 2 NC fiSi C 2 h 2 2 h a i where ai and ai are the appearance descriptors of f i and f i ; d is the dimension of (8) appearance descriptors; N C is the count of training images in group C, and h is the bandwidth of the kernel function. In the Eq. (8), the appearance threshold ai is used to normalize the distances of feature descriptors, which makes the estimation more adaptive to patterns with different anatomical variabilities. The bandwidth h is a free parameter to control the smoothness of the probability density function17, and its optimal value can be obtained via the cross-validation approach. Bayes classification The classification of an unlabeled image is based on the informativeness of each local feature quantified in probabilistic modeling in terms of likelihood ratio30,31. Given the knowledge of (T, C), it is assumed that local features are conditional independent13. Then, the Bayes classifier makes a decision using the maximum a posteriori (MAP) rule as: p C,T | F C arg max C p C , T | F * p C,T N p f | C,T i arg max , C p C , T i 1 p fi | C , T (9) N arg max P0 dlr ( fi ) C i 1 where p C, T | F represents the posterior probability density of (C, T) given F. p(C , T ) represents a joint prior distribution over (C, T), and p ( F ) represents the probability density of evidence of feature set F. Accordingly, the classification is primarily driven by the data likelihood ratio (DLR) of the unlabeled volumetric image: N DLR dlr ( f i ) . (10) i 1 Evaluations of classification performance The threshold of data likelihood ratio was adjusted to generate the receive operating characteristic (ROC) curve32. Besides, we also reported other two threshold-independent metrics from the ROC curve—the equal error classification rate (EER) and the area under the ROC curve (AUC). RESULTS The bandwidth was originally set as h 0.2 . Cross-validation in grid-search manner was performed to check each combination of thresholds: x 1, 2, ...,10 , 0.6, 0.7, ..., 2.0 . Different values of the bandwidth were then cross-validated in 0.04, 0.06, ...,1.00 . The value that yielded the best classification performance was selected as the optimal value of the bandwidth. The cross-validation surfaces for geometry thresholds x , on three divisions were shown in Fig. 2. The maxima of the surfaces were obtained at the following coordinates: divisions 1) x' 7, 1.3 ; divisions 2) x' 7, 1.3 ; divisions 3) x' 7, 1.8 . The cross-validation curves for the bandwidth on three divisions were shown in Fig. 3. The trends of AUC curves were similar on different divisions. Particularly, the curves were relatively stationary between the 0.15 and 0.25, and they decreased drastically when the bandwidth went from the 0.1 to 0, while decreased gradually as the bandwidth was above 0.4. This coincided with the smoothing mechanism of the bandwidth. On the one hand, small value resulted in the undersmoothing of probability density functions, thus the functions became more sensitive to noise from the inter-subject anatomical variability. On the other hand, large value may result in the oversmoothing, which makes the function insensitive to fine anatomical patterns. To avoid such overfitting, the curves derived from different divisions were averaged. The optimal value for the bandwidth was selected at h 0.23 where the maximum of the averaged AUC curve was reached. We evaluated the performance of the proposed method on the three divisions with different levels of ages and the severity from clinical diagnosis, in comparison with a recent local-feature based classification method13. Their performances were firstly tested via the ROC curves (shown in Fig. 4). Overall, the ROC curves of our method were above that of the Toews’ method. Then, the performances were also compared using both the EER values and AUC values. Particularly, the EER values of our method were 0.85, 0.79 and 0.72 respectively, while the corresponding values derived from the Toews’ method were 0.80, 0.72, 0.70. In addition, AUC values of our method were 0.92, 0.85 and 0.80 respectively, while these values generated by Toews’ method were 0.88, 0.81 and 0.73. Both methods were implemented in C++ programming language and tested on a computer with a four-core-processor running at 3.46GHz and 8GB RAM. The average time consumed to classify an unlabeled image was about 2.2 minutes. Such time can meet the good criterion for a clinical MRI diagnosis. The memory amounts consumed in the experiments were also listed in Table I. They were generally acceptable and linearly dependent on the sample size of study cohort. DISCUSSION In this paper, we proposed a volumetric brain MRI classification method for neurodegenerative disease based on statistics of local features using kernel density estimation. Statistics of local features specifically aimed at making use of the group-related anatomical patterns whose correspondence between all images were ambiguous. Nonparametric kernel density estimation technique was adopted to improve both the accuracy and reliability of the probabilistic densities in statistics, further enhancing the classification performance. In the experiments on three divisions of a freely available OASIS dataset18 with different age ranges and different severity of clinical diagnosis, the proposed method all achieved higher AUC values than the method currently suggested by Toews13]. The better classification accuracy indicated that the proposed method may be potentially useful for computer-aided diagnosis in clinical settings. The Bayes classifier employed in the volumetric MRI classification method was built on three steps involving linear registration, scale-invariant feature transform, and probabilistic modeling. In particular, linear registration was used to achieve approximate inter-subject alignment of potential corresponding anatomical pattern in volumetric images. A large number of local features extracted by the 3D scale-invariant feature transform were used to represent various anatomical patterns of volumetric images. Based on these local features, the probabilistic modeling step can quantify the anatomical variability and informativeness with respect to groups in terms of likelihood ratios. The probabilistic modeling aimed at making use of group-related local features which did occur with statistical regularity to improve the individual classification performance. This was achieved by robust feature clustering and probability density estimation. In the presence of anatomical variability, feature clustering tried to identify correspondences of the same underlying anatomical patterns based on the distinctive appearance and geometry of local features. Particularly, the error threshold for the measurement of appearance similarity was determined in a feature-specific manner, meaning that clusters with different anatomical variability may have different error thresholds. In conclusion, feature clustering may provide a more effective mechanism for statistics of individual anatomical variability, overcoming the limitation of traditional methods which were based on the fundamental assumption of one-to-one correspondence between all subjects. After that, KDE was utilized to estimate the probability densities of local features. Compared with the naive estimator adopted in Toews’ classification method, the estimator of KDE was evidently smoother14. In addition, the amount of smoothing controlled by bandwidth of KDE was cross-validated to select an optimal value, so the estimator could be closer to the actual distribution of the local feature and more robust to the noise from anatomical variability16,17. A limitation of our current study has been the failure to compare different classifiers. Only the Bayes classifier was tested as it could be naturally applied to the statistic of local features given the strong independent assumption. Although the Bayes classifier could obtain good accuracy and robustness in the classification experiments of Alzheimer’s diseases, other classifiers should be performed to find out which was more suitable according to the no-free-lunch theorem33. Nevertheless, most classifier algorithms were applied to an input vector with fixed-length, and the elements were correspondent between the input vector and the vectors in training samples. In contrast, the numbers of local features extracted in different image are not fixed, and the correspondences may not exist in all volumetric images. Therefore, special feature selection strategies should be introduced to obtain a more suitable vector for each volumetric image with fixed-length and correspondent elements from the local features. In future, we plan to compare various classifiers combined with suitable feature selection techniques to further improve classification performances for neurodegenerative diseases. In particular, we will first expand the correspondence of the local features between subsets of subjects to the whole set via some strategies, and then generate a new vector for each volumetric images with fixed-length and correspondent elements. After that, some sophisticated feature selection and reduction methods will be applied to produce a relatively short vector to avoid the "curse of dimensionality" phenomenon34. Finally, various tests will be performed on the short vectors to compare different classifiers (e.g., AdaBoost and support vector machine35) on the OASIS dataset. REFERENCES 1. 2. 3. 4. 5. 6. 7. 8. Reiman EM, Caselli RJ, Yun LS, Chen K, Bandy D, Minoshima S, et al. Preclinical Evidence of Alzheimer's Disease in Persons Homozygous for the ε4 Allele for Apolipoprotein E. N Engl J Med 1996; 12:752-758 (PMID: 8592548). Nakata Y, Sato N, Nemoto K, Abe O, Shikakura S, Arima K, et al. Diffusion abnormality in the posterior cingulum and hippocampal volume: correlation with disease progression in Alzheimer's disease. Magn Reson Imaging 2009; 3:347-354 (PMID: 18771871). Braak H, Braak E. Evolution of the neuropathology of Alzheimer's disease. Acta Neurol Scand Suppl 1996:3-12 (PMID: 12098565). Jack CR, Shiung MM, Weigand SD, O’Brien PC, Gunter JL, Boeve BF, et al. Brain atrophy rates predict subsequent clinical conversion in normal elderly and amnestic MCI. Neurology 2005; 8:1227-1231 (PMID:16247049). Blezek DJ, Miller JV. Atlas stratification. Med Image Anal 2007; 5:443-457 (PMID:17765003). Grenander U, Miller MI. Computational anatomy: an emerging discipline. Quarterly of applied mathematics 1998; 4:617-694 (PMID: 9339500). Rueckert D. Nonrigid registration: Concepts, algorithms, and applications. Medical image registration. Boca Raton: FL: CRC Press; 2001. p. 281–301 (PMID:12045001). Ono M, Kubik S, Abernathy CD. Atlas of the cerebral sulci. New York: Thieme Medical, 1990 (PMID:10011237) 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. Sun ZY, Rivière D, Poupon F, Régis J, Mangin J-F. Automatic inference of sulcus patterns using 3D moment invariants. Proceedings of the 10th international conference on Medical image computing and computer-assisted intervention; 2007. p 515-522 (PMID: 18051098). Toews M, Arbel T. A Statistical Parts-Based Model of Anatomical Variability. IEEE Trans Med Imaging 2007; 4:497-508 (PMID:17427737). Toews M, Collins DL, Arbel T. Automatically learning cortical folding patterns. Biomedical Imaging: From Nano to Macro, IEEE International Symposium on; 2009. p 1330-1333 (PMID:17427742). Toews M, Wells Iii W, Collins DL, Arbel T. Feature-based morphometry: Discovering group-related anatomical patterns. NeuroImage 2010; 3:2318-2327 (PMID:19853047). Silverman BW. Density estimation for statistics and data analysis. London: Chapman and Hall, 1986 (PMID: 22252279). Parzen E. On the estimation of a probability density function and mode. Annals of Mathematical Statistics 1962:1065-1076 (PMID: 21118770). Scott DW. Multivariate Density Estimation: Theory, Practice, and Visualization. New York: Wiley, 1992 (PMID:19513124). Duda RO, Hart PE, Stork DG. Pattern Classification (2nd Edition). New York: Wiley-Interscience, 2000 (PMID: 23323582). Marcus DS, Wang TH, Parker J, Csernansky JG, Morris JC, Buckner RL. Open Access Series of Imaging Studies (OASIS): Cross-sectional MRI Data in Young, Middle Aged, Nondemented, and Demented Older Adults. Journal of Cognitive Neuroscience 2007; 9:1498-1507 (PMID: 17714011). Morris JC. The Clinical Dementia Rating (CDR): current version and scoring rules. Neurology 1993; 11:2412-2414 (PMID:8232972). Talairach J, Tournoux P. Co-planar stereotaxic atlas of the human brain: 3-dimensional proportional system: an approach to cerebral imaging. Stuttgart: Georg Thieme Verlag, 1988 (PMID:10842217). Penev PS, Atick JJ. Local feature analysis: a general statistical theory for object representation. Network: computation in neural systems 1996; 3:477-500 (PMID: 23322348). Fergus R. Object Class Recognition by Unsupervised Scale-Invariant Learning. IEEE Computer Society Conference on Computer Vision and Pattern Recognition; 2003. p 264-264 (PMID: 23262468). Lindeberg T. Scale-space theory: A basic tool for analysing structures at different scales. Journal of Applied Statistics 1994; 2:224-270 (PMID: 22422546). Lowe DG. Distinctive Image Features from Scale-Invariant Keypoints. Int J Comput Vis 2004; 2:91-110 (PMID: 17946463). Mikolajczyk K, Schmid C. A performance evaluation of local descriptors. IEEE Trans Pattern Anal Mach Intell 2005; 10:1615-1630 (PMID: 16237996). Allaire S, Kim JJ, Breen SL, Jaffray DA, Pekar V. Full orientation invariance and improved feature selectivity of 3D SIFT with application to medical image 26. 27. 28. 29. 30. 31. 32. 34. 35. analysis. Computer Vision and Pattern Recognition Workshops, IEEE Computer Society Conference on; 2008. p 1-8 (PMID: 22915118). Ni D, Qu Y, Yang X, Chui YP, Wong TT, Ho SS, et al. Volumetric Ultrasound Panorama Based on 3D SIFT. Proceedings of the 11th International Conference on Medical Image Computing and Computer-Assisted Intervention, Part II 2008. p 52-60 (PMID: 18982589). Cheung W, Hamarneh G. N-SIFT: N-Dimensional Scale Invariant Feature Transform. IEEE Trans Image Process 2009; 9:2012-2021 (PMID: 19502129). Brown M, Lowe DG. Invariant features from interest point groups. Proceedings of The 13th British Machine Vision Conference; 2002; Cardiff, Wales. p 656-665 (PMID: 23297842). Bishop CM. Pattern recognition and machine learning. New York: Springer, 2006 (PMID: 23193592). Uzunbas MG, Soldea O, Unay D, Cetin M, Unal G, Ercil A, et al. Coupled nonparametric shape and moment-based intershape pose priors for multiple basal ganglia structure segmentation. IEEE Trans Med Imaging 2010; 12:1959-1978 (PMID: 21118755). Zhang H. The Optimality of Naive Bayes. Proceedings of the 17th Florida Artificial Intelligence Research Society Conference; 2004. p 562-567 (PMID: 19963578). Fawcett T. An introduction to ROC analysis. Pattern Recognition Letters 2006; 8:861-874 (PMID: 23322456). Wolpert DH. The lack of a priori distinctions between learning algorithms. Neural Comput 1996; 7:1341-1390 (PMID: 18781492). Duchesnay E, Cachia A, Roche A, Riviere D, Cointepas Y, PapadopoulosOrfanos D, et al. Classification Based on Cortical Folding Patterns. IEEE Trans Med Imaging 2007; 4:553-565 (PMID: 17427742). Figure 1. Scale-invariant features extracted in a three-dimensional structural MR image. Circles represent the locations and scales of features in the central coronal slice (left) and the central axial slice (right). The features shown above are located within 2 mm of the corresponding slice. Note how features reflect the spatial extent of underlying anatomical structures, e.g., the size of sulci or ventricles. Figure 2. Cross-validation surfaces for geometry thresholds on three different divisions: (a) Subjects aged 60–80 years, CDR=1 (66 NC, 20 AD); (b) Subjects aged 60–96 years, CDR=1 (98 NC, 28 AD); (c) Subjects aged 60–80 years, CDR=0.5 and 1 (66 NC, 70 AD). Bandwidth is set as h 0.2 . The surfaces are relatively stable in the neighborhoods of the maximum points. Figure 3. Cross-validation curves for bandwidths on three different divisions, given geometry thresholds respectively: division 1) x' 7, 1.3 ; division 2) x' 7, 1.3 ; division 3) x' 7, 1.8 . The dotted curve is the average of other three curves. The optimal value for the bandwidth is selected at point where the maximum of the averaged AUC curve is reached. Figure 4. Comparison of ROC curves of two classification methods on three different divisions: (a) Subjects aged 60–80 years, CDR=1 (66 NC, 20 AD); (b) Subjects aged 60–96 years, CDR=1 (98 NC, 28 AD); (c) Subjects aged 60–80 years, CDR=0.5 and 1 (66 NC, 70 AD). The red solid curves are the result of our method, while the blue dashes are those of Toews. Table 1. The memory amounts practically consumed to classify a new image on the three divisions Division 1) Division 1) Division 1) Sample size 85 125 135 Memory (MB) 593 804 855