Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
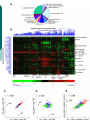
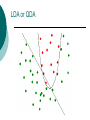
Mutivariate statistical Analysis methods Ahmed Rebaï Centre of Biotechnology of Sfax [email protected] Basic statistical concepts and tools Statistics Statistics are concerned with the ‘optimal’ methods of analyzing data generated from some chance mechanism (random phenomena). ‘Optimal’ means appropriate choice of what is to be computed from the data to carry out statistical analysis Random variables A random variable is a numerical quantity that in some experiment, that involve some degree of randomness, takes one value from some set of possible values The probability distribution is a set of values that this random variable takes together with their associated probability The Normal distribution Proposed by Gauss (1777-1855) : the distribution of errors in astronomical observations (error function) Arises in many biological processes, Limiting distribution of all random variables for a large number of observations. Whenever you have a natural phenomemon which is the result of many contributiong factor each having a small contribution you have a Normal The Quincunx Bell-shaped distribution Distribution function The distribution function is defined F(x)=Pr(X<x) t F ( t ) f ( x )dx where 1 f(x) e 2² ( x )² 2 ² F is called the cumulative distribution function (cdf) and f the probability distrbution function (pdf) of X and ² are respectively the mean and the variance of the distribution Moments of a distribution The kth moment is defined as 'k E( x ) x k f ( x ) dx k The first moment is the mean The kth moment about the mean is k E( x ) ( x ) f ( x ) dx k k The second moment about the mean is called the variance ² Kurtosis: a useful moments’ function Kurtosis 4=4-3²2 4 0 for a normal distribution so it is a measure of Normality Observations Observations xi are realizations of a random variable X The pdf of X can be visualized by a histogram: a graphics showing the frequency of observations in classes Estimating moments The Mean of X is estimated from a set of n observations (x1, x2, ..xn) as 1 n x xi n i 1 The variance is estimated by n 1 2 2 ( xi x ) Var(X) = n 1 i1 The fundamental of statistics Drawing conclusions about a population on the basis on a set of measurments or observations on a sample from that population Descriptive: get some conclusions based on some summary measures and graphics (Data Driven) Inferential: test hypotheses we have in mind befor collecting the data (Hypothesis driven). What about having many variables? Let X=(X1, X2, ..Xp) be a set of p variables What is the marginal distribution of each of the variables Xi and what is their joint distribution If f(X1, X2, ..Xp) is the joint pdf then the marginal pdf is f ( X i ) f ( x1 ,.., xi 1 , xi 1 ..., x p )dx1 ....dx p Independance Variables are said to be independent if f(X1, X2, ..Xp)= f(X1) . f(X2)…. f(Xp) Covariance and correlation Covariance is the joint first moment of two variables, that is Cov(X,Y)=E(X-X)(Y- Y)=E(XY)-E(X)E(Y) Correlation: a standardized covariance ( X ,Y ) Cov( X ,Y ) Var( X ).Var( Y ) is a number between -1 and +1 For example: a bivariate Normal Two variables X and Y have a bivariate Normal if f ( x, y ) 1 21 2 1 2 e ( x 1 )( y 2 ) ( y 2 )² 1 ( x 1 )² 2 2 ² ² 2 1 1 1 2 is the correlation between X and Y Uncorrelatedness and independence If =0 (Cov(X,Y)=0) we say that the variables are uncorrelated Two uncorrelated variables are independent if and only if their joint distribution is bivariate Normal Two independent variables are necessarily uncorrelated Bivariate Normal f ( x, y ) 1 21 2 1 2 e ( x 1 )( y 2 ) ( y 2 )² 1 ( x 1 )² 2 1 2 ²2 1 2 ²1 If =0 then f ( x, y ) 1 21 ² e ( x 1 )² ²1 1 22 ² e ( y 2 )² ²2 So f(x,y)=f(x).f(y) the two variables are thus independent Many variables We can calculate the Covariance or correlation matrix of (X1, X2, ..Xp) v( x1 ) c(x1,x2 ) ........c(x1,x p ) c(x1,x2 ) v( x2 ) ........c(x2 ,x p ) c(x ,x ) c(x ,x )..........v( x ) 2 p p 1 p C=Var(X)= A square (pxp) and symmetric matrix A Short Excursion into Matrix Algebra What is a matrix? Operations on matrices Transpose Properties Some important properties Other particular operations Eigenvalues and Eigenvectors Singular value decomposition Multivariate Data Multivariate Data Data for which each observation consists of values for more than one variables; For example: each observation is a measure of the expression level of a gene i in a tissue j Usually displayed as a data matrix Biological profile data The data matrix x11 x12 ....x1 p x 21 x 22 ....x 2 p x x ....x np n1 n 2 n observations (rows) for p variables (columns) an nxp matrix Contingency tables When observations on two categorial variables are cross-classified. Entries in each cell are the number of individuals with the correponding combination of variable values Eyes colour Hair colour Fair Red Medium Dark Blue 326 38 241 110 Medium 343 84 909 412 Dark 98 48 403 681 Light 688 116 584 188 Mutivariate data analysis Exploratory Data Analysis Data analysis that emphasizes the use of informal graphical procedures not based on prior assumptions about the structure of the data or on formal models for the data Data= smooth + rough where the smooth is the underlying regularity or pattern in the data. The objective of EDA is to separate the smooth from the rough with minimal use of formal mathematics or statistics methods Reduce dimensionality without loosing much information Overview on the techiques Factor analysis Principal components analysis Correspondance analysis Discriminant analysis Cluster analysis Factor analysis A procedure that postulates that the correlations between a set of p observed variables arise from the relationship of these variables to a small number k of underlying, unobservable, latent variables, usually known as common factors where k<p Principal components analysis A procedure that transforms a set of variables into new ones that are uncorrelated and account for a decreasing proportions of the variance in the data The new variables, named principal components (PC), are linear combinations of the original variables PCA If the few first PCs account for a large percentage of the variance (say >70%) then we can display the data in a graphics that depicts quite well the original observations Example Correspondance Analysis A method for displaying relationships between categorial variables in a scatter plot The new factors are combinations of rows and columns A small number of these derived coordinate values (usually two) are then used to allow the table to be displayed graphically Example: analysis of codon usage and gene expression in E. coli (McInerny, 1997) A gene can be represented by a 59dimensional vector (universal code) A genome consists of hundreds (thousands) of these genes Variation in the variables (RSCU values) might be governed by only a small number of factors For each gene and each codon i calculate RCSU=# observed codon /#expected codon Codon usage in bacterial genomes Evidence that all synonymous codons were not used with equal frequency: Fiers et al., 1975 A-protein gene of bacteriophage MS2, Nature 256, 273-278 UUU Cys UUC Cys UUA Ter UUG Trp CUU Arg CUC Arg CUA Arg CUG Arg Phe 0 Phe 3 Leu * Leu 12 Leu 7 Leu 6 Leu 6 Leu 3 AUU Ile 6 UCU Ser 5 UAU Tyr 4 UGU 10 UCC Ser 6 UAC Tyr 12 UGC 8 UCA Ser 8 UAA Ter * UGA 6 UCG Ser 10 UAG Ter * UGG 6 CCU Pro 5 CAU His 2 CGU 9 CCC Pro 5 CAC His 3 CGC 5 CCA Pro 4 CAA Gln 9 CGA 2 CCG Pro 3 CAG Gln 9 CGG 1 ACU Thr 11 AAU Asn 2 AGU Multivariate reduction Attempts to reduce a high-dimensional space to a lower-dimensional one. In other words, it tries to simplify the data set. Many of the variables might co-vary, therefore there might only be one, or a small few sources of variation in the dataset A gene can be represented by a 59-dimensional vector (universal code) A genome consists of hundreds (thousands) of these genes Variation in the variables (RSCU values) might be governed by only a small number of factors Plot of the two most important axes Lowly-expressed genes Highly expressed genes Recently acquired genes Discriminant analysis Techniques that aim to assess whether or a not a set of variables distinguish or discriminate between two or more groups of individuals Linear discriminant analysis (LDA): uses linear functions (called canonical discriminant functions) of variable giving maximal separation between groups (assumes tha covariance matrices within the groups are the same) if not use Quadratic Discriminant analysis (QDA) Example: Internal Exon prediction Data: A set of exons and non-exons Variables : a set of features donor/acceptor site recognizers octonucleotide preferences for coding region octonucleotide preferences for intron interiors on either side LDA or QDA Cluster analysis A set of methods (hierarchical clustering, K-means clustering, ..) for constructing sensible and informative classification of an initially unclassified set of data Can be used to cluster individuals or variables Example: Microarray data Other Methods Independant component analysis (ICA): similar to PCA but components are defined as independent and not only uncorrelated; moreover they are not orthogonal and uniquely defined Multidimensional Scaling (MDS): a clustering technique that construct a low-dimentional geometrical representation of a distance matrix (also Principal coordinates analysis) Useful books: Data analysis Useful book: R langage