Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
The Measure of a Man (Star Trek: The Next Generation) wikipedia , lookup
Data (Star Trek) wikipedia , lookup
Concept learning wikipedia , lookup
Linear belief function wikipedia , lookup
Time series wikipedia , lookup
Machine learning wikipedia , lookup
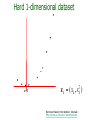
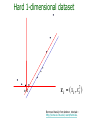
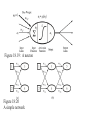
CS 8520: Artificial Intelligence Machine Learning 2 Paula Matuszek Spring, 2013 CSC 8520 Spring 2013. Paula Matuszek 1 Regression Classifiers • We said earlier that the task of a supervised learning system can be viewed as learning a function which predicts the outcome from the inputs: – Given a training set of N example pairs (x1, y1) (x2,y2)...(xn,yn), where each yj was generated by an unknown function y = f(x), discover a function h that approximates the true function y • A large class of supervised learning approaches discover h with regression methods. CSC 8520 Spring 2013. Paula Matuszek 2 Regression Classifiers • The basic idea underlying regression is: – plot all of the sample points for n-feature examples in an n-dimensional space – find an n-dimensional plane that separates the positive examples from the negative examples best • If you are familiar with the statistical concept of regression for prediction, this is the same idea. CSC 8520 Spring 2013. Paula Matuszek 3 Linear Classifiers denotes +1 denotes -1 How would you classify this data? Copyright © 2001, 2003, Andrew W. Moore Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Linear Classifiers denotes +1 denotes -1 How would you classify this data? Copyright © 2001, 2003, Andrew W. Moore Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Linear Classifiers denotes +1 denotes -1 How would you classify this data? Copyright © 2001, 2003, Andrew W. Moore Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Linear Classifiers denotes +1 denotes -1 How would you classify this data? Copyright © 2001, 2003, Andrew W. Moore Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Linear Classifiers denotes +1 denotes -1 Any of these would be fine.. ..but which is best? Copyright © 2001, 2003, Andrew W. Moore Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Measuring Fit • For prediction, we can measure the error of our prediction by looking at how far off our predicted value is from the actual value. – compute individual errors – sum them • Typically we are much more worried about large errors than small ones – square the errors • This gives us a measure of fit which is the sum of squared errors • This best fit hypothesis can be solved analytically (see equation 18.3 in the text) CSC 8520 Spring 2013. Paula Matuszek 9 Linear Classifiers • A linear classifier is just a hypothesis determined by linear regression with a threshold added • Rather than a hard threshold we typically use a logistic function to determine the optimal cutoffs. – fitted through gradient descent CSC 8520 Spring 2013. Paula Matuszek 10 More on Regression Models • So far we have discussed linear models • We can add dimensions to the model by including higher-order terms, such as squared or cubed values of the features. • As with decision trees, we can get overfitting. If we add enough dimensions we can fit almost anything! CSC 8520 Spring 2013. Paula Matuszek 11 Support Vector Machines • A Support Vector Machine (SVM) is a classifier – It uses features of instances to decide which class each instance belongs to • It is a supervised machine-learning classifier – Training cases are used to calculate parameters for a model which can then be applied to new instances to make a decision • It is a binary classifier – it distinguishes between two classes • It is currently the most popular off-the-shelf machine learning classifier CSC 8520 Spring 2013. Paula Matuszek 12 Basic Idea Underlying SVMs • Find a line, or a plane, or a hyperplane, that separates our classes cleanly. – This is the same concept as we have seen in regression. • By finding the greatest margin separating them – This is not the same concept as we have seen in regression. What does it mean? CSC 8520 Spring 2013. Paula Matuszek 13 Linear Classifiers denotes +1 denotes -1 Any of these would be fine.. ..but which is best? Copyright © 2001, 2003, Andrew W. Moore Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Classifier Margin denotes +1 denotes -1 Copyright © 2001, 2003, Andrew W. Moore Define the margin of a linear classifier as the width that the boundary could be increased by before hitting a datapoint. Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Maximum Margin denotes +1 denotes -1 The maximum margin linear classifier is the linear classifier with the maximum margin. Called Linear Support Vector Machine (SVM) Copyright © 2001, 2003, Andrew W. Moore Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Maximum Margin denotes +1 denotes -1 Support Vectors are those datapoints that the margin pushes up against Copyright © 2001, 2003, Andrew W. Moore The maximum margin linear classifier is the linear classifier with the, um, maximum margin. Called Linear Support Vector Machine (SVM) Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Why Maximum Margin? denotes +1 denotes -1 Support Vectors are those datapoints that the margin pushes up against Copyright © 2001, 2003, Andrew W. Moore 1. If we’ve made a small error in the location off(x,w,b) the boundary (it’s been = sign(w. x - b) jolted in its perpendicular direction) this gives us least chance of causing a The maximum misclassification. margin linear 2. Empirically it works very very classifier iswell. the linear classifier with the, um, maximum margin. This is the simplest kind of SVM (Called an LSVM) Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Concept Check • For which of these could we use a basic linear SVM? – A: Classify the three kinds of iris in the UC Irvine data set? – B: Classify email into spam and non-spam? – C: Classify students into likely to pass or not? • Which of these is the SVM margin? A CSC 8520 Spring 2013. Paula Matuszek B 19 Messy Data • This is all good so far. • Suppose our aren’t that neat: CSC 8520 Spring 2013. Paula Matuszek 20 Soft Margins • Intuitively, it still looks like we can make a decent separation here. – Can’t make a clean margin – But can almost do so, if we allow some errors • We introduce a slack variable, which measure the degree of misclassification and adds a cost (C) for these misclassified instances. • Tradeoff between wide margin and classification errors – High cost will give relatively narrow margins – Low cost will give broader margins but misclassify more data. • How much we want it to cost to misclassify instances depends on our domain -- what we are trying to do CSC 8520 Spring 2013. Paula Matuszek 21 Only Two Errors, Narrow Margin CSC 8520 Spring 2013. Paula Matuszek 22 Several Errors, Wider Margin CSC 8520 Spring 2013. Paula Matuszek 23 Finding the Margin • Conceptually similar to sum of squared errors for regression • First we find the maximum margin separator – minimize the error of the points that are closest to the separator line – Formula 18.14 in the text • The margin is then the band that touches the nearest points CSC 8520 Spring 2013. Paula Matuszek 24 Evaluating SVMs • Same as evaluating any other classifier • Train on sample data, evaluate on test data (why?) • Look at: – classification accuracy – confusion matrix – sensitivity and specificity CSC 8520 Spring 2013. Paula Matuszek 25 More on Evaluating SVMs • Overfitting: very close fit to training data which takes advantage of irrelevant variations in instances – performance on test data will be much lower – may mean that your training sample isn’t representative – in SVMs, may mean that C is too high • Is the SVM actually useful? – Compare to the “majority” classifier CSC 8520 Spring 2013. Paula Matuszek 26 Non-Linearly-Separable Data • Suppose we can’t get a good linear separation of data? • As with regression, allowing non-linearity will give us better modeling of many data sets. • In SVMs, we do this by using a kernel. • A kernel is a function which maps our data into a higher-order order feature space where we can find a separating hyperplane • Common kernels are polynomial, RBF CSC 8520 Spring 2013. Paula Matuszek 27 Hard 1-dimensional dataset What can be done about this? x=0 Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Hard 1-dimensional dataset x=0 Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Hard 1-dimensional dataset x=0 Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. SVM Kernel Functions • K(a,b)=(a . b +1)d is an example of an SVM Kernel Function • Beyond polynomials there are other very high dimensional basis functions that can be made practical by finding the right Kernel Function • Most common: Radial-Basis-style Kernel Function: Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Borrowed heavily from Andrew tutorials:: http://www.cs.cmu.edu/~awm/tutorials. Kernel Trick • We don’t actually have to compute the complete higher-order function • In the 18.14 equation we only use the dot product • So we replace it with a kernel function • This means we can work with much higher dimensions without getting hopeless performance • The kernel trick in SVMs refers to all of this: using a kernel function instead of the dot product to give us separation of non-linear data without impossible performance cost. CSC 8520 Spring 2013. Paula Matuszek 34 Why SVMs? • Focus on the instances nearest the margin is paying more attention to where the differences are critical • Can handle very large feature sets effectively • In practice has been shown to work well in a variety of domains CSC 8520 Spring 2013. Paula Matuszek 35 Summary • SVMs are a form of supervised classifier • The basic SVM is binary and linear, but there are non-linear and multi-class extensions • “One key insight and one neat trick”1 – key insight: maximum margin separator – neat trick: kernel trick • A good method to try first if you have no knowledge about the domain • Applicable in a wide variety of domains 1Artificial Intelligence, a Modern Approach, third edition, Russell and Norvig, 2010, p, 744 CSC 8520 Spring 2013. Paula Matuszek 36 Learning by Analogy: Case-based Reasoning • Case-based systems are a significant chunk of AI in their own right. A case-based system has two major components: – Case base – Problem solver • The case base contains a growing set of cases, analogous to either a KB or a training set. • Problem solver has – A case retriever and – A case reasoner. • May also have a case installer. CSC 8520 Spring 2010. Paula Matuszek CSC 8520 Spring 2013. Paula Matuszek 37 Case-Based Retrieval • Cases are described as a set of features • Retrieval uses methods such as – Nearest neighbor: compare all features to all cases in KB and choose closest match – Indexed: compute and store some indices with each case and retrieve matching indices – Domain-based model clustering: CB is organized into a domain model; insertion is harder, but retrieval is easier. • Example: “documents like this one” – Features are the word frequencies in the document CSC 8520 Spring 2010. Paula Matuszek CSC 8520 Spring 2013. Paula Matuszek 38 Case-Based Reasoning Example • A frequency matrix for diagnosing system problems is a simple case-based example • Representation is a matrix of observed symptoms and causes • Each case is an entry in cell of the matrix – Critic is actual outcome of case – Learner adds entry to appropriate cells • Performer matches symptoms, chooses possible causes CSC 8520 Spring 2013. Paula Matuszek 39 Car won’t start Battery dead Out of gas Alternator Battery bad bad case 1 case 2 case 3 Car stalls at stoplights case 4 case 5 Car misfires in rainy weather Lights won’t case 1 case 2 come on CSC 8520 Spring 2013. Paula Matuszek 40 Case-based Reasoning • Definition of relevant features is critical: – Need to get the ones which influence outcomes – At the right level of granularity • The reasoner can be a complex planning and what-if reasoning system, or a simple query for missing data. • Only really becomes a “learning” system if there is a case installer as well. • Can grow cumulatively. CSC 8520 Spring 2013. Paula Matuszek 41 Neural Nets, the very short version • A neural net consists of layers of nodes, or neurons, each of which has an activation level – Nodes of each layer receive inputs from previous layers; these are combined according to a set of weights. – If the activation level is reached the node “fires” and sends inputs to the next level – The initial layer is data from cases; the final layer is expected outcomes • Learning is accomplished by modifying the weights to reduce the prediction error CSC 8520 Spring 2013. Paula Matuszek 42 Figure 18.19: A neuron Figure 18:20 A simple network CSC 8520 Spring 2013. Paula Matuszek A network with an input layer, a hidden layer, and an output layer. 43 Neural Nets, continued • The typical method of modifying the weights is back-propagation – success or failure at the output node is “propagated back” through the nodes which contributed to that output node – essentially a form of gradient descent • Number of hidden nodes/layers is complicated decision – too many = overfitting – Typical is to try several and evaluate CSC 8520 Spring 2013. Paula Matuszek 44 Reinforcement Learning • If an agent has multiple sequential actions to perform, learning needs a different mode – each action affects available future actions – feedback may not be available after every action – agent has a long-term goal to maximize • Agent learns a policy which is basically a transition function • Issues include – exploration vs exploitation – credit assignment – generalization CSC 8520 Spring 2013. Paula Matuszek 45 Supervised Learning, Summary • Learning systems which, given examples and results, learn a model which will yield correct results for future examples • Typically used for classification • Most widely applied ML category • Depends on getting relevant features and representative examples • Evaluated against separate test sample; overfitting • Usefulness should be checked against “majority” classifier CSC 8520 Spring 2013. Paula Matuszek 46 Unsupervised Learning • Typically used to refer to clustering methods which don’t require training cases – No prior definition of goal – Typical aim is “put similar things together” • • • • Grouping search results Grouping inputs to a customer response system Purchases from a web site Census data about types and costs of housing • Combinations of hand-modeled and automatic can work very well: Google News, for instance. • Still requires good feature set CSC 8520 Spring 2013. Paula Matuszek 47 Clustering Basics Collect examples Compute similarity among examples according to some metric Group examples together such that – examples within a cluster are similar – examples in different clusters are different Summarize each cluster Sometimes -- assign new instances to the most similar cluster CSC 8520 Spring 2013. Paula Matuszek 48 Clustering Example . .. . . . . . . . . . . . . . Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt 3 Measures of Similarity • In order to do clustering we need some kind of measure of similarity. • This is basically our “critic” • Vector of values, depends on domain: – documents: bag of words, linguistic features – purchases: cost, purchaser data, item data – census data: most of what is collected • Cosine similarity CSC 8520 Spring 2013. Paula Matuszek 50 Cosine similarity measurement Cosine similarity is a measure of similarity between two vectors by measuring the cosine of the angle between them. The result of the Cosine function is equal to 1 when the angle is 0, and it is less than 1 when the angle is of any other value. As the angle between the vectors shortens, the cosine angle approaches 1, meaning that the two vectors are getting closer, meaning that the similarity of whatever is represented by the vectors increases. CSC 8520 Spring 2013. Paula Matuszek Based on home.iitk.ac.in/~mfelixor/Files/non-numeric-Clustering-seminar.pp 51 Clustering Algorithms Hierarchical – Bottom up – Top-down Flat – K means Probabilistic – Expectation Maximumization (E-M) CSC 8520 Spring 2013. Paula Matuszek 52 Hierarchical Agglomerative Clustering (HAC) Starts with all instances in a separate cluster and then repeatedly joins the two clusters that are most similar until there is only one cluster. The history of merging forms a binary tree or hierarchy. Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt CSC 8520 Spring 2013. Paula Matuszek 7 53 Dendogram: Hierarchical Clustering Clustering obtained by cutting the dendrogram at a desired level: each connected component forms a cluster. CSC 8520 Spring 2013. Paula Matuszek http://www.csee.umbc.edu/~nicholas/676/MRSslides/lecture17-clustering.ppt 54 Partitioning (Flat) Algorithms Partitioning method: Construct a partition of n documents into a set of K clusters Given: a set of documents and the number K Find: a partition of K clusters that optimizes the chosen partitioning criterion – Globally optimal: exhaustively enumerate all partitions. Usually too expensive. – Effective heuristic methods: K-means algorithm. http://www.csee.umbc.edu/~nicholas/676/MRSslides/lecture17-clustering.ppt CSC 8520 Spring 2013. Paula Matuszek 55 K-Means Clustering Typically provide number of desired clusters, k. Randomly choose k instances as seeds. Form initial clusters based on these seeds. Iterate, repeatedly reallocating instances to different clusters to improve the overall clustering. Stop when clustering converges or after a fixed number of iterations. Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt CSC 8520 Spring 2013. Paula Matuszek 18 56 K Means Example (K=2) Pick seeds Reassign clusters Compute centroids Reasssign clusters x x x x Compute centroids Reassign clusters Converged! Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt 22 K-Means • Tradeoff between having more clusters (better focus within each cluster) and having too many clusters. Overfitting again. • Results can vary based on random seed selection. – Some seeds can result in poor convergence rate, or convergence to sub-optimal clusterings. • The algorithm is sensitive to outliers – Data points that are far from other data points. – Could be errors in the data recording or some special data points with very different values. http://www.csee.umbc.edu/~nicholas/676/MRSslides/lecture17-clustering.ppt CSC 8520 Spring 2013. Paula Matuszek 58 Strengths of k-means • Strengths: – Simple: easy to understand and to implement – Efficient: Time complexity: O(tkn), • where n is the number of data points, • k is the number of clusters, and • t is the number of iterations. – Since both k and t are small. k-means is considered a linear algorithm. • K-means is most popular clustering algorithm. • In practice, performs well, especially on text. www.cs.uic.edu/~liub/teach/cs583-fall-05/CS583-unsupervised-learning.ppt CSC 8520 Spring 2013. Paula Matuszek 59 REALLY Unsupervised Learning • Turn the machine loose to learn on its own • Needs – A representation. Still need some idea of what we are trying to learn! – Good natural language processing – A context • People don’t learn very well unsupervised. • Currently some interesting research for instancelevel knowledge. • Much harder to acquire structural or relational knowledge – but we are getting there. CSC 8520 Spring 2013. Paula Matuszek 60 More Aspects of Machine Learning • Machine learning varies by degree of human intervention: – Rote -- human builds KB. Cyc – Human assisted -- human adds knowledge directed by machine. Animals, Teiresias – Human scored -- human provides training cases. Neural nets, ID3, CART. – Completely automated. -- Nearest Neighbor, other clustering methods CSC 8520 Spring 2013. Paula Matuszek 61 More Aspects of Machine Learning • Machine Learning varies by degree of transparency – Hand-built KBs are by definition clear to humans – Human-aided trees like Animals are also generally clear and meaningful, could easily be modified by humans – Inferred rules like ID3's are generally understood by humans but may not be intuitively obvious. Modifying them by hand may lead to worse results. – Systems like SVMs are typically black box: you can look at the models but it's hard to interpret them in any humanmeaningful way and essentially impossible to modify them by hand. CSC 8520 Spring 2013. Paula Matuszek 62 More Aspects of Machine Learning • Machine learning varies by goal of the process – Extend a knowledge base – Improve some kind of decision making, such as guessing an animal or classifying diseases. – Improve overall performance of a program, such as game playing – Organize large amounts of data – Find patterns or "knowledge" not previously known, often to take some action. CSC 8520 Spring 2013. Paula Matuszek 63 The Web • Machine learning is one of those fields where the web is changing everything! • Three major factors – One problematic aspect of machine learning research is finding enough data. • This is NOT an issue on the web! – Another problematic aspect is getting a critic • Web offers a lot of opportunities – A third is identifying good practical uses for machine learning • Lots of online opportunities here CSC 8520 Spring 2013. Paula Matuszek 64 Online Uses for Machine Learning • Improved search: learn from click-throughs. • Recommendations: learn from peoples’ opinions and choices. • Online games. AIs add to the background but can’t be too static. • Better targeting for ads. More learning from clickthroughs. • Customer Response Centers. Clustering, improved retrieval of responses. CSC 8520 Spring 2013. Paula Matuszek 65 Summary • Valuable both because we want to understand how humans learn and because it improves computer systems • May learn representation or actions or both • Variety of methods, some knowledge-based and some statistical • Currently very active research area • Web is providing a lot of new opportunities • Still a long way to go CSC 8520 Spring 2013. Paula Matuszek 66