Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
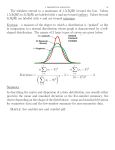
Lecture 2 STAT 211 – 019 Dan Piett West Virginia University Last Lecture Population/Sample Variable Types Discrete/Continuous Numeric & Ranked/Unranked Categorical Displaying Small Sets of Numbers Dot Plots, Stem and Leaf, Pie Charts Histograms Frequency/Density and Symmetric vs Right/Left Skewed Measures of Center Mean/Median Overview 2.3 Measures of Dispersion 2.5 Boxplots 3.1 Scatterplots 3.2 Correlation 3.3 Regression Section 2.3 Measures of Dispersion Descriptive Statistics Describing the Data How do we describe data? Graphs (Last Class) Measures Center (Last Class) Mean/Median Dispersion/Spread (This Class) Variance, Standard Deviation, IQR Spread of Data Example: Spread Data 1: 8, 8, 9, 9, 10, 11, 11, 12, 12 Data 2: -30, -20, -10, 0, 10, 20, 30, 40 ,50 Data 1 – Mean = Median = 10 Data 2 – Mean = Median = 10 Both have the same measure of center but how do they differ? Data 2 is much more spread out. Sample Standard Deviation Sample Standard Deviation (S) is a measure of how spread out the data is S can be any number >= 0 Larger S indicates a larger spread Unit Associated with S is the same unit as the variable Example: Mean of 110 lb, Standard Deviation 10 lb The square of the sample standard deviation is called the sample variance Standard Deviation Example Data 1 (8, 8, 9, 9, 10, 11, 11, 12, 12) S = 1.58 Data 2 (-30, -20, -10, 0, 10, 20, 30, 40 ,50) S = 27.39 As you can see, the standard deviation of Data 2 is much larger than Data 1. Population Variance/Standard Deviation Much like the sample mean (xbar) estimates the population mean (mu), the sample variance/standard deviation (s) can be used to estimate the true population standard deviation (sigma) Linear Transformations and Changes of Scale By adding or subtracting a constant to every value in a data set The mean is increased/decreased by the same amount The median is increased/decreased by the same amount The standard deviation is unchanged By multiplying each value by a constant The mean is multiplied by the same amount The median is multiplied by the same amount The standard deviation is multiplied by the same amount Section 2.5 Boxplots Quartiles Quartiles are numbers which partition the data into 4 subgroups (ie 4 quarters in a dollar) Q1 The data separating lowest 25% of the data values Q2 aka. Median The data separating the lowest 50% of the data values Q3 The data separating the lowest 75% of the data values Q4 aka. Maximum The largest data value Quartiles Example You can think of Q1 as the median of the bottom half of the data and Q3 as the median of the top half of the data Interquartile Range (IQR) The IQR is another measure of spread, much like S. Larger IQR results in more spread data IQR is calculated as Q3 - Q1 Example Data 1 (8, 8, 9, 9, 10, 11, 11, 12, 12) IQR = 11.5-8.5=3 Data 2 (-30, -20, -10, 0, 10, 20, 30, 40 ,50) IQR = 35-(-15) = 50 Boxplots Boxplots are a graphical representation of the quartiles. Using IQR to Find Potential Outliers One method to find potential outliers is as follows: Find the IQR 2. Add 1.5*IQR to Q3 1. Anything larger than this value can be flagged as a potential outlier 3. Likewise, subtract 1.5*IQR from Q1 Anything smaller than this value can be flagged as a potential outlier Example Data 1 (8, 8, 9, 9, 10, 11, 11, 12, 12) Data 2 (-30, -20, -10, 0, 10, 20, 30, 40 ,50) Section 3.1 Scatterplots Bivariate Data Bivariate data is data consisting of two variables from the same individual Examples Height and Weight Classes skipped and GPA Graphed using a scatterplot Scatterplot Example Section 3.2 Correlation Pearson Correlation Coefficient We have discussed ways to describe data of one variable. This section will discuss how to describe two variables on the same individual together. The correlation coefficient, r, is a measure of the strength of a linear (straight line) relationship between bivariate data. (You will not need to know the formula for r) To say two variables are correlated is two say that an increase/decrease in one corresponds to an increase/decrease in the other. More on r r can take on values between -1 and 1 The strength of the correlation depends on how close you are to the extreme values of -1 or 1 r = -.78 is a stronger correlation than r = .50 There are three types of correlation Positive Negative No Correlation Positive Correlation Positive Correlation exists when r is between 0 and 1. The closer r is to 1, the stronger the relationship This implies that if you increase one of the variables, the other one will also increase. Examples: Height and Weight, Temperature and Ice Cream Sales Negative Correlation Positive Correlation exists when r is between -1 and 0. The closer r is to -1, the stronger the relationship This implies that if you increase one of the variables, the other one will decrease. Example: Temperature and Hot Chocolate Sales No Correlation No Correlation exists when r is approximately 0 This implies that if you increase one of the variables the other one does not change Example: Temperature and Cookie Sales Interpretation of r Although we may find that two variables are correlated, this does not mean that there is necessarily a causal relationship. Example: High School Teachers who are paid less tend to have students who do better on the SATs than Teachers who are paid more. It has been found that there is a negative correlation between teacher salary and students SAT scores. Therefore we should pay our teachers less so students score higher. Clearly this is not a causal relationship. There is likely a third variable, that is explaining this. One possibility may be the age of the teacher. Section 3.3 Regression Regression Intro So we have decided that two variables are correlated, we are now going to use the value of one of the variables, “x”, to predict the value of the other variable, “y”. Example: Use height (x) to predict weight (y) Use temperature (x) to predict ice cream sales (y) Regression Equation Calculating a Regression Equation Given the slope and intercept Plotting a Regression Line Notes on Regression Lines Residuals A residual is the distance between a point (observed y-value) and the regression line (predicted y-value) Formula: Observed Value – Predicted Value Using the Cholesterol Example: For TV Hours = 3, our predicted value was 212.2 The actual value on the graph is 220. The residual for this particular point is = 220-212.2=7.8 A residual may be positive or negative The interpretation is that the observed y-value is 7.8 units larger than the predicted y value for TV Hours = 3