Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
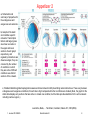
Bioinformatics III “Systems biology” “Cellular networks” “Computational cell biology” Course will teach mathematical methods that are applied from protein complexes to interaction networks 1. Lecture WS 2008/09 Bioinformatics III 1 Organization of biological cells 1. Lecture WS 2008/09 Bioinformatics III 2 Organization of biological cells (Top) since the 1950ies, a paradigm became established that information flows from DNA over RNA to protein synthesis which then gives rise to particular phenotypes. (Middle) The upcome of structural biology - the first crystal structure of the protein Myoglobin was determined in 1960 - emphasized the importance of the three-dimensional structures of proteins determining their function. (Bottom) Today, we have realized the central role played by molecular interactions that influence all other elements. 1. Lecture WS 2008/09 Bioinformatics III 3 Organization of transcriptional regulatory networks (left) The 'basic unit' comprises the transcription factor, its target gene with DNA recognition site and the regulatory interaction between them. (middle) Units are often organized into network 'motifs' which comprise specific patterns of inter-regulation that are over-represented in networks. Examples of motifs include single input multiple output (SIM), multiple input multiple output (MIM), and feed-forward loop (FFL) motifs. (right) Network motifs can be interconnected to form semi-independent 'modules' many of which have been identified by integrating regulatory interaction data with gene expression data, and imposing evolutionary conservation. The next level consists of the entire network (not shown). 1. Lecture WS 2008/09 Bioinformatics III 4 Major metabolic pathways 1. Lecture WS 2008/09 Bioinformatics III 5 Content (ca.) Protein interaction networks: - different topologies (random networks, scale-free networks) - intro of protein complexes: exp. data - computational analysis (mathematical graphs) - graphical layout (force minimization) - quality check (Bayesian analysis) - modularity - network flow Transcriptional regulatory networks, motifs Signal transduction networks Metabolic networks: metabolic flux analysis, extreme pathways, elementary modes FFT protein-protein docking, fitting into EM maps, tomography integration of interactome and regulome (Lichtenberg), integration of protein networks with metabolic pathways 1. Lecture WS 2008/09 Bioinformatics III 6 Appetizer 1 Cell cycle proteins that are part of complexes or other physical interactions are shown within the circle. For the dynamic proteins, the time of peak expression is shown by the node color; static proteins are represented as white nodes. Outside the circle, the dynamic proteins without interactions are positioned and colored according to their peak time. Lichtenberg et al. Science 307, 724 (2005) 1. Lecture WS 2008/09 Bioinformatics III 7 Appetizer 2 a, Schematics and summary of properties for the endogenous and exogenous sub-networks. b, Graphs of the static and condition-specific networks. Transcription factors and target genes are shown as nodes in the upper and lower sections of each graph respectively, and regulatory interactions are drawn as edges; they are coloured by the number of conditions in which they are active. Different conditions use distinct sections of the network. c, Standard statistics (global topological measures and local network motifs) describing network structures. These vary between endogenous and exogenous conditions; those that are high compared with other conditions are shaded. (Note, the graph for the static state displays only sections that are active in at least one condition, but the table provides statistics for the entire network including inactive regions.) Luscombe, Babu, … Teichmann, Gerstein, Nature 431, 308 (2004) 1. Lecture WS 2008/09 Bioinformatics III 8 Mathematical techniques covered Mathematical graphs – classification of protein-protein interaction networks, – algorithms on graphs – regulatory networks Bayesian networks – protein interaction networks Boolean networks – transcriptional networks Fourier transformation – protein/protein-docking, pattern matching Linear and convex algebra – metabolic networks Ordinary and stochastic differential equations – kinetic modelling of signal transduction pathways 1. Lecture WS 2008/09 Bioinformatics III 9 Literature lecture slides are available already; final version 3 days before lecture suggested reading: links will be put up on course website http://gepard.bioinformatik.uni-saarland.de/teaching... Text books €55,- €37,- (Amazon) €54,- All 3 books are available in the computer science library! 1. Lecture WS 2008/09 Bioinformatics III 10 assignments 10 weekly assignments planned Homework assignments are handed out in the Thursday lectures and are available on the course website on the same day. Homework will include many programming assignments. You can program in any popular programming language. We recommend powerful script languages such as Phython or Perl that allow to solve problems efficiently. Solutions need to be returned until Thursday of the following week 14.00 to Peter Walter in room 0.11 Geb. C 7 1, ground floor, or handed in prior (!) to the lecture starting at 14.15. 2 students may submit one joint solution. Also possible: submit solution by e-mail as 1 printable PDF-file to [email protected]. Tutorial: participation is recommended but not mandatory. Date: Wed 14-16 ? Homeworks submitted on Thursdays will be discussed on the following Wednesday. Each student needs to present his solution to one of the assignments on the blackboard once in the tutorial session. 1. Lecture WS 2008/09 Bioinformatics III 11 tests 4 tests are planned on: Nov. 11, Dec. 9, Jan. 13, Feb. 10 Each will last 45 minutes. Tests will cover the material from the lectures since the start of the lecture or since the last test. You need to pass 3 out of 4 tests. The grade for the tests will be computed from the best 3 tests. If you miss one of the tests for a medical reason, please provide a medical certificate. You will be given a chance for an oral exam on the same subject. If you have passed only 2 tests, you may choose one of the failed or missing tests for an oral re-exam. If you have only passed 1 test, you have failed the class. 1. Lecture WS 2008/09 Bioinformatics III 12 Schein = successful written exam The successful participation in the lecture course („Schein“) will be certified upon successful completion of the written exam that will take place on Feb. 20, 2009, 10 – 12 am. Participation at the exam is open to those students who have - received 50% of credit points for the assignments and - presented once during the tutorials and - have passed 3 tests. The final mark of the „Schein“ will be the average of the 3 best test results (50%) and of your result in the final exam (50%). The final exam will take 120 min and only cover the material of the assignments. In case of illness please send E-mail to: [email protected] and provide a medical certificate. A „second and final chance“ exam will be offered in April 2009. 1. Lecture WS 2008/09 Bioinformatics III 13 tutors Peter Walter, Sikander Hayat – assignments Geb. C 7 1, room 0.11 [email protected] 1. Lecture WS 2008/09 Bioinformatics III 14 Systems biology Biological research in the 1900s followed a reductionist approach: detect unusual phenotype isolate/purify 1 protein/gene, determine its function However, it is increasingly clear that discrete biological function can only rarely be attributed to an individual molecule. new task of understanding the structure and dynamics of the complex intercellular web of interactions that contribute to the structure and function of a living cell. 1. Lecture WS 2008/09 Bioinformatics III 15 Systems biology Development of high-throughput data-collection techniques, e.g. microarrays, protein chips, yeast two-hybrid screens allow to simultaneously interrogate all cell components at any given time. there exists various types of interaction webs/networks - protein-protein interaction network - metabolic network - signalling network - transcription/regulatory network ... These networks are not independent but form „network of networks“. 1. Lecture WS 2008/09 Bioinformatics III 16 DOE initiative: Genomes to Life a coordinated effort slides borrowed from talk of Marvin Frazier Life Sciences Division U.S. Dept of Energy 1. Lecture WS 2008/09 Bioinformatics III 17 Facility I Production and Characterization of Proteins Estimating Microbial Genome Capability • Computational Analysis – Genome analysis of genes, proteins, and operons – Metabolic pathways analysis from reference data – Protein machines estimate from PM reference data • Knowledge Captured – Initial annotation of genome – Initial perceptions of pathways and processes – Recognized machines, function, and homology – Novel proteins/machines (including prioritization) – Production conditions and experience 1. Lecture WS 2008/09 Bioinformatics III 18 Facility II Whole Proteome Analysis Modeling Proteome Expression, Regulation, and Pathways • Analysis and Modeling – Mass spectrometry expression analysis – Metabolic and regulatory pathway/ network analysis and modeling • Knowledge Captured – Expression data and conditions – Novel pathways and processes – Functional inferences about novel proteins/machines – Genome super annotation: regulation, function, and processes (deep knowledge about cellular subsystems) 1. Lecture WS 2008/09 Bioinformatics III 19 Facility III Characterization and Imaging of Molecular Machines Exploring Molecular Machine Geometry and Dynamics • Computational Analysis, Modeling and Simulation – Image analysis/cryoelectron microscopy – Protein interaction analysis/mass spec – Machine geometry and docking modeling – Machine biophysical dynamic simulation • Knowledge Captured – Machine composition, organization, geometry, assembly and disassembly – Component docking and dynamic simulations of machines 1. Lecture WS 2008/09 Bioinformatics III 20 Facility IV Analysis and Modeling of Cellular Systems Simulating Cell and Community Dynamics • • Analysis, Modeling and Simulation – Couple knowledge of pathways, networks, and machines to generate an understanding of cellular and multi-cellular systems – Metabolism, regulation, and machine simulation – Cell and multicell modeling and flux visualization Knowledge Captured – Cell and community measurement data sets – Protein machine assembly time-course data sets – Dynamic models and simulations of cell processes 1. Lecture WS 2008/09 Bioinformatics III 21 Computing and Information Infrastructure Capabilities “Genomes To Life” Computing Roadmap Protein machine Interactions Molecule-based cell simulation Molecular machine classical simulation Cell, pathway, and network simulation Community metabolic regulatory, signaling simulations Constrained rigid docking Constraint-Based Flexible Docking Current U.S. Computing Genome-scale protein threading Comparative Genomics Biological Complexity 1. Lecture WS 2008/09 Bioinformatics III 22 Are biological networks special? Statistical physics: tries to finding universal scaling laws of systems, e.g. how does the dynamics of a glass change when you lower the temperature? Phase-transition „critical slowing down“. „Relaxtion times in spin-glasses or glasses are observed to grow to such an extent at low temperatures that these systems do not reach thermal equilibrium on experimentally accessible timescales. Properties of such systems are then often found to depend on their history of preparation; such systems are said to age. Similar observations are made in coarsening dynamics at first order phase transitions. Some properties of spin-glasses and glasses must therefore be studied via dynamical approaches which allow taking possible history dependence explicitly into account.“ 1. Lecture WS 2008/09 Bioinformatics III Albert-Laszlo Barabasi 23 Power laws A power law relationship between two scalar quantities x and y is any such that the k relationship can be written as y ax where a (the constant of proportionality) and k (the exponent of the power law) are constants. Power laws can be seen as a straight line on a log-log graph since, taking logs on both sides, the above equation is equal to log y log( ax k ) which has the same form as the equation for a line k log x log a y mx c Power laws are observed in many fields, including physics, biology, geography, sociology, economics, and war and terrorism. They are among the most frequent scaling laws that describe the scaling invariance found in many natural phenomena. www.wikipedia.org 1. Lecture WS 2008/09 Bioinformatics III 24 Degree The most elementary characteristic of a node is its degree (or connectivity), k. It is defined as the number of links between this node and other nodes. a In the undirected network, node A has k = 5. b In networks in which each link has a selected direction there is an incoming degree, kin, which denotes the number of links that point to a node, and an outgoing degree, kout, which denotes the number of links that start from it. E.g., node A in b has kin = 4 and kout = 1. An undirected network with N nodes and L links is characterized by an average degree <k> = 2L/N (where <> denotes the average). Barabasi & Oltvai, Nature Reviews Genetics 5, 101 (2004) 1. Lecture WS 2008/09 Bioinformatics III 25 Degree distribution The degree distribution, P(k), gives the probability that a selected node has exactly k links. P(k) is obtained by counting the number of nodes N(k) with k = 1,2... links and dividing by the total number of nodes N. The degree distribution allows us to distinguish between different classes of networks. Barabasi & Oltvai, Nature Reviews Genetics 5, 101 (2004) 1. Lecture WS 2008/09 Bioinformatics III 26 Clustering coefficient In many networks, if node A is connected to B, and B is connected to C, then it is highly probable that A also has a direct link to C. This phenomenon can be quantified using the clustering coefficient Cl 2nl k k 1 where nI is the number of links connecting the kI neighbours of node I to each other. In other words, CI gives the number of 'triangles' that go through node I, whereas kI (kI -1)/2 is the total number of triangles that could pass through node I, should all of node I's neighbours be connected to each other. Barabasi & Oltvai, Nature Reviews Genetics 5, 101 (2004) 1. Lecture WS 2008/09 Bioinformatics III 27 Clustering coefficient a Only 1 pair of node A's 5 neighbours are linked together (B and C), which gives nA = 1 and CA = 2/20. By contrast, none of node F's neighbours link to each other, giving CF = 0. The average clustering coefficient, <C >, characterizes the overall tendency of nodes to form clusters. An important measure of the network's structure is the function C(k), which is defined as the average clustering coefficient of all nodes with k links. For many real networks C(k) k-1, which is an indication of a network's hierarchical character. The average degree <k>, average path length <ℓ> and average clustering coefficient <C> depend on the number of nodes and links (N and L) in the network. By contrast, the P(k) and C(k ) functions are independent of the network's size and they therefore capture a network's generic features, which allows them to be used to classify various networks. Barabasi & Oltvai, Nature Reviews Genetics 5, 101 (2004) 1. Lecture WS 2008/09 Bioinformatics III 28 Random networks Aa The Erdös–Rényi (ER) model of a random network starts with N nodes and connects each pair of nodes with probability p, which creates a graph with approximately pN (N-1)/2 randomly placed links. Ab The node degrees follow a Poisson distribution, where most nodes have approximately the same number of links (close to the average degree <k>). The tail (high k region) of the degree distribution P(k ) decreases exponentially, which indicates that nodes that significantly deviate from the average are extremely rare. Ac The clustering coefficient is independent of a node's degree, so C(k) appears as a horizontal line if plotted as a function of k. The mean path length is proportional to the logarithm of the network size, log N, which indicates that it is characterized by the small-world property. Barabasi & Oltvai, Nature Rev Gen 5, 101 (2004) 1. Lecture WS 2008/09 Bioinformatics III 29 Scale-free networks Scale-free networks are characterized by a power-law degree distribution; the probability that a node has k links follows P(k) ~ k- -, where is the degree exponent. The probability that a node is highly connected is statistically more significant than in a random graph, the network's properties often being determined by a relatively small number of highly connected nodes („hubs“, see blue nodes in Ba). In the Barabási–Albert model of a scale-free network, at each time point a node with M links is added to the network, it connects to an already existing node I with probability I = kI/JkJ, where kI is the degree of node I and J is the index denoting the sum over network nodes. The network that is generated by this growth process has a power-law degree distribution with = 3. Barabasi & Oltvai, Nature Reviews Genetics 5, 101 (2004) 1. Lecture WS 2008/09 Bioinformatics III 30 Scale-free networks (Bb) Power-law distributions are seen as a straight line on a log–log plot. (Bc) The network that is created by the Barabási– Albert model does not have an inherent modularity, so C(k) is independent of k. Scale-free networks with degree exponents 2< <3, a range that is observed in most biological and nonbiological networks, are ultra-small, with the average path length following ℓ ~ log log N, which is significantly shorter than log N that characterizes random small-world networks. Barabasi & Oltvai, Nature Reviews Genetics 5, 101 (2004) 1. Lecture WS 2008/09 Bioinformatics III 31 Importance of the degree exponent The value of in P(k) k - determines many properties of the system. The smaller the value of , the more important the role of the hubs is in the network. In general, the unusual properties of scale-free networks are valid only for < 3. For 2> >3 there is a hierarchy of hubs, with the most connected hub being in contact with a small fraction of all nodes. For = 2 a hub-and-spoke network emerges, with the largest hub being in contact with a large fraction of all nodes. Here, the dispersion of the P(k) distribution, defined as 2 = <k2> - <k>2, increases with the number of nodes (that is, diverges), resulting in a series of unexpected features, such as a high degree of robustness against accidental node failures. For >3, the hubs are not relevant, most unusual features are absent, and in many respects the scale-free network behaves like a random one. Barabasi & Oltvai, Nature Reviews Genetics 5, 101 (2004) 1. Lecture WS 2008/09 Bioinformatics III 32 Shortest path and mean path length The distance in networks is measured by the path length, which tells us how many links we need to pass through to travel between two nodes. As there are many alternative paths between two nodes, the shortest path — the path with the smallest number of links between the selected nodes — has a special role. In directed networks, the distance ℓAB from node A to node B is often different from the distance ℓBA from B to A. E.g. in b , ℓBA = 1, whereas ℓAB = 3. Often there is no direct path between two nodes. As shown in b, although there is a path from C to A, there is no path from A to C. The mean path length, <ℓ>, represents the average over the shortest paths between all pairs of nodes and offers a measure of a network's overall navigability. Barabasi & Oltvai, Nature Reviews Genetics 5, 101 (2004) 1. Lecture WS 2008/09 Bioinformatics III 33 First breakthrough: scale-free metabolic networks (d) The degree distribution, P(k), of the metabolic network illustrates its scale-free topology. (e) The scaling of the clustering coefficient C(k) with the degree k illustrates the hierarchical architecture of metabolism (The data shown in d and e represent an average over 43 organisms). (f) The flux distribution in the central metabolism of Escherichia coli follows a power law, which indicates that most reactions have small metabolic flux, whereas a few reactions, with high fluxes, carry most of the metabolic activity. Barabasi & Oltvai, Nature Reviews Genetics 5, 101 (2004) 1. Lecture WS 2008/09 Bioinformatics III 34 Second breakthrough: Yeast protein interaction network: first example of a scale-free network A map of protein–protein interactions in Saccharomyces cerevisiae, which is based on early yeast two-hybrid measurements, illustrates that a few highly connected nodes (which are also known as hubs) hold the network together. The largest cluster, which contains 78% of all proteins, is shown. The colour of a node indicates the phenotypic effect of removing the corresponding protein (red = lethal, green = non-lethal, orange = slow growth, yellow = unknown). Barabasi & Oltvai, Nature Rev Gen 5, 101 (2004) 1. Lecture WS 2008/09 Bioinformatics III 35 Summary Many cellular networks show properties of scale-free networks - protein-protein interaction networks - metabolic networks - genetic regulatory networks (where nodes are individual genes and links are derived from expression correlation e.g. by microarray data) - protein domain networks However, not all cellular networks are scale-free. E.g. the transcription regulatory networks of S. cerevisae and E.coli are examples of mixed scale-free and exponential characteristics. It is a topic of ongoing debate whether the analysis of subnetworks (available data is sparse) allows conclusions on the underlying topology of the entire network. Next lecture: - mathematical properties of networks - origin of scale-free topology - topological robustness Barabasi & Oltvai, Nature Rev Gen 5, 101 (2004) 1. Lecture WS 2008/09 Bioinformatics III 36