Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
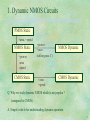
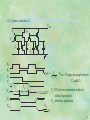
5 CMOS Logic Basics(1)-combinational logic Contents 1. Dynamic NMOS logic 2. Pseudo NMOS logic Transistor sizing Complex logic gate layout 3. Static(complementary) CMOS logic Inverter, NAND, NOR gates layout 4. Pass transistor logic 5. BiCMOS logic 6. Dynamic CMOS logic 5.1 1. Dynamic NMOS Circuits PMOS Static +area, +speed NMOS Static +power -area -speed CMOS Static +power +area (utilize para. C) +area +speed NMOS Dynamic CMOS Dynamic Q. Why we study dynamic NMOS which is not popular ? (compared to CMOS) A. Simple vehicle for understanding dynamic operation. 5.2 i) 2 phase, ratioed type VDD 2 1 2 1 2 Vi C1 1 V2 i VC1 VC2 VC3 C2 C3 Low level is determined from inverter ratio demands large chip area! 5.3 ii) 2 phase, ratioless A 1 VDD 2 Vi C2 C1 C4 C3 1 2 DV = C3 VDD : Charge sharing between C2+C3 C2 and C3 Vi VC1 VC2 Ta Tb VL Ta: DC power consmption due to ratioed operation Tb: ratioless operation DV VC3 VC4 VL O 5.4 iii) 2 phase ratioless B VDD 1 2 C2 T1 Vi C1 C3 C4 Vi가 high이고 1이 on 일때 VDD-GND DC경로를 표 한 T1이 차단 DV C 3 C 4 V C 2 C 3 C 4 DD Charge Sharing에 의한 전압강하 C기생성분의 증가로 CV2f(dynamic 전력소모) 증가 5.5 iv) 2 phase ratioless C 1 2 No DC path extremely large CV2f dissipation and large clock driver simple layout Vi 1 2 5.6 v) 4 phase ratioless A 1 2 2 3 1 Type 2 1 2 3 4 3 4 2 Type 3 4 1 3 Type 4 4 Type 1 Type 1 2 3 4 1 2 3 4 E P H H H E P H H H E P P H H E E : evaluate P : precharge H : hold 5.7 vi) 4 phase ratioless B 1 2 1 2 T1 x 2 3 12 23 y 1 2 1 2 장 * same as 5. except T1 which prevents charge sharing between x and y improves noise immunity 5.8 2. Pseudo NMOS logic A kind of ratioed logic as R-load, depletion-load. No body effect VDD IL grounded-gate PMOS is close to constant current source load pseudo NMOS const. I src IL depl. Vo PDN VOL is given by R Load line curve 2 kp VOL 2 k n (VDD VTn )VOL ( V V ) DD Tp 2 2 VOL enh. Vo Kp , assuming VT VTn VTp (V DD VT )1 1 Kn 5.9 Pseudo-NMOS vs. Complementary CMOS (Pros.) of Pseudo -NMOS 1. Smaller number of transistors less area, less capacitive loading to preceding gate (Cons.) 1. Power consumption due to DC current path: Pav (low) VDD I low kp 2 VDD (VDD VT ) 2 low NML( i.e., high low-output VOL=ILRPDN) (Comments) Pseudo-NMOS is desirable for applications where speed is of major importance, or where we know that the majority of outputs are high, such as address decoder in memory 5.10 Design constraints of pseudo-NMOS 1. Power consumption : to reduce static power 2. noise margin: to obtain reasonably high NML, VOL=ILRPDN should be low. 3. output rise time 4. output fall time RPU large 1. Power consumption 2. Noise margin RPDN small 3. Rise time 4. Fall time RPU small : contradictory 5.11 Answer to Question Q1. How do we consider capacitance to VDD ? A1. Capacitance to VDD and all other DC nodes are lumped as capacitance to ground. Charge variation on node x due to DVX DQX = C G N D [(V x DV x )V x ] C VD D [(V X DV x V D D ) (V x V D D )] = C G N D DV x C VD D DV x = VDD (C G N D C VD D ) DV x C eff C G N D C VD D x Ceff 5.12 Q2. Name a circuit where capacitance ratio, not value, determines the behaviour. A2. Switched-capacitor filter i V1 V2 i f f C1 C2 V1 V2 v1 V 2 1 i fc (V1 V 2 ) R R fc F (S ) 1 SRC 2 fC 1 SC 2 e-ratio 5.13 Variations of pseudo-NMOS i) parallel large adaptive PMOS load In pseudo-NMOS tPLH tends to be rather high to make VOL low enough(i.e., NML high enough). In standby, large PMOS pull-up, M1 is off, which is turned on after an address translation is detected to result in large current drive. 5.14 Ex.) Pseudo-NMOS layout example(4-input NAND) (W/L)NMOS = 1.8/1.2 (W/L)PMOS = 1.8/4.8 5.15 Istatic = 48.5A, VOH = 5V, VOL = 0.48V VM = 1.62V, NMH = 3.26V, NML= 0.27V tpHL = 0.6nsec, tpLH = 2.37nsec Trying to make PMOS longer to increase NML yields even worse tpLH, which is already large. If we change to (W/L)NMOS = 7.2/1.2, (W/L)PMOS = 1.8/1.2, Istatic 0.18mA, tpHL 0.24ns, tpLH 1.4ns 5.16 ii) CMOS Multi-drain Logic This idea came from I2L(Integrated-Injection Logic). Low energy due to low switching voltage NOR-type logic only Q i n n p I I p Q i 5.17 Z=A+B A B Q. Why is I2L not used much ? A. 1) efficiency of PNP current source 2) CMOS is better in area, power, speed 5.18 A Z=A+B B A+B Fanout limited by NML 5.19 iii) Ganged CMOS logic A B C Z NOR gate ; Z = A+B+C Can be operated as NAND gate by suitably ratioing PMOS over NMOS. Can be operated as quarternary logic 5.20 iv) Cascode Logic(1) : CVSL Q CVSL(Cascode Voltage Switch Logic) or DCVSL(Differential Cascode Voltage Switch Logic) Q Q Q a a b ... ... b a b c c CVSL : requires dual signal rail ratioed logic(DC path exists) large current spike during switching regenerative feedback fast(?) 5.21 Common factor sharing between Out and Out 5.22 (Another example for sharing) Q abcd 5.23 Dynamic CVSL 5.24 SSDL(Sample-Set Differential Logic) : modified version of dynamic CVSL during clk low ; one at VDD, the other at slightly below VDD during clk high : set to VDD & VSS quickly 5.25 v) Cascode Logic(II) : DSLL(Differential Split Level Logic) replaces p-load in pseudo-NMOS with cross-coupled cascoded n-and PMOS out out VDD VTN set VR 2 VD D I N : VX VTN , when 2 IN :0 V VDD , when IN VX VD D 0 , IN : 2 PMOS, NMOS의 size를 이 조건에 맞도록 정한다. VR in in 5.26 A t1 P1 in t3 n1 P3 out P4 out C1 in t2 n2 P2 A VR C2 VR V DD ( ) 일때 in : low(0V), in : high 2 P2 is fully ON, A is pulled to VDD, C2 is discharged P1 is not fully OFF, A is at 0.5-0.6V(just below VTN of n1) V C1 is charged to D D via t3, P3 2 VD D Switch in to and in to 0V. 2 P1 turns on very fast( VDD, A A t2 turns on very fast( it wasn’t completely OFF) it was just under threshold) 0.5-0.6V 5.27 Size of PMOS is set indep. of pull-down NMOS, as they are decoupled by cascode NMOS. Therefore, charging through PMOS is faster than in pseudo-NMOS. Repartitioning the gate to open-drain structure, where input and output resides in(0, VD D 2 ), this improving speed. ( Voltage swing in large C is reduced.) 5.28 iv) SPFL(Source Follower Pull-uP Logic) extensive use of NMOS over slower PMOS utilizing parallel connection over slower series connection good for NOR gate P1 is turned off by anyone of N1-N4, connected as paralled source follower, turned on suffers from body effect and degraded VH in the internal node(Nload). 5.29 3. Static(Complementary) CMOS inverter layout PMOS drain(p-diffusion) and NMOS drain(n-diffusion) can be connected via metal strap and contacts. Power and ground are run in metal and connected to the sources of PMOS & NMOS. 5.30 Various layout styles of inverter 5.31 Various layout styles of large-W/L inverter(driver) 5.32 Static CMOS NAND gate default : horizonal PWR, GND/vertical polysilicon gate 5.33 Static CMOS NOR gate (b) is faster than (a) Why ? 5.34 Transistor sizing for 8-input NAND gate Delay(ns) (before/after sizing) area(before/after sizing) Appr. 1 2.82 + 3.37 = 6.2 4.6 216 120 Appr. 2 0.88 + 4.36 = 5.24 4.8 216 136 Appr. 3 0.31+0.4+0.31+2.17=3.193.5 360 124 5.35 Complex gate layout i) Linear Array Think of an AOI(And-OR-Invert) cell : f = X X X X X 1 2 3 4 5 1 2 3 4 5 VDD f f In static CMOS circuit 5.36 Since each P-N pair(sharing the same input) is represented by P-MOS poly-Si Symbolize by N-MOS a’ a active area contact aluminum N N P-well 5.37 VDD Symbolic Layout of AOI gate 1 2 3 4 5 VDD 1 2 3 4 5 out VSS 3 5 2 4 1 (Layout ‘a’) VSS Noting that 5.38 Layout ‘a’ can be simplified 1 VDD 2 3 4 5 VDD P N 1 out 2 3 VSS out 4 5 VSS out (Layout ‘b’) If we interchange 2 and 3 Observation : 1-3-2-4-5 is and Euler path for N-graph. But not for P-graph. VDD out VSS 1 3 2 (Layout ‘c’) 4 Ques. How to find a sequence which is an Euler path for both P-and N-graph. 5 5.39 Ans. Sequence 2-3-1-4-5- is it! VDD 2 Ques. How do we find it consistently? 3 1 2 3 1 4 4 out 5 3 out 5 1 5 2 (a) 4 VSS (b) VDD 2 VSS 3 2 3 1 4 5 VDD out out 1 4 P-part N-part 5 VSS (Layout ‘d’) 5.40 Euler path methold 2 2 3 1 4 5 3 1 4 5 2 2 3 2 3 5 4 Stretch 3 5 2 3 1 1 Split contact 4 1 4 4 5 5 (rubber band) 5.41 1. Find all Euler paths that cover the graph. 2. Find a p- and an n-Euler path that have identical labeling(a labeling is an ordering of the gate labels on each vertex). 3. If the paths in step 2 are not found, then break the gate in the minimum number of places to achieve step 2 by separate Euler paths. 5.42 관찰 1) Euler path가 존재하면 그 path에 포함된 모든 edge에 대응하는 gate는 diffusion 영역을 공유하면서 연결된다. 관찰 2) 전체 edge를 지나는 Euler path가 존재하지 않으면 전체 graph 를 Euler path를 갖는 subgraph로 분할한다.(여기서 모든 Euler path는 p-와 N-graph 모두에게 존재하는 것을 뜻한다.) 이때, 각 subgraph는 layout에서 각 diffusion island(혹은, interlace)를 형성하고, 각 interlace 사이에는 gap이 있다. 관찰 3) Reduction of graph ; 홀수개의 edge로 된 series, 혹은 parallel graph는 single edge로 줄여서 Euler path를 찾은 후, 원래 graph 상의 Euler path로 복원시킬 수 있다. 관찰 4) make the # of inputs to all gates to be odd, by inserting dummy input, so that E-graph can always be found. 5.43 Graph reduction fro finding Euler path (복원 2) (복원 1) (축약 1) example. 1 2 3 4 5 6 7 (축약 2) , 8 10 9 5.44 Graph model reduction phase (축약 2) (축약 1) E-path reconstruction 1 1 4 3 2 (복원 1) (복원 2) 10 8 5 7 9 6 5.45 Appending pseudo input ex. 1 P1 2 3 P2 4 5 8 P1, P2 : pseudo input 10 9 Heuristic algorithm ; 1. Add pseudo-input to every gate with an even number of inputs. 2. Rearrange the input sequence such that # of interlaces between real and pseudo inputs is minimal. Top and bottom pseudo inputs does not contribute to separation areas. P1 2 3 P1 2 3 1 4 5 P2 8 1 10 9 4 5 P2 5.46 Minimal Interlace Algorithm White ; pseudo input Black ; real input White & Black ; gate with both pseudo and real input 5.47 When a signal is applied to multiple transistors. ex) CMOS XNOR gate 5.48 ii) Gate Matrix 5.49 Gate Matrix layout algorithm Transistors are grouped in strips to allow maximum source/drain connection by abutment. To achieve better grouping, polysilicon columns are allowed to interchange to increase abutment. The resultant groups are then placed in rows with groups maximally connected to the VSS and VDD rails placed toward these signals. Row placement is then based on the density of other connections. Routing is achieved by vertical diffusion or Manhattan(horizontal and vertical) metal routing. This normally would require a maze router. 5.50 4. Pass Transistor Logic (or Transmission Gate Logic) AND, OR function can be implemented using series- and parallelconnected switches. Other combinational logic: series and parallel connection General concept example A Out Switch Network X B necessary for grounding X when B=0 MOSFET is a “switch”, but with some nonideality, i.e. finite threshold voltage(+body effect), and conduction dependent on Vgs 5.51 Threshold loss problem C=5V A=5V B can be charged up to | VDD-VT |, where VT 1.5V due to body effect Moreover, charging B is very slow at the end due to reducing | VGS | B CL C=5V A=5V B M2 M1 restoring level using inverter voltage at B is not high enough to turn M2 off. Therefore, leakage current flows through M2-M1 5.52 Solution Conductance C=5V total B A=5V gDS,P CL gDS,N C=0V PMOS: transmits HIGH well NMOS: transmits LOW well 0 VTP Vin ,Vout VTN VDD As B goes HIGH(C=HIGH), VGSP is -5V invariably, while VGSN approaches VTN When A is LOW(C=HIGH), VGSN is 5V invariably, while VGSP approaches VTP 5.53 Cascade connection of pass transistors V V V V Vo V R R C R C R C C = RC • n(n+1)/2, n: number of stages(transistors) 1/2 • n2 • RC Vo can reach up to V-VTN V V V V Vo(high) = V-3VTN Output of pass transistor better not be used as control variable for another gate. Vo 5.54 Cases where pass tr. is appropriate Multiplexer S F=A • S+B • S A requires 8 tr’s vs 6 here S B S XOR gate A B B A F B B 5.55 4-input Multiplexer using CMOS switch concept 5.56 Rules for transmission gate logic construction 1 •A conducting path can never exist between two different inputs which could take different logic levels. •If there is an overlap between 1 and 2, the intermediate node “y” will take an undefined potential, 1 X1 2 X1 Y located between the 1 and 0. This potential will give rise to an erratic behavior of the logic, although it may not be detected by a switch-level simulator •This problem can be solved by designing control signal with a mutual exclusion feature 5.57 Rules for transmission gate logic construction 2 •When a branch has several transmission-gates in series, internal nodes can behave as a dynamic memory •Such a gate cannot be considered as a pure static combinational logic gate, because the memory effect can give rise to false outputs, according to the history of successive inputs and control levels, Moreover, the output could be at high impedance if no buffer has been provided. •This behavior dramatically increases the simulation and test problems 5.58 Rules for transmission gate logic construction 3 •To avoid undesired high impedance states, care should be taken to always provide at least one conducting path between an input and the output •The input variable sources must be low-impedance sources for the same reason a a Ex) 1-to-2 decoder 1 a X1 X1 1 a X2 0 wrong X2 good 5.59 Formal design procedure for transmission-logic Generalized form of a transmission-gate logic V1 V2 A1 A2 Aj B1 B2 Bj X1 X2 Xj Z1 Z2 Zj F Vl Vn V1 P1 V2 P2 Vl Pl Vn Pn F F=P1(V1)+P2(V2)+…+Pn(Vn) with Pi=X1 • X2 • … • Xj 5.60 Design procedure using Karnaugh map 5.61 Design procedure using Karnaugh map 5.62 Design procedure using Karnaugh map 5.63 Ex) Comparator An-1 An-1 Cn((=0) Dn(=0) Aj Aj A0 A0 Cn Cj+1 Cj C1 C0 Dn Dj+1 Dj D1 D0 Bn-1 Bn-1 Bj Bj B0 B0 1) Cn=0, Dn =0 3) C0 becomes 1 when A>B 2) For cell I, D0 becomes 1 when A<B Ci =1 when Ci+1 =1, or C0 and D0 are both 0 when A=B Ai > Bi and Di+1 =0 Di =1 when Di+1 =1, or Ai > Bi and Ci+1 =0 5.64 Ci Ci 1 Ai Bi Di 1 AiBi 00 A 00 A 01 B B 01 A C D A C B B D 11 A C D A C B B D 10 A C D A C B B D C C D D Ci+1Di+1 d 11 not exist A 10 B d A C D B d A C D B d A C D B C D When Ai Bi 1, pass Ci 1 When Ai Bi 1, pass Di 1 5.65 Di Di 1 Ai Bi Ci 1 AiBi 00 A 00 A 01 B B 01 A C D A C B B D 11 A C D A C B B D 10 A C D A C B B D C C D D Ci+1Di+1 d 11 not exist A 10 B d A C D B d A C D B d A C D B C D When Ai Bi 1, pass Di 1 When Ai Bi 1, pass Ci 1 5.66 Resultant I-th layout Ai Ci+1 Ai Bi Bi Ci Di+1 Di 5.67 5. BiCMOS logic Comparison of CMOS vs. Bipolar ECL CMOS CMOS ECL Adv. high, symm noise margin high input impedance high gain in transition region high packing density low power consumption high current drive per unit area high switching speed low I/O noise Low speed(esp. for large C) High power consumption large area low input impedance smaller noise margin Disad. 5.68 ECL(Emitter-Coupled Logic) Vo ,1 VCC VBE ( on) RC I C 1 V 2 VCC VBE ( on) RC I C 2 Vin Vref I C1 exp( ) IC 2 VT I C1 I C 2 I EE 5.69 Deriving ViH, ViL for noise margin (Define ViL as Q1 carrying 1% of IEE, while Q2 99%) I C1 ex 0.01( X Vref Vin L ) x I EE 1 e V iL ,iH V ref VT ln ( 1 ) ViL=Vref-120mV, ViH=Vref +120mV (when VT=26mU) narrow transition region of 240mV. VO 2 VCC-VBE(on)(on) 0.24V VCC-VBE(on)-IEERC VO1 ViL Vref ViH Vin 5.70 Cross-section of BiCMOS Process n-epitaxial layer on P-substrate (n-epi. For n-well of PMOS & collector of npn BJT) n+-buried layer(before epi.) to reduce collector resistance and to increase latchup immunity 5.71 Basic Function of BiCMOS gate is better be M2 Q2 M1 Q1 When Vin = 0 on on When Vin = 1 on on Z2 Z1 off on on off Z2, Z1 : necessary to remove base charge for fast turn-off, also to prevent instantaneous DC path with both Q1, Q2 on. 5.72 Increased power consumption due to reduced swing 5.73 Transient behaviour of BiCMOS inverter 5.74 Combinational logic gate in BiCMOS VDD i) When Vi=1, Vo must be 0 For that, f must be ON f Vi A and f must be OFF Q1 Z1 f : PMOS, f : NMOS ii) Then, Z1 better be ON VO and Z2 must be OFF Z1 : same as f (NMOS) f Q2 Z 2 : Z1 control input from A Z2 5.75 Several Topologies of BiCMOS inverter (a) : basic (b) : Similar(PMOS pulldown:slower) (c) Vo reaches VDD 5.76 (d) Feed Z1 into the Q2 base Utilize charge removed from Q1-base to turn on Q2. 5.77 (e) BiCMOS with full rail output(GND, VDD) VDD speed up charge MP Q1 M1 R1 M1 can be added to removal from Q1-base Vo Mn Vi R2 Q2 5.78 NAND2 BiCMOS gate For large fan-in, discharging Q1-base is slow due to many parallel PMOSFET’S. 5.79 NOR2 BiCMOS gate NAND is preferred over NOR in BiCMOS logic, because charging through series PMOSFET’S is very slow 5.80 BiCMOS AOI/OAI logic 5.81 BiCMOS to CMOS interface circuit One can connect PMOS output and VDD. Connecting from Q1-base to feedback inverter is faster than connecting from Q1-emitter 5.82 Comparison of CMOS & BiCMOS VM tP ,C M O S t0 C L ID VM tP ,B iC M O S t1 C L ID t0, t1 : delay from input to output due only to internal capacitance t1 t0 t1> t0 ( CMOS BiMOS CL tP In BiCMOS, internal node capacitance and delay due to additional delay are larger.) 5.83 6. Dynamic CMOS Logic Dynamic vs. Static scheme (for charge storage) Static storage due to static FF(positive feedback) Stored value remains valid as long as power is supplied In order to change state, a pulse from lower Zo(output impedance) source (than the Zi of FF) for a minimal length equal to the propagation delay of 2-stage inverter chain must be applied Dynamic charge storage(on capacitor) depends on leakage current requires periodic refresh Dynamic charge storage requires high input impedance device for good readout, which is available in CMOS, not in Bipolar Therefore, dynamic is impossible in Bipolar, while in CMOS, both static and dynamic are possible 5.84 Pseudo-static latch D in D high : transparent mode low : storage mode(bistable action) 5.85 Static latch in R R > Ron (pass Tr.) for overwrite Condition for static charge storage i) Cross-coupling with 1 gain ii) Sufficient node capacitance (otherwise corrupted by small noise) 5.86 Master-slave D-FF is built by cascading two pseudo-static latches clocked opposite Problem occurs when & overlaps due to clock skew; i) node A is undefined as driven by both In and B ii) Input signal can race through both master and slave FF if and are both high for long enough time 5.87 Using nonoverlapping clock(1 , 2) Nonoverlap interval(t 12) needs to be long enough to guarantee non overlap despite clock skew. (Maintaining two nonoverlapping clocks all over the chip is very hard) During nonoverlap period, storage mechanism is dynamic, while static during feedback on. (hence the name pseudo-static) 5.88 Purely dynamic 2-phase FF 5.89 Simple dynamic logic using 1- clock in out n < delay < N (RonCin)max < TW < n N < TP < min(Trefresh) This doubled-sided relation is too difficult to satisfy for all signal cases. TW TP 5.90 Dynamic logic using 2-phase clocking in out 1 > delay RonCin C/L 2 > preset 1 1 t12 2 t21 (i) (ii) (iii) TP 2 t12 > (C/L)delay,min0 t21 > for clock skew Tp = delay+C/L delay + preset +t21 2 t12 (C / L) delay.max 5.91 Observations on Dynamic Logic vs. Static Logic Occupies less area : only one type of MOSFET is mainly used comparable to NMOS or pseudo-NMOS Offers higher speed: less input capacitance, i.e. 0.5 and lower switching threshold, i.e. device threshold rather than 1 Vdd 2 Vulnerable to problems such as charge sharing, glitch, clock skew : as it requires clock circuits. Difficult to operate at low frequency, making it unsuitable for portable(low-power) systems unless some modifications are made Needs pre-charging anyway, causing unnecessary charging and discharging regularly for quiet input signals 5.92 Ripple-through logic DC current path exists during clocked transistor on P-logic clk c Vo clk a a b c b Vo clk clk=0 : prech. clk=1 : eval clk=0 : eval clk=1 : prech. clk N-logic poor signal swing 5.93 It is impossible to cascade ripple-through gates of the same kind. When clk=0, ‘out’ node cannot be fully precharged. Node X is high, connecting ‘out’ to GND thus forming VDD-GND DC path 5.94 Cascading different kinds (ideal clock) clk = 0 : pre-charge clk = 1 : evaluate 5.95 Cascading different kinds (with clock skew) t1 - t2 (0-0 overlap); Stage 2 in eval. mode is affected by prech. of stage1 t3 - t4 (1-1 overlap); Stage 2 output can be determined be prech. of stage2, regardless of, or less affected by the evaluated signal of stage1. 5.96 Clocked CMOS(C2MOS) Inverter Functionally equivalent to each other C2MOS, (a) requires less area than (b). 5.97 What would happen if clocked transistors are connected at the PWR/GND ends? 5.98 Output degradation occurs due to charge sharing clk input output hi-Z state charge sharing 5.99 C2MOS register (C2MOS Master Slave D-f/f) Insensitive to or 1 2 overlap C2MOS D-f/f consists of two cascaded C2MOS latches oppositely clocked 1 0 section eval. hold section hold eval. 5.100 C2MOS register with ( ) clocking is insensitive to overlap as long as the rise and fall times of clock is sufficiently small. While signal propagates via alternative charging and discharging in the cascaded logic stages, it is impossible in C2MOS D-f/f 5.101 When the clock rise and fall times are very slow, race condition can occur. ( due to the simultaneous turning on M2 and Mg.) 5.102 Pipelining Insights Tmin : min. clock period Tmin : tp,reg + tp,logic + tsetup,reg This includes thold,reg Tmin,pipe = tp,reg + max(tp,add , tp,abs , tp,log ) + tsetup,reg 5.103 Latches vs. Registers Latch is level-sensitive, i.e., output follows input during (clock) = 1, while sampled input is stored during = 1. (positive latch) D 0 1 0 Q clk() D ( -ve D-latch ) 1 Q clk() ( +ve D-latch ) D Q D Q 5.104 Positive edge-triggered D-f/f or D-Reg. D QM -ve latch (master) +ve latch Q (slave) clk shaded region has no effect D (i) setup time QM (ii) hold time Q (iii) C-Q delay (i) (ii) (iii) 5.105 Setup and hold time violations (due to clock skew) M1(register) g1 clk logic CL M2(register) delay(skew) hold time violation occurs when g1+ CL< skew : M2 samples one cycle too late! setup time violation occurs when g1+ CL> skew + p : Next M2 sample will not have been updated 5.106 Double-sided constraint on skew and delay(g1+ CL) difficult to satisfy skew < g1+ CL < skew+ p (tight-rope walk) g1+ CL < p (when skew 0) g1 : clk-to-Q delay of M1, CL : logic delay p : clock period, skew : clock skew X0 d1 X1 d2 X2 X2-d2 < X1 < X0+d1 l1 l2 d2 d1 < l2 < l1 5.107 Timing constraints in latch-based system ((b) and (c)) (a) clk Reg. A clk Latch A (b) (c) clk Latch Tq A Tq Comb.Logic Td Tq Comb.Logic Td Comb.Logic Ts Tda Latch B Ts Reg. B Ts Latch B Comb.Logic Tdb Latch C 5.108 Timing constraints in latch-based pipelined system (cont’d) Tc0 Tc1 Tp In (c), min(clk=high) time is given by Tc1 > Tda + Tga + Tsb Tda : delay of first-part logic Tga : clk-Q delay of latch A Tsb : setup time of latch B Similarly, Tc0 > Tdb + Tgb + Tsa Assuming 50% clock cycle and identical latches, Tc = Tc1 + Tc0 > Tda + Tdb + 2(Tg + Ts) 5.109 If we use dynamic latch in latch-based pipeline, we obtain the following circuit; Vin A Here, “race” occurs if 0 (i.e. finite overlaps) Vc1 Vc2 B During D11 , “race” occurs between input(A) and Vc1(B). (Vc1 is the legal affector of Vc2 ) D11 5.110 Rule iii) C2MOS latch-based (rather than dynamic latch-based) pipelined circuit is race-free as long as all static logic functions between C2MOS latch are noninverting If F is inverting, NMOS in the 1st & 2nd stage can both conduct if 0 5.111 Rule iii) This circuit is insensitive to clock overlap. For (1-1) overlap i.e., when = = 1, the only way race can occur is when logic function F is inverting as the following; 5.112 NORA(NO-RAce) CMOS and rules to prevent RACE i) consists of i) C2MOS pipeline registers, and ii) NP-CMOS dynamic functional blocks modules. ii) Each block module is a combinational logic followed by a C2MOS latch. (Generalization) Each combinational logic is a cascade of an appropriate number(being limited by clock period) of either static or dynamic logic stages. iii) Number of static inversions between C2MOS latches should be even iv) Same(opposite) type of two dynamic logic stages need an odd (even) number of static inversions between them. v) Number of static inversions between the last dynamic and the C2MOS latch must be even for race-free. 5.113 Rule ii) Examples of NORA blocks(modules) -block consisting of two dynamic stage(N and P) followed by C2MOS latch; 5.114 Rule v) O.K. case Examples (Cont’d) -block consisting of a dynamic stage followed by two(even) static inversions until the C2MOS latch block =0 =1 Logic Precharge Evaluate Latch Hold Evaluate block Logic Evaluate Precharge Latch Evaluate Hold 5.115 Rule v) violation case Race occurs in a circuit violating condition(v) 5.116 Domino logic(Special part of NORA) only noninverting outputs are available only low-to-high transition during evaluation (therefore, no glitches) 5.117 Charge compensation scheme in Domino logic(I) 5.118 Charge compensation scheme(II) 5.119 Internal node precharge to prevent charge sharing 5.120 MODL(Multiple Output Domino Logic) Useful when the target logical expression F can be expressed as F = f1 f2 fn where fi’s are subfunctions also required as output 5.121 MODL carry lookahead adder ci+1 = gi + pi ci c1 = g0 + p0c0 (c0 = cin) c2 = g1 + p1(g0+p0c0) 5.122 MODEL CLA Carry generation circuit 5.123 Latched Domino Logic (Ldomino) offers dual rail output, i.e., NOT operations are possible. can only be used as input stages to a chain of standard domino gates, as it cannot be driven by a standard domino gate.(WHY?) 5.124 Clocked Ldomino separates coupled latch from logic 5.125 NORA with Domino logic 5.126 NORA with Domino logic 5.127 Pipeline(Synchronous) operation (inter-block) + Domino-mode (Asynchronous) operation (intra-block) 5.128 True Single-Phase Clocked logic(TSPC logic) i) Doubled n-C2MOS latch & doubled p-C2MOS latch 6 transistors / latch unlike no race with clock skew (as C2MOS latch) no limit on the number of inversions whatsoever (unlike C2MOS latch in NORA) 5.129 Logic can be inserted between latches, or in the n-C2MOS/p-C2MOS as below; 5.130 ii) Simplified TSPC (called split-output) 5 Tr’s / latch Voltage at node A(A’) swings up to VDD-VTn (down to VTp) 5.131 iii) D-flipflops using TSPC 5.132 iv) Some remarks on TSPC; Successfully used for very high-speed CMOS circuits such as Alpha chip (200MHz in 0.75m technology) Clock slope should be sufficiently steep to prevent both PMOS and NMOS on, resulting in undefined outputs and race conditions. TSPC is vulnerable to noise, as TSPC register is dynamic and the impedance of the storage node is high. Often a feedback transistor is added to make it possible 5.133 Schmitt Trigger converts slowly-changing input to fast-transition output difference in switching threshold according to the direction of input change V(hysteresis voltage) = | VM+ VM | noise suppression 5.134 Emitter-coupled Schmitt Trigger VM RE VCC VBE ( on) RE ( R1 // R2) VM RE VCC VBE ( on) RE R1 5.135 CMOS Schmitt Trigger Switching threshold of CMOS inverter depends on W/L-ratio between PMOS and NMOS transistors 5.136 Alternate CMOS Schmitt Trigger 5.137 Monostable Sequential Circuit (One-Shot) used in ATD(address transition detection) circuit (in) (out) delay(td) td short pulse generation N1 In X N2 Out In X Out 5.138 Astable Circuits Ring counter with adjustable frequency(VCO) M5&M6 form current mirror generating Iref and can be shared among inverters. Shmitt trigger is for when Iref is small. 5.139 길 잃은 사공 세계 시장과 기술의 흐름을 보지 않고 공학을 가르치고 배우는 사람은 바람과 물결의 방향도 모르고 나침반도 없이 생각날 때 마다 노를 젓는 한심한 뱃사공이다. 5.140 도전의 높이 도전한 만큼만 성공할 수 있다. 오르려고 계획한 산의 높이보다 더 높이 올라서 있을 수는 없다. 5.141 技流파악 당신이 기술의 흐름을 아는데 필요한 3요소 : 1) 흐름을 보고 싶어하는 열망, 2) 전문가로서의 당신의 수준, 기초가 든든한지? 3) 세계의 top들이 모여드는 모임에 1년에 2번 이상 참석 5.142