Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
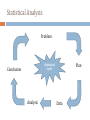
UNIVARIENT & BIVARIENT GEOSTATISTICAL ANALYSIS Mirza Muhammad Waqar Contact: [email protected] +92-21-34650765-79 EXT:2257 RG712 Course: Special Topics in Remote Sensing & GIS What is Statistics About? Statistics is the science of collecting, organizing, analyzing and interpreting data in order to make decisions Statistics is the science of data-based decision making in the case of uncertainty Statistical Analysis Problem Statistical Cycle Conclusion Analysis Plan Data 1. Problem "I wonder if there are differences between...“ What information will you need to answer the question? Identify two or more sub-groups of the population to compare. What variables are likely to show differences? 2. Plan If collecting data you will need to plan a survey of questionnaire. Using available data sets is recommended If using a data set decide what sub-groups of data are needed and choose from the available variables (choose carefully so you can answer the problem 3. Data Collect data by making a survey or questionnaire, OR take a sample from large data set. (at least 30 values) For example, Census data Clean the data set before continuing 4. Analysis Analyze the data to find similarities and differences. You will need measures of central tendency (mean, median, mode) AND measures of spread (range, inter quartile range, standard deviation) Use technology to calculate the statistics: calculator, or EXCEL (using excel) 5. Conclusion Remember that you are analysing and comparing data from a SAMPLE from a population Is there a difference between the subgroups? Comparisons made from a Box-and-Whisker graph Comparisons bases on measures of central tendency Comparisons made from measures of spread Role of Statistics in GIS To describe and summarize spatial data. To make generalizations concerning complex spatial patterns. To use samples of geographic data to infer characteristics for a larger set of geographic data. To determine if the magnitude or frequency of some phenomenon differs from one location to another. To learn whether an actual spatial pattern matches some expected pattern. What is Geostatistics? Applies the theories of statistical inference to geographic phenomena. Methods of geostatistics are used in petroleum geology, hydrogeology, hydrology, meteorology, oceanography, geochemistry A way of describing the spatial continuity as an essential feature of natural phenomena. Recognized to have emerged in the early 1980’s as a hybrid of mathematics, statistics, and mining engineering. Some Useful Definitions Data – information coming from observations, counts, measurements or responses. The data you will be analyzing will almost always be a sample form a population. Population – the collection of all outcomes, responses, measurements or counts that are of interest. Sample – a subset of a population. We will almost always be dealing with samples and hopping to make inference about the population. Some Useful Definitions Parameter – numerical description of a characteristic of the population. Statistic – a description of a characteristic of the sample. We will often wish to make inferences about parameter based on statistics. Some Useful Definitions Descriptive Statistics – relate to organizing, summarizing and displaying data. Inferential Statistics – relate to using a sample to draw conclusions about a population. Inferential statistics involves drawing a conclusion from some data. Inferences vs. Descriptive Consider: Average length of females and males: 90cm and 100cm respectively. Descriptive statistics: the values. Inference: males are (in general) taller than females. Descriptive Statistics 3 categories of descriptive statics in geostatistics Univariate Descriptive Statistics Use to describe and summarize single data/variable Bivariate Descriptive Statistics Use to describe relationship between two data/variable Spatial Descriptive Statistics Describe data in term of space and time Univariate Description Describe and summarize single variable Graphical methods Histogram Cumulative Frequency Numerical methods divides in three categories Measurement of location Measurement of spread Measurement of shape Univariate Description Measurement of location Measurement of center location Measurement of other part Qunatile Quartile percentile Measurement of spread (variability) Mean Median Mode Variance Standard Deviation Inter-Quartile range Measurement of shape (symmetry & length) Coefficient of skewness Coefficient of Variation Frequency Table and Histogram Histogram – is a bar graph that plots the frequency of distribution of dataset. The horizontal scale is representing classes/bin The vertical scale measures the frequencies of the classes. Consecutive boundaries much touch Ideal Histogram for Image Analysis Frequency (f) Vegetation Urban Area Soil Water Band A Actual Histogram from Image Analysis Frequency (f) Vegetation Urban Area Soil Water Band A Histogram from Image Analysis Very informative tool for analysis. Histogram define the contrast of satellite image. More the BV’s range, more the contrast. Low Contrast Histogram High Contrast Histogram Histogram from Image Analysis We can also identify the largest land cover in satellite image by histogram. Rough quantification of landcovers can be made using histogram. This rough quantification quantification. leads to correct Using histogram, range of a particular landcover can be identified in aspect of BV. Frequency Table To develop a histogram a frequency table is used. Frequency table: records how often observed values fall within certain intervals or classes. Constructing a Frequency Distribution Decide on the number of classes to include in the frequency distribution. Find the class width as follows: Determine the range of the data Divide the range by the number of classes and round up to the next convenient number Find the class limits: Start with the lowest value as the lower limit of the first class, add the class width to this to obtain the lower limit for the second class, etc. Place a mark in the row for the class corresponding to each data point Count the number of marks in each class. Frequency Table Cumulative Frequency Table and Histogram Cumulative frequency of a class is the sum of the frequency of that class and all previous classes. The cumulative frequency for the last class is always n. Cumulative Frequency Tables Cumulative Histogram Measure of Location It provide us the information about where various part (information) of data lies Center of data can be find by Mean Median Mode Location of other parts of the data are given by the quantiles Mean Median Mode Mean – average of all the data points in the data/distribution Median – middle value in an ordered array of number. Unique and unbiased Based on every data point in the dataset Can be sensitive to outlaying observations Unaffected by extremely large and extremely small values. Mode – the most frequently occurring value in a dataset. Unlike the mean and median, the mode is not always uniquely defined. Bimodal – two values having same number of instances in the data Multimodal – three or more values having same number of occurrences Univarient Statistics for Image Analysis The histogram of satellite image can not be the uni-mode data. Number of mode represents how many land covers exists in the satellite image. We can’t make decision about transition zone using histogram. Univarient Statistics for Image Analysis Frequency (f) Vegetation Urban Area Soil Water Frequency (f) Band A Vegetation Urban Area Soil Water Band A Which Measure is Best? No clear answer to this question. The mean can be influenced by outliers while the mode may not be particularly “typical central value”. Statistical inference based on the median and the mode is difficult. Percentiles Divide a group of data into 100 parts At least n% od data live below the nth percentile, and most (100-n)% of the data lie above the nth percentile. Example – 90th percentile indicates that at least 90% of the data lie below it, and at most 10% of the data live above it. The median and the 50% percentile have the same value. Percentiles (i): Computational Procedure Organize the data into an ascending ordered array. Calculated percentile location i= 𝑃 (𝑛) 100 Determine the percentile’s location and its value. If i is a whole number, the percentile is the average of the value at the i and (i+1) positions. If i is not a whole number, the percentile is at (i+1) position in the order array. Percentiles: Example Raw Data: 14, 12, 19, 23, 5, 13, 28, 17 Order Array: 5, 12, 13, 14, 17, 19, 23, 28 Location of 30th percentile i 30 (8) = = 2.4 100 The location index, i, is not a whole number; i+1=2.4+1=3.4; the whole number portion is 3; the 30th percentile is at the 30th location of the array; the 30th percentile is 13. Quartiles Formulae in EXCEL Calculating Means: Average(data) Calculating Median: Median(data) Calculating Mode: Mode(data) Calculating Minimum: min(data) Calculating Maximum: max(data) Calculating Quartile: QUARTILE(data,quart) Calculating Percentile: PERCENTILE(array,k) Measure of Spread/Variation Measure of variability describe the spread or the dispersion of a dataset. Common measures of variability Range Interquartile Range Mean Absolute Deviation Variance Standard Deviation Coefficient of Variation Range The difference between the largest and the smallest values in a set od data Simple to compute Ignore all data points except two extremes Range = Maximum – Minimum Range tells us about the spread of data. Some time range provides us very information when outliers exists in data biased Interquartile Range Range of values between the first and third quartiles Less influenced by extremes Interquartile Range = Q3 – Q1 Deviation, Variance and Standard Deviation The deviation of a data entry x in a population data set is the difference between x and population mean µ, i.e. Deviation of x = x - µ The sum of the deviation over entries is zero. Mean Absolute Deviation Average of the absolute deviation from the mean X X-µ |X - µ| 5 -8 8 9 -4 4 16 3 3 17 4 4 18 5 5 0 24 M.A.D. = M.A.D. = ∑ |X − µ| 𝑁 24 5 = 4.8 Variance The population variance is the sum of squared deviation over all entries: Population Variance = σ2 = ∑ (Xi − µ)2 𝑵 Population Variance Average of squared arithmetic mean X X-µ (X - µ)2 5 -8 64 9 -4 16 16 3 9 17 4 16 18 5 25 0 130 deviation σ2 = from ∑ (Xi − µ)2 𝑵 M.A.D. = 130 5 = 26.0 Sample Variance S2 = ∑ (Xi − µ)2 𝒏−𝟏 the Variance for Image Analysis For variance analysis, we go for comparative analysis. By comparing variance of all bands we come to know that which band has more dispersion. Band # Variance Band 1 572 Band 2 634 Band 3 93 Band 4 224 Band 5 336 Band 7 325 Variance for Image Analysis Less the variance, it depicts homogeneity of the data is high. Outlier can disturb the variance. that the Standard Deviation The population standard deviation is the square root of the population variance i.e. σ = σ2 = ∑ (Xi − µ)2 𝑁 Standard Deviation Square root of the variance X X-µ (X - µ)2 5 -8 64 9 -4 16 16 3 9 17 4 16 18 5 25 0 130 σ= σ= ∑ (Xi − µ)2 𝑵 130 = 5 26 = 5.1 Standard Deviation of Sample ∑ (Xi − µ)2 σ= 𝒏−𝟏 Empirical Rules Data are normally distributed (or approximately normally distributed) Distance from the mean % of values falling within distance µ ± 1σ 68 µ ± 2σ 95 µ ± 3σ 99.7 Shape of Distribution - Systematic A frequency distribution is systematic when a vertical line can be drawn through the middle of a graph of distribution and the resulting halves are mirror images. Shape of Distribution - Uniform A frequency distribution is uniform when the number of entries in each class is equal. Shape of Distribution - Skewed A frequency distribution is skewed right (or positively skewed) if its tail extends to the right (mode < median < mean) Shape of Distribution - Skewed A frequency distribution is skewed left (of negatively skewed) if its tail extends to the left (mode > median > mean) Measure of Shape Shape of the distribution is described by Coefficient of skewness Coefficient of kurtosis Coefficient of Skewness Sknewness Absence of symmetry Extreme values in one side of distribution Symmetry measure for skewness = 𝐸 𝑥−µ σ3 3 Where E is Expected value (mean) If S<0, distribution is negatively skewed (skewed to the left) If S=0, distribution is symmetric (not skewed) If S>0, distribution is positively skewed (skewed to the right) Skewness Skewness Kurtosis Describes the shape of the curve about the mean Kurtosis is based on the size of distribution’s tail A measure of weather the curve of distribution is: Bell Shaped – normal distribution Peaked – large tail (Leptokurtic) Flat – small tail (Platykurtic) Kurtosis & Skewness Coefficient of Kurtosis The following formula can be used to calculate kurtosis: Kurtosis = ∑ 𝑿−µ 𝑵𝝈𝟒 𝟒 -3 Kurtosis can be expressed as a number or value A value of kurtosis = 0 indicates symmetrical or no kurtosis Positive value = leptokurtic Negative value = platykurtic Multivariate Statistical Parameter 1. 2. Covariance Correlation Covariance How the two variables are varying with respect to each other. Bands having same information content has high covariance and vice versa. Optimum index factor (OIF) can be used to identify those bands which contain distinct information content. Correlation It is the measurement of linear relationship between the variables. Correlation-Covariance Matrix * Band 1 Band 2 Band 3 Band 4 Band 5 Band 7 Band 1 1 0.5 0.7 0.2 -0.4 0.9 Band 2 0.5 1 0.25 0.15 0.75 0.65 Band 3 0.7 0.25 1 0.29 -0.45 -0.1 Band 4 0.2 0.15 0.29 1 0.12 -0.25 Band 5 -0.4 0.75 -0.45 0.12 1 0.19 Band 7 0.9 0.65 -0.1 -0.25 0.19 1 Correlation Coefficient: Correlation Coefficient: Correlation Coefficient: +1 0 -1 Direct Relationship No Relationship Indirect Relationship Questions & Discussion