Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
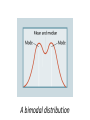
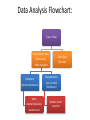
Quantitative Skills: Data Analysis Data analysis is one of the first steps toward determining whether an observed pattern has validity. Data analysis also helps distinguish among multiple working hypotheses. Descriptive statistics serves to summarize the data. It helps show the variation in the data, standard errors, best-fit functions, and confidence that sufficient data have been collected. Inferential statistics involves inferring parameters in the natural population from a sample. Most of the data you will collect will fit into two categories: measurements or counts. Measurement data Count data Most measurements are continuous, meaning there is an infinite number of potential measurements over a given range. Count data are recordings of qualitative, or discrete, data. Number of leaf stomata Number of white eyed individuals How much is good enough? • How much data should a researcher collect to make a claim with confidence? How big should the size of the sample be? • Is it possible the results were due to chance instead of the manipulation of the variable being tested? Conducting Data Analysis When an investigation involves measurement data, one of the first steps is to construct a histogram, or frequency diagram, to represent the data’s distribution If the data show an approximate normal distribution on a histogram, then they are parametric data. If the data do not show an approximate normal distribution on a histogram, then they are nonparametric data. Different descriptive statistics and tests need to be applied to those data. Sometimes, due to sampling bias, data might not fit a normal distribution even when the actual population could be normally distributed. In this case, a larger sample size might be needed. For parametric data (a normal distribution), the appropriate descriptive statistics include : • • • • • the mean (average) sample size variance standard deviation standard error The mean (x)of the sample is the average. The mean summarizes the entire sample and might provide an estimate of the entire population’s true mean. The sample size (n) refers to how many members of the population are included in the study. Sample size is important when estimating how well the sample set represents the entire population. Variance (s2) and standard deviation (s) measure how far a data set is spread out. A variance of zero indicates that all the values in a data set are identical. Variance Distance from the mean Because the differences from the mean are squared to calculate variance, the units of variance are not the same units as in the original data set. The standard deviation is the square root of the variance. The standard deviation is expressed in the same units as the original data set, which makes it generally more useful than the variance. A small standard deviation indicates that the data tend to be very close to the mean. A large standard deviation indicates that the data are very spread out away from the mean. A little more than two-thirds of the data points will fall between +1 standard deviation and −1 standard deviation from the sample mean. More than 95% of the data falls between ±2 standard deviations from the sample mean. 68–95–99.7 Rule In a normal distribution, 68.27% of all values lie within one standard deviation of the mean. 95.45% of the values lie within two standard deviations of the mean. 99.73% of the values lie within three standard deviations of the mean. Sample standard error (SE) is a statistic used to make an inference about how well the sample mean matches up to the true population mean. Standard error should be represented by including error bars on graphs when appropriate. Error bars are used on graphs to indicate the uncertainty of a reported measurement. Different statistical tools are used in the case of data that does not resemble a normal distribution (nonparametric data, or data that is skewed or includes large outliers). • • • • median mode quartiles box-and-whisker plots The median is the value separating the higher half of a data sample from the lower half. To find the median of a data set, first arrange the data in order from lowest to highest value and then select the value in the middle. 5, 1, 3, 7, 2 1, 2, 3, 5, 7 median If there are two values in the middle of an ordered data set, the median is found by averaging those two values. 5, 1, 3, 7, 4, 2 1, 2, 3, 4, 5, 7 3.5 median The mode is the value that appears most frequently in a data set. 3, 5, 1, 3, 7, 2 3 is the mode in this example because it appears more frequently than any other number. A bimodal distribution Data Analysis Flowchart: Type of Data Measurement Data Count Data (Continuous) (Discrete) · Make histogram Parametric (normal distribution) Mean, standard deviation, standard error Nonparametric (not a normal distribution) Median, mode, quartiles Example of Data Analysis: Do shady English ivy leaves have a larger surface area than sunny English ivy leaves? Since the data collected is in centimeters, it is measurement data, not count data. So the first step is to make a: HISTOGRAM Does the data resemble a normal curve? (Close enough, with possible differences due to sampling error) Next, the appropriate statistical tools are applied: A bar graph can then be produced to compare the means: Do the error bars for the shady leaf mean overlap with the error bars for the sunny leaf mean? (No.) A more rigorous statistical test will need to be performed, but because the error bars do not overlap there is a high probability that the two populations are indeed different from each other. Example of Data Analysis: Is 98.6°F actually the average body temperature for humans? Since the data collected is in Farenheit, it is measurement data, not count data. So the first step is to make a: HISTOGRAM Does the data resemble a normal curve? (Close Enough) Next, the appropriate statistical tools are applied: *Note that by convention, descriptive statistics rounds the calculated results to the same number of decimal places as the number of data points plus 1. According to the 68–95–99.7 Rule, 68% of all samples lie within one standard deviation from the mean. This means that around 68% of the temperatures should be between 97.51 and 98.99. Including the standard error, we can say with a 68% confidence that the mean human body temperature of our sample is 98.25 ± 0.06°F.