Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Data Mining:
Concepts and Techniques
— Slides for Textbook —
— Chapter 7 —
©Jiawei Han and Micheline Kamber
Department of Computer Science
University of Illinois at Urbana-Champaign
www.cs.uiuc.edu/~hanj
1
Chapter 7. Classification and Prediction
What is classification? What is prediction?
Issues regarding classification and prediction
Classification by decision tree induction
Bayesian Classification
Classification by Neural Networks
Classification by Support Vector Machines (SVM)
Classification based on concepts from association rule
mining
Other Classification Methods
Prediction
Classification accuracy
Summary
2
Classification
Classification:
predicts categorical class labels
Typical Applications
{credit history, salary}-> credit approval ( Yes/No)
{Temp, Humidity} --> Rain (Yes/No)
x X {0,1} , y Y {0,1}
n
Mathematically
h: X Y
y h( x )
3
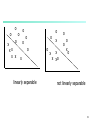
Linear Classification
x
x
x
x
x
x
x
x
x
ooo
o
o
o o
x
o
o
o o
o
o
Binary Classification
problem
The data above the red
line belongs to class ‘x’
The data below red line
belongs to class ‘o’
Examples – SVM,
Perceptron, Probabilistic
Classifiers
4
Discriminative Classifiers
Advantages
prediction accuracy is generally high
robust, works when training examples contain errors
fast evaluation of the learned target function
(as compared to Bayesian methods – in general)
(Bayesian networks are normally slow)
Criticism
long training time
difficult to understand the learned function (weights)
(Bayesian networks can be used easily for pattern discovery)
not easy to incorporate domain knowledge
(easy in the form of priors on the data or distributions)
5
Neural Networks
Analogy to Biological Systems (Indeed a great example
of a good learning system)
Massive Parallelism allowing for computational
efficiency
The first learning algorithm came in 1959 (Rosenblatt)
who suggested that if a target output value is provided
for a single neuron with fixed inputs, one can
incrementally change weights to learn to produce these
outputs using the perceptron learning rule
6
Neural Networks
Advantages
prediction accuracy is generally high
robust, works when training examples contain errors
output may be discrete, real-valued, or a vector of
several discrete or real-valued attributes
fast evaluation of the learned target function
Criticism
long training time
difficult to understand the learned function (weights)
not easy to incorporate domain knowledge
7
Network Topology
Input variables number of inputs
number of hidden layers
# of nodes in each hidden layer
# of output nodes
can handle discrete or continuous variables
normalisation for continuous to 0..1 interval
for discrete variables
use k inputs for each level
use k output for each level if k>2
A has three distinct values a1,a2,a3
three input variables I1,I2I3 when A=a1 I1=1,I2,I3=0
feed-forward:no cycle to input untis
fully connected:each unit to each in the forward layer
8
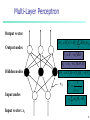
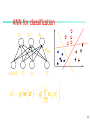
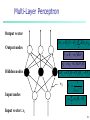
Multi-Layer Perceptron
Output vector
Err j O j (1 O j ) Errk w jk
Output nodes
k
j j (l) Err j
wij wij (l ) Err j Oi
Hidden nodes
Err j O j (1 O j )(T j O j )
wij
Input nodes
Oj
1
I j
1 e
I j wij Oi j
i
Input vector: xi
9
Variabe Encodings
Continuous variables
Ex:
Dollar amounts
Averages: averages sales,volume
Ratio income-debt,payment to laoan
Physical measures: area, temperature...
Transfer between
0-1 or 0.1 – 0.9
-1.0 - +1.0 or -0.9 – 0.9
z scores z = x – mean_x/standard_dev_X
10
Continuous variables
When a new observation comes
it may be out of range
What to do
Plan for a larger range
Reject out of range values
Pag values lower then min to minrange
higher then max to maxrange
E.g.: new observation transformed value 1.2
Make it 1
1.2 to 1
11
Ordinal variables
Discrete integers
Ex:
Age ranges : young mid old
İncome : low,mid,high
Number of children
Transfer to 0-1 interval
Ex: 5 categories of age
1 young,2 mid young,3 mid, 4 mid old 5 old
Transfer between 0 to 1
12
Thermometer coding
0 0 0 0 0 0/16 = 0
1 1 0 0 0 8/16 = 0.5
2 1 1 0 0 12/16 = 0.75
3 1 1 1 0 14/16 =0.875
Useful for academic grades or bond ratings
Difference on one side of the scale is more
important then on the other side of the scale
13
Nominal Variables
Ex:
Gender marital status,occupation
1- treat like ordinary variables
Ex marital status 5 codes:
Single,divorced,maried,widowed,unknown
Mapped to -1,-0.5,0,0.5,1
Network treat them ordinal
Even though order does not make sence
14
2- break into flags
One variable for each category
1 of N coding
Gender has three values
Male female unknown
Male
1 -1 -1 or 1 0 0
Female
-1 1 -1
010
Unknown -1 -1 1
001
15
1 of N-1 coding
Male
1 -1 or 1 0
Female
-1 1
0 1
Unknown -1 -1
0 0
3 replace the varible with an numerical one
16
Time Series variables
Stock market prediction
Output IMKB100 at t
Inputs:
IMKB100 at t-1, at t-2, at t-3...
Dollar at t-1, t-2,t-3..
İnterest rate at t-1,t-2,t-3
Day of week variables
Ordinal
Monday 1 0 0 0 0 ,...,Friday 0 0 0 0 1
Nominal Monday to Friday map
from -1 to 1 or 0 to 1
17
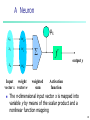
A Neuron
- mk
x0
w0
x1
w1
xn
f
output y
wn
Input
weight
vector x vector w
weighted
sum
Activation
function
The n-dimensional input vector x is mapped into
variable y by means of the scalar product and a
nonlinear function mapping
18
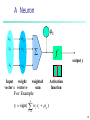
A Neuron
- mk
x0
w0
x1
w1
xn
f
output y
wn
Input
weight
weighted
vector x vector w
sum
For Example
y sign(
n
w x
i 0
i
i
Activation
function
mk )
19
Network Training
The ultimate objective of training
obtain a set of weights that makes almost all the
tuples in the training data classified correctly
Steps
Initialize weights with random values
repeat until classification error is lower then a
threshold (epoch)
Feed the input tuples into the network one by one
For each unit
Compute the net input to the unit as a linear combination of
all the inputs to the unit
Compute the output value using the activation function
Compute the error
Update the weights and the bias
20
Example: Stock market prediction
input variables:
individual stock prices at t-1, t-2,t-3,...
stock index at t-1, t-2, t-3,
inflation rate, interest rate, exchange rates $
output variable:
predicted stock price next time
train the network with known cases
adjust weights
experiment with different topologies
test the network
use the tested network for predicting unknown
stock prices
21
Other business Applications (1)
Marketing and sales
Prediction
Classification
Sales forecasting
Price elasticity forecasting
Customer responce
Target marketing
Customer satisfaction
Loyalty and retention
Clustering
segmentation
22
Other business Applications (1)
Risk Management
Credit scoring
Financial health
Clasification
Bankruptcy clasification
Fraud detection
Credit scoring
Clustering
Credit scoring
Risk assesment
23
Other business Applications (1)
Finance
Prediction
Clasification
Hedging
Future prediction
Forex stock prediction
Stock trend clasification
Bond rating
Clustering
Economic rating
Mutual fond selection
24
Perceptrons
Mitchell 97 Sec 4.4, WK 91 sec 4.2
N inputs Ii i:1..N
single output O
two classes C0 and C1 denoted by 0 and 1
one node
output:
O=1 if w1I1+ w2I2+...+wnIn+w0>0
O=0 if w1I1+ w2I2+...+wnIn+w0<0
sometimes is used for constant term for w0
called bias or treshold in ANN
25
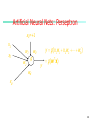
Artificial Neural Nets: Perseptron
x0=+1
x1
x2
w1
w2
g
wd
y g (x 1w 1 x 2w 2 w 0 )
w0
y
g ( wT x)
xd
26
Perceptron training procedure(rule) (1)
Find w weights to separate each training sample
correctly
Initial weights randomly chosen
weight updating
samples are presented in sequence
after presenting each case weights are updated:
wi(t+1) = wi(t)+ wi(t)
i(t+1) = i(t)+ i(t)
wi(t) = (T -O)Ii
i(t) = (T -O)
O: output of perceptron,T true output for each
case, learning rate 0<<1 usually around 0.1
27
Perceptron training procedure (rule) (2)
each case is presented and
weights are updated
after presenting each case if
the error is not zero
then present all cases ones
each such cycle is called an epoch
unit error is zero for perfectly separable samples
28
Perceptron convergence theorem:
if the sample is linearly separable the
perceptron will eventually converge: separate
all the sample correctly
error =0
the learning rate can be even one
This slows down the convergence
to increase stability
it is gradually decreased
linearly separable: a line or hyperplane can
separate all the sample correctly
29
If classes are not perfectly linearly separable
if a plane or line can not separate classes
completely
The procedure will not converge and will keep on
cycling through the data forever
30
o
x
o
o
o
o
xx
x x
o
o
o
x
linearly separable
o
o
o
x
x
x
x xo
o
o
o
xo
not linearly separable
31
Example calculations
Two weights w1=0.25 w2=0.5 w0 or =-0.5
Inputs are :I1= 1.5 I2 =0.5
and T = 0 true output
learning rate=0.1
perceptron separate this as:
O = 0.25*1.5+0.5*0.5-0.5=0.125>0 O=1
O is not equal to true output T weight update required
w1(t+1) = 0.25+0.1(0-1)1.5=0.1
w2(t+1) = 0.5+ 0.1(0-1)0.5 =0.45
(t+1) = -0.5+ 0.1(0-1)=-0.6
with the new weights:
O = 0.1*1.5+0.45*0.5-0.6=-0.225 O =0
no error
32
Above ihe ine is class 1
Below the line is class 0
I2
0.25*I1+0.5*I2-0.5=0
1
o
0.5
1.5
class 0 I2
true class is 0 but
classified as class 1
class 1
I1
2
0.1*I1+0.45*I2-0.6=0
1.33
class 0
0.5
o
true class is 0 and
classified as class 0
class 1
I1
6
33
Least mean square or delta rule
Output is just a linear function of inputs
O = w1I1+ w2I2+...+wnIn+w0
T=0 or 1 again but O is a real number
Minimize error
E=(1/2)(T-O)2 least mean square error
reduces the distance between output and the true
answer
Example
34
If there are two inputs the error surface has a
global minimum
see figure 4.4 in Mitchell 97
Start from an initial random weights
the algorithm find the direction so that error is
decreased most
direction is negative of gradient
gradient is the direction with steepest increase
in error or
wi=-(dE/dwi)=d(Td-Od)Ii,dSee table 4.1 in
Mitchell 97
35
Note about gradient
y=f(x1,x2....,xn)
x1,..xn variables or inputs y output
grad f = a vector of partial derivatives
(dy/dx1, dy/dx2,..., dy/dxn)
indicates the direction the function’s increases
most
36
w2
global minimum
x
initial point
o
w1
37
proof of gradient decent (delta) rule
wi=-(dE/dwi)
but Od = ni=0wiIi,d where I0,d=1
dE/dwi=d/dwi[(1/2)d(Td-Od)2]
apply chain rule
= (1/2)d{2(Td-Od)*d/dwi[(Td-Od)]}
=
but d/dwi[(Td-ni=0wiIi,d)]= -Ii,d so
d{(Td-Od)*d/dwi[(Td-ni=0wiIi,d)]}
dE/dwi=d(Td-Od)(-Ii,d)
hence
w =-(dE/dw )= (T -O )I
38
Stochastic gradient decent or
Incremental gradient decent
Update weights incrementally,after presenting
each sample
wi(t) = (T -O)Ii
i(t) = (T -O) delta rule or LMS rule
for all training samples
new weights are
wi(t+1) = wi(t)+ wi(t)
i(t+1) = i(t)+ i(t)
same as the perceptron training rule
an approximation to the gradient decent
learning rate small converge but slow
high unstable but fast
39
Example Delta rule
In the previous example
weights w1=0.25 w2=0.5 w0 or =-0.5
İnputs are I1= 1.5 I2 =0.5
and T = 0 true output
learning rate=0.1
perceptron separa this as:
O = 0.25*1.5+0.5*0.5-0.5=0.125>0 O=0 closer to 0
Weigth update is necessary
w1(t+1) = 0.25+0.1(0-.125)1.5=0.23
w2(t+1) = 0.5+ 0.1(0-.125)0.5 =0.49
(t+1) = -0.5+ 0.1(0-.125)=-0.51
with the new weights:
O = 0.23*1.5+0.49*0.5-0.51=0.08
40
XOR: exclusive OR problem
Two inputs I1 I2
when both agree
I1=0 and I2=0 or I1=1 and I2=1
class 0, O=0
when both disagree
I1=0 and I2=1 or I1=1 and I2=0
class 1, O=1
one line can not solve XOR
but two ilnes can
41
I2
class 0
1
class 1
0
1
I1
a single line can not separate these classes
42
Multi-layer networks
Study section 4.5(4.5.3 excluded) Mitchell and
4.3 In WK
One layer networks can separate a hyperplane
two layer networks can any convex region
and three layer networks can separate any non
convex boundary
Examples see notes
43
ANN for classification
o2
o1
oK
wKd
x0=+1
x1
x2
xd
d
o tj g ( wTj xt ) g w ji x it
i 0
44
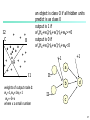
I2
C
+
+
+
B
o o o o
o o
+
o
+
o
+
+
A +
+
+
+
+
I1
inside the triangle ABC is class O
outside the triangle is class +
class =0 if
+1
I1+I2>=10
+1
I1<=I2
a
I2<=10
I1
d
b
output of hidden node a:
1 if class O
I2
w11I1+w12I2+w10>=0
c
0 if class is +
so w1i s are W11=1,w12=1 and w10=-10
w11I1+w12I2+w10<0
45
I2
C
+
+
output of hidden node b:
1 if that is O
w21I1+w22I2+w20>=0
0 if that is +
w21I1+w22I2+w20<0
so w2i s are W21=-1,w22=1 and w10=-0
+
B
o o o o
o o
+
o
+
o
+
+
A +
+
+
+
+
+1
+1
a
I1
I1
b
output of hidden node c:
1 if
I2
w31I1+w32I2+w30>=0
c
0 if
so w1i s are W31=0,w32=-1 and w10=10
w11I1+w12I2+w10<=0
d
46
I2
C
+
+
an object is class O if all hidden units
predict is as class 0
output is 1 if
w’aHa+w’bHb+w’cHc+wd>=0
output is 0 if
w’aHa+w’bHb+w’cHc+wd<0
+
B
o o o o
o o
+
o
+
o
+
+
A +
+
+
+
+
+1
+1
a
I1
weights of output node d:
wa=1,wb=1wc=1
wd=-3+x
where x a small number
I1
b
I2
d
c
47
I2
C
+
+
o
o o o
o
o o
+
A
+
+
+ +
o
+
ADBC is the union of two convex
regions in this case triangles
each triangular region can be separated
by a two layer network
B
o o + +
o
o +
+
D I1
d separates ABC
e separates ADB
I2
ADBC is union of
ABC and ADB
output is class O if
w’’f0+w’’f1He+w’’f2Hf>=0
w’’f0=--0.99,w’’f=1,w’’f2=1
+1
+1
a
w’’f0
I1
b
d
w’’f1
f
c
first hidden
layer
e
w’’f2
second hidden
layer
48
In practice boundaries are not known but
increasing number of hidden node: two layer
perceptron can separate any convex region
if it is perfectly separable
adding a second hidden layer and or ing the
convex regions any nonconvex boundary can be
separated
if it is perfectly separable
Weights are unknown but are found by training
the network
49
Network Training
The ultimate objective of training
obtain a set of weights that makes almost all the
tuples in the training data classified correctly
Steps
Initialize weights with random values
Feed the input tuples into the network one by one
For each unit
Compute the net input to the unit as a linear combination
of all the inputs to the unit
Compute the output value using the activation function
Compute the error
Update the weights and the bias
50
Multi-Layer Perceptron
Output vector
Err j O j (1 O j ) Errk w jk
Output nodes
k
j j (l) Err j
wij wij (l ) Err j Oi
Hidden nodes
Err j O j (1 O j )(T j O j )
wij
Input nodes
Oj
1
I j
1 e
I j wij Oi j
i
Input vector: xi
51
Back propagation algorithm
LMS uses a linear activation function
not so useful
threshold activation function is very good in
separating but not differentiable
back propagation uses logistic function
O = 1/(1+exp(-N))=(1+exp(-N))-1
N: net input to a node = w1I1+w2I2+... wNIN+
the derivative of logistic function
dO/dN = -(1+exp(-N))-2(-exp(-N))
(1+exp(-N))-2(1-1+exp(-N))=O(1-O)
dO/dN = O*(1-O) expressed as a function of
output where O =1/(1+exp(-N)), 0<=O<=1
52
Minimize total error again
E= (1/2)Nd=1Mk=1(Tk,d-Ok,d)2
where N is number of cases
M number of output units
Tk,d:true value of sample d in output unit k
Ok,d:predicted value of sample d in output unit k
the algorithm updates weights by a similar
method to the delta rule
for each output units
wij=-(dE/dwi)=d=1 Od(1- Od)(Td-Od)Ii,d or
wij(t) = O(1-O)(T -O)Ii | when objects are
ij(t) = O(1-O)(T -O) | presented sequentially
here O(1-O)(T -O)= is the error term
53
so wij(t)= *errorj*Ii or ij(t)= *errorj
for all training samples
new weights are
wi(t+1) = wi(t)+ wi(t)
i(t+1) = i(t)+ i(t)
but for hidden layer weights no target value is
available
wij(t) = Od(1- Od) (Mk=1errork*wkh)Ii
ij(t) = Od(1- Od)(Mk=1errork*wkh)
the error rate of each output is weighted by its weight
and summed up to find the error derivative
The weights from hidden unit h to output unit k is
responsible for the error in output unit k
54
Example: Sample iterations
A network suggested to solve the XOR problem
figure 4.7 of WK page 96-99
learning rate is 1 for simplicity
I1=I2=1
T =0 true output
55
1
I1:1
0.1
3
O3:0.65
0.5
0.3
5
-0.2
I2:1
2
0.4
O5:0.63
-0.4
4
O4:0.48
56
item
I1
I2
w13
w14
w23
w24
w35
w45
teta3
teta4
teta5
value
1
unit
net input
3 .1+.3+.2=.6
4 -.2+.4-.3=-.1
5 .5* .65-.4* .48+.4=.53
unit
error derivative
5 .63* (1-.63)* (0-.63)=-.147
4 .48* (1-.48)* (-.147)* (-.4)=.15
3 .65* (1-.65)* (-.147)* (.5)=-.017
1
0.1
-0.2
0.3
0.4
0.5
-0.4
0.2
-0.3
0.4
weights
w45
w35
w24
w23
w14
w13
teta5
teta4
teta3
output
1/(1+exp(-.6))=.65
1/(1+exp(-.1))=.48
1/(1+exp(-.53))=.63
bias adjust
-0.147
0.15
-0.017
Value
-.4+(-.147)* .48=-.47
.5+(-.147)* .65=.40
.4+(.015)* 1=.42
.3+(-.017)* 1=.28
-.2+(.015)* 1=.19
.1+(-.017)* 1=.08
.4+(-.147)=.25
-.3+(.015)=-.29
.2+(-.017)=.18
57
Exercise
Carry out one more iteration for the XOR problem
58
Practical Applications of BP
Revision by epoch or case
dE/dwj = Ni=1Oi(1-Oi)(Ti-Oi)Iij
where i= 1,..,N index for samples
N sample size
j: index for inputs Iij input variable j for
sample i
This is the theoretical and actual derivtives
information in all samples are used in one
update of the weight j
weights are revised after each epoch
59
If samples are presented one by one weight j is
updated after presenting each sample by
dE/dwj = Oi(1-Oi)(Ti-Oi)Iij
this is just one term in the epoch update or
gradient formula of derivative
called case update
updating by case is more common and give better
results
less likely to stack to local minima
Random or sequential presentation
in each epoch case are presented in
sequential order or
in random order
60
sequential presentation
1 2 3 3 5.. 1 2 3 4 5..1 2 3 4 5.. 1 2 3 4 5..
epoch 1
epoch 2 epoch 3
random presentation
1 2 5 4 3.. 3 2 1 4 5..5 1 4 2 3.. 2 5 4 1 3..
epoch 1
epoch 2 epoch 3
61
Neural Networks
Random initial state
weights and biases are initialized to random values
usually between -0.5 to 0.5
the final solution may depend on the initial values of
weights
the algorithm may converge to different local minima
Learning rate and local minima
learning rate
too small: slow convergence
too large: much fast but osilations
With a small learning rate local minimum is less likely
62
Momentum
Momentum is added to the update equations
wij(t+1) = *errorderivativej*Ii+ mon*wij(t)
ij(t+1) = *errorderivativej+ mom*ij(t)
momentum term
slows down the change of direction
avoids falling into a local minima or
speed up convergence by increasing the
gradient by adding a value to it
when it falls into flat regions
63
Stoping criteria
Limit the number of epochs
improvement in error is so small
sample error after a fixed number of epochs
measure the reduction in error
no change in w values above a threshold
64
Overfitting
Sec 4.6.5 pp 108-112 Mitchell
E monotonically decreases as number of iterations
increases Fig 4.9 in Mitchell
Validation or test case error
in general
decreases first then start increasing
Why
as training progress some weights values are
high
fit noise in training data
not representative features of the population
65
What to do
Weight decay
slowly decrease weights
put a penalty to error function for high weights
Monitoring the validation set error as well as the
training set error as a function of iterations
see figure 4.9 in Mitchell
66
Error and Complexity
Sec 4.4 of WK pp 102-107
error rate on the training set decreases as number of
hidden units is increased
error rate on test set first decreases flatten out then start
increasing as number of hidden layers is increased
Start with zero hidden units
increase gradually the number of units in hidden layer
at each network size
10 fold cross validation or
sampling the different initial weights
may be used to estimate error.
error may be averaged
67
A General Network Training
Procedure
Define the problem
Select input and output variables
Make necessary transformations
Decide on algorithm
gradient decent or stochastic approximation
(delta rule)
Choose the transfer function
logistic, hyperbolic tangent
Select a learning rate a momentum
after experimenting with possibly different rates
68
A General Network Training Procedure cnt
Determine the stopping criteria
after error decreases by to a level or
number of epochs
Start from zero hidden units
increment number of hidden units
for each number of hidden units repeat
train the network on training data set
perform cross validation to estimate test error rate
by averaging on different test samples
for a set of initial weights
find best initial weights
69
Chapter 7. Classification and Prediction
What is classification? What is prediction?
Issues regarding classification and prediction
Classification by decision tree induction
Bayesian Classification
Classification by Neural Networks
Classification by Support Vector Machines (SVM)
Classification based on concepts from association rule
mining
Other Classification Methods
Prediction
Classification accuracy
Summary
71
Other Classification Methods
k-nearest neighbor classifier
case-based reasoning
Genetic algorithm
Rough set approach
Fuzzy set approaches
72
Instance-Based Methods
Instance-based learning:
Store training examples and delay the processing
(“lazy evaluation”) until a new instance must be
classified
Typical approaches
k-nearest neighbor approach
Instances represented as points in a Euclidean
space.
Locally weighted regression
Constructs local approximation
Case-based reasoning
Uses symbolic representations and knowledgebased inference
73
The k-Nearest Neighbor Algorithm
All instances correspond to points in the n-D space.
The nearest neighbor are defined in terms of
Euclidean distance.
The target function could be discrete- or real- valued.
For discrete-valued, the k-NN returns the most
common value among the k training examples nearest
to xq.
Vonoroi diagram: the decision surface induced by 1NN for a typical set of training examples.
.
_
_
_
+
_
_
.
+
+
xq
_
+
.
.
.
.
74
V: v1,...vn
fp(xq) = argmaxvVki=1(v,f(xi))
(a,b) =1 if a=b otherwise 0
for real valued target functions
fp(xq) = ki=1f(xi)/k
75
Discussion on the k-NN Algorithm
The k-NN algorithm for continuous-valued target functions
Calculate the mean values of the k nearest neighbors
Distance-weighted nearest neighbor algorithm
Weight the contribution of each of the k neighbors
according to their distance to the query point xq
1
giving greater weight to closer neighbors w
d ( xq , xi )2
Similarly, for real-valued target functions
Robust to noisy data by averaging k-nearest neighbors
Curse of dimensionality: distance between neighbors could
be dominated by irrelevant attributes.
To overcome it, axes stretch or elimination of the least
relevant attributes.
76
Robust to noisy data by averaging k-nearest neighbors
Curse of dimensionality: distance between neighbors could
be dominated by irrelevant attributes.
To overcome it, axes stretch or elimination of the least
relevant attributes.
stretch each variable with a different factor
experiment on the best stretching factor by cross
validation
zi =kxi
irrelevant variables has small k values
k=0 completely eliminates the variable
77
Chapter 7. Classification and Prediction
What is classification? What is prediction?
Issues regarding classification and prediction
Classification by decision tree induction
Bayesian Classification
Classification by Neural Networks
Classification by Support Vector Machines (SVM)
Classification based on concepts from association rule
mining
Other Classification Methods
Prediction
Classification accuracy
Summary
78
Classification Accuracy: Estimating Error
Rates
Partition: Training-and-testing
used for data set with large number of samples
Cross-validation
use two independent data sets, e.g., training set
(2/3), test set(1/3) (holdout method)
divide the data set into k subsamples
use k-1 subsamples as training data and one subsample as test data—k-fold cross-validation
for data set with moderate size
Bootstrapping (leave-one-out)
for small size data
79
cross-validation
divide the data set into k subsamples S1,S2,..Sk
use k-1 subsamples as training data and one subsample as test data --- k-fold cross-validation
for data set with moderate size
stratified cross validation folds are stratified so that the
class distribution in each fold approximately the same
as in the initial data
10-fold stratified cross validation is most common
80
leave-one-out
for small size data
k = S sample size in cross validation
one sample is used for testing
S-1 for training
repeat for each sample
81
Bootstrapping
sampling with replacement to form a training set
a date set of N instances is samples N times with replacement
some elements in the new data set are repeated
test instances: not picked in the new data set but in the original data
set
0.632 Bootstrap
out of n cases with 1-1/n probability an object is not selected at each
drawing
after n drawings probability of not selecting a case is
n
-1
(1-1/n) =e =0.368
so %36.8 of the objects are not in the training sample or they
constitute the test data
error = 0.632*etest + 0.368*etrainingg
The whole bootstrap is repeated several times and error rate is
averaged
82
Bagging and Boosting
General idea
Training data
Classification method (CM)
Altered Training data
Classifier C
CM
Classifier C1
Altered Training data
……..
Aggregation ….
CM
Classifier C2
Classifier C*
83
Bagging
Given a set S of s samples
Generate a bootstrap sample T from S. Cases in S may not
appear in T or may appear more than once.
Repeat this sampling procedure, getting a sequence of k
independent training sets
A corresponding sequence of classifiers C1,C2,…,Ck is
constructed for each of these training sets, by using the
same classification algorithm
To classify an unknown sample X,let each classifier predict
or vote
The Bagged Classifier C* counts the votes and assigns X
to the class with the “most” votes
84
Increasing classifier accuracy-Bagging
WF pp 250-253
Bagging
take t samples from data S
sampling with replacement
each case may occur more than ones
a new classifier Ct is learned for each set St
Form the bagged classifier C* by
voting classifiers equally
the majority rule
For continuous valued prediction problems
take the average of each predictor
85
Increasing classifier accuracyBoosting WF pp 254-258
Boosting increases classification accuracy
Applicable to decision trees or Bayesian
classifier
Learn a series of classifiers, where each
classifier in the series pays more attention to
the examples misclassified by its predecessor
Boosting requires only linear time and
constant space
86
Boosting Technique — Algorithm
Assign every example an equal weight 1/N
For t = 1, 2, …, T Do
Obtain a hypothesis (classifier) h(t) under w(t)
Calculate the error of h(t) and re-weight the examples
based on the error . Each classifier is dependent on the
previous ones. Samples that are incorrectly predicted
are weighted more heavily
(t+1) to sum to 1 (weights assigned to
Normalize w
different classifiers sum to 1)
Output a weighted sum of all the hypothesis, with each
hypothesis weighted according to its accuracy on the
training set
87
Boosting Technique (II) — Algorithm
Assign every example an equal weight 1/N
For t = 1, 2, …, T Do
Obtain a hypothesis (classifier) h(t) under w(t)
Calculate the error of h(t) and re-weight the examples
based on the error
decrease the weights of correctly classified cases
(t+1) = weightst*e/1-e
weights
e:current classifiers overall error
for correctly classified cases
weights for incorrectly classified cases are unchanged
Normalize w(t+1) to sum to 1
when error > 0.5 delete current classifier and stop
or e=0 stop
Output a weighted sum of all the hypothesis, with each
hypothesis weighted according to its accuracy on the training
set
weight = -log(e/1-e)
88
Bagging and Boosting
Experiments with a new boosting algorithm,
freund et al (AdaBoost )
Bagging Predictors, Brieman
Boosting Naïve Bayesian Learning on large subset
of MEDLINE, W. Wilbur
89
Is accuracy enough to judge a
classifier?
Speed
robustness (accuracy on noisy data)
scalability
number of I/O opp. For large datasets
interpretability
subjective
objective:
number of hidden units for ANN
number of tree notes for decision trees
90
Alternatives to accuracy measure
Ex: cancer or not_cancer
cancer samples are positive
not_cancer samples are negative
sensitivity = t_pos/pos
specificity = t_neg/neg
precision = t_pos/(t_pos+f_pos)
t_pos:#true positives
cancer samples that were correctly classified as such
91
pos:# positive (cancer samples)
t_neg:#true negatives
not cancer samples that were correctly classified as
such
neg:# negative (not_cancer samples)
f_pos:# false positives (not_cancer samples
that were incorrectly labelled as cancer)
accuracy = f(sensitivity,specificity)
accuracy = sensitivity*pos/(pos+neg)+
specificity*neg/(pos+neg)
92
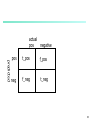
actual
pos
negative
predicted
pos
t_pos
f_pos
neg
f_neg
t_neg
93
Evaluating numeric prediction
Same strategies: independent test set, cross-validation,
significance tests, etc.
Difference: error measures
Actual target values: a1 a2 …an
Predicted target values: p1 p2 … pn
Most popular measure: mean-squared error
( p1 a1 ) 2 ... ( pn an ) 2
n
Easy to manipulate mathematically
94
Other measures
The root mean-squared error :
( p1 a1 ) 2 ... ( pn an ) 2
n
The mean absolute error is less sensitive to outliers
than the mean-squared error:
| p1 a1 | ... | pn an |
n
Sometimes relative error values are more
appropriate (e.g. 10% for an error of 50 when
predicting 500)
95
Lift charts
In practice, costs are rarely known
Decisions are usually made by comparing possible
scenarios
Example: promotional mailout to 1,000,000
households
•
Mail to all; 0.1% respond (1000)
•
Data mining tool identifies subset of 100,000
most promising, 0.4% of these respond (400)
40% of responses for 10% of cost may pay off
Identify subset of 400,000 most promising,
0.2% respond (800)
A lift chart allows a visual comparison
•
96
Generating a lift chart
Sort instances according to predicted probability of being positive:
Predicted probability
Actual class
1
0.95
Yes
2
0.93
Yes
3
0.93
No
4
0.88
Yes
x axis is sample size
…
…
y axis is number of true positives
…
97
A hypothetical lift chart
40% of responses
for 10% of cost
80% of responses
for 40% of cost
98
Chapter 7. Classification and Prediction
What is classification? What is prediction?
Issues regarding classification and prediction
Classification by decision tree induction
Bayesian Classification
Classification by Neural Networks
Classification by Support Vector Machines (SVM)
Classification based on concepts from association rule
mining
Other Classification Methods
Prediction
Classification accuracy
Summary
99
Summary
Classification is an extensively studied problem (mainly in
statistics, machine learning & neural networks)
Classification is probably one of the most widely used
data mining techniques with a lot of extensions
Scalability is still an important issue for database
applications: thus combining classification with database
techniques should be a promising topic
Research directions: classification of non-relational data,
e.g., text, spatial, multimedia, etc..
100
References (1)
C. Apte and S. Weiss. Data mining with decision trees and decision rules. Future
Generation Computer Systems, 13, 1997.
L. Breiman, J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees.
Wadsworth International Group, 1984.
C. J. C. Burges. A Tutorial on Support Vector Machines for Pattern Recognition. Data
Mining and Knowledge Discovery, 2(2): 121-168, 1998.
P. K. Chan and S. J. Stolfo. Learning arbiter and combiner trees from partitioned data for
scaling machine learning. In Proc. 1st Int. Conf. Knowledge Discovery and Data Mining
(KDD'95), pages 39-44, Montreal, Canada, August 1995.
U. M. Fayyad. Branching on attribute values in decision tree generation. In Proc. 1994
AAAI Conf., pages 601-606, AAAI Press, 1994.
J. Gehrke, R. Ramakrishnan, and V. Ganti. Rainforest: A framework for fast decision tree
construction of large datasets. In Proc. 1998 Int. Conf. Very Large Data Bases, pages
416-427, New York, NY, August 1998.
J. Gehrke, V. Gant, R. Ramakrishnan, and W.-Y. Loh, BOAT -- Optimistic Decision Tree
Construction . In SIGMOD'99 , Philadelphia, Pennsylvania, 1999
101
References (2)
M. Kamber, L. Winstone, W. Gong, S. Cheng, and J. Han. Generalization and decision tree
induction: Efficient classification in data mining. In Proc. 1997 Int. Workshop Research
Issues on Data Engineering (RIDE'97), Birmingham, England, April 1997.
B. Liu, W. Hsu, and Y. Ma. Integrating Classification and Association Rule Mining. Proc.
1998 Int. Conf. Knowledge Discovery and Data Mining (KDD'98) New York, NY, Aug.
1998.
W. Li, J. Han, and J. Pei, CMAR: Accurate and Efficient Classification Based on Multiple
Class-Association Rules, , Proc. 2001 Int. Conf. on Data Mining (ICDM'01), San Jose, CA,
Nov. 2001.
J. Magidson. The Chaid approach to segmentation modeling: Chi-squared automatic
interaction detection. In R. P. Bagozzi, editor, Advanced Methods of Marketing Research,
pages 118-159. Blackwell Business, Cambridge Massechusetts, 1994.
M. Mehta, R. Agrawal, and J. Rissanen. SLIQ : A fast scalable classifier for data mining.
(EDBT'96), Avignon, France, March 1996.
102
References (3)
T. M. Mitchell. Machine Learning. McGraw Hill, 1997.
S. K. Murthy, Automatic Construction of Decision Trees from Data: A Multi-Diciplinary
Survey, Data Mining and Knowledge Discovery 2(4): 345-389, 1998
J. R. Quinlan. Induction of decision trees. Machine Learning, 1:81-106, 1986.
J. R. Quinlan. Bagging, boosting, and c4.5. In Proc. 13th Natl. Conf. on Artificial
Intelligence (AAAI'96), 725-730, Portland, OR, Aug. 1996.
R. Rastogi and K. Shim. Public: A decision tree classifer that integrates building and
pruning. In Proc. 1998 Int. Conf. Very Large Data Bases, 404-415, New York, NY, August
1998.
J. Shafer, R. Agrawal, and M. Mehta. SPRINT : A scalable parallel classifier for data
mining. In Proc. 1996 Int. Conf. Very Large Data Bases, 544-555, Bombay, India, Sept.
1996.
S. M. Weiss and C. A. Kulikowski. Computer Systems that Learn: Classification and
Prediction Methods from Statistics, Neural Nets, Machine Learning, and Expert Systems.
Morgan Kaufman, 1991.
S. M. Weiss and N. Indurkhya. Predictive Data Mining. Morgan Kaufmann, 1997.
103
www.cs.uiuc.edu/~hanj
Thank you !!!
104