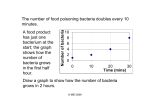
Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Deep Learning for Bacteria Event Identification Jin Mao Postdoc, School of Information, University of Arizona Dec 13th, 2016 AGENDA Recurrent Neural Network Bacteria Event Identification Task Methods by TurkuNLP Results Recurrent Neural Network A Simple Forward NN Recurrent Neural Network Recurrent Neural Network 1. At the time t, the input is formed by concatenating vector w and output from context layer at previous time. 2. The output is the probability of the next word Recurrent Neural Network RNN At time t, the calculation is based on all the information collected till time t-1. Each time, one word. Each epoch, one iteration. Refer to Mikolov et al. (2010) for more details. Bacteria Event Identification Task BB3-event 2016 Three types of entity Bacteria Habitat Geographical A single type of event: Lives_in Bacteria Event Identification Task Lives_in Event Given the text and the annotated entities: T13 Habitat 648 666 patients with WARI T15 Bacteria 750 771 Mycoplasma pneumoniae … T18 Bacteria 950 971 Mycoplasma pneumoniae T19 Habitat 1007 1048 school age children with wheezing illness Identify the events/relationships: R1 Lives_In Bacteria:T15 Location:T13 R2 Lives_In Bacteria:T18 Location:T19 Notice: all bacteria and habitat entities will not appear in the events. Methods by TurkuNLP Preprocessing The TEES system(Bj¨orne and Salakoski, 2013): 1. Tokenization 2. POS tagging, and parsing, 3. remove cross-sentence relations. TEES can extract associations between entities that occur in the same sentence. Methods by TurkuNLP Shortest Dependency Path 1, the BLLIP parser (Charniak and Johnson, 2005) with the biomedical domain model created by McClosky (2010). 2, the Stanford conversion tool (de Marneffe et al., 2006) to create dependency graphs 3, use the collapsed variant of the Stanford Dependencies (SD) representation. Methods by TurkuNLP Shortest Dependency Path One theory: The syntactic structure connecting two entities is known to contain most of the words relevant to characterizing the relationship R(e1, e2), while excluding less relevant and uninformative words. Typically, the dependency parse is directed, two sub-paths: each from an entity to the common ancestor of the two entities. In this study, treat the dependency structure as an undirected graph. always proceed the path from the BACTERIA entity to the HABITAT/GEOGRAPHICAL entity select the syntactic head of the entity as the starting point Methods by TurkuNLP Neural Network Architecture RNN: Long Short-Term Memory (LSTM) Three separate RNNs are used. words the POS tags the dependency types Methods by TurkuNLP Neural Network Architecture Source: bacteria 128 dimensions Sigmoid activation function Target: habitat Input Layer Hidden Layer Output Binary Classification Layer A binary feature, 0-geographical 1-habitat Methods by TurkuNLP Features and Embeddings Word Embeddings: pre-trained from the combined texts of all PubMed titles and abstracts and PubMed Central Open Access (PMC OA) full text articles. (Available from http://bio.nlplab.org/) 200-dimensional, word2vec, skip-gram model the vectors of the 100,000 most frequent words out of vocabulary BACTERIA mentions are instead mapped to the vector of the word “bacteria”. Methods by TurkuNLP Features and Embeddings POS Embeddings: 100-dimensional Initialized randomly at the beginning of the training Dependency type embeddings 350 dimensions Initialized randomly at the beginning of the training Methods by TurkuNLP Training Objectives: use binary cross-entropy as the objective function and the Adam optimization algorithm back-propagation 4 epochs L1 and l2 weighting regularizations do little help Dropout on the output of hidden layers Results Overcoming Variance The limited number of training examples: Initial random state of the model impacts the performance a lot Voting Results On test set Train the model on the training set plus the development set Ignored all potential relations between entities belonging to different sentences Low recall. Conclusions (1) The NN model with pre-trained word embedding improves the precision (2) Complicated, a lot of model architectures, and a lot of regurization/training methods, parameters. (3) Future study: a. Pre-trained POS and dependency type embeddings b. Different amount of training data c. Cross sentence problem:create an artificial “paragraph” node connected to all sentence roots This presentation is from: Mehryary, F., Björne, J., Pyysalo, S., Salakoski, T., & Ginter, F. (2016). Deep Learning with Minimal Training Data: TurkuNLP Entry in the BioNLP Shared Task 2016. ACL 2016, 73. Reference: Mikolov, T., Karafiát, M., Burget, L., Cernocký, J., & Khudanpur, S. (2010, September). Recurrent neural network based language model. InInterspeech (Vol. 2, p. 3). Thank you!