Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
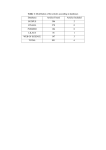
A Study on Traffic Accident Analysis Using Support Vector Machines Topic Area: C2 Traffic Operations, Control, & Management Paper Number: Authors: Hironobu HASEGAWA1, Masaru FUJII2, Mikiharu ARIMURA3, Tohru TAMURA4 Title: A Study on Traffic Accident Analysis Using Support Vector Machines Abstract: In Japan, the number of traffic accident fatalities has tended to decrease each year since 1992, but the number of traffic accidents has continued to increase and the number of injuries resulting from traffic accidents has also remained high. Therefore, measures to prevent traffic accidents are still important despite the decline in fatalities. When considering traffic safety measures, it is effective to extract dangerous locations with high fatality and injury accident rates and then analyze the details of the factors involved in such accidents. Due to numerous factors, however, it is difficult to effectively and efficiently process large quantities of traffic accident data. For this reason, previous traffic analyses are reviewed, and a Support Vector Machine (hereinafter referred to as “SVM”), which has become the focus of attention as a data mining method, is chosen. The SVM is applied to the traffic accident data analysis. The effectiveness of and problems surrounding a SVM are examined in this study. The classification rate of the SVM toward non-learning data was approximately 70%. 1 Hironobu HASEGAWA Postgraduate student Division of Civil and Environmental Eng. Muroran Institute of Technology Address: 27-1 Mizumoto, Muroran, Hokkaido, 050-8585, JAPAN Fax: +81-143-46-5289 E-mail: [email protected] 2 Masaru FUJII Postgraduate student Division of Civil and Environmental Eng. Muroran Institute of Technology Address: 27-1 Mizumoto, Muroran, Hokkaido, 050-8585, JAPAN Fax: +81-143-46-5289 E-mail: [email protected] 3 Mikiharu ARIMURA Docon Co., Ltd. Address: Atsubetsu-chuo 1-5-4-1, Atsubetsu-ku, Sapporo, Hokkaido, 004-8585, JAPAN Fax: +81-11- 801-1520 E-mail: [email protected] 4 Tohru TAMURA Professor & Dr. of Engineering Dept. of Civil Engineering and Architecture Muroran Institute of Technology Address: 27-1 Mizumoto, Muroran, Hokkaido, 050-8585, JAPAN Fax: +81-143- 46-5288 E-mail: [email protected] 1. Introduction In Japan, the number of traffic accident fatalities reached a record high in 1970. Thanks to constant improvements in road structures, vehicles and legal systems for increased driving safety, however, the death toll has dropped yearly and was reduced by approximately 40% in 2005 as compared with 1970. On the other hand, the number of traffic accidents, which had been decreasing since 1969, once again began to rise in 1977 and increased 1.3-fold in 2005 as compared with 1969. As a result, the death toll is declining, but the number of traffic accidents triggering fatal accidents is increasing yearly and traffic accidents are still one of the biggest problems facing society today. Numerous factors have been considered, including the safety of environments and vehicles surrounding drivers, driving conditions and more. Among these factors, accidents caused by drivers or vehicles can be avoided through the development of legal systems, strengthening of controls and enhancement of vehicle safety. However, an effective and efficient countermeasure is necessary in each case for accidents caused by driving conditions, which are greatly related to regional characteristics such as weather, landscape, traffic demand and trip characteristics. When considering traffic safety measures, it is effective to extract dangerous locations with high fatality and injury accident rates and then analyze the details of the factors involved in such accidents. Due to numerous factors, however, it is difficult to effectively and efficiently process large quantities of traffic accident data. For this reason, previous traffic analyses are reviewed, and a Support Vector Machine (hereinafter referred to as “SVM”), which has become the focus of attention as a data mining method, is chosen. The SVM is applied to the traffic accident data analysis. The effectiveness of and problems surrounding a SVM are examined in this study. 2. Review of previous studies and positioning of this study Traffic accident analysis methods include those based on crash experiments and those based on statistical analysis of actual traffic accident data. When examining each detailed factor of an accident and countermeasures for these factors at accident locations, crash experiment methods have a comparative advantage. However, these methods entail a great deal of work, and are ineffective in detecting information in large quantities of data such as unique tendencies and cause-and-effect relationships. They are therefore unsuitable for comprehensive understanding of factors in traffic accidents and the planning of countermeasures. For example, it is difficult to discover accidents of the same type using these methods. As a result, statistical analysis is used for comprehensive classification analysis of large quantities of accident data. Examples of existing studies using macro data such as integrated traffic accident data include those conducted by Mori1),2), Goto3), and Hirasawa4) in Japan. Mori et al. analyzed the relationship between traffic accident countermeasures and reductions in the number of accidents. They attempted to estimate the occurrence of traffic accidents (accident density) using explanatory variables such as pedestrians, bicycles, and vehicle traffic2). However, the analysis was conducted in individual categories such as road structures and side walks, and can therefore not be considered a comprehensive classification analysis. The study with risk maps by Goto et al. shows risks of traffic accidents that reflect local characteristics. It does not, however, quantify the relationship between factors and risks of traffic accidents, which can be the key to planning traffic safety measures. Hirasawa et al. are developing an accident analysis system using GIS as a tool for planning traffic safety measures. Their system is effective for analyzing data individually and specifically with a focus on accident locations. Yet, it is still riddled with many problems as an analysis tool for planning of traffic safety measures, including responses to the same type of accidents in consideration of local circumstances 4). On the other hand, in the United States, Miao Chong tried to discriminate levels of injury to drivers using the machine learning approach5). Miao et al. discriminated five classes (i.e. “No Injury,” “Possible Injury,” “Non-incapacitating Injury,” “Incapacitating Injury” and “Fatal Injury”) using four methods (i.e. “neural networks trained using hybrid learning approaches,” “decision trees,” “Support Vector Machines” and “a concurrent hybrid model involving decision trees and neural networks”). As a result, the method of “concurrent hybrid model involving decision trees and neural networks” showed the best performance in terms of discrimination, and the adoption of SVM failed. However, the causes behind the failure have not been examined carefully, and the authors concluded with this short statement, “From an intelligent systems point of view, it is interesting to note the failure of SVMs in modeling the complexity of different injury classes.” Accident data accumulated daily is assumed to often be used for aggregative purposes. For example, the data are sorted by accident type, then shared and used to develop important policies. However, it is obvious that the quality of accident data is insufficient for the planning of micro accident measures, whereas accident data can be used to show macro declining trends of traffic accidents. The purpose behind studying how to use the data mining method for traffic accident analysis is the preparation of an efficient analysis method for micro accident data such as road structures, implementation methods and vehicle behavior records at the time of an accident. The SVM used in this study is a two-value discrimination method based on the Optimal Separating Hyperplane proposed by Vapnik et al. in the 1960s. Vapnik himself expanded the method to a model capable of being adapted to non-linear classification by incorporating a kernel function in the 1990s. As a result of this expansion, the SVM has become one of the best methods with high recognition performance6). High discrimination performance with unknown data means that the SVM can be used as a basic algorithm for diagnosis models of accident measures. The objective of this study is to examine and sort out issues related to adapting the SVM to traffic accident analysis. 3. Outline of the SVM The SVM is a method for forming a discrimination tool for two class patterns using linear threshold elements. Figure 1 shows the conceptual diagram of the SVM. x2 H1:f(x)=1 H0:f(x)=0 ξi xi ξj xj 1/ w H2:f(x)=1 x1 Fig. 1: Conceptual Diagram of SVM A discriminant function f(x) for distinguishing the data groups and is required. The f(x) maximizes both the frontiers (H1 and H2) of areas containing the data and the distance 1 w between hyperplanes separating the data. If the data can be completely divided into two classes, it is referred to as a hard margin, and if not, it is referred to as a soft margin. A brief explanation of a soft margin is given below. First, when the training data composed of N components in xi (i=1~ℓ) and the class level yi[-1or 1] is given, the problem of soft margin optimization is defined as formula (1). 1 2 w C i , w R N ,b R , R w , 2 i 1 (1) subject to y i ( w xi b ) 1 i ,i 1, , minimize i 0 ,i 1, , The w is the weight vector against an input in the formula. The dual problem in formula (2) is gained by introducing Lagrange multipliers i and i into the optimization problem (primal problem). LD ( ) maximize y subject to i i 1 i i 1 1 i jy iy j xiT x j 2 i , j 1 0 i (2) 0 i C , i 1, , The separation by a curved surface should be considered to enable more complex discrimination. First, the input datum xi is mapped to the high-dimensional feature space. x ( x) (1 ( x) , 2 ( x) , ) (3) The amount corresponding to the feature space in formula (2) is the value calculated by an inner product of the vector, which can be substituted by a kernel function. This substitution is referred to as a kernel trick. It is then applied to formula (2) and the following optimization problem is gained. maximize W ( ) i i 1 subject to y i i 1 (4) , 0 i C , i 1, , 0 i 1 i jy iy j K ( xi , x j ) , R 2 i , j 1 In this case, the bias b can be gained by the formula (5). (5) b y i jy j K ( x j , xi ) jSv Sv shows a set of vectors and j shows an arbitrary support vector. At last, the discriminant function f(x) becomes formula (6). (6) f ( x) wT xi b jy j K ( x j , x) b j Sv When the bias b is a fixed value, the equal sign in formula (4) disappears and the problem becomes a quadric maximization problem. The optimized solution can be gained by updating in the following formula using the steepest descent method. W ( ) αi min C , max( 0 , αi ) αi (7) ω ηi ( 0 ω 2) , i 1, , K ( xi , xi ) The ω shows the convergence ratio. The convergence assessment for the optimization problem is conducted by comparing object function values of primal and dual problems. Pr oportion Primal object function v alue - dual object function v alue Primal object function v alue 1 αi 2W( ) Cξi i 1 i 1 α W( ) Cξ 1 i 1 i ξi max 0 , 1 y (i i 1 αy j 1 j j ε (8) i K ( xi , x j ) b) , (i 1, , ) 4. Traffic Accident Classification by the SVM (1) Outline of the classification method Figure 2 shows the outline of the accident analysis flow proposed in this study. First, target accidents are extracted, then dimensions are aggregated using principal components analysis, and finally major accidents are classified by the SVM. Creation of the data set 1.Extraction of target accidents 2.Dimensional aggregation 3.Class labeling Setting of SVM parameters •Parameter C of the soft margin •Parameter r of the GAUSS kernel Verification of models with unun-learning data Classification of major accidents Fig. 2: Accident Classification Flow (2) Preprocessing of data a) Traffic accident data In Japan, the traffic accident statistical data offered by the Institute for Traffic Accidents Research and Data Analysis are available to the general public (ITARDA data) as aggregated traffic accident data. ITARDA data include types of accidents and behavior, levels of damage caused by accidents, information on parties involved, shapes and conditions of roads at accident locations, roadside environments and local characteristics. b) Creation of a data set In this study, after all error data have been removed, 149 accidents are extracted from approximately 7,500 accidents that occurred in the Oshima and Hiyama districts of Hokkaido between FY1999 and FY2004, under the conditions that 1) accidents occurred at intersections of the DID area and 2) perpetrators were age 65 or older. The data were then set as an example of an SVM discrimination problem. Not all of the items related to each accident are necessarily accident factors. Therefore, ten items that can be described as factors are chosen. Furthermore, the factors are reduced by principal component analysis to intuitively understand road problems (Table 1). Since results of this analysis indicate that the cumulative contribution rate exceeded 60% before the third principal components, the number of factors is three. Table 1: Results of principal component analysis Interpretation of factors and principal components Principal component 1: Driving environment Month of accident Road condition Ratio of day-and-night on weekdays Principal component 2: Road structure Number of lanes Width of road Representative width of sidewalks Extension of median zone setting Traffic volume for 12 hours during the daytime on weekdays Principal component 3: Usage characteristics Designated maximum speed Mix rate of large-sized vehicles for 12 hours during the daytime on weekdays Contribution rate (%) Principal Component 1 Principal Component 2 Principal Component 3 0.003 -0.065 0.046 0.067 -0.319 0.222 -0.587 0.429 -0.325 -0.414 -0.459 -0.470 -0.397 -0.420 -0.398 -0.262 -0.130 0.317 0.218 -0.124 -0.113 -0.078 0.191 -0.01 -0.188 -0.148 35.177 0.568 0.361 13.804 0.407 -0.359 12.170 In this study, two classes are designated as classification classes: major accidents involving fatalities and serious injuries, and other accidents resulting in minor injuries. A principal component point gained by principal component analysis is set as the input xi, and the index yi[1,1] is given to each piece of data for classification (Fig. 3). Major accidents PCS2 PCS3 0 6 Road structure -2 Usage characteristic 2 4 6 Non-major accidents 4 -4 2 0 -2 -6 -4 -6 -6 -4 -2 0 PCS1 Driving 2 4 6 environment Fig. 3: Distribution of Data (3) Setting of model parameters From the data set created in the preceding section, twenty pieces of data (ten data of y = 1 and ten data of y = -1) are extracted as training data. The convergence ratio, convergence condition and the maximum number of cycles are set as ω 1.0 , 10 4 and 8×106 respectively. In addition, the Gauss kernel is used for the kernel function K ( xi , x j ) in formula (9). x x 2 i j , i ,j 1, , K ( xi , x j ) exp (9) 2 2r The discrimination performance of the SVM is affected by the parameter C of the soft margin and the Gauss kernel parameter r. An appropriate value should therefore be calculated using iterative counting. The best result (C=50 and r=0.1) gained from several trials is used in this test. (4) Verification of models with non-learning data 129 pieces of data are extracted as verification data from the data set after removing the training data. The verification data are shown in Fig. 4. The red and blue data in the figure indicate major accidents and nonmajor accidents, respectively. Major accidents PCS2 PCS3 0 6 Road structure -2 Usage characteristic 2 4 6 Non-major accidents 4 -4 2 0 -2 -6 -4 -6 -6 -4 -2 0 2 4 6 PCS1 environment Driving Fig. 4: Distribution of Verification Data Verification data are classified by the created SVM. Figure 5 presents the classification results. The red, blue and green data in the figure indicate major accidents, non-major accidents and discrimination thresholds, respectively. Major accidents Non-major accidents PCS2 PCS3 0 6 Road structure -2 Usage characteristic 2 4 6 Discrimination thresholds 4 -4 2 0 -2 -6 -4 -6 -6 -4 -2 0 2 4 6 PCS1 environment Driving Fig. 5: Results of data discrimination by the SVM The classification rate of the SVM for non-learning data is 73%, which means the SVM correctly classified 94 out of 129 example samples. The SVM also classified seven out of ten samples for fatal/major accidents. 5. Conclusion In this study, we attempted to classify fatal/major accidents and other minor accidents in ITARDA data using the SVM. This study made it clear that accident data are a mixture of discrete and continuous quantities, and that the SVM cannot simply be applied. This study was aimed at data from accidents that occurred at DID intersections and involved elderly persons. After extraction of the data, principal component analysis was conducted to determine the distribution of accident data, and the data were then converted into continuous quantities for three axes: driving environment, road structures and usage characteristics. The percentage of fatal/major accidents is approximately 1% of the sample data set. This percentage is too low for creating a training data set, so data other than that from fatal/major accidents was divided to create minor accident data identical in size to that of fatal/major accidents. Multiple training data were then created and a discriminant function was gained using the SVM. The classification rate of the SVM toward non-learning data was approximately 70%, and a discriminant function with a classification rate identical to that for the small amount of fatal/major accident data was also gained. It is possible to predict areas with the possibility of fatal/major accidents using sensitivity analysis of the discriminant function based on the amount of the principal component. This is a challenge that will be tackled in the future. In this study, the SVM is used as a data mining method for existing accident statistical data. The authors find themselves in a dilemma because even if macro data were to be analyzed, the results could still only be applied to macro policy planning. Collectable data as continuous quantities, e.g. the feature quantity of an intersection’s “shape” and speeds of vehicles approaching intersections, are suitable for analysis by the SVM. Thus, there is a fair possibility that the SVM can be utilized as a data analyzing method in the ITS society. References 1) Mori and Ikeda: A Study on an Estimation Method of Traffic Accident Reduction Impact by Road Projects, Conference Material 3-13, pp. 17 - 20, 2003 of the Fourth Road Committee on Advanced Road Technology 2) Mori, Ikeda and Miyashita: Evaluation of Road Safety Facilities using a Road Traffic Accident Database, The National Institute for Land and Infrastructure Management, “FY2005 NILIM Research Map,” (http://www.nilim.go.jp/lab/bcg/siryou/tnn/tnn0253pdf/ks025319.pdf) 3) Goto, Saito, Hirasawa: A study on analysis and evaluation methods of traffic accident risk, FY2005 Research paper collection of Japan Society of Civil Engineers, Hokkaido Branch, No.62, 2006 4) Hirasawa, Takada, Asano: Development of Traffic Accident Analysis Systems, FY2003 Research paper collection at The 47th Hokkaido Regional Development Bureau Technical Research Presentation Meeting 5) Miao Chong, Ajith Abraham and Marcin Paprzycki: Traffic Accident Data Mining Using Machine Learning Paradigms, Fourth International Conference on Intelligent Systems Design and Applications, 2004 6) N. Cristianini & J. Shawe-Taylor : An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods, Cambridge University Press, 2000