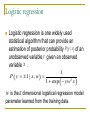Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Personalization Services in CADAL
Zhang yin Zhuang Yuting Wu Jiangqin
College of Computer Science, Zhejiang
University
November 19,2006
Outline
Introduction
The Architecture of Personalization Services
Personalized Search
Recommendation based on the Information
Filtering techniques
Future plan
Outline
Introduction
The Architecture of Personalization Services
Personalized Search
Recommendation based on the Information
Filtering techniques
Future plan
Background
The number of digital books meeting with OEB
standard is 1,023,425.
It’s a time consuming process finding the useful
information and knowledge in this large digital
collection of CADAL.
Personalization service is provided to help users
to quickly locate their interested things in the
collection of CADAL.
Outline
Introduction
The Architecture of Personalization Services
Personalized Search
Recommendation based on the Information
Filtering techniques
Future plan
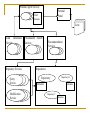
Personal Agent Services
Personal
Portal
User
Metadata
Users
Link Generation
Services
Repository Services
Query
Service
Modification
Service
Personalized
Services
Search
Recommendation
Services
Repositories
Repository
A
Repository B
Metadata
Metadata
Repository C
Metadata
Outline
Introduction
The Architecture of Personalization Services
Personalized Search
Recommendation based on the Information
Filtering techniques
Future plan
Query Expansion
Many users often send one or two keywords
as a query
The search results can be improved by
expanding the query with additional search
keywords.
Query Expansion depends on the NLP
(Natural Language Processing)techniques
and relevance feedback methods
Keyword Expansion – The Trigger pairs
model
If a word S is significantly correlated to
another word T, then (S,T) is considered as a
trigger pair, with S the trigger, T the trigged
word.
When we see the S in the document, we
expect T to appear after S with some
confidence.
Trigger pairs selection algorithm(1)
We define that the keywords are K1 , K2 , Km ,
and the expected number of refinement
words is N. Initialize n m, S is the empty set.
1. S1 s11 , s12 , , s1i K1 is the trigger set to K1 .
s11, s12 , , s1i are sorted in decreasing order
of the mutual information.
S2 s21 , s22 , , s2 j K 2is the trigger set to K 2
Sm sm1 , sm 2 ,
, smk K m
is the trigger set to Km
Trigger pairs selection algorithm(2)
S , and
2. S S S , S , , S S S
S is one of the combinations of n
S S
sets out of m. The words in the S are sorted
in decreasing order of mutual information.
3. If S N , let the top N words in S be the
refinement words and stop.
4. Otherwise, let n n 1 , continue step 2.
p
p
q
q
r
r
p
q
r
Outline
Introduction
The Architecture of Personalization Services
Personalized Search
Recommendation based on the Information
Filtering techniques
Future plan
Implemented Information filtering techniques
A Content-based filtering method
A Collaborative filtering method
LR_Rocchio algorithm
The user profile is represented as a vector of
indicative words extracted from the contents
of all digitized books.
The LR_Rocchio algorithm set a bayesian
prior of the Logistic Regression model
parameter using the user profile calculated by
Rocchio algorithm.
Increasing Rocchio algorithm
A widely used user profile updating algorithm
is the increasing Rocchio algorithm, which
can be generalized as :
Q Q
xi R
R
xi
xi NR
xi
NR
Where Q is the initial profile vector, Q wr1 , , wrk
is the new profile vector, R is the set of
relevant documents, and NR is the set of
irrelevant documents.
Logistic regression
Logistic regression is one widely used
statistical algorithm that can provide an
estimation of posterior probability P y | x of an
unobserved variable y given an observed
variable x .
P y 1 | x, w
1
1 exp ywT x
w is the K dimensional logistical regression model
parameter learned from the training data.
LR prior(1)
The Bayesian-based learning algorithms
often begin with a certain prior belief p w
about the distribution of the logistic regression
model parameter.
1
N
m
,
v
Gaussian distribution w w
A classifier learned with a non-informative
prior usually over fits the training data.
LR prior(2)
A prior mw that encodes Rocchio’s suggestion
about decision boundary can be learned via
constrained maximum likelihood estimation:
1
mw arg max w log
T
1 exp yi w xi
i 1
t
Under the constraint:
cos w, wR 0
The Approaches of Collaborative filtering
Memory-based
Model-based
Pearson Correlation Coefficients
Clustering
Aspect model
Hybrid
A hybrid approach using the cluster-based
smoothing
1.
2.
Create the user clusters C using the k-means
method.
Given the user ua , and i rated items, an item t and
an integer K , the number of nearest neighbors.
Choose
users into G from groups that are
most similar to user ua .
Calculate similarity sim u, ua for each u in G in
which the rating of the user u is the combination of
Ru t and RCu t .
Select the top-K most similar users as neighbors.
Predict the rating of the item t for ua by the
behaviors of the K nearest neighbors.
s
3.
4.
5.
Symbol definition
T t1 , t2 ,
U u1 , u2 ,
, tm be a set of items
, un
be a set of users
Each triple ui , ii , ri indicates the item ii is
rated as ri by the user.
Ru t denotes the rating of item t by user u
Ru denotes his average rating.
the clustering results of the users U u1 , u2 , , un
1
2
n
C
,
C
,
,
C
u
are represented as u u
ua user for whom recommender service
similarity measure function
the Pearson correlation-coefficient function is
taken as the similarity measure function.
The similarity between user u and user u is
defined as :
simu ,u
R t R R t R
tT u T u
u
u
R t R
tT u T u
u
u
2
u
u
R t R
tT u T u
u
u
Reducing Data Sparsity
At the early stage of system running, the collected
rating data is sparse. To fill the missing values in
data set, clusters are explicitly exploited to smooth
the sparse data.
R t if user u rate the item t
Ru t { u
Rˆ t else
u
ˆ t R R t
R
u
u
Cu
RCu t
R t R
u Cu t
u
u
Cu t
Where Cu t Cu is the user set in user cluster Cu that
have rated item t. Cu t is the number of users in cluster
who have rated the item t
Increasing System Scalability
make use of the user cluster in neighbor
selection to increase system scalability.
The centroid of cluster is represented as the
average rating over the cluster. The similarity
between the cluster C and user is defined as:
RC t Ru t Ru
simua ,C
tT ua T C
R t
tT ua T C
After
a
C
2
a
R t R
tT ua T C
ua
2
ua
calculating the similarity, the users in the most
similar cluster are taken as the candidates that need to be
recalculated similarity with the active user on the smoothed
data.
Weighting
The different weights wut are placed on the
original data and smoothing data when
calculating the similarity between the cluster
users and the active user.
1 if user u rate the item t
wut {
else
Where is the tuning parameter between original rating
and group rating, its value varied from 0 to 1.
Reformed similarity measure function
The system will select the top K most similar
users based on the following similarity
function:
simua ,u
tT ua
wut Ru t Ru Rua t Rua
w R t R R t R
2
tT ua
ut
u
u
tT ua
ua
ua
2
Prediction for the active user
After the neighbor selection, a weighted aggregate
of the deviations from the neighbor’s mean is used
to generate the prediction for the active user as the
following:
Rua t Rua
K
i 1
wut simua ,ui Rui t Rui
K
w
i 1
ut
simua ,ui
收藏的图书可以在用户登录的首页上找到,如下图:
Modify the user’s
information;
Set the rule;
The complete list of
the user’s collections
My bookshelf:the
books user has
collected
Outline
Introduction
The Architecture of Personalization Services
Personalized Search
Recommendation based on the Information
Filtering techniques
Future plan
Future Plan
Extend the architecture of personalization
services to incorporate the semantic web
techniques.
Put more effort on the web usage mining
techniques to discover the user pattern from
the web data.
Thanks!
Email: [email protected]