Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
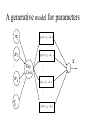
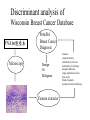
Natural Discriminant Analysis Using Interactive Potts Models Neural computation 2002, April Jiann-Ming Wu [email protected] Department of Applied Mathematics, National Donghwa University Outlines 1. Discriminant analysis by learning samples 2. A generative model 3. PottsNDA - The mapping function of PottsDA - The learning network of PottsDA - A mixed integer and linear programming - A hybrid of mean field annealing and gradient descent methods - Interactive Dynamics 4. Incremental learning 5. Numerical simulations and discussion 6. Conclusions Discriminant analysis by learning samples Training set d=2 N=800 S={(0 1),(1 0)} 0.8 0.6 0.4 0.2 0.8 0.6 0.4 0.2 0 0 -0.2 -0.2 -0.4 -0.4 -0.6 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 Testing set d=2 N=800 S={(0 1),(1 0)} -0.6 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 Training set= PottsDA q=g(x;W) Testing set Correct rate A generative model for parameters 1 p( x | y1 , A1 ) 2 p( x | y2 , A2 ) p ( x | y k , Ak ) … … K … … k Flip Coin x p( x | y K , AK ) A generative model Piece-wise multivariate Gaussian distribution Voronoi partition Ωk = {x | arg minj‖x - yj‖A = k , x ∈ Rd }, where ‖x‖A denotes the Mahalanobis distance of Partition by the Mahalanobis distance Partition by A=I The mapping function of PottsDA Category of each region: ξk ∈ {e1M,…, eMM} or {( 0 1), (1 0)}, 1≦k≦K The mapping function of PottsDA • For an extreme beta value or where zk= Byk and A = B’B. The learning Network of PottsDA Potts model for <> dynamics for A dynamics for y inter-connection data networks ( A,{y} ,<>, <>) Potts model for <> • Membership vectors: δi ∈ {e1k,..., ekk}, 1≦i≦N • Measurement A • Kernels {yk, 1≦k≦K } • Category of each region Ωk ξk ∈ {e1M,…, eMM}, 1≦k≦K Objective: fitness of the generative model to all predictors • Maximal likelihood In terms of membership vectors • Setting det(A-1) = - det(A) and neglecting the last constant term • Maximizing the function l is equivalent to minimizing the function E1 Objective: Minimal design cost MILP: A mixed integer-linear programming • Objectives and constraints Minimizing subject to A hybrid of mean field annealing and gradient descent methods • The gradient descent method can not be directly applied to binary variables • MFE for binary variables and GD for continuous variables • {δi} and {ξk} are associated with Potts neural variables or Potts spins in statistical mechanism An energy function for the MILP Mean field annealing • • • • Fixing A and {yk}, trace the mean configuration〈〉and〈〉for emulating thermal equilibrium at each temperature. Probability of the system configuration is proportional to the Boltzmann distribution The annealing process gradually increases the parameter from a sufficiently low value to a large one To a sufficiently large value, the Boltzmann distribution is ultimately dominated by the optimal configuration, where A free energy for interactive Potts models •A result of minimizing energy and maximizing entropy where〈〉,〈〉, u , and v denote {i}, {k}, {ukm}, and {vik}, respectively, and ui and vk are auxiliary vectors. Derivation of interactive dynamics Mean field equations Updating rule for each element of A When all Amn = 0 , we have Adaption of the kernels {yk} • Gradient descent method • Again when y = 0 , we have The learning process of PottsDA 1. 2. 3. 4. 5. 6. Set a sufficiently low value, each kernel yk near the mean of all predictors, and each〈ik〉near and〈km〉near . Iteratively update all〈ik〉and vik by equation (20) and equation (21) respectively, to a stationary point. Iteratively update each〈km〉and ukm by equation (22) and equation (23), respectively, to a stationary point. Update each yi by equation (28). Update A by equations (25) and (26). If and are larger than a prior threshold, then halt, otherwise increase by an annealing schedule and then go to step 2. Incremental Learning for Optimal Model Size • The variables {〈ik〉} and {〈km〉} are first recorded by temporal variables {ik*}, { km*}, to establish an intermediate recognizing network with kernels {yk}, and the matrix A. • The size of {yk} is sufficient depends on the quantity of the design cost , which denotes the number of errors of predicting all training samples. • Define the hit ratio r as . • Define the local hit ratio rk as or each internal region k = {x│k = arg minjx - yjA}, where Nk denotes the size of the set { xi k}. Incremental Learning • The kernel yk of an under-estimated internal region, such as yk < , is duplicated with small perturbation to produce its twin kernel denoted by yk* . • A set of new kernels {yknew} is created to be the union of {yk}, and {yk* │rk < }, having the model size of K + K* where K and K* respectively denote the number of the original kernels and that of the under-estimated internal regions. • Let the index of yk be k still and that of yk* be denoted by k’ . Incremental Learning • For each input parameter xi , assuming xi ∈ Ω(yk) , a new membership vector δinew, now with K + K* element, is created as follows: In the second line of the above equation, the new vector δinew means that xi has the same probability 1/2 to be mapped to each of the twins, yknew and yk’new. • Create new category responses {ξknew} for the new kernels {yknew} and set each element of ξknew near 1/M. Incremental Learning process 1. 2. 3. 4. 5. Set a sufficiently low β value, a threshold θ, and an initial model size K; set each kernel yk near the mean of all predictors, each〈δik〉near 1/K , and〈ξkm〉near 1/M . Iteratively update all 〈δik〉 and vik by equation (20) and (21), respectively to a stationary point. Iteratively update each〈ξkm〉and ukm by equation (22) and equation (23) respectively to a stationary point. Update each yi by equation (28). Update A by equations (25) and (26). Incremental Learning process (continue) 6. 7. 8. 9. 10. If and are larger than a prior threshold, such as 0.98, then go to step 7, otherwise increase β by an annealing schedule and then go to step 2. Record {〈δi〉}, {〈ξk〉} by temporal variables {δi*}, {ξk*}, respectively. Determine r and all rk using A, {yk}, {δi*}, {ξk*} . If r >θ, halt, otherwise duplicate the kernels of K* under-estimated regions with small perturbation and create new variables {yknew}, {δinew}, {ξknew} using { yk}, {yk* | rk <θ}, {δi*}, {ξk*} as described in the context. K ← K + K*, increase β with a small constant, and replace {yk}, {〈δi〉} and {〈ξk〉} with {yknew}, {δinew} and {ξknew} respectively, and goto step 2. Numerical Simulations • Performance evaluation of 1. PottsDA 2. Radial basis function(RBF) method 3. Support vector machine(SVM) method (Vapnik 1995) Artificial data: Example 1 Mixing matrix 0.8 0.6 0.4 0.2 Results of PottsDA: the two columns of the inverse of demixing matrix, the four kernels, and their category response. 0 -0.2 -0.4 -0.6 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 Artificial data: Example 2 0.8 x(t) = Hs(t) s(t) = [s¹(t) s²(t) s³(t)]’ 0.6 0.4 0.2 •s¹(t) and s²(t), are of uniform 0 distributions within [-0.5,0.5] -0.2 •s³(t) is a gaussian noise of N(0,√2) -0.4 •Discriminant rule: sign(s¹(t)) *sign(s²(t)) -0.6 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 the third source as a noise for prediction. Artificial data: Example 3 1.5 1 Results of PottsDA: the two columns 0.5 of the inverse of demixing matrix, 0 the 40 kernels, and their category -0.5 response. -1 -1.5 -1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1 Incremental learning of PottsDA for Example 3 •∑〈δik〉² 1 0.9 0.8 0.7 0.6 K=35 0.5 0.4 0.3 K=44 K=10 K=20 0.2 . 0.1 0 500 1000 1500 2000 2500 3000 The horizontal coordinate is the time index for varying the beta value Discriminant analysis of Wisconsin Breast Cancer Database •Walberg and Mangasarian 1990 • 699 instances, each containing 9 features for predicting one of benign and malignant categories. • 458 instances in the benign category 241 instances in the malignant category Discriminant analysis of Wisconsin Breast Cancer Database FNA細胞樣本 Microscopy PottsDA Breast Cancer Diagnosis Benign Or Malignant Feature extractor Features: clump thickness uniformity of cell size uniformity of cell shape marginal adhesion single epithelial cell size bare nuclei bland chromatin normal nucleoli and mitoses Simulation Results • Walberg and Mangasarian 1990 error rate for testing > 6% • 683 instances of the database by Malini Lamego(2001) • For the 219-case test set, the RBF method with 80 kernels and the SVM method result in error rates 4.17% and 4.63% for testing. Conclusions • The PottsDA method is composed of a discriminant network and an annealed recurrent learning network. • The generative model is a potential approach to characterizing predictors of a training set. • A hybrid of mean field annealing and gradient descent methods are reliable for solving a MILP. • The incremental learning process is effective for optimal model size. • The performance of the PottsDA is encouraging.