Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Degrees of freedom (statistics) wikipedia , lookup
Bootstrapping (statistics) wikipedia , lookup
Psychometrics wikipedia , lookup
Inductive probability wikipedia , lookup
Confidence interval wikipedia , lookup
History of statistics wikipedia , lookup
Statistical inference wikipedia , lookup
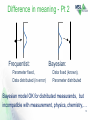
CCT/14-39 Bayesian Uncertainty: Pluses and Minuses Rod White Thanks to Rob Willink, Blair Hall, Dave LeBlond Measurement Standards Laboratory New Zealand Outline: • • • • • • • A simple statistical experiment (coin toss) Confidence intervals (frequentist) Bayes’ rule and Bayesian statistics Credible intervals (Bayesian) Difference in meaning Differences in performance Other differences 2 Spot the difference: coin toss 3 Interpretation of coin toss • Call before toss • Uncertainty due to randomness • Frequentist probability • Call after toss • Uncertainty due to lack of information • Bayesian probability • Definition of probability is different – F: Long-run frequency of events – B: Degrees of belief • Bayesian thinking - more natural • Bayesian probability - wider applicability 4 Confidence Intervals (F) • Problem: – measure Boltzmann’s constant, k – Error is zero-mean normal noise process • Measure: – n samples from normal distribution – calculate mean, sample standard deviation • Estimate k – 95% prob. of being within M t 0 .9 7 5 , n 1 S / n , M t 0 .9 7 5 , n 1 S / – Note: M , S are random variables; the statement is meaningless when replaced by numerical values – Note: mean of measurements has normal distribution – Note: use t-distribution to calculate confidence interval n 5 Bayes rule P(A) P(AUB) • Basic statistical result • Usually expressed as P(B) P( A | B ) P(B ) P(B | A) P( A) P(A | B) P(B | A) P( A) P(B) 6 Bayes rule cont. • Example: effectiveness of medical screening – 1% of population have disease – Test 80% reliable for detecting disease – Test 90% reliable for detecting absence of disease • Test 10,000 people – Correctly identify 80% of the 100 people with disease – Incorrectly identify 10% of 9,900 without disease – Probability of having the disease having tested positive: P( A | B) 0 .8 0 0 .0 1 0 .8 0 0 .0 1 0 .1 0 .9 9 0 .0 7 5 . – Interpreted differently by Bayesians and frequentists – Applies for single probability 7 Bayesian statistics • Generalise Bayes rule from probability to the whole distribution: P( A | B) P(B | A) P(B P( A) | A) P( A)dA – Where P ( A ) is the prior distribution – P ( A | B ) is the posterior distribution – And P(B | A) is liklihood function P(B | A) P( A)dA – There are two main types of Bayesian approach 8 – ‘Subjective’ and ‘objective’ Credible Intervals (Sub. B) • Use prior distribution to represent prior knowledge of Boltzmann’s constant – E.g. as normal distribution N(kprior, sprior) • Make n measurements – Calculate mean, m, and standard deviation, s • Calculate posterior distribution k post ms 2 p rio r s k p rio r s 2 p rio r 2 s /n 2 /n s 2 post s s 2 s p r io r 2 p r io r 2 s /n 2 /n – This is a subjective Bayesian approach – Computationally expensive (most of the time) 9 Credible Intervals (Obj. B) • Assume complete ignorance - use Jeffreys prior • Make measurements – Calculate mean, m, and standard deviation, s • Calculate posterior distribution – t distribution with, m, s, n = n -1, s / n,m t – Credible interval m t – Same numerical interval as frequentist – This is an objective Bayesian approach 0 .9 7 5 , n 1 0 .9 7 5 , n 1 s / n 10 Bayesian Successes • Insurance industry – Adjusting premiums • Cryptography and communications – Identifying messages in noise • Machine learning – Adaptation • Most exploit the iterative aspect • Prior distribution gradually ‘forgotten’ 11 Difference in meaning – Pt 1 Frequentist 95% of intervals include k Bayesian 95% chance that k lies in the interval Bayesian meaning closer to intuition 12 Difference in meaning - Pt 2 Frequentist: Parameter fixed, Data distributed (in error) Bayesian: Data fixed (known), Parameter distributed Bayesian model OK for distributed measurands, but incompatible with measurement, physics, chemistry,… 13 Difference in performance • Problem: expanded uncertainty in X+Y – xi: n1 samples drawn from N( 0, s1) – yi : n2 samples drawn from N( 0, s2) • Frequentist (GUM): – Use Welch-Satterthwaite approximation to give effective degrees of freedom • Bayesian (GUM-S1): – Convolve two t distributions with n1-1 and n2-1 degrees of freedom 14 Combining uncertainty • Coverage factor vs lo g 1 0 s 1 / n1 / s 2 / n 2 • GUM (dotted curve) < GUM-S1 (solid curve) 15 Combining uncertainty cont. • GUM is nearly always closer than GUM-S1 16 Summary • Advantages of Bayesian approach – – – – Incorporation of prior knowledge (not GUM-S1) Allows recursion/iteration (not GUM-S1) Greater breadth of applicability (but is model correct?) Closer to colloquial understanding of probability • Disadvantages – – – – – – Poorly understood Not consistent with physics and measurement Poorer coverage (for GUM-S1) Poorer for non-linear systems? (2 examples published) Inconsistent with GUM (loss of harmony) Computationally expensive 17 Where to from here? • The two methods are different and suit different purposes • Match the method to the purpose – For fixed parameters frequentist – For distributed parameters, subjective Bayesian • Objective method must go – Problems with coverage, non-linearity – Does not allow iteration or inclusion of prior information for Type A (baby out with bathwater) • Research required – Non-linearity, comparisons, correlation…? 18