Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Data Mining System
(Knowledge Data Discovery)
WXGC6307
Case Scenario
ABC Enterprise is a multinational company that offers multimedia
content services in several regions in Asia. It has more than 6
millions content subscribers. For a company of this size, another
major problem is to maintain good relationship with their
existing content subscribers. Every year, they have to offer good
content promotion to suit their customer needs. However, this is
a difficult task because they have huge collection of data about
their subscribers which have different needs and lifestyle.
Therefore, the CEO of the company, Mr. Ridzuan wishes that
there is a system that can be built to analyze enormous data
about their subscribers and can suggest what kind of content
promotions suitable for them.
Knowledge Discovery &
Data Mining
Knowledge Discovery (KD) is a process of
extracting previously unknown, valid, and
actionable (understandable) information
from large databases.
Data mining is a step in the KDD process
of applying data analysis and discovery
algorithms.
Relates to machine learning, pattern
recognition, statistics, data visualization
etc.
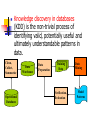
Knowledge discovery in databases
(KDD) is the non-trivial process of
identifying valid, potentially useful and
ultimately understandable patterns in
data.
Clean,
Collect,
Summarize
Operational
Databases
Data
Warehouse
Data
Preparation
Training
Data
Verification,
Evaluation
Data
Mining
Model
Patterns
Why Mine Data?
Huge amounts of data being collected and
warehoused
Walmart records 20 millions per day
health care transactions: multi-gigabyte databases
Mobil Oil: geological data of over 100 terabytes
Affordable computing
Competitive pressure
gain an edge by providing improved, customized
services
information as a product in its own right
Data Mining Methods
Prediction Methods
using some variables to predict unknown
or future values of other variables
Descriptive Methods
finding human-interpretable patterns
describing the data
Data Mining Tasks
Classification
Clustering
Association Rule Discovery
Sequential Pattern Discovery
1. Classification
Data defined in terms of attributes, one
of which is the class.
Find a model for class attribute as a
function of the values of
other(predictor) attributes, such that
previously unseen records can be
assigned a class as accurately as
possible.
Classification:Example
Classification: Direct Marketing
Goal: Reduce cost of soliciting (mailing) by
targeting a set of consumers likely to buy a
new product.
Data
for similar product introduced earlier
we know which customers decided to buy and
which did not {buy, not buy} class attribute
collect various demographic, lifestyle, and
company related information about all such
customers - as possible predictor variables.
Learn classifier model
2. Clustering
Given a set of data points, each having a set
of attributes, and a similarity measure among
them, find clusters such that
data points in one cluster are more similar to one
another
data points in separate clusters are less similar to
one another.
Similarity measures
Euclidean distance if attributes are continuous
Problem specific measures
Clustering:
Market Segmentation
Goal: subdivide a market into distinct subsets
of customers where any subset may
conceivably be selected as a market target to
be reached with a distinct marketing mix.
Approach:
collect different attributes on customers based on
geographical, and lifestyle related information
identify clusters of similar customers
measure the clustering quality by observing
buying patterns of customers in same cluster vs.
those from different clusters.
3. Association Rule Discovery
Given a set of records, each of which
contain some number of items from a
given collection:
produce dependency rules which will
predict occurrence of an item based on
occurences of other items
Association Rule Discovery
Marketing and Sales Promotion Application
4. Sequential Pattern Discovery
Given: set of objects, each associated
with its own timeline of events, find
rules that predict strong sequential
dependencies among different events,
of the form (A B) (C) (D E) --> (F)
Sequential Pattern Discovery:
Examples
sequences in which customers purchase
goods/services
understanding long term customer
behavior -- timely promotions.
In point-of--sale transaction sequences
Athletic Apparel Store:
(Shoes) (Racket, Racketball) -->
(Sports Jacket)
Data Mining Systems
Clementine (SPSS)
Data Miner (Statistica)
http://www.spss.com/spssbi/clementine/index.htm
http://www.statsoft.com/dataminer.html
RuleQuest (C5.0)
http://www.rulequest.com/
Limitation/Challenges
large data
high dimensionality
number of variables (features), number of cases
(examples)
multi gigabyte, terabyte databases
efficient algorithms, parallel processing
large number of features: exponential increase in
search space (potential for spurious patterns)
Use of domain knowledge
utilizing knowledge on complex data relationships,
known facts
Intelligence Density Dimension
Accuracy
Explainability
Flexibility
Response speed