Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
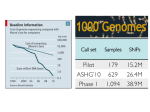
Supplementary Figures Supplementary Figure 1 Amplicon and library preparation. (a) Layout of the preconfigured primer plate. (b) Generation of individual patient libraries and preparation of lane pools for subsequent emulsion PCR and amplicon sequencing. Supplementary Figure 2 emPCR conditions and PTP layout. All 8 lane pools (6 lanes with study samples and 2 lanes with individual separate samples from each participating laboratory) were diluted to a final concentration of 4 x 106 molecules/µl. For subsequent emPCR 2.1 copies per bead were used. For all 8 lanes of one PTP A and B beads were processed separately and were combined after breaking and enrichment (upper panel). PTP layout after sequencing is given in the lower panel. Supplementary Figure 3 Distribution of generated amplicon sequence reads per patient. Data on the homogeneity of amplicons is given for a comparison of an experienced center using automated solutions for amplicon purification against a laboratory having no experience in 454 amplicon deep-sequencing. For an exemplary patient, the 31 amplicons (x-axis) and number of generated forward (A beads) and reverse (B beads) sequence reads is represented (yaxis). (a) Case #08, processed at an experienced center using automated solutions for amplicon purification. (b) Case #08, processed at a center having no experience in 454 amplicon deep-sequencing and using manual preparation procedures. The results demonstrate that experience and automation are of advantage for amplicon homogeneity. Supplementary Figure 4 Laboratory comparison by coverage plots. For all laboratories an output is given illustrating the coverage obtained for each amplicon in comparison to the remainder laboratories. Each figure (a-i) depicts one center (red bars) in comparison against the remainder 9 laboratories (grey bars). Supplementary Figure 5 Distinction of molecular mutations in subclones. The distribution of sequence reads for two distinct subclones in sample #10 is depicted. Sample #10 harbored 3 KRAS mutations in 2 subclones. Clone 1 harbored a KRAS G12C mutation in 11.5% of the reads (ranging from 8.8%13.6%). A second larger subclone containing two variants (L19F and T20S) was found to be mutated in the same exon in 21% (ranging from 16%-27%) of the reads. All three mutations were consistently detected in all 10 participating centers, regardless of high (a) or low (b) coverage achieved. The figure illustrates two exemplary centers with either high coverage (664-fold) or low coverage (139-fold), respecitvely. Like in Fig. 2 in the main article this example again demonstrates that mutational burden of the respective variants is equivalent between the two centers although the coverage is exceedingly different. Supplementary Figure 6 Bland-Altman analyses of 80 variants with sequence alterations ≥ 20%. Individual Bland-Altman analyses of all variants ≥ 20% were performed to investigate whether systematic differences in the percentages of reads detecting a variant existed among laboratories for the same sample. Each Bland–Altman plot thus is a visual representation of the consistency of the variant results between any two centers. For each comparison (a-i), the mean value of the 2 relative variant frequencies from a single patient sample at the 2 centers (x-axis) is plotted against the difference between the same 2 results (y-axis). The solid red horizontal line represents the overall mean of the differences, and the dashed red lines show the range containing the mean of the differences ±1.96 standard deviations, which is referred to as the limits of agreement. Depicted in each plot are the data for the 80 most likely variants as listed in Supplementary Data Spreadsheet 1. At most, two variants had to be excluded due to rare amplicon dropouts in one of the two centers included in the comparison. Supplementary Figure 7 Bland-Altman analyses of low-level variants. Bland-Altman analyses of all sequence variants < 20% were performed to investigate whether systematic differences in the percentages of reads detecting a variant existed among laboratories for the same sample. Each Bland–Altman plot thus is a visual representation of the consistency of the variant results between any two centers. (a-j) For each comparison, the mean value of the 2 relative variant frequencies from a single patient sample at the 2 centers (x-axis) is plotted against the difference between the same 2 results (y-axis). The solid red horizontal line represents the overall mean of the differences, and the dashed red lines show the range containing the mean of the differences ±1.96 standard deviations, which is referred to as the limits of agreement. Depicted in each plot are the data for 14 low-level variants as listed in Supplemental Data Table 2. At most, three variants had to be excluded due to rare amplicon dropouts in one of the two centers included in the comparison. Supplementary Figure 8 Standard deviation and coefficient of variation data. A total of 80 variants with frequencies > 20% and 14 variants with frequencies < 20% are depicted. The standard deviations of the low-level variants’ relative frequencies were comparable to those of the most likely variants with frequencies > 20%. Hence, the coefficient of variation increases for low-level variants. Top panel: Standard deviation; lower panel: coefficient of variation.