Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Chapter 4
Numerical
Descriptive
Techniques
1
4.2 Measures of Central Location
Usually, we focus our attention on two types of
measures when describing population
characteristics:
Central location (e.g. average)
Variability or spread
The measure of central location
reflects the locations of all the actual
data points.
2
4.2 Measures of Central Location
The measure of central location reflects the
locations of all the actual data points.
How?
With two data points,
the central location
But
if
the
third data
With one data point
should
fall inpoint
the middle
on the leftthem
hand-side
clearly the centralappears between
(in order
of
the
midrange,
it
should
“pull”of
location is at the point to reflect the location
the central
location
to the left.
itself.
both
of them).
3
The Arithmetic Mean
This is the most popular and useful measure of
central location
Sum of the observations
Mean =
Number of observations
4
The Arithmetic Mean
Sample mean
x
n
n
ii11xxii
nn
Sample size
Population mean
N
i1 x i
N
Population size
5
The arithmetic
mean
The Arithmetic Mean
• Example 4.1
The reported time on the Internet of 10 adults are 0, 7, 12, 5, 33,
14, 8, 0, 9, 22 hours. Find the mean time on the Internet.
x
10
i 1 xi
10
0x1 7x2
... 22
x10
11.0
10
• Example 4.2
Suppose the telephone bills of Example 2.1 represent
the population of measurements. The population mean is
x42.19
x38.45
... x45.77
i200
1
2
200
1 x i
200
200
43.59
6
The Median
The Median of a set of observations is the value that
falls in the middle when the observations are arranged
in order of magnitude.
Example 4.3
Comment
Find the median of the time on the internet Suppose only 9 adults were sampled
(exclude, say, the longest time (33))
for the 10 adults of example 4.1
Even number of observations
0, 0, 5,
0, 7,
5, 8,
7, 8,
9, 12,
14,14,
22,22,
33 33
8.59,, 12,
Odd number of observations
0, 0, 5, 7, 8 9, 12, 14, 22
7
The Mode
The Mode of a set of observations is the value that
occurs most frequently.
Set of data may have one mode (or modal class), or two
or more modes.
The modal class
For large data sets
the modal class is
much more relevant
than a single-value
mode.
8
The Mode The Mean, Median,
Mode
The Mode
Example 4.5
Find the mode for the data in Example 4.1. Here are the
data again: 0, 7, 12, 5, 33, 14, 8, 0, 9, 22
Solution
• All observation except “0” occur once. There are two “0”. Thus, the
mode is zero.
• Is this a good measure of central location?
• The value “0” does not reside at the center of this set
(compare with the mean = 11.0 and the mode = 8.5).
9
Relationship among Mean, Median, and Mode
If a distribution is symmetrical, the mean,
median and mode coincide
If a distribution is asymmetrical, and skewed
to the left or to the right, the three measures
differ.
A positively skewed distribution
(“skewed to the right”)
Mode Mean
Median
10
Relationship among Mean, Median, and Mode
If a distribution is symmetrical, the mean, median
and mode coincide
If a distribution is non symmetrical, and skewed
to the left or to the right, the three measures
differ.
A positively skewed distribution
(“skewed to the right”)
A negatively skewed distribution
(“skewed to the left”)
Mode
Mean
Median
Mean
Mode
Median
11
The Geometric Mean
This is a measure of the average growth rate.
Let Ri denote the the rate of return in period i
(i=1,2…,n). The geometric mean of the returns
R1, R2, …,Rn is the constant Rg that produces the
same terminal wealth at the end of period n as
do the actual returns for the n periods.
12
The Geometric Mean
The Geometric Mean
For the given series of rate of
returns the nth period return is
calculated by:
If the rate of return was Rg in every
period, the nth period return would
be calculated by:
n
(1 R1 )(1 R 2 )...( 1 R n ) (1 R g )
Rg is selected such that…
Rg n (1 R1)(1 R2 )...(1 Rn ) 1
13
4.3 Measures of variability
Measures of central location fail to tell the whole story
about the distribution.
A question of interest still remains unanswered:
How much are the observations spread out
around the mean value?
14
4.3 Measures of variability
Observe two hypothetical
data sets:
Small variability
The average value provides
a good representation of the
observations in the data set.
This data set is now
changing to...
15
4.3 Measures of variability
Observe two hypothetical
data sets:
Small variability
The average value provides
a good representation of the
observations in the data set.
Larger variability
The same average value does not
provide as good representation of the
observations in the data set as before.
16
The range
The range of a set of observations is the difference
between the largest and smallest observations.
Its major advantage is the ease with which it can be
But, how do all the observations spread out?
computed.
? to provide
Its major shortcoming?is its?failure
Largest
information onSmallest
the dispersion of the
observations
observation
observation
between the two end points.
The range cannot assistRange
in answering this question
17
The Variance
This measure reflects the dispersion of all the
observations
The variance of a population of size N x1, x2,…,xN
whose mean is is defined as
2
2
N
(
x
)
i 1 i
N
The variance of a sample of n observations
x1, x2, …,xn whose mean is x is defined as
s2
ni1( xi x)2
n 1
18
Why not use the sum of deviations?
Consider two small populations:
9-10= -1
11-10= +1
8-10= -2
12-10= +2
A measure of dispersion
A
Can the sum of deviations
agreesofwith
this
Be aShould
good measure
dispersion?
The sum
of deviations is
observation.
zero for both populations,
8 9 10 11 12
therefore, is not a good
…but
Themeasurements
mean of both in B
measure
of
arepopulations
moredispersion.
dispersed
is 10...
4-10 = - 6
16-10 = +6
7-10 = -3
then those in A.
B
4
Sum = 0
7
10
13
16
13-10 = +3
19
Sum = 0
The Variance
Let us calculate the variance of the two populations
2
2
2
2
2
2 (8 10) (9 10) (10 10) (11 10) (12 10)
A
2
5
2
2
2
2
2
2 (4 10) (7 10) (10 10) (13 10) (16 10)
B
18
5
Why is the variance defined as
the average squared deviation?
Why not use the sum of squared
deviations as a measure of
variation instead?
After all, the sum of squared
deviations increases in
magnitude when the variation
of a data set increases!!
20
The Variance
Let us calculate the sum
of squared
deviations
for both data sets
Which
data set has
a larger dispersion?
Data set B
is more dispersed
around the mean
A
B
1
2 3
1
3
5
21
The Variance
SumA = (1-2)2 +…+(1-2)2 +(3-2)2 +… +(3-2)2= 10
SumB = (1-3)2 + (5-3)2 = 8
SumA > SumB. This is inconsistent with the
observation that set B is more dispersed.
A
B
1
2 3
1
3
5
22
The Variance
However, when calculated on “per observation”
basis (variance), the data set dispersions are
properly ranked.
A2 = SumA/N = 10/5 = 2
B2 = SumB/N = 8/2 = 4
A
B
1
2 3
1
3
5
23
The Variance
Example 4.7
The following sample consists of the number of jobs
six students applied for: 17, 15, 23, 7, 9, 13. Finds its
mean and variance
Solution
x
i61 xi
ni1( x i
6
17 15 23 7 9 13 84
14 jobs
6
6
2
x
)
1
2
s
(17 14)2 (15 14)2 ...(13 14)2
n 1
6 1
33.2 jobs2
24
The Variance – Shortcut method
n
2
n
1
(
x
)
2
2
i1 i
s
x i
n 1 i1
n
2
1 2
17
15
...
13
2
2
17 15 ... 13
6 1
6
33.2 jobs2
25
Standard Deviation
The standard deviation of a set of observations is
the square root of the variance .
Sample standard dev iation: s s
2
Population standard dev iation:
2
26
Standard Deviation
Example 4.8
To examine the consistency of shots for a new
innovative golf club, a golfer was asked to hit 150
shots, 75 with a currently used (7-iron) club, and 75
with the new club.
The distances were recorded.
Which 7-iron is more consistent?
27
The Standard
Deviation
Standard Deviation
Example 4.8 – solution
Excel printout, from the
“Descriptive Statistics” submenu.
The innovation club is
more consistent, and
because the means are
close, is considered a
better club
Current
Mean
Standard Error
Median
Mode
Standard Deviation
Sample Variance
Kurtosis
Skewness
Range
Minimum
Maximum
Sum
Count
Innovation
150.5467
0.668815
151
150
5.792104
33.54847
0.12674
-0.42989
28
134
162
11291
75
Mean
Standard Error
Median
Mode
Standard Deviation
Sample Variance
Kurtosis
Skewness
Range
Minimum
Maximum
Sum
Count
150.1467
0.357011
150
149
3.091808
9.559279
-0.88542
0.177338
12
144
156
11261
75
28
Interpreting Standard Deviation
The standard deviation can be used to
compare the variability of several distributions
make a statement about the general shape of a
distribution.
The empirical rule: If a sample of observations has a
mound-shaped distribution, the interval
( x s, x s) contains approximately 68% of the measuremen ts
( x 2s, x 2s) contains approximately 95% of the measuremen ts
( x 3s, x 3s) contains approximately 99.7% of the measuremen ts
29
Interpreting Standard Deviation
Example 4.9
A statistics practitioner wants to describe the
way returns on investment are distributed.
The mean return = 10%
The standard deviation of the return = 8%
The histogram is bell shaped.
30
Interpreting Standard Deviation
Example 4.9 – solution
The empirical rule can be applied (bell shaped histogram)
Describing the return distribution
Approximately 68% of the returns lie between 2% and 18%
[10 – 1(8), 10 + 1(8)]
Approximately 95% of the returns lie between -6% and 26%
[10 – 2(8), 10 + 2(8)]
Approximately 99.7% of the returns lie between -14% and 34%
[10 – 3(8), 10 + 3(8)]
31
The Chebysheff’s Theorem
The proportion of observations in any sample that lie within
k standard deviations of the mean is at least
1-1/k2 for k > 1.
This theorem is valid for any set of measurements
(sample, population) of any shape!!
K
Interval
Chebysheff
Empirical Rule
1
2
3
x s, x s
x 2s, x 2s
x 3s, x 3s
at least 0%
at least 75%
at least 89%
(1-1/12)
(1-1/22)
(1-1/32)
approximately 68%
approximately 95%
approximately 99.7%
32
The Chebysheff’s Theorem
Example 4.10
The annual salaries of the employees of a chain of computer
stores produced a positively skewed histogram. The mean and
standard deviation are $28,000 and $3,000,respectively. What
can you say about the salaries at this chain?
Solution
At least 75% of the salaries lie between $22,000 and $34,000
28000 – 2(3000) 28000 + 2(3000)
At least 88.9% of the salaries lie between $$19,000 and
$37,000
28000 – 3(3000) 28000 + 3(3000)
33
The Coefficient of Variation
The coefficient of variation of a set of measurements is
the standard deviation divided by the mean value.
s
Sample coefficien t of variation : cv
x
Population coefficien t of variation : CV
This coefficient provides a proportionate measure of
variation.
A standard deviation of 10 may be perceived
large when the mean value is 100, but only
moderately large when the mean value is 500
34
4.4 Measures of Relative Standing
and Box Plots
Percentile
The pth percentile of a set of measurements is the
value for which
• p percent of the observations are less than that value
• 100(1-p) percent of all the observations are greater than
that value.
Example
• Suppose your score is the 60% percentile of a SAT test.
Then
40%
60% of all the scores lie here
Your score
35
Quartiles
Commonly used percentiles
First (lower)decile
First (lower) quartile, Q1,
Second (middle)quartile,Q2,
Third quartile, Q3,
Ninth (upper)decile
= 10th percentile
= 25th percentile
= 50th percentile
= 75th percentile
= 90th percentile
36
Quartiles
Example
Find the quartiles of the following set of
measurements 7, 8, 12, 17, 29, 18, 4, 27, 30, 2,
4, 10, 21, 5, 8
37
Quartiles
Solution
Sort the observations
2, 4, 4, 5, 7, 8, 10, 12, 17, 18, 18, 21, 27, 29, 30
The first quartile
15 observations
At most (.25)(15) = 3.75 observations
should appear below the first quartile.
Check the first 3 observations on the
left hand side.
At most (.75)(15)=11.25 observations
should appear above the first quartile.
Check 11 observations on the
right hand side.
Comment:If the number of observations is even, two observations
remain unchecked. In this case choose the midpoint between these
two observations.
38
Location of Percentiles
Find the location of any percentile using the formula
P
LP (n 1)
100
w hereLP is the location of the P th percentile
Example 4.11
Calculate the 25th, 50th, and 75th percentile of the data in
Example 4.1
39
Location of Percentiles
Example 4.11 – solution
After sorting the data we have 0, 0, 5, 7, 8, 9, 22, 33.
25
L 25 (10 1)
2.75
100
Values 0
0
Location 2
Location 1
3.75 5
2.75
3
Location 3
The 2.75th location
Translates to the value
(.75)(5 – 0) = 3.75
40
Location of Percentiles
Example 4.11 – solution continued
50
L 50 (10 1)
5.5
100
The 50th percentile is halfway between the fifth
and sixth observations (in the middle between 8
and 9), that is 8.5.
41
Location of Percentiles
Example 4.11 – solution continued
75
L 75 (10 1)
8.25
100
The 75th percentile is one quarter of the distance
between the eighth and ninth observation that is
14+.25(22 – 14) = 16.
Eighth
observation
Ninth
observation
42
Quartiles and Variability
Quartiles can provide an idea about the shape of
a histogram
Q1 Q2
Positively skewed
histogram
Q3
Q1
Q2
Q3
Negatively skewed
histogram
43
Interquartile Range
This is a measure of the spread of the middle
50% of the observations
Large value indicates a large spread of the
observations
Interquartile range = Q3 – Q1
44
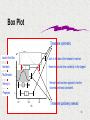
Box Plot
This is a pictorial display that provides the main
descriptive measures of the data set:
•
•
•
•
•
L - the largest observation
Q3 - The upper quartile
Q2 - The median
Q1 - The lower quartile
S - The smallest observation
1.5(Q3 – Q1)
S
Whisker
1.5(Q3 – Q1)
Q1
Q2 Q 3
Whisker
L
45
Box Plot
Example 4.14 (Xm02-01)
Bills
42.19
38.45
29.23
89.35
118.04
110.46
.
Smallest =. 0
.
Q1 = 9.275
Median = 26.905
Q3 = 84.9425
Largest = 119.63
IQR = 75.6675
Outliers = ()
Left hand boundary = 9.275–1.5(IQR)= -104.226
Right hand boundary=84.9425+ 1.5(IQR)=198.4438
-104.226
0
9.275
84.9425 119.63
26.905
198.4438
No outliers are found
46
Box Plot
Additional Example - GMAT scores
Create a box plot for the data regarding the GMAT scores of
200 applicants (see GMAT.XLS)
GMAT
512
531
461
515
.
.
.
Smallest = 449
Q1 = 512
Median = 537
Q3 = 575
Largest = 788
IQR = 63
Outliers = (788, 788, 766, 763, 756, 719, 712, 707, 703, 694, 690, 675, )
417.5 449
512-1.5(IQR)
512
537
575
669.5
575+1.5(IQR)
47
788
Box Plot
GMAT - continued
Q1
512
449
25%
Q2
537
50%
Q3
575
669.5
25%
Interpreting the box plot results
• The scores range from 449 to 788.
• About half the scores are smaller than 537, and about half are larger than
537.
• About half the scores lie between 512 and 575.
• About a quarter lies below 512 and a quarter above 575.
48
Box Plot
GMAT - continued
The histogram is positively skewed
Q1
512
449
25%
Q2
537
50%
Q3
575
669.5
25%
50%
25%
25%
49
Box Plot
Example 4.15 (Xm04-15)
A study was organized to compare the quality of
service in 5 drive through restaurants.
Interpret the results
Example 4.15 – solution
Minitab box plot
50
Box Plot
Jack in the Box5
Jack in the box is the slowest in service
Hardee’s
Hardee’s service time variability is the largest
C7
McDonalds
4
3
Wendy’s
2
Popeyes
1
Wendy’s service time appears to be the
shortest and most consistent.
100
300
200
C6
51
Box Plot
Times are symmetric
Jack in the Box5
Jack in the box is the slowest in service
Hardee’s
Hardee’s service time variability is the largest
C7
McDonalds
4
3
Wendy’s
2
Popeyes
1
Wendy’s service time appears to be the
shortest and most consistent.
100
300
200
C6
Times are positively skewed
52
4.5 Measures of Linear Relationship
The covariance and the coefficient of correlation
are used to measure the direction and strength
of the linear relationship between two variables.
Covariance - is there any pattern to the way two
variables move together?
Coefficient of correlation - how strong is the linear
relationship between two variables
53
Covariance
Population covariance COV(X, Y)
(x i x )(y i y )
N
x (y) is the population mean of the variable X (Y).
N is the population size.
(xi x)(y i y)
Sample cov ariance cov (x y, )
n-1
x (y) is the sample mean of the variable X (Y).
n is the sample size.
54
Covariance
Compare the following three sets
xi
yi
(x – x) (y – y) (x – x)(y – y)
2
6
7
13
20
27
-3
1
2
x=5
y =20
xi
yi
(x – x) (y – y) (x – x)(y – y)
2
6
7
27
20
13
-3
1
2
x=5
y =20
-7
0
7
21
0
14
Cov(x,y)=17.5
7
0
-7
-21
0
-14
Cov(x,y)=-17.5
xi
yi
2
6
7
20
27
13
Cov(x,y) = -3.5
x=5 y =20
55
Covariance
If the two variables move in the same direction,
(both increase or both decrease), the covariance
is a large positive number.
If the two variables move in opposite directions,
(one increases when the other one decreases),
the covariance is a large negative number.
If the two variables are unrelated, the covariance
will be close to zero.
56
The coefficient of correlation
Population coefficien t of correlatio n
COV ( X, Y)
xy
Sample coefficien t of correlatio n
cov(X, Y)
r
sx sy
This coefficient answers the question: How strong is
the association between X and Y.
57
The coefficient of correlation
+1 Strong positive linear relationship
COV(X,Y)>0
or r =
or
0
No linear relationship
-1 Strong negative linear relationship
COV(X,Y)=0
COV(X,Y)<0
58
The coefficient of correlation
If the two variables are very strongly positively
related, the coefficient value is close to +1
(strong positive linear relationship).
If the two variables are very strongly negatively
related, the coefficient value is close to -1 (strong
negative linear relationship).
No straight line relationship is indicated by a
coefficient close to zero.
59
The coefficient of correlation and the
covariance – Example 4.16
Compute the covariance and the coefficient of
correlation to measure how GMAT scores and
GPA in an MBA program are related to one
another.
Solution
We believe GMAT affects GPA. Thus
• GMAT is labeled X
• GPA is labeled Y
60
The coefficient of correlation and the
covariance – Example 4.16
Student
1
x
599
y
9.6
x2
y2
xy
358801
92.16
5750.4
2
689
8.8
474721
77.44 6063.2
cov(x,y)=(1/12-1)[67,559.2-(7587)(106.4)/12]=26.16
3
584
7.4
341056
54.76
4321.6
Sx = {(1/12-1)[4,817,755-(7587)2/12)]}.5=43.56
4
100
6310
Sy =………………………………………………….
similar631
to Sx =10
1.12 398161
593 xSy = 26.16/(43.56)(1.12)
8.8
351649 77.44
r = 11
cov(x,y)/S
= .5362 5218.4
12
683
8
466489
64
5464
Total
7,587
106.4
4,817,755
957.2
67,559.2
Shortcut Formulas
cov(x, y )
xi y i
1
xi y i
n 1
n
2
1
x
2
s2
x
i
n 1
n
61
The coefficient of correlation and the
covariance – Example 4.16 – Excel
Use the Covariance option in Data Analysis
If your version of Excel returns the population covariance and
variances, multiply each one by n/n-1 to obtain the
corresponding sample values.
Use the Correlation option to produce the correlation matrix.
Variance-Covariance Matrix
Population
values
GPA
GPA
1.15
GMAT
23.98
GMAT
1739.52
Sample
values
12 GPA
12-1
GMAT
GPA
GMAT
1.25
26.16
1897.66
62
The coefficient of correlation and the
covariance – Example 4.16 – Excel
Interpretation
The covariance (26.16) indicates that GMAT score
and performance in the MBA program are positively
related.
The coefficient of correlation (.5365) indicates that
there is a moderately strong positive linear
relationship between GMAT and MBA GPA.
63
The Least Squares Method
We are seeking a line that best fits the data when two
variables are (presumably) related to one another.
We define “best fit line” as a line for which the sum of
squared differences between it and the data points is
n
minimized.
2
Minimize( y i ŷ i )
i1
The actual y value of point i
The y value of point i
calculated from the
equation ŷ b b
i
0
x
1 i
64
The least Squares Method
Y
Errors
Errors
X
Different lines generate different errors,
thus different sum of squares of errors.
There is a line that minimizes the sum of squared errors 65
The least Squares Method
The coefficients b0 and b1 of the line that minimizes the
sum of squares of errors are calculated from the data.
n
b1
cov(x, y )
s x2
( x x )( y y )
i
i
i 1
,
n
( xi x ) 2
i 1
b0 y b1 x
n
where y
y
i 1
n
n
i
and x
x
i 1
n
i
66
The Least Squares Method
Example 4.17
b1
x
Find the least squares line for Example 4.16 (Xm04-16.xls)
cov(x, y )
s x2
xi
n
y
y
26 .16
.0138
1897 .2
Scatter Diagram
12
7,587
632 .25
12
y = 0.1496 + 0.0138x
10
8
6
106 .4
500
8.87
n
12
b0 y b1 x 8.87 (.0138 )( 632 .25 ) .145
i
600
700
800
67