
Slide 1
... [3] Fitness functions for evolving box-pushing behaviour Sprinkhuizen-Kuyper, I.G., Kortmann, R., and Postma, E.O. Proceedings of the Twelfth Belgium-Netherlands Artificial Intelligence ...
... [3] Fitness functions for evolving box-pushing behaviour Sprinkhuizen-Kuyper, I.G., Kortmann, R., and Postma, E.O. Proceedings of the Twelfth Belgium-Netherlands Artificial Intelligence ...

ppt - of Dushyant Arora
... can be seperated by a straight line • Perceptron cannot find weights for problems that are not linearly seperable. An example is the XOR problem. ...
... can be seperated by a straight line • Perceptron cannot find weights for problems that are not linearly seperable. An example is the XOR problem. ...

chaper 4_c b bangal
... binary properties of ORing and ANDing of inputs along with summing operations. Such functions can be built into the summation and transfer functions of a network. Seven major components make up an artificial neuron. These components are valid whether the neuron is used for input, output, or is in t ...
... binary properties of ORing and ANDing of inputs along with summing operations. Such functions can be built into the summation and transfer functions of a network. Seven major components make up an artificial neuron. These components are valid whether the neuron is used for input, output, or is in t ...


Thermo mechanical modeling of continuous casting with artificial
... I. Grešovnik, T. Kodelja, R. Vertnik and B. Šarler: A software Framework for Optimization Parameters in Material Production. Applied Mechanics and ...
... I. Grešovnik, T. Kodelja, R. Vertnik and B. Šarler: A software Framework for Optimization Parameters in Material Production. Applied Mechanics and ...

MACHINE INTELLIGENCE
... • Set the weights by either some rules or randomly • Set Delta = Error = actual output minus desired output for a given set of inputs • Objective is to Minimize the Delta (Error) • Change the weights to reduce the Delta • Information processing: pattern ...
... • Set the weights by either some rules or randomly • Set Delta = Error = actual output minus desired output for a given set of inputs • Objective is to Minimize the Delta (Error) • Change the weights to reduce the Delta • Information processing: pattern ...

Multilayer Networks
... network input layer. The network propagates the input pattern from layer to layer until the output pattern is generated by the output layer. If this pattern is different from the desired output, an error is calculated and then propagated backwards through the network from the output layer to the inp ...
... network input layer. The network propagates the input pattern from layer to layer until the output pattern is generated by the output layer. If this pattern is different from the desired output, an error is calculated and then propagated backwards through the network from the output layer to the inp ...

WEKA - WordPress.com
... computational model that tries to simulate the structure and/or functional aspects of biological neural networks. • ANN consists of an interconnected group of artificial neurons and processes information using a connectionist approach to computation [10]. • ANN is an adaptive system that can change ...
... computational model that tries to simulate the structure and/or functional aspects of biological neural networks. • ANN consists of an interconnected group of artificial neurons and processes information using a connectionist approach to computation [10]. • ANN is an adaptive system that can change ...
Slide ()
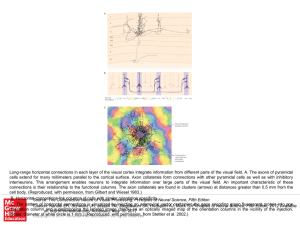
... Long-range horizontal connections in each layer of the visual cortex integrate information from different parts of the visual field. A. The axons of pyramidal cells extend for many millimeters parallel to the cortical surface. Axon collaterals form connections with other pyramidal cells as well as w ...
... Long-range horizontal connections in each layer of the visual cortex integrate information from different parts of the visual field. A. The axons of pyramidal cells extend for many millimeters parallel to the cortical surface. Axon collaterals form connections with other pyramidal cells as well as w ...

Lecture 9 Unsupervis..
... If the learning rate is constant , then the winning unit that responds to a pattern may continue changing during training. If the learning rate is decreasing with time, it may become too small to update cluster centres when new data of different probability are ...
... If the learning rate is constant , then the winning unit that responds to a pattern may continue changing during training. If the learning rate is decreasing with time, it may become too small to update cluster centres when new data of different probability are ...

Self Organized Maps (SOM)
... proposed by Teuvo Kohonen, known as Kohanen networks They provide a way of representing multidimensional data in much lower dimensional space, such as one or two dimensions. ...
... proposed by Teuvo Kohonen, known as Kohanen networks They provide a way of representing multidimensional data in much lower dimensional space, such as one or two dimensions. ...


ReinforcementLearning_part2
... Only two basic rules 1. Capture rule: stones that have no liberties ->captured and removed from board 2. ko rule: a player is not allowed to make a move that returns the game to the previous position ...
... Only two basic rules 1. Capture rule: stones that have no liberties ->captured and removed from board 2. ko rule: a player is not allowed to make a move that returns the game to the previous position ...

Neural Network for Winner take All Competition using Palm Print
... bound of the GEMNET is always greater than that of the MAXNET. The MAXNET requires more iteration to reach the convergence; its error bound will be further reduced. The GEMNET is much more robust to the offset error than the MAXNET. The offset variation is the common phenomenon of the non ideal char ...
... bound of the GEMNET is always greater than that of the MAXNET. The MAXNET requires more iteration to reach the convergence; its error bound will be further reduced. The GEMNET is much more robust to the offset error than the MAXNET. The offset variation is the common phenomenon of the non ideal char ...

Computational intelligence meets the NetFlix prize IEEE
... Fuzzy ART (FA) incorporates fuzzy set theory into ART and extends the ART family by being capable of learning stable recognition clusters in response to both binary and realvalued input patterns with either fast or slow learning. The basic FA architecture consists of two-layer nodes or neurons, the ...
... Fuzzy ART (FA) incorporates fuzzy set theory into ART and extends the ART family by being capable of learning stable recognition clusters in response to both binary and realvalued input patterns with either fast or slow learning. The basic FA architecture consists of two-layer nodes or neurons, the ...


Print this Page Presentation Abstract Program#/Poster#: 671.09/EE5
... orientation-tuned neurons to drifting gratings. In particular, we investigated the impact of the pinwheel structure on single cell responses. We assumed for simplicity that the pinwheels are organized in a square lattice, though similar results were obtained for other geometries. The parameters of t ...
... orientation-tuned neurons to drifting gratings. In particular, we investigated the impact of the pinwheel structure on single cell responses. We assumed for simplicity that the pinwheels are organized in a square lattice, though similar results were obtained for other geometries. The parameters of t ...

PowerPoint
... • Output units compete with one another. • These are winner takes all units (grandmother cells) ...
... • Output units compete with one another. • These are winner takes all units (grandmother cells) ...

YAPAY SİNİR AĞLARINA GİRİŞ
... real world applications. This may make machines more powerful, relieve humans of tedious tasks, and may even improve upon human performance. These should not be thought of as competing goals. We often use exactly the same neural networks and techniques for both. Frequently progress is made when the ...
... real world applications. This may make machines more powerful, relieve humans of tedious tasks, and may even improve upon human performance. These should not be thought of as competing goals. We often use exactly the same neural networks and techniques for both. Frequently progress is made when the ...

PowerPoint
... • Output units compete with one another. • These are winner takes all units (grandmother cells) ...
... • Output units compete with one another. • These are winner takes all units (grandmother cells) ...

Syllabus P140C (68530) Cognitive Science
... – Demos of learning digits – Demos of learning faces – Demos of learned movements Geoff Hinton ...
... – Demos of learning digits – Demos of learning faces – Demos of learned movements Geoff Hinton ...

Neural Networks - School of Computer Science
... A typical neural network will have several layers an input layer, one or more hidden layers, and a single output layer. In practice no hidden layer: cannot learn non-linear separable one-three layers: more practical use more than five layers: computational expensive ...
... A typical neural network will have several layers an input layer, one or more hidden layers, and a single output layer. In practice no hidden layer: cannot learn non-linear separable one-three layers: more practical use more than five layers: computational expensive ...

The rise of neural networks Deep networks Why many layers? Why
... difficult to overfit, even for a very large network. Unfortunately, training data can be expensive or difficult to acquire, so this is not always a practical option. Another approach is to reduce the number of hidden neurons (hence the number of degrees of freedoms). However, large networks have the ...
... difficult to overfit, even for a very large network. Unfortunately, training data can be expensive or difficult to acquire, so this is not always a practical option. Another approach is to reduce the number of hidden neurons (hence the number of degrees of freedoms). However, large networks have the ...


Presentation
... system using a large number of neurons This allows for robustness – an ability, for example, to recognize a slightly deformed square as still being essentially a square ...
... system using a large number of neurons This allows for robustness – an ability, for example, to recognize a slightly deformed square as still being essentially a square ...