

Finding the t-value having area 0.05 to it`s right
... much variability we will get over repeated sampling) • If we know the shape and parameters (e.g., mean and standard deviation) of the sampling distribution of a statistic, we can derive the position of a particular statistic in the overall distribution. ...
... much variability we will get over repeated sampling) • If we know the shape and parameters (e.g., mean and standard deviation) of the sampling distribution of a statistic, we can derive the position of a particular statistic in the overall distribution. ...

Quantitative Methods for Economic Analysis - 1 (EC3 B03) UNIVERSITY OF CALICUT
... b) the grades are a statistic d) the grades are a population 22. What method is used to sample a population so that it is representative of the population a) samples are chosen at random from the population b) every other element in a population is chosen c) all but the observations that have the lo ...
... b) the grades are a statistic d) the grades are a population 22. What method is used to sample a population so that it is representative of the population a) samples are chosen at random from the population b) every other element in a population is chosen c) all but the observations that have the lo ...




Chapters 6 -7 - Department of Agriculture and Water Resources
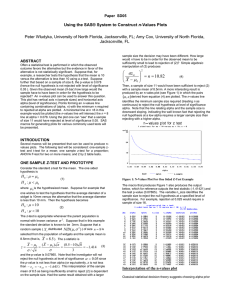
... accuracy and numerical stability of the statistical algorithms in EXCEL; based on the results of rigorous testing, McCullough and Wilson (1999) concluded that ‘persons desiring to conduct statistical analyses of data are advised not to use EXCEL’. However, while this is important when accuracy to m ...
... accuracy and numerical stability of the statistical algorithms in EXCEL; based on the results of rigorous testing, McCullough and Wilson (1999) concluded that ‘persons desiring to conduct statistical analyses of data are advised not to use EXCEL’. However, while this is important when accuracy to m ...

Note
... (F=Far and N=Near) defined by PROXIM. It also shows how many values in each group are missing - in other words how many have unknown values of PEFR. It often happens that not all data in a study are recorded for each individual: items may have been missed, or incorrectly recorded. During analysis su ...
... (F=Far and N=Near) defined by PROXIM. It also shows how many values in each group are missing - in other words how many have unknown values of PEFR. It often happens that not all data in a study are recorded for each individual: items may have been missed, or incorrectly recorded. During analysis su ...






Brian`s Quick and Easy Statistics Recipes
... are the odds of getting two distributions of the same thing that were that different). Or in other words we can show that the null hypothesis is very unlikely to be true. Null Hypothesis: There is no real difference between the two groups or no real effect of the treatment. There is always some poss ...
... are the odds of getting two distributions of the same thing that were that different). Or in other words we can show that the null hypothesis is very unlikely to be true. Null Hypothesis: There is no real difference between the two groups or no real effect of the treatment. There is always some poss ...





Lecture 3 - Bauer College of Business
... (married) respondents fell in the high-purchase category Do unmarried respondents purchase more fashion clothing? A third variable, the buyer's sex, was introduced As shown in Table 15.7, - 60% (25%) of unmarried (married) females fell in the ...
... (married) respondents fell in the high-purchase category Do unmarried respondents purchase more fashion clothing? A third variable, the buyer's sex, was introduced As shown in Table 15.7, - 60% (25%) of unmarried (married) females fell in the ...

Exercise #2
... c. Smooth and filter the data. Like explained in class in tutorial 11, usually we would like to filter out noise from the real phenomena. Think about what are the frequencies of your measured phenomena, and what are the frequencies of the noise, can you separate between the two and filter out the no ...
... c. Smooth and filter the data. Like explained in class in tutorial 11, usually we would like to filter out noise from the real phenomena. Think about what are the frequencies of your measured phenomena, and what are the frequencies of the noise, can you separate between the two and filter out the no ...



