Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
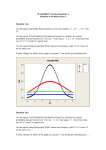
Lab Activity 2: Probability Plots and Sampling Distributions Feel free to work together on lab activities! Before you raise your hand to ask me, try to learn from one another! Normal Probability Plots In Sections 7.3 and 7.4, a central question is whether observations come from a normal distribution. Although there are various ways to test for normality, the graphical method of normal probability plots is the best method in my opinion. This method is covered in Section 4.6, but we’ll hit the high points below. 1. The idea is this: If a sample is really drawn from a normal distribution, then the pth percentile of the sample should match closely with the pth percentile of a truly normal population. Plotting one against the other should result in a straight line. Furthermore, it doesn’t matter which “truly normal population” we compare with, since any normal population is just a linear combination of any other. Start Minitab. Construct a normal probability plot “by hand” as follows: First, obtain a sample of size 100 from a normal distribution with mean 400 and standard deviation 20 and store it in column C1. Go to Calc > Random Data > Normal…. These data will go on the X-axis after they are sorted. Sort by going to Calc > Sort… and entering C1 in three separate boxes: “sort”, “store in”, and “sort by”. Next, obtain the percentiles of the standard normal distribution that will go on the Y-axis as explained in the box at the bottom of page 192. Generate a series of values (i-.5)/n for n=100 and i=1, …, 100 by going to Calc > Make Patterned Data > Simple set of numbers…. The patterned data should go from .5/100 to 99.5/100 in steps of 1/100 and they should be stored in column C2. Next, obtain the corresponding standard normal quantiles by going to Calc > Probability Distributions > Normal…. Obtain the inverse cumulative probability values corresponding to column C2, then store the results in column C3. Finally, with the data in C1 and the true standard normal percentiles in C3, produce a normal probability plot, which is simply a scatterplot with the data on one axis (often the x-axis) and the percentiles on the other axis (often the y-axis). A scatterplot is produced by going to Graph > Plot…. Attach your normal probability plot below, noting its straight-line appearance. "Handmade" normal probability plot 3 2 C3 1 0 -1 -2 -3 350 400 450 C1 2. Do #88 (from Chapter 4) in Minitab. Ordinarily it’s not necessary to do probability plots by hand! Enter the values in the fourth column of the worksheet. Go to Graph > Probability Plot…. Enter “C4” in the “Variables” box and make sure that the distribution is set to “Normal”. To make the necessary calculations (square root and cubed root) in Minitab, go to Calc > Calculator. To obtain the square root of the data values, choose “Square root” from the list of functions, enter “C4” inside the parentheses, and “Store result in” C5. There is no function in the list for cubed root, but you can raise C4 to the 1/3 power instead and store the result in C6. In Minitab, the double-star (**) button is the same as a ^ (raises a value to a power). Copy and paste your three normal probability plots, and comment on them below. (a) The plot below shows an obvious curvature, indicating that normality is probably not a safe assumption. (b) The square-root-transformed plot below looks less curved than the original, though there is still a slight curvature evident. (c) The cube-root-transformed plot below is the straightest of the three. If we’re trying to transform the data to normality, the cube root looks like the best bet. Sampling distributions We have been learning about the distribution of X . The distributions of statistics such as X are often referred to sampling distributions, because their randomness is solely the result of the fact that they are based on the values found in a random sample. 3. IQ scores for PSU students are normally distributed with mean 100 and standard deviation 15. Using the empirical rule (p. 167), sketch by hand a picture of this distribution, giving the correct scale on the horizontal axis. Here is a sketch: 55 70 85 100 115 130 145 What would the sampling distribution of the sample mean IQ look like for repeated samples of 16 PSU students? Go to Calc > Random Data > Normal…. Generate 10,000 rows of data, enter the mean and standard deviation of IQ scores, and store the values in columns C7-C22. (Note: You can actually type “C7-C22”.) Each row (between C7-C22) is a sample of size 16 from the population. To calculate the mean IQ for each sample, go to Calc > Row Statistics…. You want to calculate the mean of C7-C22 (“Input variables” box) and store the result in column C23. Now, create a histogram of the values in C23 (Graph > Histogram…). This histogram gives you an approximation of the sampling distribution of the sample mean IQ ( X ) for repeated samples of 16 PSU students! Print and attach this histogram. Below, describe the shape, location, and spread of the histogram (in comparison to the picture of the population distribution you drew above). Here is the histogram: 600 Frequency 500 400 300 200 100 0 85 95 105 115 C23 Now, using the theory presented at the end of lecture on Wednesday, give by hand the approximate shape, the mean, and the standard deviation of the sampling distribution of X for repeated samples of size n = 16. (Hint: CENTRAL LIMIT THEOREM!) According to the central limit theorem, X is approximately normally distributed (in this case, it’s EXACTLY normally distributed because the population itself is normally distributed). The mean and standard deviation of the distribution of X are 100 and 15/sqrt(16)=3.75, respectively.