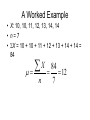Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
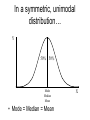
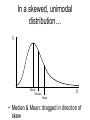
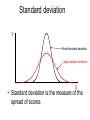
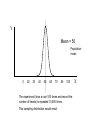
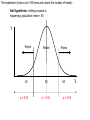
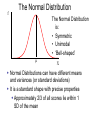
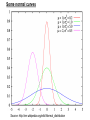
Science & Statistics in Psychology:Lecture 5 Variability and inferential statistics Dr Caleb Owens Consultation: Wednesdays 9-10am [email protected] Lecture Plan 1. Theory & Evidence : Science and pseudoscience; the importance of a rationale 2. The power of a name : Measurement and constructs 3. A thousand zeros : Types of research design; internal and external validity 4. Predictions : Hypotheses in science; the null hypothesis; the importance of a disprovable hypothesis 5. The coin toss : Understanding variability in sampling and measurement; probability and the appeal to ignorance 6. Too much of a good thing : Statistical power; Practical significance Build up knowledge about current theories and evidence Design experiment Conceive of experimental hypothesis Test null hypothesis Decide if findings are statistically significant Decide if findings are practically significant Draw conclusions Lecture 5 - Outline • Descriptive statistics – Central tendency • Mean • Mode • Median – Variability • Range • Variance • Standard deviation • Distributions – Describing distributions (skew) – The normal distribution – Deviation from the mean and probability • Inferential statistics – The sampling distribution – The P-value – Making a statistical decision Descriptive statistics • Summarize a collection of data – How many scores were there? (n) – What is the difference between the highest and lowest score (range) – What is the most common score (mode) – What is the ‘middle’ score (median) – What number is least different to all the scores? (mean/average) Descriptive statistics: Measures of Central Tendency Number of children in families 2 2 3 2 1 2 0 4 • How many scores? (n=8) • The range? (4-0=4) • Mode? (2) • Mean? (2+2+3+2+1+2+0+4 / 8) (16/8) =2 • Median? (2) Descriptive statistics just summarize a group of scores and nothing more Numerical Indices of Central Tendency • Mode – Score with the highest frequency (most common score) X 4 f 1 X 4 f 2 5 6 7 2 2 3 5 6 7 1 1 1 8 9 10 0 1 1 8 2 Mode = 4, 8 Mode = 7 This set of scores is ‘bimodal’ Advantages & Disadvantages of the Mode • Advantages: – By definition it is a score that actually occurred – Represents the largest number of people – Can be used with any scale • Disadvantages – Depends on how we group the data • E.g. if all cancers are grouped together it becomes the most common way to die; if considered separately road fatalities begin to feature Numerical Indices of Central Tendency • Median – The Middle Score X 4 5 6 7 8 9 10 f 1 2 2 3 0 1 1 Median = 6 X 4 5 6 7 8 Median = 6.5 Median location = N+1 / 2 (where N is the number of numbers) f 2 1 1 1 2 Advantages & Disadvantages of the Median • Advantages: – Not disproportionately affected by extreme scores – Only requires an ordinal scale • Disadvantages – Not as easy to use in calculations as the mean – Not as efficient as the mean – the mean is better for estimating population means by using a sample Numerical Indices of Central Tendency • Mean – the balance point of the distribution X n • = Sigma = Sum • The mean () is equal to the sum of all scores ( X) divided by the number of scores (n) A Worked Example • X: 10, 10, 11, 12, 13, 14, 14 • n=7 • X = 10 + 10 + 11 + 12 + 13 + 14 + 14 = 84 X n 84 12 7 Advantages & Disadvantages of the Mean • Advantages: – Easy to manipulate mathematically – Good for estimating a population mean from samples • Disadvantages – Easily affected by extreme values – Requires at least an interval scale Warning about Means • Time taken to complete a test (minutes): 1 2 3 3 3 4 5 4 54 • Mean = Median = Mode = 3 • But if someone falls asleep! 1 2 3 3 3 • Mean = 10 (Median & Mode = 3) Applying Central Tendency… • With different scales of measurement Scale of Measurement Nominal Index of Central Tendency Mode Ordinal Mode, Median Interval Mode, Median, Mean Ratio Mode, Median, Mean • Never over-interpret means – Means do not tell you the nature of the distribution Females Males Frequency Y Performance X Understanding variability • Scores on a hard class quiz • 16 students • Mean = 94/16 = 5.875 9 7 8 10 7 5 6 6 2 7 6 5 1 4 5 6 How many students received each score? • 1 • 2 • 3 • 4 • 5 • 6 • 7 • 8 • 9 • 10 / / / /// //// /// / / / (Frequency) Number of people who got each score Frequency Distribution Y Scores possible X Shapes of distributions Symmetrical Distributions Y X Shapes of distributions Skewed Distributions (Frequency distributions) Positive Skew Negative Skew In a symmetric, unimodal distribution… Y 50% 50% Mode Median Mean • Mode = Median = Mean X In a skewed, unimodal distribution… Y Mode Median X Mean • Median & Mean: dragged in direction of skew PSYC1001 Quiz Results 2010 Understanding variability Y • • • X Red line: scores spread out more, more variability Black line: scores tightly packed around mean, less variability These two different distributions have the same mean and mode, so how can we describe them to show the difference? Standard deviation Y Small standard deviation Large standard deviation X • Standard deviation is the measure of the spread of scores Class quiz : no one studies • 1 • 2 • 3 • 4 • 5 • 6 • 7 • 8 • 9 • 10 / / // / /// //// /// / // / More variability: higher standard deviation Class quiz : many students copy • 1 • 2 • 3 • 4 • 5 • 6 • 7 • 8 • 9 • 10 / ///// ///////// /// / Less variability: smaller standard deviation PSYC1001 Quiz Results 2010 Measures of variability • Range – Highest score minus the lowest • Standard Deviation – The average deviation of scores around the mean • Standard error – The average deviation of means around a population mean Understanding variability • Measurement is inexact (instruments, errors) • Noise is always present • Behaviour is not consistent • We struggle to find patterns in a chaotic world Challenges facing inferential statistics • We take a sample from a population • Is the sample representative (Was it selected in an unbiased manner? Is it large enough?) • See Lecture 4 : External Validity • How do we know if differences or effects in the sample reflect real differences in the population, or have just been caused by sampling error? – Understanding the variability we expect from sampling alone vs the variability we expect if there were a real effect present is the challenge The role of variability in inferential statistics • • • You wish to test the usefulness of two different psychotherapies for relieving depression You randomly allocate ten participants to each therapy You obtain the following improvement scores (a higher score means they became less depressed) Therapy A 0 2 5 3 Therapy B 5 12 -12 -4 4 6 -2 0 -1 3 5 0 13 -4 2 3 Therapy A Mean = 2 SD = 2.5 -12 -10 -8 -6 -4 -2 0 2 4 6 8 10 12 Mean = 2 Therapy B SD = 7.2 -12 -10 -8 -6 -4 -2 0 2 4 6 8 10 12 What is inferential statistics? • We construct a hypothesis about an effect in the population • We select a sample from that population • We measure the sample and use the values we obtain from the sample to draw inferences about the population • We would like to say: “On the basis of what we have observed in our sample, we can make this conclusion about the population….” The sampling distribution • So far we have considered a spread of raw scores within an individual experiment • Since the question for inferential statistics is: what conclusion can we make about the population from our sample, we need to consider the distribution of sample means from each experiment A distribution of raw scores X XXXXX XXXXXXX XXXXXXXXX XXXXXXXXXXX XXXXXXXXXXXX XXXXXXXXXXXXXXXXX Mean = M Sample mean Raw scores A distribution of sample means: The sampling distribution M MMM MMMMM MMMMMM MMMMMMMM MMMMMMMMMM MMMMMMMMMMMMM Sample means Mean = Population mean • Raw score distribution • Sampling distribution – Shows variability across individuals – Is real – Shows us the likelihood of obtaining a particular score – Shows variability across experiments – Is hypothetical: You would never run the same experiment so many times – Shows us the likelihood of obtaining an experiment result if the null is true See previous lecture The coin toss • We hypothesize that a particular coin is “unbiased” – that is, we expect that if we toss it there is a equal (50/50) chance that it will turn up heads or tails • We can take a ‘sample’ of the coins behaviour, by tossing it 100 times • If the coin is fair how many times would we expect it to turn up heads? • If we do not obtain that exact number from our sample, is that a problem? Y Mean = 50 Population mean 0 20 30 40 50 60 70 80 100 The experiment (toss a coin 100 times and record the number of heads) is repeated 10,000 times. This sampling distribution would result. X We tolerate a degree of variability close to the expected mean But beyond a certain point we decide something is happening Y Mean = 50 Population mean 0 20 30 40 50 60 70 80 100 The experiment (toss a coin 100 times and record the number of heads) is repeated 10,000 times. This sampling distribution would result. X The experiment (toss a coin 100 times and record the number of heads) Null hypothesis: nothing unusual is happening: population mean = 50 Y Reject 40 Since this is a frequency distribution of all possible sample means, the ‘height’ of the line indicates the likelihood of getting a particular result. That’s why there’s a bump in the middle – the hypothesized population mean is the most likely result! Retain Reject 50 60 X The experiment (toss a coin 100 times and record the number of heads) Null hypothesis: nothing unusual is happening: population mean = 50 Y Reject 40 p < 0.05 Retain Reject 50 60 p > 0.05 p < 0.05 X Possible outcomes • Sample value: 53 heads – Statistical test: p = 0.91 – We would retain our null hypothesis that it is a fair coin. We have not found any evidence to suggest it is not. • Sample value: 65 heads – Statistical test: p = 0.022 – We would reject our null hypothesis that it is a fair coin. We have found evidence to suggest that it is biased toward heads The p-value • A small p-value (0.002, 0.01, 0.045) means: it is highly improbable that we obtained our result by chance alone • A large p-value (0.06, 0.12, 0.67) means: it is probable that we obtained our result by chance alone • The usual cut off for psychology is 0.05. This is a convention, there is no mathematical reason for it. The p-value • The cutoff of 0.05 means, that if there is less than a 5% chance that our result is due to chance, we will say something is happening: we will reject the null hypothesis (see Lecture 4). • If there is more than 5% chance that our result is simply due to chance, we will consider that the result is unreliable and possibly represents nothing more than sampling error: we will retain the null hypothesis Calculating the p-value • Understand what the p-value is and how it is used • You need a lot of information to work out a pvalue (i.e. all the data) – So no you don’t need to know how to do it • Even in 2nd year you’ll be using software to do it • But how is it that we can estimate the likelihood of outcomes on hypothetical sampling distributions? – We use what we know about the normal curve f The Normal Distribution The Normal Distribution is: • Symmetric • Unimodal • ‘Bell-shaped’ X Normal Distributions can have different means and variances (or standard deviations) It is a standard shape with precise properties Approximately 2/3 of all scores lie within 1 SD of the mean Some normal curves Source: http://en.wikipedia.org/wiki/Normal_distribution Source: http://en.wikipedia.org/wiki/Normal_distribution There’s also a good diagram like this in the appendix of Weiten Appendix B page A10 Are we certain? • Science deals with probabilities – Is it possible that for a lucky 100 tosses, we just got more heads in our sample, and it is still a fair coin? • YES – Is that probable? • NO • Science does not deal with certainty. Science never proclaims certainty. Nature of evidence _____________ Conclusion Slight evidence Modest evidence Overwhelming evidence “Something is happening!” Too liberal – too excited by chance. Driven by confirmation bias to confirm a belief. Reasonable scientific conclusion. Finding warrants further investigation. Solid scientific conclusion. Phenomenon is robust. “Nothing is happening!” Reasonable conclusion, result is attributed to chance Possibly too conservative to ignore something not caused by chance. Way too conservative. Denial of the overwhelming evidence may be driven by a strong belief. The point at which we change our mind is the challenge inferential statistics faces