Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
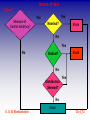
© .S. B. Bhattacharjee Ch 4_1 © .S. B. Bhattacharjee Ch 4_2 What is meant by a measure of central tendency? An average is frequently referred to as a measure of central tendency or central value. This is a single value which is considered the most representative or typical value for a given set of data. It is the value around which data in the set tend to cluster. For example: The average starting salary for social workers is TK.15,000 per Year and it gives some idea of how much variety or heterogeneity there is in the distribution ) © .S. B. Bhattacharjee Ch 4_3 What are the objectives of averaging? The following are two main objectives of the study of average: To get one single value that describes the characteristics of the entire data. Measures of central value, by condensing the mass of data in one single value, enable us to get an idea of the entire data. Thus one value can represent thousands, lakhs and even millions of values. For example: It is impossible to remember the individual incomes of millions of earning people of Bangladesh and even if one could do it there is hardly any use. But if the average income is obtained, we get one single value that represents the entire population. Such a figure would throw light on the standard of living of an average Bangladeshi. © .S. B. Bhattacharjee Ch 4_4 What are objectives of averaging? To facilitate comparison. Measures of central value, by reducing the mass of data in one single figure, enable comparisons to be made. Comparison can be made either at a point of time or over a period of time. For example: The figure of average sales for December may be compared with the sales figures of previous months or with the sales figure of another competitive firm. © .S. B. Bhattacharjee Ch 4_5 What should be the properties of a good average? Since an average is a single value representing a group of values, it is desirable that such a value satisfies the following properties: It should be easy to understand: Since statistical methods are designed to simplify complexity, it is desirable that an average be such that can be readily understood, its use is bound to be very limited. It should be simple to compute: Not only an average should be easy to understand but it also should be simple to compute so that it can be used widely. © .S. B. Bhattacharjee Ch 4_6 What should be the properties of a good average? It should be based on all the observations: The average should depend upon each and every observation so that if any of the observation is dropped average itself is altered. It should be rigidly defined: An average should be properly defined so that it has one and only one interpretation. It should preferably be defined by an algebraic formula so that if different people compute the average from the same figures they all get the same answer (Barring arithmetical mistakes). © .S. B. Bhattacharjee Ch 4_7 What should be the properties of a good average? It should be capable of further algebraic treatment: We should prefer to have an average that could be used for further statistical computations. For example: If we are given separately the figures of average income and number of employees of two or more companies we should be able to compute the combined average. © .S. B. Bhattacharjee Ch 4_8 What should be the properties of a good average? It should have sampling stability: We should prefer to get a value which has what the statisticians call ‘Sampling stability’. This means that if we pick 10 different groups of college students, and compute the average of each group, we should expect to get approximately the same values. It should not be unduly affected by the presence of extreme values: Although each and every observation should influence the value of the average, none of the observations should influence it unduly. If one or two very small or very large observations unduly affect the average, i.e., either increase its value or reduce its value, the average cannot be really typical of the entire set of data. In other words, extremes may distort the average and reduce its usefulness. © .S. B. Bhattacharjee Ch 4_9 What are various measures of central tendency ? The following are the measures of central tendency which are generally used in Business: Mean Arithmetic mean Geometric mean Harmonic mean Median Mode © .S. B. Bhattacharjee Ch 4_10 How would you select a specific measure of central tendency? Selection of a measure of central tendency largely depends on the nature of data. Continued……. © .S. B. Bhattacharjee Ch 4_11 Nature of data Figure:1 Measure of Central tendency? Yes Yes Nominal? Mode No Yes No Mode Ordinal? No Distribution Skewed? Yes No Mean © .S. B. Bhattacharjee Ch 4_12 What are various types of averages or means? Mean Arithmetic mean Geometric mean Harmonic mean Continued……. © .S. B. Bhattacharjee Ch 4_13 What is arithmetic mean? The arithmetic mean, often simply referred to as mean, is the total of the values of a set of observations divided by their total number of observations. © .S. B. Bhattacharjee Ch 4_14 What are the methods of computing arithmetic mean? For ungrouped data, arithmetic mean may be computed by applying any of the following methods: Direct method Short-cut method © .S. B. Bhattacharjee Ch 4_15 X 1 , X 2 , ...... X N What is direct method? Thus, if X 1 , X 2 , ...... X N represent the values of N items or observations, the arithmetic mean denoted by X is defined as: N X X 1 X 2 ....... X N © .S. B. Bhattacharjee N Xi i 1 N Ch 4_16 Example: The monthly income (in Tk) of 10 employees working in a firm is as follows: 4487 4489 4493 4502 4446 4475 4492 4572 4516 4468 Find the average monthly income. Applying the formula we get: X 4487+4493+4502+4446+4475+4492+4572+4516+4468 +4489 = 44.949 X X N 44940 4494 10 Hence the average monthly income is Tk.4494. © .S. B. Bhattacharjee Ch 4_17 What is short cut method? A short cut is one in which the arithmetic mean is calculated by taking deviations from any arbitrary point . The formula for computing mean by short cut method is as follows: d X A N d = (X – A ) Where , and A = Arbitrary point (or assumed mean) It should be noted that any value can be taken as arbitrary point and the answer would be the same as obtained by the direct method. © .S. B. Bhattacharjee Ch 4_18 Example: 2 Calculation of average monthly income by the short– cut method from the following data. In this case 4460 is taken as the arbitrary point. Calculation of average income X (X - 4460) (TK) (TK) 4487 +27 Assumed mean 4493 +33 = Tk.4460 4502 +42 4446 -14 4475 +15 4492 +32 4572 +112 4516 +56 4468 +8 4489 +29 © .S. B. Bhattacharjee = +340 Ch 4_19 Applying the formula we get: d 340 X A 4460 4460 34 Tk .4494 N 10 One may find that short-cut method takes more time as compared to direct method. However, this is true only for ungrouped data. In case of grouped data, considerable saving in time is possible by adopting the short-cut method. © .S. B. Bhattacharjee Ch 4_20 What are the methods of estimating average from grouped data? Direct method Short-cut method Continued….. © .S. B. Bhattacharjee Ch 4_21 Example 3 Compute the average from the following data by direct method. © .S. B. Bhattacharjee Profits (Tk. Lakhs) No. of Companies 200-400 500 400-600 300 600-800 280 800-1000 120 1,000-1,200 100 1.200-1,400 80 1.400-1,600 20 Ch 4_22 Direct Method The formula for estimating average from grouped data by direct method is: fx X N Where, X = mid-point of various classes f= the frequency of each class N= the total frequency Continued……. © .S. B. Bhattacharjee Ch 4_23 Calculate the average profits for all the companies. Profits (Tk. Lakhs) Mid-points X No. of Companies f fx 200-400 300 500 1,50,000 400-600 500 300 1,50,000 600-800 700 280 1,96,000 800-1000 900 120 1,08,000 1,000-1,200 1100 100 1,10,000 1.200-1,400 1300 80 1,04,000 1.400-1,600 1500 20 30,000 N=1,400 © .S. B. Bhattacharjee Continued……. fx 8,48,000 Ch 4_24 fx 8,48,000 X 605.71 N 1,400 Thus, the average profit is Tk. 605.71 lakhs. © .S. B. Bhattacharjee Ch 4_25 Short-cut Method When short-cut method is used, the following formula is applied. fd X A i N Where, A = Arbitrary point (assumed mean) XA d i and i = size of the equal class interval © .S. B. Bhattacharjee Ch 4_26 Example: Mid-points f X A d i fd 19.5-29.5 24.5 2 -3.50 -7.00 29.5-39.5 34.5 12 -2.50 -30.00 39.5-49.5 44.5 15 -1.50 -22.50 49.5-59.5 54.5 20 -0.50 -10.00 59.5-69.5 64.5 18 +0.50 9.00 69.5-79.5 74.5 10 +1.50 15.00 79.5-89.5 84.5 9 +2.50 22.50 89.5-99.5 94.5 4 +3.50 14.00 Marks N = 90 © .S. B. Bhattacharjee Continued……. fd 9.0 Ch 4_27 fd X A i N 9.0 59.5 10 90 9.0 59.5 10 90 59.5 1 58.5 Here, assumed mean, A = 59.5 class-interval, i =10 © .S. B. Bhattacharjee Ch 4_28 What are the mathematical properties of arithmetic mean? The important mathematical properties of arithmetic mean are: 1.The algebraic sum of the deviations of all the observations from arithmetic mean is always zero, i.e., X X 0 This shall be clear from the following example: X 10 20 30 40 50 X 150 © .S. B. Bhattacharjee X X -20 - 10 0 +10 +20 X X 0 Continued…… Ch 4_29 2. The sum of the squared deviations of all the observations from arithmetic mean is minimum, that is, less than the squared deviations of all the observations from any other value than the mean. The following example would clarify the point: X Here , X X N 20 5 4 X X X X 2 2 -2 4 3 -1 1 4 0 0 5 +1 1 6 +2 4 2 X X x 20 X X 0 © .S. B. Bhattacharjee Continued…… 10 Ch 4_30 3.If we have the arithmetic mean and number of observations of two or more than two related groups, we can compute combined average of these groups by applying the following formula: X 12 N1 X 1 N 2 X 2 N1 N 2 Continued…… © .S. B. Bhattacharjee Ch 4_31 Where, X 12 = Combined mean of the two groups. X1 = Arithmetic mean of the first group. X2 = Arithmetic mean of the second group. N1 = Number of observations in the first group. N2 = Number of observations in the second group. Continued……… © .S. B. Bhattacharjee Ch 4_32 Example: There are two branches of a company employing 100 and 80 employees respectively. If arithmetic means of the monthly salaries paid by two branches are Tk. 4570 and Tk. 6750 respectively, find the arithmethtic mean of the salaries of the employees of the company as a whole. Applying the following formula, we get: X 12 X 12 N1 X 1 N 2 X 2 N1 N 2 100 4570 80 6750 100 80 997000 180 Tk .5538.89 © .S. B. Bhattacharjee Ch 4_33 What are the merits of arithmetic mean? Merits: It possesses first six out of seven characteristics of a good average. The arithmetic mean is the most popular average in practice. It is a large number of characteristics. ??? Continued…… © .S. B. Bhattacharjee Ch 4_34 What are the limitations of arithmetic mean? Limitations: Arithmetic mean is unduly affected by the presence of extreme values. In opened frequency distribution, it is difficult to compute mean without making assumption regarding the size of the class-interval of the open-end classes. The arithmetic mean is usually neither the most commonly occurring value nor the middle value in a distribution. In extremely asymmetrical distribution, it is not a good measure of central tendency. © .S. B. Bhattacharjee Ch 4_35 What is meant by weighted arithmetic mean? A weighted average is an average estimated with due weight or importance given to all the observations. The terms ‘weight’ stands for the relative importance of the different observations. Problem: An important problem that arises while using weighed mean is selection of weights. Weights may be either actual or arbitrary, i.e., estimated. Uses: Weighted mean is specially useful in problems relating to the construction of index numbers and standardized birth and death rates. Continued…. © .S. B. Bhattacharjee Ch 4_36 The formula for computing weighted arithmetic mean is given below: WX Xw , W where, Xw =The weighted arithmetic mean X = The variable. W = Weights attached to the variable X. © .S. B. Bhattacharjee Ch 4_37 Example: A contractor employs three types of workers – male, female and children. To male worker he pays Tk. 100 per day, to a female worker Tk. 75 per day and to a child worker Tk. 35 per day. What is the average wage per day paid by the contractor? Solution: The simple average wage is not arithmetic mean, i.e., 100 75 35 Tk . 70 per day. If we assume that 30 the number of male, female and child workers is the same, this answer would be correct. For example, if we take 10 workers in each case then the average wage would be 10 100 10 75 10 35 X © .S. B. Bhattacharjee 10 10 10 1000 750 350 Tk .70 30 Ch 4_38 Continued…. Let us assume that the number of male, female and child workers employed are 20, 15 and 5, respectively. The average wage would be the weighted mean calculated as follows: Continued….. © .S. B. Bhattacharjee Ch 4_39 Example: Wage per day (Tk) X 100 75 35 No. of workers WX W 20 15 5 2000 1125 175 W= 40 WX = 3300 WX Xw W 3300 82.50 40 Hence the average wage per day paid by the contractor is Tk. 82.50. © .S. B. Bhattacharjee Ch 4_40 What is meant by geometric mean? The geometric mean (GM) is defined as Nth root of the product of N observations of a given data. If there are two observations, we take the square toot; if there are three observations, the cube root; and so on, The formula is: G.M N ( X 1)( X 2)( X 3)...( X N ) , where, X1, X2, X3….., XN refer to the various observations of the data. © .S. B. Bhattacharjee Ch 4_41 How is geometric mean computed? To simplify calculations logarithms are used. Log G.M . log X 1 log X 2 .... log X N N log X G.M . antilog N © .S. B. Bhattacharjee log X N Ch 4_42 How is geometric mean calculated? In ungrouped data, geometric mean is calculated with the help of the following formula: log X G.M . Antilog N In grouped data, first midpoints are found out and then the following formula is used for calculating geometric mean : f log X , Where G.M . Antilog N X = midpoint © .S. B. Bhattacharjee Ch 4_43 What are the applications of geometric mean? Geometric mean is specially useful in the following cases: The geometric mean is used to find the average per cent increase in sales, production, population or other economic or business data. For example, from 2002 to 2004 prices increased by 5%, 10% and 18% respectively. The average annual increase is 11% as given by the arithmetic average but it is 10.9% as obtained by the geometric mean. This average is also useful in measuring the growth of population, because population increases in geometric progression. © .S. B. Bhattacharjee Continued……. Ch 4_44 Geometric mean is theoretically considered to be the best average in the construction of index number. It makes index numbers satisfy the time reversal test and gives equal weights to equal ratio of change. It is an average which is most suitable when large weights have to be given to small values of observations and small weights to large values of observations, situations which we usually come across in social and economic fields. © .S. B. Bhattacharjee Ch 4_45 What are the merits of geometric mean? Merits Geometric mean is highly useful in averaging ratios and percentages and in determining rates of increase and decrease. It is also capable of algebraic manipulation. For example, if the geometric mean of two or more series and their numbers of observations are known, a combined geometric mean can easily be calculated. Continued……. © .S. B. Bhattacharjee Ch 4_46 What are the limitations of geometric mean? Limitations Compared to arithmetic mean, this average is more difficult to compute and interpret. Geometric mean cannot be computed when there are both negative and positive values in a series or more observations are having zero value. © .S. B. Bhattacharjee Ch 4_47 What is meant by harmonic mean? The harmonic mean is based on the reciprocal of the numbers averaged. It is defined as the reciprocal of the arithmetic mean of the reciprocal of the individual observation. Continued……. © .S. B. Bhattacharjee Ch 4_48 How is harmonic mean computed? The formula for estimating follows: H .M . harmonic mean is as N 1 1 1 1 .... X3 XN X1 X 2 Where number of observations is large, the computation of harmonic mean in the above manner becomes tedious. Continued……. © .S. B. Bhattacharjee Ch 4_49 To simplify calculations, we obtain reciprocals of the various observations and apply the following formulae: N For ungrouped data,= H .M 1 X N For grouped data, = N H .M . or 1 f f X X . Continued……. © .S. B. Bhattacharjee Ch 4_50 Calculation of Harmonic Mean 1 X X 10 20 25 40 50 H .M N 1 X © .S. B. Bhattacharjee 0.100 0.050 0. 04 0.025 0.020 1 0 235 X 5 21 28 0 235 Continued……. Ch 4_51 Calculation of Harmonic Mean Variable X f 1 f X 0-10 10-20 5 15 8 15 1.600 1.000 20-30 30-40 40-50 25 35 45 20 4 3 0.800 0.114 0.067 1 f X 3 581 H .M . © .S. B. Bhattacharjee N 1 f X 50 13 96 3 581 Ch 4_52 What are the applications of harmonic mean? The harmonic mean is restricted in its field of applications. It is useful for computing the average rate of increase of profits or average speed at which a journey has been performed or the average price at which an article has been sold. For example, if a man walked 20 km., in 5 hours, the rate of his walking speed can be expressed as follows: 20 km. 4 km. per hour , 5 hours Continued……. © .S. B. Bhattacharjee Ch 4_53 Where X, the unit of the first term is an hour and the unit of the second term is a kilometer. 5 hours 1 hour per km., 20 km. 4 Example: In a certain factory a unit of work is completed by A in 4 minutes, by B in 5 minutes, by C in 6 minutes, by D in 10 minutes and by E in 12 minutes. (a) What is the average number of units of work completed per minute? (b) At this rate how many units will they complete in a sixhour day? Continued……. © .S. B. Bhattacharjee Ch 4_54 The average number of units per minutes will be obtained by calculating the harmonic mean. 1 X X 4 5 6 0.250 0.200 0.167 10 12 0.100 0.083 H .M . © .S. B. Bhattacharjee 1 08 X N 1 X Continued……. 5 6 25 08 Ch 4_55 Example: A toy factory has assigned a group of 4 workers to complete an order of 1, 400 toys of certain type. The productive rates of the four workers are given below: Workers A B Productive rates 4 minutes per toy 6 minutes per toy C D 10 minutes per toy 15 minutes per toy Find the average minutes per toy by the group of workers. © .S. B. Bhattacharjee Continued……. Ch 4_56 If we assume that each of the four workers is assigned the same number of toys (constant value) to 1,400 meet the order, or = 350 toys per worker, the 4 arithmetic mean would give the correct answer. 4 6 10 15 X 4 35 4 3 8 minutes per toy. 4 Continued……. © .S. B. Bhattacharjee Ch 4_57 Verification Time required by A to complete 350 toys ×4 =1,400 minutes Time required by B to complete 350 toys ×6 =2,100 minutes Time required by C to complete 350 toys ×10 =3,500 minutes Time required by D to complete 350 toys ×15 =5,250 minutes 12,250 minutes. In 12,250 minutes, 1,400 toys will be completed. Hence, in completing one toy time taken will be 12,250 3 8 minutes 1,400 4 © .S. B. Bhattacharjee Continued……. Ch 4_58 However, if we assume that each worker works the same amount of time but produces different number of toys, harmonic mean would be more appropriate. This assumption is more true in practice (people working same amount of time but having different output) 4 60 6 H .M . 6 minutes per toy 1 1 1 1 35 7 4 6 10 15 4 Time required to complete 1,400 toys 1,400 48 9,600 minutes 7 Continued……. © .S. B. Bhattacharjee Ch 4_59 Verification: Each workers works for 9,600 2,400 minutes 4 2400 600 Toys produced by A in 2400 minutes 4 2400 400 Toys produced by B in 2400 minutes 6 Toys produced by C in 2400 minutes 2400 240 10 2400 Toys produced by D in 2400 minutes 160 15 Total = 1,400 © .S. B. Bhattacharjee Ch 4_60 What are merits of harmonic mean? Merits The harmonic mean, like the arithmetic mean and geometric mean, is computed from all observations. It is useful in special cases for averaging rates. © .S. B. Bhattacharjee Ch 4_61 What are the limitations of harmonic mean? Limitations Harmonic mean cannot be computed when there are both positive and negative observations or one or more observations have zero value. It also gives largest weight to observations and as such is not representation of a statistical series. smallest a good It is in dealing with business problems harmonic mean is rarely used. © .S. B. Bhattacharjee Ch 4_62 What is meant by median ? Median is a point in a distribution of scores above and below which exactly half of the cases fall. This is a value which appears in the middle of ordered sequence of values. This is also known as positional average. The term ‘position’ refers to the place of a value in a series. Example: If the income of five persons is Tk.7000, 7200,7500,7600,7800, then the median income would be Tk.7500. © .S. B. Bhattacharjee Ch 4_63 Apply the formula : Median = Size of N 1 th 2 observation. From the following data of wages of 7 workers, compute the median wage: Wages (in Tk.) 4600, 4650, 4580, 4690, 4660, 4606, 4640 © .S. B. Bhattacharjee Ch 4_64 Calculation of Median from ungrouped data S. No. Wages arranged in ascending order 1 2 3 4 4580 4600 4606 4640 5 6 7 4650 4660 4690 © .S. B. Bhattacharjee Ch 4_65 N 1 7 1 Median Size of th observation 4th observation 2 2 Value of 4th observation is 4640. Hence median wages = 4640. In the above illustration, the number of observations was odd and, therefore, it was possible to determine value of 4th observation. When the number of observations are 8 the median would be the value of 8 1 = 4.5th observation. 2 For finding out the value of 4.5th observation, we shall take the average of 4th and 5th observation. Hence the median shall be 4640 4650 4645 2 © .S. B. Bhattacharjee Ch 4_66 Formula for calculation of median from grouped data N p.c. f . Median L 2 i, f Where L = Lower level of median class i.e. the class in which the middle observation in the distribution lies p.c.f.= Preceding cumulative frequency to the median class. i = The class-interval of the median class Continued….. © .S. B. Bhattacharjee Ch 4_67 Calculation of Median Marks Marks 19.5-29.5 f 2 c. f 2 29.5-39.5 39.5-49.5 49.5-59.5 59.5-69.5 12 15 20 18 14 29 49 67 69.5-79.5 79.5-89.5 89.5-99.5 10 9 4 77 86 90 Continued….. © .S. B. Bhattacharjee Ch 4_68 Median = Size of N 2 N the 2 the observation observation = 45th observation Hence median lies in the class 49.5-59.5 Continued….. © .S. B. Bhattacharjee Ch 4_69 N p.c. f Here, L = 49.5, N = 2 Median L i 90, p.c.f = 29 , f =20 f i = 10. 45 29 49.5 10 20 N 90 16 45 49.5 10 20 2 2 49.5 8 57.5 © .S. B. Bhattacharjee Ch 4_70 What are merits of median? Merits The median is superior to arithmetic mean in certain respects. It is especially useful in case of open–end distribution and also it is not influenced by the presence of extreme values. In fact when extreme values are present in the data, the median is a more satisfactory measure of central tendency than the mean. © .S. B. Bhattacharjee Continued…… Ch 4_71 Merits The sum of the deviations of observations from median (ignoring signs) is minimum. In other words, the absolute deviation of observations from the median is less than from any other value in the distribution © .S. B. Bhattacharjee Continued…… Ch 4_72 What are the limitations of median? Limitations The median is not capable of algebraic treatment. Median cannot be used for determining the estimation purposes since it is more affected by sampling fluctuations. The median tends to be rather unstable value if the number of observations is small. © .S. B. Bhattacharjee Ch 4_73 What are positional measures ? Positional measures are those that are estimated by dividing a series into a equal number of parts. Important amongst these are quartiles, deciles and percentiles. Quartiles are those values of the variate which divide the total frequency into four equal parts, deciles divide the total frequency in 10 equal parts and the percentiles divide the total frequency in 100 equal parts. Continued…… © .S. B. Bhattacharjee Ch 4_74 How are quartiles, deciles and percentiles computed? The procedure for computing quartiles, deciles, etc., is the same as for median. For grouped data, the following formulae are used for quartiles, deciles and percentiles: jN p.c. f . Qj L 4 i f for j = 1,2,3 KN p.c. f . Dk L 10 i f © .S. B. Bhattacharjee Continued……. for K = 1,2,…,9 Ch 4_75 IN p.c. f . P1 L 100 i f for I = 1,2,…,99 where the symbols have their usual meanings and interpretation. © .S. B. Bhattacharjee Continued……. Ch 4_76 The profits earned by 100 companies during 2003-04 are given below: Profits (Tk. lakhs) 20-30 No. of companies 4 30-40 40-50 50-60 60-70 8 18 30 15 70-80 80-90 90-100 10 8 7 Calculate Q1 , Median, d4 and P80 and interpret the values. © .S. B. Bhattacharjee Continued……. Ch 4_77 Calculation of Q1 , Q2, d4 and P80 Profits (Tk. lakhs) f c.f. 20-30 30-40 40-50 50-60 4 8 18 30 4 12 30 60 60-70 70-80 80-90 15 10 8 75 85 93 90-100 7 100 © .S. B. Bhattacharjee Continued……. Ch 4_78 100 Q1 Size of N / 4th observation 25th observation. 4 Hence Q1 lies in the class 40 50. N p.c. f . Q1 L 4 i f 25 12 40 10 40 7.22 47.22 18 25 per cent of the companies earn an annual profit of Tk. 47.22 lakhs or less. © .S. B. Bhattacharjee Continued……. Ch 4_79 2N Median or Q2 Size of th observation 50th observation. 4 Q2 lies in the class 50 60 2N p.cf . Q2 L 4 i f 50 30 50 10 50 6 67 30 56 67 50 per cent of the companies earn an annual profit of Tk. 56.67. © .S. B. Bhattacharjee Continued……. Ch 4_80 4N D4 Size of th observation 40 th observation 10 D4 lies in the clas 50 60 4N p.c. f . D4 L 10 i f 40 30 50 10 30 50 3.33 53.33. Thus 40 per cent of the companies earn an annual profits of Tk. 53.33 lakhs or less. © .S. B. Bhattacharjee Continued……. Ch 4_81 80 N 80 100 P80 Size of the observation 80th observation 100 100 P80 lies in the class 70 80. 80 N p.c. f . P80 L 100 i f 80 75 70 10 70 5 75 10 This means that 80 per cent of the companies earn an annual profit of Tk. 75 lakhs or less and 20 per cent of the companies earn an annual profit of more than Tk. 75 lakhs. © .S. B. Bhattacharjee Ch 4_82 What is meant by Mode? Mode refers to the most common value in a distribution or the largest category of variable. It may also defined as the value which occurs the maximum number of times, i.e. having the maximum frequency. © .S. B. Bhattacharjee Ch 4_83 How is mode calculated? It involves fitting mathematically some appropriate type of frequency curve to the grouped data and the determination of the value on the X-axis below the peak of the curve. However, there are several elementary methods of estimating the mode. Method for ungrouped Method for grouped data. © .S. B. Bhattacharjee Ch 4_84 Calculation of mode- ungrouped data The following figures relate to the preferences with regard to size of screen (in inches) of T.V. sets of 30 persons selected at random from a locality. Find the modal size of the T.V. screen. 12 20 12 24 29 20 12 20 29 24 24 20 12 20 24 29 24 24 20 24 24 20 24 24 12 24 20 29 24 24 © .S. B. Bhattacharjee Continued…… Ch 4_85 Calculation of modal Size Size in inches Tally Frequency 12 5 20 24 8 13 29 4 Total 30 Since size 24 occurs the maximum number of times, the modal size of T.V. screen is 24 inches © .S. B. Bhattacharjee Ch 4_86 Calculation of mode – grouped data In the case of grouped data, the following formula is used for calculating mode: Where 1 Mo L i 1 2 L = Lower limit of the modal class. 1 2 The difference between the frequency of the modal class and the frequency of the premodal class, i.e., preceding class. The difference between the frequency of the modal class and the post-modal class, i.e., succeeding class. i = The size of the modal class. © .S. B. Bhattacharjee Ch 4_87 Another form of this formula is: f1 f o Mo L i 2 f1 f o f 2 where, L = Lower limit of the modal class f1 = Frequency of the modal class fo = Frequency of the class preceding the modal class. f2 = Frequency of the class succeeding the modal class. © .S. B. Bhattacharjee Ch 4_88 A distribution containing more than one mode is called bimodal or multimodal. This cannot be determined by the said formula. When mode is ill-defined, its value (value of mode) may be ascertained by the following approximate formula based upon the relationship between mean, median and mode. 1 Mean median Mean Mode) 3 © .S. B. Bhattacharjee Ch 4_89 In the given Sum, mentioned in slide no ch 4-68 L 49.5 1 20 15 5 2 20 18 2 i 10 We know, 1 Mo L i 1 2 5 10 52 5 49 5 10 7 50 49 5 7 49 5 7 14 56 64 49 5 © .S. B. Bhattacharjee Ch 4_90 How would you locate mode graphically? In a frequency distribution the value of mode can be determined graphically. The steps in calculation are : Draw a histogram of the given data. Draw two lines diagonally on the inside of the modal class bar, starting from each upper corner of the bar to the upper corner of the adjacent bar. Draw a perpendicular line from the intersection of the two diagonal lines to the X-axis (horizontal scale) which gives modal value. © .S. B. Bhattacharjee Ch 4_91 The daily profits in Tk. of 100 shops are given us follows: Profits No. of shops 0-100 12 100-200 18 200-300 27 300-400 20 400-500 17 500-600 6 Draw the histogram and thence find the modal value. Check this value by direct calculation. © .S. B. Bhattacharjee Ch 4_92 Mode lies in the class 200-300 1 Mo L i 1 2 9 200 100 97 Here, L 200 1 27 18 9 2 27 20 7 i 100 900 200 16 200 56 25 256 25 © .S. B. Bhattacharjee Ch 4_93 Locating Mode graphically 30 27 No. of shops 25 18 20 15 0-100 20 100-200 17 200-300 12 10 300-400 6 5 400-500 500-600 0 Mode=Tk.258 profits (in Tk. Lakhs) © .S. B. Bhattacharjee Ch 4_94 From the diagram, the modal value is also 256. Hence by both the method the same value of mode is obtained. Mode can also be determined from frequency polygon in which case perpendicular is drawn on the base from the apex of the polygon and the point where it meets the base gives the modal value. However, graphic method of determining mode can be used only where there is one class containing the highest frequency. If two or more classes have the same highest frequency, mode cannot be determined graphically. © .S. B. Bhattacharjee Ch 4_95 What are the merits of mode? Merits Like median, the mode is not affected by extreme values and its value can be obtained in open-end distributions without ascertaining the class limits. Mode can be easily used to describe qualitative phenomenon. For example, when we want to compare the consumer preferences for different types of products, say, soap, toothpastes, are etc., of different media of advertising, we should compare the modal preferences. In such distributions where there is an outstanding large frequency, mode happens to be meaningful as an average. © .S. B. Bhattacharjee Ch 4_96 What are the limitations of mode? Limitations Mode is not a rigidly defined measure as there are several formulae for calculating the mode, all of which usually give somewhat different answers. The value of mode cannot always be computed, such as ,in case of bimodal distributions. © .S. B. Bhattacharjee Ch 4_97 What is the relationship among mean, median and mode? A distribution in which the values of mean, median and mode coincide is known as symmetrical distribution. Conversely stated, when the values of mean, median and mode are not equal, the distribution is known as asymmetrical or skewed. In moderately skewed or asymmetrical distributions, a very important relationship exists among mean, median and mode. In such distributions, the distance between the mean and the median is approximately one-third of the distance between the mean and mode as will be clear from the following diagram: © .S. B. Bhattacharjee Ch 4_98 Relationship among mean, median and mode DIVIDES AREA IN HALVES UNDER PEAK OF CURVE CENTRE OF GRAVITY X Mo Me © .S. B. Bhattacharjee Ch 4_99 Karl Pearson has expressed relationship as follows: this approximate 1 Mean Median Mean Mode 3 Or Mode = 3 median – 2 Mean and 2 Mean Mode Median 3 If we know any of the two values out of the three, we can compute the third from these relationships. Continued…… © .S. B. Bhattacharjee Ch 4_100 Example: In a moderately asymmetrical distribution the Mode and Mean are 32.1 and 35.4 respectively. Calculate the Median. Solution: Mode = 3 Median – 2Mean Here, Mode = 32.1, Mean =35.4 Substitution the values, 32.1 =3 Median – 2×35.4 Or 32.1= 3 Median – 70.8 Or, 3 Median =32.1+70.8 Or 3 Median = 102.9 Median = 34.3 © .S. B. Bhattacharjee Ch 4_101 What are the important features influencing selection of progressive average? This average is based upon the arithmetic mean. The important features of this average are: It is a cumulative average. In the calculation of this average all previous figures are added and no previous figure is left as is done in the case of moving average. The progressive average of the first year would remain the same; the progressive average for the second year ab is equal to ; for the third year a b c , for the 2 3 fourth year a b c d ; and so on. 4 Continued……. © .S. B. Bhattacharjee Ch 4_102 What are the important features influencing selection of progressive average? The average value can be obtained for all the years. The moving average, on the other hand, cannot be computed for all the years. The longer the period of moving average, the greater the number of years for which the moving average cannot be computed. This average is generally used during the early years of the working of a business. For example, the figures of sales, profits or production of each successive year may be compared with the respective figures for the entire previous period in other to find out how a business is growing. © .S. B. Bhattacharjee Ch 4_103 What are the important features influencing selection of progressive average? © .S. B. Bhattacharjee Ch 4_104 What are the situations unfavorable to using arithmetic mean? In the following cases, arithmetic mean should not be used: In highly-skewed distributions In distributions with open-end intervals When the distributions is unevenly spread, concentration being small or large at irregular points. When an average rate of growth or change over a period of time is required. Continued……. © .S. B. Bhattacharjee Ch 4_105 What are the situations unfavorable to using arithmetic mean? When the observations form progression, i.e., 1, 2, 4, 8, 16, etc. a geometric When averaging of rates (i.e., speed, fluctuations in the prices of articles, etc.) is needed. When there are very large and very small values of observations arithmetic mean would be seriously misleading on account of undue influence of extreme values. © .S. B. Bhattacharjee Ch 4_106 What are the critical points one has to keep in mind while using an average? Since an average is a single value representing a group of values, it must be properly interpreted, otherwise, there is every possibility of jumping to wrong conclusion. An average may give us a value that does not exist in the data. For example, The arithmetic mean of 100, 300, 250, 50, 100 Continued…….. © .S. B. Bhattacharjee Ch 4_107 What are the critical points one has to keep in mind while using an average? At times an average may give absurd results. For example, if we calculate average size of a family we may get a value 4.8. But this is impossible as persons cannot be in fractions. Measures of central value fail to give us any idea about the formation of the series. Two or more series may have the same central value but may differ widely in composition. © .S. B. Bhattacharjee Continued….. Ch 4_108 Concluding Remarks We must remember that an average is a measure of central tendency. Hence unless the data show a clear-cut concentration of observations an average may not be meaningful at all. This evidently precludes the use of any average to typify a bimodal or a U-shaped or a J-shaped distribution. © .S. B. Bhattacharjee Ch 4_109 © .S. B. Bhattacharjee Ch 4_110