Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
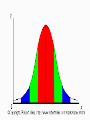
A normal distribution of data means that most of the observations in a set of data are close to the "average," while relatively few observations tend to one extreme or the other. Let's say you are interested in nutrition You need to look at people's typical daily kilojoule consumption. Like most data, the numbers for people's typical consumption probably will turn out to be normally distributed. That is, for most people, their consumption will be close to the mean, while fewer people eat a lot more or a lot less than the mean. When you think about it, that's just common sense. Not that many people are getting by on a single serving of kelp and rice. Or on eight meals of steak and milkshakes. Most people lie somewhere in between. Measurements made of the following quantities are considered to exhibit the characteristics of a normal distribution: heights of adults cholesterol levels metabolic rates crop yields per area lengths of sardines oxygen consumption radiation exposures per area IQ’s head circumference blood pressures exam scores There are many more, but if a particular quantity does follow this distribution, many useful statements may be made regarding the proportions of the population that lie in appropriate intervals. Hypothetical data with a bell-shaped frequency polygon would look like this: If the frequency polygon with a normal distribution is made into a smooth curve, the result is a normal curve: The x-axis (the horizontal one) is the value in question... kilojoules consumed, dollars earned or crimes committed, for example. And the y-axis (the vertical one) is the number (or frequency) of data points for each value on the x-axis. In other words, the number of people who eat x kilojoules, the number of households that earn x dollars, or the number of cities with x crimes committed. Not all sets of data will have graphs that look this perfect. Some will have relatively flat curves, others will be pretty steep. Sometimes the mean will lean a little bit to one side or the other. But all normally distributed data will have something like this same "bell curve" shape. The standard deviation is the statistic that tells you how tightly all the various observations are clustered around the mean in a set of data. When the observations are pretty tightly bunched together and the bell-shaped curve is steep, the standard deviation is small. When the examples are spread apart and the bell curve is relatively flat, that tells you that you have a relatively large standard deviation. One standard deviation away from the mean in either direction on the horizontal axis (the red area on the above graph) accounts for around 68 percent of the observations in this group. Two standard deviations away from the mean (the red and green areas) account for roughly 95 percent of the observations. And three standard deviations (the red, green and blue areas) account for about 99 percent of the observations. If this curve were flatter and more spread out, the standard deviation would have to be larger in order to account for those 68 percent or so of the people. So that's why the standard deviation can tell you how spread out the examples in a set are from the mean. Why is this useful? Looking at the standard deviation can help point you in the right direction when asking why information is the way it is. http://www.youtube.com/watch?v=Wqw9cLRMPL0&feature=related The normal distribution The ends of the normal curve extend toward infinity—they approach the horizontal axis (x axis) but never quite touch it. This property represents the possibility that, although the normal curve contains virtually all values of a variable, a very small number of values may exist that reflect extremely large or extremely small measurements (or values) of the variable (outliers). The horizontal axis of a normal curve can be divided into 6 equal units 3 units between the mean and the place where the curve approaches the axis on the left side, and 3 units between the mean and the place where it approaches the axis on the right side. These six units collectively reflect the amount of variation that exists within virtually all values of a normally distributed variable. In a normal distribution of any variable, virtually all values (except for 0.26%) fall within these six units of variation. Each unit corresponds to exactly one standard deviation. Look up a Z value of 1 on Page 442 of the textbook Area under the Standard Normal Curve … How does this table work? The normal distribution showing standard deviations Normal distributions derived from different data sets tend to have different means and different standard deviations. The figures below demonstrate how this occurs by comparing three pairs of normal curves. The figure also demonstrates the fact that normal curves can be drawn in a way that they reflect the distribution of data. That is, curves may be high and narrow, low and wide, or anything in between. Curves can be drawn to suggest the degree of variation present in the distribution of a variable—that is, the size of its standard deviation. Flatter curves suggest relatively large standard deviations and higher ones reflect relatively small standard deviations; however, they still retain what is essentially a “bell shape.” As the distribution is symmetrical, 50 percent of the total area of the frequency polygon in a normal distribution falls below the mean and 50 percent falls above it. Other segments of the frequency polygon similarly reflect standard percentages of its total area. The next chart displays the percentage of the normal curve that falls between the mean and the point (or variable) referred to as standard deviation and between standard deviations. Almost all the area of the frequency polygon (99.74%) lies between the points -3SD and +3SD Understanding that the percentage of the area under a normal curve is also the percentage of values that fall within a certain area of a normally distributed variable is critical to our understanding. To summarise the characteristics of the standard normal curve: It is bell shaped and symmetrical. Its’ mean, median, and mode all fall at the same point. It is asymptotic which means the tails come close to but do not touch the x axis. Nearly all its area (99.74%) falls within three standard deviations of the mean. The centre and variation will depend on the values of mu and sigma The total area under the curve is 1 such that: the area within 1SD of mean = 68.26% the area within 2 SD of mean = 95.44% the area within 3SD of mean = 99.74% Example using area under the curve The time taken to repair defective components produced on an assembly line was monitored by the manager each day over six months. It was found that the daily repair time followed an approximate normal distribution with a mean of 10 hours and a standard deviation of 2 hours. Sketch the normal curve, and shade in the region that represents the proportion of days on which the repair time for defective components was: Between 8 and 12 hours more than 11 hours Less than 9 hours Between 11 and 14 hours In this example, one curve is used to represent a single distribution, and various proportions of the observations are indicated by shading under the curve. We could calculate these areas and obtain values for the proportions. After detailed calculations, we could construct a table to show values for all the different areas under this curve. However, in practice, we often need values for areas under many normal curves (with different means and different standard deviations), so this particular table would have very limited use. It is impractical to create a table for every normal curve and z-scores overcome this problem by converting all our measurements into standard score or z-score form. To convert a raw score of x to a standard or z-score Standard score = z = observed value – mean Standard deviation = To convert a z-score to a raw score If we were to repeatedly take samples from a population and graph all the means we'd have a normal distribution of sample means with the standard deviation of these means called the standard error. This is such an important concept in statistics, almost everything else you learn after this depends on the fundamental concept. It's called the central limit theorem. The central limit theorem in it's shortest form states that the sampling distribution of the sampling means approaches a normal distribution as the sample size gets larger, regardless of the shape of the population distribution So the sample means will be normally distributed (especially when the sample is above 30) even if the population is positively skewed, negatively skewed or even binomial (having only 2 outcomes). Here are two key points from the central limit theorem: The average of our sample means will itself be the population mean. The standard deviation of the sample means equals the standard error of the population mean. The important message the central limit theorem provides is the sampling distribution of the means is normally distributed even if the population is not http://www.khanacademy.org/math/statistics/v/centrallimit-theorem Even though the individuals in a population may have considerable variable among themselves, there is much less variation among the averages of samples of many individuals. What that allows us to do is solve problems about means, even when the data is not normally distributed. Therefore the standard deviation of the distribution of means is calculated by: Regardless of the distribution of the parent population: The mean of the population of means is always equal to the mean of the parent population from which the samples were drawn. The standard deviation of the population of means is always equal to the standard deviation of the parent population divided by the square root of the sample size (N). The distribution of means will increasingly approximate a normal distribution as the size N of samples increases. A consequence of Central Limit Theorem is that if we average measurements of a particular quantity, the distribution of our average tends toward a normal one. The Central Limit Theorem explains why we frequently we see the famous bell-shaped "Normal distribution" (or "Gaussian distribution") in the measurements domain. The notation ‘Pr’ or ‘P’ followed by ‘( z-score takes on particular values )’ will mean: The proportion of time that a z-score takes on those particular values. For example, Pr(z-score is less than 0.57) = the proportion of z-scores that are less than 0.57. Stat Mode 1,0, 0, xy, 0.1, ENT, 1, xy, 0.3, ENT…… RCL, 4 – mean is 1.7 100,000, ENT, 125000, ENT …. RCL, 6 x RCL 6 = 251,440 RCL 6 = 15856.86 Not to be confused with the Correlation Coefficient The Coefficient of Variation is just showing what percentage of the mean is the Standard Deviation The larger the Standard Deviation is the larger the percentage is and the greater is the dispersion of data from the mean - for example if the STD Dev was 30,000 we would have a coefficient of variation of 30,000 / 101,600 x 100 = 29.53% 4 (a) Mean = 33.6 Standard deviation = 11.66 (i) Probability profit > $46,000 = 46 – 33.6 11.66 = 1.06 Z = 0.5 – 0.3554 = 14.46% (ii) Range = 33.6 + or – 1.96 (11.66) $10,746 to $56,454 What is Hypothesis Testing? A statistical hypothesis is an assumption about a population parameter, often the mean. This assumption may or may not be true. In hypothesis testing we analyse differences between the results we observe and the results we would expect to obtain if the hypothesis were true. Hypothesis testing refers to the formal procedures used by statisticians to accept or reject statistical hypotheses. State the null and alternate hypotheses to be tested Determine the level of significance Select the test statistic Determine the critical value Calculate the value of the test statistic Draw a conclusion Statistical Hypotheses The best way to determine whether a statistical hypothesis is true would be to examine the entire population. Since that is often impractical, researchers typically examine a random sample from the population. If sample data are not consistent with the statistical hypothesis, the hypothesis is rejected. Are smoking and lung cancer related? Are males better than females at maths? Does fluoridation of the water supply help reduce tooth decay? Does a particular drug assist in curing a disease? Has random breath testing reduced the road toll? Is performance at high school related to performance at TAFE? Is profit related to the amount spent on advertising? Two types of statistical hypotheses Null hypothesis the null hypothesis, denoted by H0, is usually the hypothesis that nothing unusual has occurred. Alternative hypothesis the alternative hypothesis, denoted by H1 or Ha, is the hypothesis that something unusual has occurred. The hypotheses can be written together in the form H0: (statement) v. H1: (alternate statement) The alternative hypothesis may be classified as two-tailed or one-tailed. In the case of the two-tailed test (two-sided alternative) we do the test with no pre-conceived notion that the true vale of µ is either above or below the hypothesised value of µ0. The test is said to be two-sided because (or twotailed) and the alternate hypothesis is written as H1: µ≠ µ0 A paint manufacturer claims that its new plastic all – weather outdoor brand dries in an average of 20 minutes when used on timber houses. To test this claim, a scientist uses the paint on 30 different pieces of timber that might be used in the construction of houses. What is the null and alternate hypotheses for this test and what type of test is it? In this case, there is no pre-conceived notion by the scientist about whether the claimed 20 minutes might be too long or too short. Therefore, a two sided alternative is appropriate. The hypotheses may be written H0: µ=20 v. H1:µ≠ 20 For the one-tailed test (one-sided alternative), we do the test with a strong conviction that if H0 is not true, it is clear that µ is either greater than µ0 or less than µ0 If we feel the only possible alternative is that µ is greater than µ0 we write H0: µ > µ0 However, if we feel the only possible alternative is that µ is less than µ0 we write H0: µ < µ0 The weights of full term female babies born to mothers at a community hospital have been recorded over the years and found to have a mean of 3200 g. A particular group of 50 mothers were identified as being heavy smokers throughout their pregnancy. Some medical researchers felt that heavy smoking would usually result in babies having lower birth weights than other babies. What test would you use to test this and what is the alternate hypothesis? In this case, there is a pre-conceived notion that, if these babies do have an unusual birth weight, it will only be in the direction of lower. That is, it is felt there is no chance that they will have a higher birth weight. When setting up the alternate hypothesis, it may well be appropriate to use a one-sided alternative. The hypothesis may be written H0: µ = 3200 v. H1: µ < 3200 A point of interest can we accept the Null Hypothesis? Some researchers say that a hypothesis test can have one of two outcomes: you accept the null hypothesis or you reject the null hypothesis. Many statisticians, however, take issue with the notion of "accepting the null hypothesis.“ Instead, they say: you reject the null hypothesis or you fail to reject the null hypothesis. Why the distinction between "acceptance" and "failure to reject?" Acceptance implies that the null hypothesis is true. Failure to reject implies that the data are not sufficiently persuasive for us to prefer the alternative hypothesis over the null hypothesis. After the appropriate hypothesis have been formulated, the next step is to determine the significance level (or -level) of the test. This level represents the borderline probability between whether an event (or sample) has occurred by chance (ie.within acceptable boundaries of variation) or an unusual event has taken place The significance level used in testing a given hypothesis, represents the maximum probability with which the tester would be willing to risk a Type I error. That is the risk the tester is prepared to take of rejecting the null hypothesis when it is actually true. Any significance level may be used The most common significance level used is 0.05 Called the 5% significance level with notation = 0.05 Another widely used level is = 0.01or 1% significance level If we use a 5% significance level, what we are saying is that an event (or sample) that occurs less than 5% of the time is considered unusual. In this case, we reject H0 if the probability of obtaining a sample like ours is less than 0.05. That is, we conclude H0 may well be false. We cannot reject H0 if this probability is more than 0.05. That is, we conclude H0 is true. If we use a 1% significance level, what we are saying is that an event (or sample) that occurs less than 1% of the time is considered unusual. In this case, we reject H0 if the probability of obtaining a sample like ours is less than 0.01. That is, we conclude H0 may well be false. We cannot reject H0 if this probability is more than 0.01. That is, we conclude H0 is true. Decision Errors - two types of errors can result from a hypothesis test Type I errors occur when the researcher rejects a null hypothesis (concludes it is false) when, in fact it is true. The probability of committing a Type I error is equal to , the significance level of the test. Type II errors occur when the researcher fails to reject a null hypothesis (concludes it is true) when it is really false. The probability of committing a Type II error is called Beta, and is often denoted by β. The probability of not committing a Type II error (1 – β) is called the Power of the test. Of course, we would like to avoid both errors as much as possible. Unfortunately, in trying to avoid one of them, we increase the chances of making the other. A company has developed a drug it feels may cure certain types of cancer. It has collected vast amounts of data as a result of clinical trials and has asked you to examine the data and determine whether the drug actually works. Outline the null and alternate hypotheses, the consequences of type I and type II errors and the relationship between these errors in this scenario. The null and alternate hypotheses in words H0 : the drug does not work v. H1 the drug does work Making a type I error: concluding the drug works when it really doesn’t Patients are given false hope Patients are taken off possibly more useful medication The company will invest additional funds in the drug only to find down the track the medication is not effective The company may be subject to litigation Making a type II error: concluding the drug doesn’t work when it really does The world and cancer patients are deprived of a cure Many patients die who may have been cured The company will have lost potential profits The company may subject the statistician to litigation In reality Decision H0 is true H0 is false Reject H0 Type I error No error made Not reject H0 No error made Type II error RCL, 6 – Std Dev of the Population, RCL 5 – Std Dev of a Sample a Z score is used for normal distributions or when the sample is greater or equal to 30 otherwise we use a t test State the null and alternate hypotheses to be tested Determine the level of significance Select the test statistic Determine the critical value Calculate the value of the test statistic Draw a conclusion Check this using Z tables in Textbook The Standard Deviation is adjusted by the size of our Sample -50 /√30 .5 - .025 = .475 What if we had taken a sample of 100 cakes and found the mean to still be 505 grams then (505-500) / (15/10) = 3.33 - is greater than 1.96 - we could not be 95% certain that a cake sampled at random would be close to the expected mean of 500 grams - that is the more cakes we sample the closer we would expect the average of the sample to be to the expected mean of the entire production run Check out the Excel Spread sheet – Exploring Self Test 5 Page 128 further Equal or not equal to – we have to test if it is outside the range - too small or too great therefore it is a two sided test. Less than or greater than - it is a one sided test. Note a Z score is used for normal distributions, when the sample is greater or equal to 30, otherwise we use a t test Question 18. x bar = mean of Sample u = mean of population s = sample std dev n = sample size (a) (80-85) / (4/(√40)) - make sure you use memory do √40 first - store in memory STO then 4 / RCL = store in memory STO then 5 / RCL = 7.9057 (a) (128-120) / 12 / (√(25-1)) = 3.27 (b) (340-330) / 23 / (√50) = 3.074 Normal populations or samples >30 - use Z and divided by √N Otherwise use t test - it becomes √n-1 Normal populations or samples >30 - use Z and divided by √N Otherwise use t test - it becomes √n-1 Question 20. (41.3-42)/(.5/(sqr root 40 )) = 14 Question 22. Critical Value 5% - .5 - .05 = .045 – Value of Z is 1.645 Value of Z test = 360 – 354 / (14 / (√30)) = 2.35 Reject the hypothesis since 2.35 > 1.645 – because it is further from the mean – outside the acceptable range Question 23