Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Clinical neurochemistry wikipedia , lookup
Human multitasking wikipedia , lookup
Recurrent neural network wikipedia , lookup
Premovement neuronal activity wikipedia , lookup
Donald O. Hebb wikipedia , lookup
Neural coding wikipedia , lookup
Activity-dependent plasticity wikipedia , lookup
Cognitive flexibility wikipedia , lookup
Optogenetics wikipedia , lookup
Cognitive neuroscience of music wikipedia , lookup
Types of artificial neural networks wikipedia , lookup
Neuroplasticity wikipedia , lookup
Concept learning wikipedia , lookup
Executive functions wikipedia , lookup
Holonomic brain theory wikipedia , lookup
Feature detection (nervous system) wikipedia , lookup
Impact of health on intelligence wikipedia , lookup
Learning theory (education) wikipedia , lookup
Neurophilosophy wikipedia , lookup
Synaptic gating wikipedia , lookup
Neural correlates of consciousness wikipedia , lookup
Neuropsychopharmacology wikipedia , lookup
Eyeblink conditioning wikipedia , lookup
Cognitive neuroscience wikipedia , lookup
Cognitive science wikipedia , lookup
Metastability in the brain wikipedia , lookup
Environmental enrichment wikipedia , lookup
Aging brain wikipedia , lookup
Nervous system network models wikipedia , lookup
Embodied cognitive science wikipedia , lookup
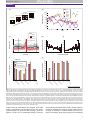
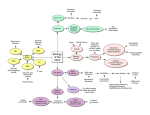
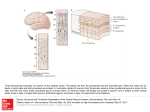
TICS-943; No. of Pages 9 Opinion Posterior cingulate cortex: adapting behavior to a changing world John M. Pearson1,2, Sarah R. Heilbronner1,2, David L. Barack2,3, Benjamin Y. Hayden1,2 and Michael L. Platt1,2,4 1 Department of Neurobiology, Duke University Medical Center, Box 3209, Durham, NC 27710, USA Center for Cognitive Neuroscience, Duke University, B203 Levine Science Research Center, Box 90999, Durham, NC 27708, USA 3 Department of Philosophy, Duke University, Box 90743, Durham, NC 27708, USA 4 Department of Evolutionary Anthropology, Duke University, 104 Biological Sciences Building, Box 90383, Durham, NC 27708-0680, USA 2 When has the world changed enough to warrant a new approach? The answer depends on current needs, behavioral flexibility and prior knowledge about the environment. Formal approaches solve the problem by integrating the recent history of rewards, errors, uncertainty and context via Bayesian inference to detect changes in the world and alter behavioral policy. Neuronal activity in posterior cingulate cortex – a key node in the default network – is known to vary with learning, memory, reward and task engagement. We propose that these modulations reflect the underlying process of change detection and motivate subsequent shifts in behavior. Learning in a changing world Most days, you drive home along a familiar route but today something unexpected happens: the city has opened a new street that offers the possibility of a shortcut. Another day, a new intersection sends you down an unexpected road. Often a traffic jam alters the time it takes you to reach your destination. Whether you are a human driving home, a monkey foraging for food, or a rat navigating a maze, unexpected changes in the world necessitate a shift in behavioral policy (see Glossary): rules that guide decisions based on prior knowledge and potentially promote learning. Changes force agents to engage learning systems, switch mental states and shift attention, among other adjustments, and recent work has examined their physiological substrates [1,2]. Yet the loci of change detection within the brain remain unidentified. Here we propose that the posterior cingulate cortex (CGp) plays a key role in altering behavior in response to unexpected change. It could be that this region, which consumes more energy than other cortical areas [3], must do so to keep pace with a dynamically changing world. Learning, change detection and policy switching Since the discovery that dopaminergic neurons respond to rewarding events by signaling the difference between expected and received rewards, the so-called ‘reward prediction error’ (RPE), theories of reinforcement learning (RL) have dominated discussions of learning and condiCorresponding author: Platt, M.L. ([email protected]). tioning [4,5]. In typical RL algorithms, learning is incremental and only slowly converges on stable behavior [5]. In an environment that rapidly alternates among several fixed but distinct reward contingencies, crude RL agents might find themselves forever playing catch-up and unable to do more than gradually adjust in response to abrupt transitions. At present, we know little about the neural processes that underly rapid change detection: those that switch between and those that initiate the learning of behavioral policies. Such processes should accommodate changes in the contingency structure of the environment (state space and Markov structure) and in its distribution of returns (volatility, outcomes and outliers). In the driving example above, the new or diverted streets correspond to changes in environmental structure and the traffic jam corresponds to a change in the distribution of returns. Standard RL fails to capture the ability of animals to implement a wide array of strategies, each learned independently, with minimal switching costs. For example, drivers stuck in unexpected traffic do not gradually modify Glossary Bayes’ rule: a rule of statistical inference used for updating uncertainty about statistical parameters (u) based on prior information (p(u)) and new observai juÞ pðuÞ tions (xi): pðujx i Þ ¼ pðxpðx . iÞ Bayesian learning: a set of learning models in which agents maintain knowledge as probability distributions updated by Bayes’ rule. Classical or Pavlovian conditioning: the process by which environmental stimuli become associated, via learning, with the prediction of outcomes. Cognitive set or set: the combination of world model, policy and attentional factors that govern performance in a task. Markov property: the mathematical assumption that transitions between states depend only on the current state, not a decision agent’s entire history: p(si|si1, si2, . . .)= p(si|si1), where si is a state and p(si) is the probability of transitioning to that state. Markov structure: the set of transition probabilities p(sijsj) that defines the relation between states in a space with the Markov property. Policy: a mapping (potentially probabilistic) between environmental variables such as states and values, and actions. Policies implicitly depend on world models because not all world models share the same sets of variables. Reinforcement learning (RL): a computational learning model in which organisms adapt to an environment by incrementally altering behavior in response to rewards and punishments. State space: the collection of distinct possible conditions for an agent– environment system in formal models of learning. States can be distinguished by, among other factors: the number and type of available choices, the information available to the agent, and the response properties of the environment. World model or model: a set of states of the world, their transition relations, and the distributions of outcomes from those states. 1364-6613/$ – see front matter ß 2011 Elsevier Ltd. All rights reserved. doi:10.1016/j.tics.2011.02.002 Trends in Cognitive Sciences xx (2011) 1–9 1 TICS-943; No. of Pages 9 Opinion Trends in Cognitive Sciences xxx xxxx, Vol. xxx, No. x Box 1. Bayesian learning Recent studies have provided evidence that both humans and nonhuman animals often employ sophisticated, model-based assumptions when learning about their environments [7,11,15]. That is, agents first determine an appropriate set of constructs by which to model the world, and then update the parameters of these models via Bayesian inference. The Bayesian approach to learning proves particularly useful when modeling behavior in environments where the underlying parameters are subject to change. The underlying link between stimuli and outcomes can either change gradually in time [7,10] or shift suddenly [11–13,77]. Such models are able to incorporate both prediction error and surprise because they include full predictive distributions for observed quantities thereby uniting aspects of both RL and attentional learning [6]. Although we remain agnostic regarding specific implementations of Bayesian learning, several key features are common to all models [7]. First, updates to the means of model parameters are proportional to the prediction error: the difference between observed and expected outcomes. Second, these updates are scaled by the learning rate, which depends on uncertainty: the width of the distribution of Slow change parameter estimates (Figure I). This uncertainty itself depends on the current estimate of environmental rate of change, allowing agents to learn more slowly in stable worlds and incorporate new information more readily in frequently changing contexts. Finally, agents are expected to incorporate prior information through Bayes’ rule, forcing them to fall back on model-based assumptions in the presence of limited information or recent change. However, full Bayesian approaches require intensive nonlinear computation, highlighting the need for simple, online update rules that approximate the full solution. Although models such as probabilistic population codes solve the Bayesian inference problem via neurons tuned to specific outcome variables [78], in regions without such well-characterized tuning curves, memory and processing constraints argue for trial-to-trial inference. In many cases, techniques such as the Kalman filter offer optimal solutions [8], whereas in others maximum likelihood estimates serve as useful approximations [11,77]. We believe that the brain uses a multitude of such approaches that can be matched to environmental dynamics to produce ‘good enough’ Bayesian behavior. Rapid change αδ Update Probability Probability Low uncertainty Higher uncertainty Prior Change rate estimate Model parameter estimate TRENDS in Cognitive Sciences Figure I. Bayesian update rules for learning Model parameters are initially estimated as prior distributions (black). When outcomes are observed, distribution means are shifted by the product of learning rate, a, and prediction error, d, while variances change based on the estimated rate of environmental change (left). When the estimated rate of environmental change is low (red), both mean updates and uncertainty (proportional to variance) are likewise small. When change is rapid (blue), means are updated rapidly but uncertainty remains high. the typical route home but reselect from among multiple alternatives based on expected delays, time of day and so on. Although several classical theories of conditioning [6] posit surprise (formalized as the absolute value of RPE) or similar violations of expectation to dynamically adjust behavior and learning rate, such models are still based on the idea of a single policy subject to gradual updates. By contrast, a change detection framework allows for multiple behavioral policies by using statistical inference to distinguish expected variation from underlying environmental shifts [7–11], allowing only the behaviorally relevant policy to be deployed and learned. As a result, agents capable of change detection, rather than forever reshaping a single policy in the face of a dynamic environment, can instead adapt rapidly by switching between behavioral policies. This idea accords well with the rapid adjustment of behavior to sudden changes in reward contingencies [12,13], and operates similarly to theories of conditioning that invoke Bayesian mechanisms to dynamically adjust learning rates [7,14] (Box 1). In such scenarios, outcome tracking not only adjusts the current strategy (and learning rate) but also determines whether or not environmen2 tal change warrants a switch to a different strategy entirely. Reinforcement learning then operates as a subprocess within the change detection system utilizing Bayesian inference along with a suite of inborn or learned models of the world [7,11,15]. Past hypotheses regarding CGp function Despite extensive interconnections with memory, attentional and decision areas (Box 2), the primary function of the CGp remains mysterious. Indeed, no commonly recognized unified theory for its role exists (Table 1). Clinical evidence demonstrates that early hypometabolism and neural degeneration in CGp predict cognitive decline in Alzheimer’s disease [16,17], and CGp hyperactivity predicts cognitive dysfunction in schizophrenia [18]. Although a host of experiments have identified the anterior cingulate cortex (ACC) as crucial for processing feedback from individual choices and subsequent alterations in behavior [9,19–27], the functional role of CGp remains relatively obscure. To date, disparate evidence for CGp involvement in cognitive and behavioral processes has thwarted simple TICS-943; No. of Pages 9 Opinion Trends in Cognitive Sciences xxx xxxx, Vol. xxx, No. x Box 2. Posterior cingulate cortex anatomy and physiology Table 1. Proposed functions of CGp with selected references Cingulate cortex as a whole has long been recognized as an important site integrating sensory, motor, visceral, motivational, emotional and mnemonic information [76]. CGp is the portion of cingulate cortex caudal to the central sulcus. Although poorly understood, this brain structure nevertheless consumes large amounts of energy, making it one of the most metabolically expensive regions of the brain [3]. CGp is reciprocally connected with areas involved in attention – areas 7a, lateral intraparietal area (LIP), and 7, or PGm/precuneus – as well as with brain areas involved in learning and motivation, including the anterior and lateral thalamic nuclei, the caudate nucleus, OFC and ACC (Figure I). CGp also forms strong, reciprocal connections with the medial temporal lobe, especially the parahippocampal gyrus, long known to be crucial for associative learning and episodic memory (for a thorough review of neuroanatomical connections, see [76]). Functional claims Evaluating sensory events and behavior to guide movement and memory Spatial learning and navigation Late stages of RL Orientation in time and space Autobiographical memory retrieval Emotional stimulus processing Reward outcome monitoring Representation of subjective value Problem solving via insight Mind wandering Action evaluation and behavioral modification Goal-directed cognition AMYG PHG Medial Thalamus OFC RSC CGp ACC LI P FE F PF C Lateral Caudate NAC VTA SNc TRENDS in Cognitive Sciences Figure I. Figure shows medial (top) and lateral (bottom) views of the macaque brain Significant neuroanatomical connections to and from CGp are shown. Note that the figure does not represent a thorough diagramming of innervations because CGp connects to a large number of brain regions. Generally, CGp neuroanatomy is similar in humans and macaques [76]. Abbreviations: VTA, ventral tegmental area; SNc, substantia nigra pars compacta; NAC, nucleus accumbens; PFC, prefrontal cortex; FEF, frontal eye field; RSC, retrosplenial cortex; PHG, parahippocampal gyrus; AMYG, amygdala. functional characterization. Anatomical connections to medial temporal lobe areas necessary for learning and memory, as well as to neocortical areas responsible for movement planning, indicate that CGp links these areas to store spatial and temporal information about the consequences of action [28,29]. The involvement of CGp in learning and memory, however, seems to extend far beyond the scope of movements and spatial orientation. Neuroimaging experiments have shown that CGp is activated by emotional stimuli, particularly when they have personal significance [30,31]. Neurons in CGp signal reward size, and some studies have proposed that they encode the subjective value of a chosen option [32–34]. The bulk of recent CGp studies, however, have focused on its role in the so-called ‘default mode network’: a set of interconnected brain regions showing elevated BOLD signal at rest and suppression during active task engagement [3]. Refs [28] [29,79] [80] [81] [30] [31] [40] [32–34] [64] [68] [41] [35] Yet none of these proposed functional roles – mnemonic, attentional, spatial and default – successfully captures the full range of phenomena shown to modulate activity in CGp. Taking a broader view based on both electrophysiological and functional imaging evidence (summarized below), we conjecture that many of these observed modulations reflect the contribution of CGp to signaling environmental change and, when necessary, relevant shifts in behavioral policy. In our scheme, suppressed CGp activity favors operation within the current cognitive set, whereas increased activity reflects a change in either environmental structure or internal state and promotes flexibility, exploration and renewed learning. This proposed role for CGp is consistent with converging evidence from imaging studies that default network regions play an active role in cognition when tasks require mental simulation and strategic planning [35–37], and lesion studies demonstrating deficits in multitasking and set-shifting [38,39]. Although this hypothesis pertains primarily to the contributions of CGp to learning and decision making, we also provide evidence to suggest that such an approach offers clues to the broader role of the default network in cognition. Change detection and policy control in CGp CGp neurons not only respond in graded fashion to the magnitude of liquid reward associated with orienting but also respond to the unpredicted omission of these same rewards [40]. In a choice task with one ‘safe’ option delivering a fixed liquid reward and one ‘risky’ option randomly delivering larger and smaller rewards with equal probability [34,41], CGp neurons encoded not only reward size but also reward variance [34]. Thus CGp neurons track policy-relevant variables such as reward value as well as estimates of variability within the current environment. In this probabilistically rewarded choice task, monkeys’ behavior followed a win-stay lose-shift heuristic [41]. After choosing the risky option, monkeys were more likely to choose it again if they received a larger reward but more likely to switch to the safe option if they received the smaller reward. Firing rates of CGp neurons were correspondingly higher following smaller rewards than large rewards, and variability in responses predicted the likelihood the monkey would switch its choice on the next trial. Brief microstimulation in CGp increased the likelihood monkeys would switch to the safe option after receiv3 TICS-943; No. of Pages 9 Opinion Trends in Cognitive Sciences xxx xxxx, Vol. xxx, No. x 6 10 5 Key: large reward safe small reward cell B040317 n=293 trials 0 -500 0 500 n=58 cells 4 2 1 0 −0.5 0 1000 Large Time (ms) Safe 5 Small 4 Outcome of gamble Fixation (d) 2.0 Firing rate difference small minus large (Hz) Firing rate (Hz) 15 Firing rate (Hz) (c) (b) (a) Pre-movement (e) 10 3 2 1 Trial in the past Post-movement (f) 10 10 8 8 Key: 6 Firing rate (Hz) 8 Firing rate (Hz) Firing rate (Hz) Into RF Out of RF 6 4 6 4 0.0 0.2 0.4 CV of reward 0.6 0.8 4 0.0 0.2 0.4 CV of reward 0.6 0.8 0.0 0.2 0.4 0.6 0.8 CV of reward TRENDS in Cognitive Sciences Figure 1. CGp encodes reward outcomes over multiple trials and predicts changes in strategy (a) Peri-stimulus time histogram (PSTH) for an example neuron following reward delivery when monkeys choose between variably rewarded outcomes and deterministically rewarded outcomes with the same mean reward rate. Firing rates were significantly greater following small or medium rewards than following large rewards. (b) Bar graph showing the average firing of all neurons in the population following delivery of large, medium and small rewards. Firing rates are averaged over a 1 s epoch beginning at the time of reward offset (t=0). Tick marks indicate one standard error. (c) Average effect of reward outcome on neuronal activity up to five trials in the future. Bars indicate one standard error. (d–f) Average neuronal firing rates as a function of coefficient of variation (CV) in reward size plotted for three trial epochs in the probabilistic reward task. Firing increased for saccades into the neuronal response field (RF), and was positively correlated with reward CV (standard deviation/mean). Bars represent SEM. Adapted from [41] and [34]. ing a large reward – as if they had erroneously detected a bad outcome [41]. Tonic firing rates in CGp maintained information about previous rewards for several trials and these modulations predicted future choices (Figure 1) [34,41]. Taken together, these findings indicate that CGp neurons encode environmental outcomes (rewards and variance), maintain this information online (in a leaky fashion), and contribute to adjusting subsequent behavior. A follow-up study probed whether representation of the need to switch applied beyond simple option switching to policy changes more generally [42]. Monkeys performed a variant of the k-armed bandit task in which reward amounts for four targets varied independently on each trial and slowly changed over time (Figure 2a,b) [8]. Behavior was characterized as following two distinct policies – explore and exploit – that depended on the recent history of rewards experienced for choosing each target [8]. Firing rates of CGp neurons not only signaled single-trial reward outcomes but also predicted the probability of shifting between policies in graded fashion (Figure 2c–e). These 4 observations endorse the idea that CGp participates in a circuit that monitors environmental outcomes for purposes of change detection and subsequent policy switching [42]. Thus, even in a more complex environment where changes in returns are gradual rather than sudden, the activity of CGp neurons both tracks and maintains strategically relevant information used to implement a change in behavioral policy. A model of change detection and policy switching in cingulate cortex In order for agents to learn and switch between distinct strategies in response to environmental change, they must detect the change through inference over behavioral outcomes and adjust parameters within a given strategy. Figure 3 depicts a schematic of one such change detection and learning process. In the model, outcome data from single events are passed to the change detection system, which recombines these variables into strategy-specific measures of Bayesian TICS-943; No. of Pages 9 Opinion Trends in Cognitive Sciences xxx xxxx, Vol. xxx, No. x (a) (b) Key: Target 1 1s inter-trial interval 200 Reward (ms juice) Saccade, reward delivery Targets appear 0.5s fixation e Tim Target 2 Target 3 180 Target 4 Chosen 160 140 120 100 80 10 20 30 40 50 60 Trial Key: Exploit (c) (d) Explore (e) 10 8 Decision epoch P(explore) next trial Firing rate (Hz) 9 Post-reward epoch 7 6 5 4 3 0.5 0.6 0.4 0.5 0.3 0.4 0.2 0.3 0.1 0.2 0 2 -1000 0 1000 2000 3000 4000 0 0.2 0.4 0.6 0.8 (f) 0 0.2 0.4 0.6 0.8 1 (g) 16 N=83 neurons 0.1 Key: 0.09 Mean absolute correlation 18 Number significant 1 % maximal firing rate Time (ms) Decision epoch Post-reward epoch 14 12 10 8 6 4 0.08 0.07 0.06 0.05 0.04 0.03 0.02 2 0.01 0 0 ng ni nc te ra ria va it e lo e n en e os ch xp e nc t ra /E ng ria e nc n ar Le ea ria e or PE R M Va pl Ex ni va os it lo xp ch E e/ e nc n ar Le ea ria or PE R M Va pl Ex TRENDS in Cognitive Sciences Figure 2. CGp neurons encode variance/learning rate and change probability in a volatile environment (a) Schematic of the four-armed bandit task. Four targets appear each trial, each baited with an independently varying juice reward. (b) Sample payouts and choices for the four options over a single block. Reward values for each target independently follow a random walk process. Black diamonds indicate the monkey’s choices during the given block. (c) PSTH for an example neuron in the four-armed bandit task showing significant differences in firing for exploratory and exploitative strategies in both the decision and evaluation epochs. Exploit trials are in red, explore trials in black. The task begins at time 0. Onset of the ‘go’ cue (dashed green line), reward delivery (unbroken red line), beginning of inter-trial interval (dashed gray line), and end of trial (rightmost dashed black line) are mean times. Dashed red lines indicate one standard deviation in reward onset. Shaded areas represent SEM of firing rates. (d,e) Neurons in CGp encode probability of exploring on the next trial. Points are probabilities of exploring next trial as a function of percent maximal firing rate in the decision epoch, averaged separately over negatively- and positively-tuned populations of neurons (d and e, respectively). (f) Numbers of neurons encoding relevant variables in a Kalman filter learning model of behavior [8,42]. Bars indicate numbers of significant partial correlation coefficients for each variable with mean firing rate in each epoch when controlling for others. The decision epoch (blue) lasted from trial onset to target selection; the post-reward epoch (red) lasted from the end of reward delivery to the end of the inter-trial interval. Dashed line indicates a statistically significant population of neurons, assuming a P=0.05 false positive rate. Variance chosen indicates the estimated variance in the value of the chosen option. Mean variance indicates the mean of this quantity across all options. (g) Mean absolute partial correlation coefficients for significant cells. Colors are as in (f). Adapted from [42]. evidence that the environment has changed. As in other models of information accumulation [43,44], this signal, representing the log posterior odds favoring a given hypothesis (in this case, environmental change), increases until reaching a threshold after which a ‘change’ signal is broadcast, learning rates increase and the agent switches strategy. In contrast to standard models of sensory evidence accumulation, these decision signals are maintained 5 TICS-943; No. of Pages 9 Opinion Trends in Cognitive Sciences xxx xxxx, Vol. xxx, No. x Sensory data Environment Task-specifc outcome variables ACC Learning module OFC/BG log(change evidence) CGp/default Threshold / policy selector DLPFC Update rule Long-term memory HPC Current policy Alternate policies TRENDS in Cognitive Sciences Figure 3. A simplified schematic of change detection and policy selection Sensory feedback from reward outcomes is divided into task-specific variables and passed on to both a RL module and a change detector. The learning module computes an update rule based on the difference between expectations and outcomes in the current world model, and updates the policy accordingly. The change detector calculates an integrated log probability that the environment has undergone a change to a new state. If this variable exceeds a threshold, then the policy selection mechanism substitutes a new behavioral policy that will be updated according to subsequent reward outcomes. across multiple outcomes, and possess only a single threshold as is appropriate for an all-or-none switching process that allows full Bayesian inference to be reduced to a simple update model [11]. Equally important, the decision variables accumulated by the change detector can vary between strategies depending on the expected distribution of outcomes from the environment. That is, the correct statistical test for agents to perform in change detection depends not only on the environment but also on current and alternative strategies. Thus in an environment where the appropriate strategy depends heavily on the relative frequency of outliers, the correct tracking statistic can be neither the mean nor the variance of outcomes but a simple proportion of occurrence above a threshold. In such a framework, the best statistic is the one that maximizes the area under the receiver operating characteristic curve for the strategy switching problem, balancing false positives against false negatives in accord with the cost-benefit analysis that obtains in the current environment. Physiologically, we tentatively identify areas such as ACC, amygdala, and basal ganglia as encoding individual event-related outcomes necessary for altering behavior within a given strategy. These variables function as inputs to both the gradual within-strategy (RL) learning system and the change detection system, the latter of which could include key default network areas such as CGp and the ventromedial prefrontal cortex (vmPFC). These identifications are indicated by the demonstrated sufficiency of midbrain dopaminergic signals for classical conditioning [45], as well as the role played by cortical targets of these signals in associative learning. For instance, the orbito6 frontal cortex (OFC) and ACC, which maintain strong reciprocal connections with the basal ganglia [46,47], are necessary for representing links between outcomes, actions and predictive cues [26,48–51], as well as facilitating changes in action [19,24]. Furthermore, we hypothesize that individual policies and policy selection are most likely to be computed in dorsolateral prefrontal cortex, already implicated in strategic decisionmaking and action planning [52,53], while long-term associative learning is implemented via the hippocampus and surrounding structures. Clearly, however, much work remains to validate both the model and the identification of its individual functions with specific anatomical areas. Evidence for such a process is depicted in Figure 2f,g. There, we present a suggestive reanalysis of behavioral and neural data from the above-mentioned bandit task [42] using an expanded Kalman filter model (see supplementary material online). This Kalman filter improved our behavioral fits in all cases, and firing in CGp neurons significantly tracked variability in the chosen targets (equivalent to uncertainty; n=8/83, 9/83), RPE (n=15/83, 17/83) and learning rate (n=10/83, 10/83). These correlations (variability: R=0.10 chosen option, RPE: R=0.10, learning rate: R=0.10; mean absolute value of partial correlation for significant cells) proved both stronger and, in some cases, more numerous than those signaling the difference between explore and exploit policies [42]. Indeed, such results are surprising because the task itself contained no underlying noise to learn (apart from the random walk). Additionally, cells that coded RPE maintained this information for the duration of the trial TICS-943; No. of Pages 9 Opinion indicating that single-trial outcome variables encoded in ACC [54,55] are buffered for purposes of uncertainty estimation and within-policy adjustment. These data not only reaffirm that CGp encodes variability in options [34,40,41] but also situate these signals within a broader online learning framework. And although we note that such results (both effect size and frequency) are strongly model dependent, they bolster the hypothesis that CGp encodes and maintains online variables related to the statistical structure of dynamic environments. Nevertheless, direct tests are needed in tasks where abrupt contingency changes occur and in which change detection is necessary for optimal behavior. Change detection: an active role for the default mode network? Functionally, CGp in humans belongs to the ‘default network’ of cortical areas that includes vmPFC and temporoparietal junction. These areas show high metabolic and hemodynamic activity at rest that is suppressed during task engagement [56]. Activation in the default network is typically anticorrelated with activation in the dorsal frontoparietal network: a set of brain areas implicated in selective attention and its concomitant benefits in accuracy and task performance [57–59]. Monkeys show strikingly similar patterns of spontaneous BOLD activity [60] and single unit activity [61,62] within this network. What has often gone missing in the discussion, however, is an active role for the default network in cognition. One suggestion for this role is retrieval of information – especially personally relevant information – from longterm memory [63], a function that CGp, with its strong connections to parahippocampal areas, is well situated to perform. Another is that the default network could be associated with divergent thinking patterns that lead to insight and creative problem solving – a process that can interfere with performance on many simple standard laboratory tasks [64]. This possibility is closely linked with the idea that default network activity is more associated with an ‘exploratory’ mode of cognition, and that default suppression is associated with an ‘exploitative’ mode [8,42]. This accords well with a view in which changing between world models and task sets requires withdrawal from task performance and a redeployment of internally directed cognition for purposes of strategy retrieval and selection. The centrality of CGp within the default network invites the possibility that change detection could be a key subfunction of default mode processing. Indeed, large-scale environmental changes are likely to signal the need for exploratory behavior. We recently reported that baseline activity of CGp neurons is suppressed during task performance, and that spontaneous firing rates predict subsequent task engagement on a trial-by-trial basis [62]. Specifically, higher firing rates predicted poorer performance on simple orienting and memory tasks [62], whereas cued rest periods, in which monkeys were temporarily liberated from exteroceptive vigilance, evoked the highest firing rates. Importantly, local field potentials in the gamma band, which has been closely linked to synaptic activity (and by extension, the fMRI BOLD signal), were also Trends in Cognitive Sciences xxx xxxx, Vol. xxx, No. x suppressed by task engagement. These results fit BOLD signal measurements showing lower CGp activity during task engagement [56,65–67]. Firing rates of CGp neurons were likewise suppressed when monkeys were explicitly cued to switch tasks but activity gradually increased on subsequent trials indicating relaxation of cognitive control [61]. The fact that CGp neurons track task engagement supports the view that the characteristic functions of the default network, including monitoring, are suppressed when operating within a stable, well-learned environment. By contrast, periods of rest can be accompanied by more generalized exploratory behavior requiring reduced focus and maximum flexibility. Even brief pauses in task performance liberate agents, monkey or human, from the need for focused task engagement thus permitting self-directed cognition, cognitive housekeeping and mind wandering [62,68]. Thus CGp and the default network could play a broader role in basic cognitive processes typically suppressed during performance of well-learned tasks, including memory retrieval, internal monitoring, and the global balance of internal versus external information processing. As a result, we predict CGp would respond most strongly during the initial phases of learning, in response to sudden environmental changes, and during self-initiated switches between behavioral policies. Conversely, we predict greatest deactivations during performance of outwardly directed effortful tasks that demand attention and engagement, and a return to baseline during breaks between trials [62], and even on repetitions of trials of the same type that presumably demand less attention [61]. These responses are quite distinct from those seen in other cortical areas, especially the frontoparietal attention network. The prevalence of increased default network activity outside task conditions in most studies would seem, on its surface, to militate against our model, as does the observation that firing in CGp neurons decreases following changes in the task at hand [61]. In fact, these responses further bolster the common view that default activation is simply the complement of activity in the frontoparietal attention network [59]. However, more recent studies have shown that in tasks requiring goal-directed introspection, default network activity shows strong positive correlation with activity in frontoparietal networks [35–37] indicating that repetitive performance in well-learned tasks could under-represent the role of default areas in active cognition. CGp lesions in both humans [38] and rodents [39] result in deficits in tasks requiring implementation of new strategies in multitasking scenarios and changes of cognitive set. Indeed, in richer environments where altering strategy requires periodically withdrawing from the current cognitive set to evaluate and decide we expect to see higher co-activation of default and attentional networks. In the same way, we hypothesize that the deactivation observed in animals switching between two well-learned tasks [61] results from the fact that changes in task demands were explicitly cued by the environment: no evaluation of evidence or internal query was required. In a task in which behavioral change requires first 7 TICS-943; No. of Pages 9 Opinion Trends in Cognitive Sciences xxx xxxx, Vol. xxx, No. x inferring the presence of a switch we predict increased activity in CGp. learning, memory, control, and reward systems to promote adaptive behavior. Extending the model We have proposed that CGp is a key node in the network responsible for environmental change detection and subsequent alterations in behavioral policy. This proposed network sits atop the RL module in the cognitive hierarchy enabling organisms to learn and implement a variety of behavioral responses to diverse environmental demands, and to refine each independently and employ them adaptively in response to change. This model makes several key predictions. First, CGp activity should show pronounced enhancement in scenarios that demand endogenously driven, as opposed to exogenously cued, changes in behavior. That is, when statistical inference becomes necessary to detect environmental change and alter behavior, CGp should show a concomitant rise in firing rate as evidence mounts, followed by a gradual fall-off as behavior crystallizes into a single policy. Naturally, this behavior requires that information be maintained and integrated across trials, and thus that firing rates in the present exhibit correlations with outcomes in the past. Likewise, set shifts resulting from inferred change points should elicit stronger modulations in CGp activity than cued change points because the latter require no integration of evidence. Consistent with this prediction, in a task-switching paradigm with random and explicitly cued switches [61], suppression of CGp firing reflected both task engagement and task switching presumably because change detection could not rely on statistical inference. Second, the process of learning entirely new associations should enhance CGp activity. This follows not only from anatomical connections between CGp and parahippocampal gyrus, which is necessary for long-term memory formation [69,70], but also from conditioning experiments showing enhanced CGp activity during learning [71]. We predict that CGp activity will be more strongly modulated by new cues that predict environmental changes that require a cognitive set switch than by new cues that are irrelevant to set shifts. Finally, the change detection hypothesis opens up new avenues for probing default network function. If the modulations in BOLD activity in fMRI studies merely represent, as we predict, one end on a continuum of resource allocation, then the idea of changes in cognitive set could offer a new perspective on default mode activation. In this framework, default network areas could be crucial for initiating transitions between basic modes of behavior, or even overriding them. This could be particularly relevant in schizophrenia, in which patients exhibit hypervigilance to behaviorally salient events in the environment but simultaneously show a diminished ability to ‘turn down’ the internal milieu [72,73]. Likewise, early degeneration in CGp in Alzheimer’s disease could cripple a key node in the interface between cognitive set and memory networks resulting in disorientation and impaired memory access [74,75]. Together, these observations indicate a healthy CGp is necessary for organizing flexible behavior in response to an ever-changing environment by mediating Acknowledgments 8 The authors were supported by NIH grants EY103496 (MLP), EY019303 (JP), F31DA028133 (SRH), and by a career development award (DA027718) and a NIDA post-doctoral fellowship (DA023338) (BYH), as well as by the Duke Institute for Brain Sciences. Appendix A. Supplementary data Supplementary data associated with this article can be found, in the online version, at doi:10.1016/j.tics.2011. 02.002. References 1 Dosenbach, N. et al. (2008) A dual-networks architecture of top-down control. Trends Cogn. Sci. 12, 99–105 2 Nakahara, K. et al. (2002) Functional MRI of macaque monkeys performing a cognitive set-shifting task. Science 295, 1532–1536 3 Gusnard, D.A. and Raichle, M.E. (2001) Searching for a baseline: Functional imaging and the resting human brain. Nat. Rev. Neurosci. 2, 685–694 4 Schultz, W. (2007) Behavioral dopamine signals. Trends Neurosci. 30, 203–210 5 Sutton, R.S. and Barto, A.G. (1998) Reinforcement Learning: An Introduction, MIT Press 6 Pearce, J. and Bouton, M. (2001) Theories of associative learning in animals. Annu. Rev. Psychol. 52, 111–139 7 Courville, A.C. et al. (2006) Bayesian theories of conditioning in a changing world. Trends Cogn. Sci. 10, 294–300 8 Daw, N.D. et al. (2006) Cortical substrates for exploratory decisions in humans. Nature 441, 876–879 9 Behrens, T.E. et al. (2007) Learning the value of information in an uncertain world. Nat. Neurosci. 10, 1214–1221 10 Yu, A.J. and Dayan, P. (2005) Uncertainty, neuromodulation, and attention. Neuron 46, 681–692 11 Nassar, M. et al. (2010) An approximately Bayesian delta-rule model explains the dynamics of belief updating in a changing environment. J. Neurosci. 30, 12366–12378 12 Gallistel, C. et al. (2001) The rat approximates an ideal detector of changes in rates of reward: Implications for the law of effect. J. Exp. Psychol. Anim. Behav. Process. 27, 354–372 13 Daw, N. and Courville, A. (2007) The rat as particle filter. Adv. Neural. Inf. Process. 20, 369–376 14 Hampton, A.N. et al. (2008) Neural correlates of mentalizing-related computations during strategic interactions in humans. Proc. Natl. Acad. Sci. U.S.A. 105, 6741–6746 15 Green, C.S. et al. (2010) Alterations in choice behavior by manipulations of world model. Proc. Natl. Acad. Sci. U.S.A. 107, 16401–16406 16 Minoshima, S. et al. (1997) Metabolic reduction in the posterior cingulate cortex in very early Alzheimer’s disease. Ann. Neurol. 42, 85–94 17 Yoshiura, T. et al. (2002) Diffusion tensor in posterior cingulate gyrus: correlation with cognitive decline in Alzheimer’s disease. Neuroreport 13, 2299–2302 18 Whitfield-Gabrieli, S. et al. (2009) Hyperactivity and hyperconnectivity of the default network in schizophrenia and in first-degree relatives of persons with schizophrenia. Proc. Natl. Acad. Sci. U.S.A. 106, 1279– 1284 19 Walton, M.E. et al. (2007) Adaptive decision making and value in the anterior cingulate cortex. Neuroimage 36 (Suppl 2), T142–154 20 Rudebeck, P.H. et al. (2008) Frontal cortex subregions play distinct roles in choices between actions and stimuli. J. Neurosci. 28, 13775– 13785 21 Quilodran, R. et al. (2008) Behavioral shifts and action valuation in the anterior cingulate cortex. Neuron 57, 314–325 22 Kennerley, S.W. et al. (2008) Neurons in the frontal lobe encode the value of multiple decision variables. J. Cogn. Neurosci. 21, 1162–1178 23 Holroyd, C.B. and Coles, M.G. (2008) Dorsal anterior cingulate cortex integrates reinforcement history to guide voluntary behavior. Cortex 44, 548–559 TICS-943; No. of Pages 9 Opinion 24 Hayden, B.Y. et al. (2009) Fictive reward signals in the anterior cingulate cortex. Science 324, 948–950 25 Seo, H. and Lee, D. (2009) Behavioral and neural changes after gains and losses of conditioned reinforcers. J. Neurosci. 29, 3627–3641 26 Hayden, B.Y. and Platt, M.L. (2010) Neurons in anterior cingulate cortex multiplex information about reward and action. J. Neurosci. 30, 3339–3346 27 Kennerley, S.W. and Wallis, J.D. (2009) Evaluating choices by single neurons in the frontal lobe: outcome value encoded across multiple decision variables. Eur. J. Neurosci. 29, 2061–2073 28 Vogt, B.A. et al. (1992) Functional heterogeneity in cingulate cortex: the anterior executive and posterior evaluative regions. Cereb. Cortex 2, 435–443 29 Sutherland, R.J. et al. (1988) Contributions of cingulate cortex to two forms of spatial learning and memory. J. Neurosci. 8, 1863–1872 30 Maddock, R.J. et al. (2001) Remembering familiar people: the posterior cingulate cortex and autobiographical memory retrieval. Neuroscience 104, 667–676 31 Maddock, R.J. et al. (2003) Posterior cingulate cortex activation by emotional words: fMRI evidence from a valence decision task. Hum. Brain Mapp. 18, 30–41 32 Levy, I. et al. (2010) Neural representation of subjective value under risk and ambiguity. J. Neurophysiol. 103, 1036 33 Kable, J.W. and Glimcher, P.W. (2007) The neural correlates of subjective value during intertemporal choice. Nat. Neurosci. 10, 1625–1633 34 McCoy, A.N. and Platt, M.L. (2005) Risk-sensitive neurons in macaque posterior cingulate cortex. Nat. Neurosci. 8, 1220–1227 35 Spreng, R.N. et al. (2010) Default network activity, coupled with the frontoparietal control network, supports goal-directed cognition. Neuroimage 53, 303–317 36 Gerlach, K.D. et al. (2011) Solving future problems: default network and executive activity associated with goal-directed mental simulations. NeuroImage, doi:10.1016/j.neuroimage.2011.01.030 37 Leech et al. (2011) Fractionating the Default Mode Network: Distinct Contributions of the Ventral and Dorsal Posterior Cingulate Cortex to Cognitive Control. J Neurosci 31, 3217–3224 38 Burgess, P. et al. (2000) The cognitive and neuroanatomical correlates of multitasking. Neuropsychologia 38, 848–863 39 Ng, C-W. et al. (2007) Double dissociation of attentional resources: prefrontal versus cingulate cortices. J. Neurosci. 27, 12123–12131 40 McCoy, A.N. et al. (2003) Saccade reward signals in posterior cingulate cortex. Neuron 40, 1031–1040 41 Hayden, B.Y. et al. (2008) Posterior cingulate cortex mediates outcomecontingent allocation of behavior. Neuron 60, 19–25 42 Pearson, J.M. et al. (2009) Neurons in posterior cingulate cortex signal exploratory decisions in a dynamic multioption choice task. Curr. Biol. 19, 1532–1537 43 Gold, J.I. and Shadlen, M.N. (2002) Banburismus and the brain: decoding the relationship between sensory stimuli, decisions, and reward. Neuron 36, 299–308 44 Gold, J.I. and Shadlen, M.N. (2007) The neural basis of decision making. Annu. Rev. Neurosci. 30, 535–574 45 Tsai, H. et al. (2009) Phasic firing in dopaminergic neurons is sufficient for behavioral conditioning. Science 324, 1080–1084 46 Haber, S. (2003) The primate basal ganglia: parallel and integrative networks. J. Chem. Neuroanat. 26, 317–330 47 Haber, S. et al. (2000) Striatonigrostriatal pathways in primates form an ascending spiral from the shell to the dorsolateral striatum. J. Neurosci. 20, 2369–2382 48 Lee, D. et al. (2007) Functional specialization of the primate frontal cortex during decision making. J. Neurosci. 27, 8170–8173 49 Schoenbaum, G. and Esber, G. (2010) How do you (estimate you will) like them apples? Integration as a defining trait of orbitofrontal function. Curr. Opin. Neurobiol. 20, 205–211 50 Schoenbaum, G. et al. (2009) A new perspective on the role of the orbitofrontal cortex in adaptive behaviour. Nat. Rev. Neurosci. 10, 885– 892 51 Matsumoto, M. et al. (2007) Medial prefrontal cell activity signaling prediction errors of action values. Nat. Neurosci. 10, 647–656 52 Barraclough, D.J. et al. (2004) Prefrontal cortex and decision making in a mixed-strategy game. Nat. Neurosci. 7, 404–410 Trends in Cognitive Sciences xxx xxxx, Vol. xxx, No. x 53 Lee, D. and Seo, H. (2007) Mechanisms of reinforcement learning and decision making in the primate dorsolateral prefrontal cortex. Ann. N.Y. Acad. Sci. 1104, 108–122 54 Seo, H. and Lee, D. (2007) Temporal filtering of reward signals in the dorsal anterior cingulate cortex during a mixed-strategy game. J. Neurosci. 27, 8366–8377 55 Rushworth, M.F. and Behrens, T.E. (2008) Choice, uncertainty and value in prefrontal and cingulate cortex. Nat. Neurosci. 11, 389–397 56 Buckner, R.L. et al. (2008) The brain’s default network: anatomy, function, and relevance to disease. Ann. N.Y. Acad. Sci. 1124, 1–38 57 Corbetta, M. et al. (2002) Neural systems for visual orienting and their relationships to spatial working memory. J. Cogn. Neurosci. 14, 508–523 58 Hopfinger, J.B. et al. (2000) The neural mechanisms of top-down attentional control. Nat. Neurosci. 3, 284–291 59 Fox, M.D. et al. (2005) The human brain is intrinsically organized into dynamic, anticorrelated functional networks. Proc. Natl. Acad. Sci. U.S.A. 102, 9673–9678 60 Vincent, J.L. et al. (2006) Coherent spontaneous activity identifies a hippocampal-parietal memory network. J. Neurophysiol. 96, 3517– 3531 61 Hayden, B. et al. (2010) Cognitive control signals in posterior cingulate cortex. Front. Hum. Neurosci. 4 62 Hayden, B.Y. et al. (2009) Electrophysiological correlates of defaultmode processing in macaque posterior cingulate cortex. Proc. Natl. Acad. Sci. U.S.A. 106, 5948–5953 63 Kim, H. et al. (2010) Overlapping brain activity between episodic memory encoding and retrieval: roles of the task-positive and tasknegative networks. Neuroimage 49, 1045–1054 64 Kounios, J. et al. (2006) The prepared mind. Psychol. Sci. 17, 882–890 65 Andrews-Hanna, J.R. et al. (2010) Functional-anatomic fractionation of the brain’s default network. Neuron 65, 550–562 66 Margulies, D.S. et al. (2009) Precuneus shares intrinsic functional architecture in humans and monkeys. Proc. Natl. Acad. Sci. U.S.A. 106, 20069–20074 67 Gusnard, D. et al. (2001) Role of medial prefrontal cortex in a default mode of brain function. Neuroimage 13, S414–S1414 68 Mason, M.F. et al. (2007) Wandering minds: the default network and stimulus-independent thought. Science 315, 393–395 69 Vincent, J.L. et al. (2007) Intrinsic functional architecture in the anaesthetized monkey brain. Nature 447, 83–84 70 Yukie, M. and Shibata, H. (2009) Temperocingulate interactions in the monkey. In Cingulate Neurobiology and Disease (Vogt, B., ed.), pp. 145–162, Oxford University Press 71 Gabriel, M. et al. (1987) Hippocampal control of cingulate cortical and anterior thalamic information processing during learning in rabbits. Exp. Brain Res. 67, 131–152 72 Broyd, S.J. et al. (2009) Default-mode brain dysfunction in mental disorders: a systematic review. Neurosci. Biobehav. Rev. 33, 279–296 73 Garrity, A.G. et al. (2007) Aberrant ‘‘default mode’’ functional connectivity in schizophrenia. Am. J. Psychiatry 164, 450–457 74 Nestor, P.J. et al. (2003) Retrosplenial cortex (BA 29/30) hypometabolism in mild cognitive impairment (prodromal Alzheimer’s disease). Eur. J. Neurosci. 18, 2663–2667 75 Zhou, Y. et al. (2008) Abnormal connectivity in the posterior cingulate and hippocampus in early Alzheimer’s disease and mild cognitive impairment. Alzheimer’s Demen. 4, 265–270 76 Vogt, B. (2009) Cingulate Neurobiology and Disease, Oxford University Press 77 Wilson, R. et al. (2010) Bayesian online learning of the hazard rate in change-point problems. Neural. Comput. 22, 2452–2476 78 Ma, W. et al. (2006) Bayesian inference with probabilistic population codes. Nat. Neurosci. 9, 1432–1438 79 Gron, G. et al. (2000) Brain activation during human navigation: gender-different neural networks as substrate of performance. Nat. Neurosci. 3, 404–408 80 Bussey, T.J. et al. (1996) Dissociable effects of anterior and posterior cingulate cortex lesions on the acquisition of a conditional visual discrimination: facilitation of early learning vs. impairment of late learning. Behav. Brain Res. 82, 45–56 81 Hirono, N. et al. (1998) Hypofunction in the posterior cingulate gyrus correlates with disorientation for time and place in Alzheimer’s disease. J. Neurol. Neurosurg. Psychiatry 64, 552–554 9