Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
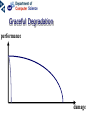
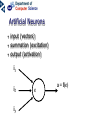
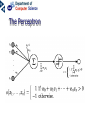
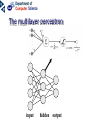
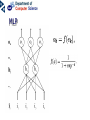
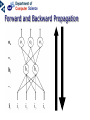
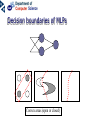
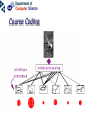
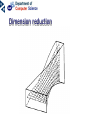
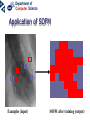
Neural networks Eric Postma IKAT Universiteit Maastricht Overview Introduction: The biology of neural networks • the biological computer • brain-inspired models • basic notions Interactive neural-network demonstrations • Perceptron • Multilayer perceptron • Kohonen’s self-organising feature map • Examples of applications A typical AI agent Two types of learning • Supervised learning – curve fitting, surface fitting, ... • Unsupervised learning – clustering, visualisation... An input-output function Fitting a surface to four points (Artificial) neural networks The digital computer versus the neural computer The Von Neumann architecture The biological architecture Digital versus biological computers 5 distinguishing properties • speed • robustness • flexibility • adaptivity • context-sensitivity Speed: The “hundred time steps” argument The critical resource that is most obvious is time. Neurons whose basic computational speed is a few milliseconds must be made to account for complex behaviors which are carried out in a few hudred milliseconds (Posner, 1978). This means that entire complex behaviors are carried out in less than a hundred time steps. Feldman and Ballard (1982) Graceful Degradation performance damage Flexibility: the Necker cube vision = constraint satisfaction Adaptivitiy processing implies learning in biological computers versus processing does not imply learning in digital computers Context-sensitivity: patterns emergent properties Robustness and context-sensitivity coping with noise The neural computer • Is it possible to develop a model after the natural example? • Brain-inspired models: – models based on a restricted set of structural en functional properties of the (human) brain The Neural Computer (structure) Neurons, the building blocks of the brain Neural activity out in Synapses, the basis of learning and memory Learning: Hebb’s rule neuron 1 synapse neuron 2 Connectivity An example: The visual system is a feedforward hierarchy of neural modules Every module is (to a certain extent) responsible for a certain function (Artificial) Neural Networks • Neurons – activity – nonlinear input-output function • Connections – weight • Learning – supervised – unsupervised Artificial Neurons • • • input (vectors) summation (excitation) output (activation) i1 i2 i3 e a = f(e) Input-output function • nonlinear function: 1 f(x) = 1 + e -x/a a0 f(e) a e Artificial Connections (Synapses) • wAB – The weight of the connection from neuron A to neuron B A wAB B The Perceptron Learning in the Perceptron • Delta learning rule – the difference between the desired output t and the actual output o, given input x • Global error E – is a function of the differences between the desired and actual outputs Gradient Descent Linear decision boundaries The history of the Perceptron • Rosenblatt (1959) • Minsky & Papert (1961) • Rumelhart & McClelland (1986) The multilayer perceptron input hidden output Training the MLP • supervised learning – – – – each training pattern: input + desired output in each epoch: present all patterns at each presentation: adapt weights after many epochs convergence to a local minimum phoneme recognition with a MLP Output: pronunciation input: frequencies Non-linear decision boundaries Compression with an MLP the autoencoder hidden representation Learning in the MLP Preventing Overfitting GENERALISATION = performance on test set • • • Early stopping Training, Test, and Validation set k-fold cross validation – leaving-one-out procedure Image Recognition with the MLP Hidden Representations Other Applications • • Practical – OCR – financial time series – fraud detection – process control – marketing – speech recognition Theoretical – cognitive modeling – biological modeling Some mathematics… Perceptron Derivation of the delta learning rule Target output Actual output h=i MLP Sigmoid function • May also be the tanh function – (<-1,+1> instead of <0,1>) • Derivative f’(x) = f(x) [1 – f(x)] Derivation generalized delta rule Error function (LMS) Adaptation hidden-output weights Adaptation input-hidden weights Forward and Backward Propagation Decision boundaries of Perceptrons Straight lines (surfaces), linear separable Decision boundaries of MLPs Convex areas (open or closed) Decision boundaries of MLPs Combinations of convex areas Learning and representing similarity Alternative conception of neurons • Neurons do not take the weighted sum of their inputs (as in the perceptron), but measure the similarity of the weight vector to the input vector • The activation of the neuron is a measure of similarity. The more similar the weight is to the input, the higher the activation • Neurons represent “prototypes” Course Coding 2nd order isomorphism Prototypes for preprocessing Kohonen’s SOFM (Self Organizing Feature Map) • • Unsupervised learning Competitive learning winner output input (n-dimensional) Competitive learning • • Determine the winner (the neuron of which the weight vector has the smallest distance to the input vector) Move the weight vector w of the winning neuron towards the input i i i w w Before learning After learning Kohonen’s idea • Impose a topological order onto the competitive neurons (e.g., rectangular map) • Let neighbours of the winner share the “prize” (The “postcode lottery” principle.) • After learning, neurons with similar weights tend to cluster on the map Topological order neighbourhoods • Square – winner (red) – Nearest neighbours • Hexagonal – Winner (red) – Nearest neighbours A simple example • A topological map of 2 x 3 neurons and two inputs visualisation 2D input input weights Weights before training Input patterns (note the 2D distribution) Weights after training Another example • Input: uniformly randomly distributed points • Output: Map of 202 neurons • Training – Starting with a large learning rate and neighbourhood size, both are gradually decreased to facilitate convergence Dimension reduction Adaptive resolution Application of SOFM Examples (input) SOFM after training (output) Visual features (biologically plausible) Relation with statistical methods 1 • Principal Components Analysis (PCA) Projections of data pca1 pca2 pca1 pca2 Relation with statistical methods 2 • • Multi-Dimensional Scaling (MDS) Sammon Mapping Distances in highdimensional space Image Mining the right feature Fractal dimension in art Jackson Pollock (Jack the Dripper) Fractal dimension Taylor, Micolich, and Jonas (1999). Fractal Analysis of Pollock’s drip paintings. Nature, 399, 422. (3 june). } Creation date Range for natural images Our Van Gogh research Two painters • Vincent Van Gogh paints Van Gogh • Claude-Emile Schuffenecker paints Van Gogh Sunflowers • Is it made by – Van Gogh? – Schuffenecker? Approach • • Select appropriate features (skipped here, but very important!) Apply neural networks van Gogh Schuffenecker Training Data Van Gogh (5000 textures) Schuffenecker (5000 textures) Results • Generalisation performance • 96% correct classification on untrained data Resultats, cont. • Trained art-expert network applied to Yasuda sunflowers • 89% of the textures is geclassificeerd as a genuine Van Gogh A major caveat… • Not only the painters are different… • …but also the material and maybe many other things…