Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
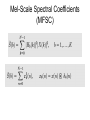
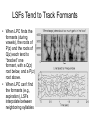
Landmark-Based Speech Recognition: Spectrogram Reading, Support Vector Machines, Dynamic Bayesian Networks, and Phonology Mark Hasegawa-Johnson [email protected] University of Illinois at Urbana-Champaign, USA Lecture 6: Speech Recognition Acoustic & Auditory Model Features • Log spectral features: log FFT, cepstrum, MFCC • Time-domain features: energy, zero crossing rate, autocorrelation • Model-based features: LPC, LPCC, PLP • Modulation filtering: cepstral mean subtraction, RASTA • Auditory model based features: auditory spectrogram, correlogram, summary correlogram Log Magnitude STFT The Problem with FFT: Euclidean Distance ≠ Perceptual Distance The “Complex Cepstrum” Cepstrum = Even Part of Complex Cepstrum Euclidean Distance Between Two Spectra = Cepstral Distance… … but Windowed Cepstral Distance = Distance Between Smoothed Spectra Cepstrally smoothed spectra Short-Time Fourier Transform = Filterbank with Uniformly Spaced Bands How to Implement Non-Uniform Filters Using the STFT Mel-Scale Bandpass Filters The Mel Frequency Scale: Humans Can Distinguish Tones 3 Mel Apart The Bark Scale (a.k.a. “Critical Band Scale”): Noise Within 1 Bark Can “Mask” a Tone Bark-Scale Warped Spectrum Mel-Scale Spectral Coefficients (MFSC) Mel-Scale Spectra of Music (Petruncio, B.S. Thesis University of Illinois, 2003) Piano Saxophone Tenor Opera Singer Drums Mel-Scale Cepstral Coefficients (MFCC) MFCC of Music (Petruncio, 2003) Piano Saxophone Tenor Opera Singer Drums Time-Domain Features “Time-Domain Features” = Features that can be computed frequently (e.g., once/millisecond) • Energy-based features: energy, sub-band energies • Low-order cepstral features: energy, spectral tilt, spectral centrality • Zero-crossing rate • Spectral flatness • Autocorrelation Example: 3 Features/1ms (Niyogi and Burges, 2002) Waveform Energy HF Energy Spectral Flatness Stop-Detection SVM TargetOutput Figure from Niyogi & Burges, 2002 Short-Time Analysis: First, Window with Overlapping Windows Energy-Based Features • Filter the signal, to get the desired band – – – – – [0,400]: is the signal voiced? (doesn’t work for telephone speech) [300,1000]: is the signal sonorant? [1000,3000]: distinguish nasals from glides [2000,6000]: detect frication energy Full Band (no filtering): syllable detection • Window with a short window (4-6ms in length) • Compute the energy: Cepstrum-Based Features • Average(log(energy)) = c[0] – c[0] = ʃ log|X(w)|dw = ½ ʃ log |X(w)|2 dw – Not the same as log(average(energy)), which is log ʃ |X(w)|2dw • Spectral Tilt: one measure is -c[1] – -c[1] = -ʃ log|X(w)|cos(w)dw ≈ HF log energy – LF log energy • A More Universally Accepted Measure: – Spectral Tilt = ʃ (w-p/2) log|X(w)| dw • Spectral Centrality: -c[2] – c[2] = -ʃ log|X(w)|cos(2w)dw – c[2] ≈ Mid Frequency Energy (p/4 to 3p/4) – Low and High Frequency Energy (0 to p/4 and 3p/4 to p) Measures of Turbulence • Zero Crossing Rate: – Count the number of times that the signal crosses zero in one window. Many: frication. Some: sonorant. Few: silence. – A related measure, used often in speech coding: “alternation rate” = the number of times the derivative crosses zero • Spectral Flatness: – average(log(energy)) – log(average(energy)) – Equal to zero if spectrum is flat (white noise, e.g., frication) – Negative if spectrum is peaky (e.g., vowels) Autocorrelation • Autocorrelation: measures the similarity of the signal to a delayed version of itself – Sonorant (low-frequency) signals: R[1] is large – Fricative (high-frequency) signals: R[1] is small or negative • R[0] is the energy – -R[0] ≤ R[k] ≤ R[0] for all k Model-Based Features: LPC, LPCC, PLP During Vowels and Glides, VT Transfer Function is All-Pole (All-Pole Model sometimes OK at other times too) Finding LPC Coefficients: Solve the “Normal Equations” • LPC Filter Prediction of s[n] is Saks[n-k]. Error is En: • ak minimize the error if they solve the Normal Equations: Roots of the LPC Polynomial • Roots of the LPC Polynomial: • Roots include: – Complex pole pair at most formant frequencies, rk and rk* – In a vowel or glide, there are additional poles at zero frequency: • One or two with bandwidth ≈ 100-300Hz; these give a negative tilt to the entire spectrum • One or two with bandwidth ≈ 2000-3000Hz; these attenuate high frequencies – In a fricative: poles may be at w=p, causing the whole spectrum to be high-pass Reflection Coefficients • LPC Speech Synthesis Filter can be implemented using a reflection line. This reflection line is mathematically equivalent to a p-tube model of the vocal tract: • PARCOR coefficients (= reflection coefficients) are found using the Levinson-Durbin recursion: LAR and LSF • Log Area Ratio (LAR) is bilinear transform of the reflection coefficients: • Line Spectral Frequencies (LSF) are the resonances of two lossless vocal tract models. Set U(0,jW)=0 at glottis; result is P(z). Set P(0,jW)=0 at glottis, result is Q(z). (Hasegawa-Johnson, JASA 2000) LSFs Tend to Track Formants • When LPC finds the formants (during vowels), the roots of P(z) and the roots of Q(z) each tend to “bracket” one formant, with a Q(z) root below, and a P(z) root above. • When LPC can’t find the formants (e.g., aspiration), LSFs interpolate between neighboring syllables LPC Cepstrum: Efficient Recursive Formula LPC Cepstrum: Efficient Recursive Formula Perceptual LPC (Hermansky, J. Acoust. Soc. Am., 1990) • First, warp the spectrum to a Bark scale: • The filters, Hb(k), are uniformly spaced in Bark frequency. Their amplitudes are scaled by the equalloudness contour (an estimate of how loud each frequency sounds): Perceptual LPC • Second, compute the cube-root of the power spectrum – Cube root replaces the logarithm that would be used in MFCC – Loudness of a tone is proportional to cube root of its power Y(b) = S(b)0.33 • Third, inverse Fourier transform to find the “Perceptual Autocorrelation:” Perceptual LPC • Fourth, use Normal Equations to find the Perceptual LPC (PLP) coefficients: • Fifth, use the LPC Cepstral recursion to find Perceptual LPC Cepstrum (PLPCC): Modulation Filtering: Cepstral Mean Subtraction, RASTA Reverberation • Reverberation adds echos to the recorded signal: • Reverberation is a linear filter: x[n] = Sk=0∞ak s[n-dk] • If ak dies away fast enough (ak≈0 for dk>N, the STFT window length), we can model reverberation in the STFT frequency domain: X(z) = R(z) S(z) • Usually, STFT frequency-domain modeling of reverberation works for – Electric echoes (e.g., from the telephone network) – Handset echoes (e.g., from the chin of the speaker) – But NOT for free-field echoes (e.g., from the walls of a room, recorded by a desktop microphone) Reverberation: Recorded and Simulated Room Response Cepstral Mean Subtraction: Subtract out Short-Term Reverb • Log Magnitude Spectrum: Constant Filter → Constant Additive Term • Reverberation R(z) is Constant during the whole sentence • Therefore: Subtract the average value from each frame’s cepstrum log R(z) is completely subtracted away • Warning: if the utterance is too short (contains too few phonemes), CMS will remove useful phonetic information! Modulation Filtering • Short-Time Log-Spectrum, log|Xt(w)|, is a function of t (frame number) and w. • Speaker information (log|Pt(w)|), Transfer function information (log|Tt(w)|), and Channel/Reverberation Information (log|Rt(w)|) may vary at different speeds with respect to frame number t. log|Xt(w)| = log|Rt(w)| + log|Tt(w)| + log|Pt(w)| • Assumption: Only log|Tt(w)| carries information about phonemes. Other components are “noise.” • Wiener filtering approach: filter log|Xt(w)| to compute an estimate of log|Tt(w)|. log|Tt*(w)| = Sk hk log|Xt-k(w)| RASTA (RelAtive SpecTral Amplitude) (Hermansky, IEEE Trans. Speech and Audio Proc., 1994) • Modulation-filtering of the cepstrum is equivalent to modulation-filtering of the log spectrum: ct*[m] = Sk hk ct-k[m] • RASTA is a particular kind of modulation filter: Features Based on Models of Auditory Physiology Processing of Sound by the Inner Ear 1. 2. 3. 4. Bones of the middle ear act as an impedance matcher, ensuring that not all of the incoming wave is reflected from the fluid-air boundary at the surface of the cochlea. The basilar membrane divides the top half of the cochlea (scala vestibuli) from the bottom half (scala tympani). The basal end is light and stiff, therefore tuned to high frequencies; the apical end is loose and floppy, therefore tuned to low frequencies. Thus the whole system acts like a bank of mechanical bandpass filters, with Q=centerfrequency/bandwidth≈6. Hair cells on the surface of the basilar membrane release neurotransmitter when they are bent down, but not when they are pulled up. Thus they half-wave rectify the wave-like motion of the basilar membrane. Neurotransmitter, in the cleft between hair cell and neuron, takes a little while to build up or to dissipate. The inertia of neurotransmitter acts to low-pass filter the half-wave rectified signal, with a cutoff around 2kHz. Result is a kind of localized energy in a ~0.5ms window. Filtering: Different Frequencies Excite Different Positions on the Basilar Membrane Inner and Outer Hair Cells on the Basilar Membrane. Each column of hair cells is tuned to a slightly different center frequency. Half-Wave Rectification: Only Down-Bending of the Hair Cells Excites a Neural Response Close-up view of outer hair cells, in a “V” configuration Neural Response to a Synthetic Vowel (Cariani, 2000) Temporal Structure of the Neural Response • Neural response patterns carries more information than just average energy (spectrogram) • For example: periodicity – Correlogram (Licklider, 1951): Measure periodicity on each simulated neuron by computing its autocorrelation – Recursive Neural Net (Cariani, 2000): Measure periodicity by building up response strength in an RNN with different delay loops – YIN pitch tracker (de Cheveigne and Kawahara, 2002): Measure periodicity using the absolute value of the difference between delayed signals Correlogram of a Sine Wave: Center Frequency vs. Autocorrelation Delay, Snapshot at one Instant in Time Correlogram of a Periodic Signal with spectral peaks at 2F0, 3F0, etcetera but none at F0 (missing fundamental) Correlogram of an Owl Hooting • Y axis = neuron’s center frequency • X axis = autocorrelation delay (same as on previous two slides • Time = time lapsed in the movie (real-time movie) • Notice: pitch fine structure, within each band, could be used to separate two different audio input signals, performing simultaneous recognition of two speech signals. Gandhi and HasegawaJohnson, ICSLP 2004 Summary • Log spectrum, once/10ms, computed with a window of about 25ms, seems to carry lots of useful information about place of articulation and vowel quality – Euclidean distance between log spectra is not a good measure of perceptual distance – Euclidean distance between windowed cepstra is better – Frequency warping (mel-scale or Bark-scale) is even better – Fitting an all-pole model (PLP) seems to improve speakerindependence – Modulation filtering (CMS, RASTA) improve robustness to channel variability (short-impulse-response reverb) • Time-domain features (once/1ms) can capture important information about manner of articulation and landmark times • Auditory model features (correlogram, delayogram) are useful for recognition of multiple simultaneous talkers