Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Gene expression wikipedia , lookup
Vectors in gene therapy wikipedia , lookup
Transposable element wikipedia , lookup
Molecular cloning wikipedia , lookup
Bisulfite sequencing wikipedia , lookup
Promoter (genetics) wikipedia , lookup
Multilocus sequence typing wikipedia , lookup
Whole genome sequencing wikipedia , lookup
Nucleic acid analogue wikipedia , lookup
Silencer (genetics) wikipedia , lookup
Deoxyribozyme wikipedia , lookup
Two-hybrid screening wikipedia , lookup
Molecular ecology wikipedia , lookup
Genomic library wikipedia , lookup
Endogenous retrovirus wikipedia , lookup
Ancestral sequence reconstruction wikipedia , lookup
Community fingerprinting wikipedia , lookup
Point mutation wikipedia , lookup
Non-coding DNA wikipedia , lookup
Structural alignment wikipedia , lookup
BCH 5405
Molecular Biology & Biotechnology
Dr. Qing-Xiang (Amy) Sang
Tuesday, March 24, 2009
A BioInformatics Survey
. . . with a focus on functional
genomics
Steve Thompson
Florida State University Department of
Scientific Computing (DSC)
To begin,
some terminology
What is bioinformatics,
genomics, proteomics,
sequence analysis,
computational molecular
biology . . . ?
My definitions, lots of overlap
Biocomputing and computational biology are synonyms and
describe the use of computers and computational techniques
to analyze any type of a biological system, from individual
molecules to organisms to overall ecology.
Bioinformatics describes using computational techniques to
access, analyze, and interpret the biological information in
any type of biological database.
Sequence analysis is the study of molecular sequence data for
the purpose of inferring the function, interactions, evolution,
and perhaps structure of biological molecules.
Genomics analyzes the context of genes or complete genomes
(the total DNA content of an organism) within the same and/or
across different genomes.
Proteomics is the subdivision of genomics concerned with
analyzing the complete protein complement, i.e. the proteome,
of organisms, both within and between different organisms.
And one way to think about it . . .
the Reverse Biochemistry Analogy
Biochemists no longer have to begin a research
project by isolating and purifying massive amounts
of a protein from its native organism in order to
characterize a particular gene product. Rather,
now scientists can amplify a section of some
genome based on its similarity to other genomes,
sequence that piece of DNA and, using sequence
analysis tools, infer all sorts of functional,
evolutionary, and, perhaps, structural insight into
that stretch of DNA!
The computer and molecular databases are a
necessary, integral part of this entire process.
The exponential growth of molecular
sequence databases & cpu power
Year
1982
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
2001
2002
2003
2004
2005
2006
2997
2008
2009
BasePairs
680338
2274029
3368765
5204420
9615371
15514776
23800000
34762585
49179285
71947426
01008486
157152442
217102462
384939485
651972984
1160300687
2008761784
3841163011
11101066288
15849921438
28507990166
36553368485
44575745176
56037734462
69019290705
83874179730
99116431942
101467270308
Sequences
606
2427
4175
5700
9978
14584
20579
28791
39533
55627
78608
143492
215273
555694
1021211
1765847
2837897
4864570
10106023
14976310
22318883
30968418
40604319
52016762
64893747
80388382
98868465
101815678
QuickTime™ and a
TIFF (Uncompressed) decompressor
are needed to see this picture.
Doubling time about a year and half!
http://www.ncbi.nlm.nih.gov/Genbank/genbankstats.html
Sequence database growth (cont.)
The International Human Genome Sequencing
Consortium announced the completion of the "Working
Draft" of the human genome in June 2000;
independently that same month, the private company
Celera Genomics announced that it had completed the
first “Assembly” of the human genome. The classic
articles were published mid-February 2001 in the
journals Science and Nature.
Genome projects have kept the data coming at an
incredible rate. Currently around 60 Archaea, 800
Bacteria, and 25 Eukaryote complete genomes, and 250
Eukaryote assemblies are represented, not counting the
well over 2,000 virus and viroid genomes available.
Some neat stuff from the human genome papers
Homo sapiens, aren’t nearly as special as we once
thought. Of the 3.2 billion base pairs in our DNA:
Traditional gene number estimates were often in the
100,000 range; turns out we’ve only got about twice
as many as a fruit fly, between 25’ and 30,000!
The protein coding region of the genome is only about
1% or so, a bunch of the remainder is ‘jumping,’
‘junk,’ ‘selfish DNA,’ much of which may be involved
in regulation and control (see CNEs at end of talk).
Some 100-200 genes were transferred from an
ancestral bacterial genome to an ancestral
vertebrate genome! However . . .
Later shown to be false by more extensive analyses, and
to be due to gene loss, not transfer.
NCBI’s
Entrez
Let’s start with sequence databases
Sequence databases are an organized way to store exponentially
accumulating sequence data. An ‘alphabet soup’ of three major
organizations maintain them. They largely ‘mirror’ one another and
share accession codes, but NOT proper identifier names:
North America: the National Center for Biotechnology Information
(NCBI), a division of the National Library of Medicine (NLM), at the
National Institute of Health (NIH), maintains the GenBank (& WGS)
nucleotide, GenPept amino acid, and RefSeq genome,
transcriptome, and proteome databases.
Europe: the European Molecular Biology Laboratory (EMBL), the
European Bioinformatics Institute (EBI), and the Swiss Institute of
Bioinformatics (SIB) all help maintain the EMBL nucleotide
sequence database, and the UNIPROT (SWISS-PROT + TrEMBL)
amino acid sequence database (with USA NBRF/PIR support also).
Asia: The National Institute of Genetics (NIG) supports the Center
for Information Biology’s (CIG) DNA Data Bank of Japan (DDBJ).
A little history
The first well recognized sequence database was Dr.
Margaret Dayhoff’s hardbound Atlas of Protein
Sequence and Structure begun in the mid-sixties. That
became NBRF/PIR (National Biomedical Research
Foundation Protein Information Resource). DDBJ began
in 1984, GenBank in 1982, and EMBL in 1980. They are
all attempts at establishing an organized, reliable,
comprehensive, and openly available library of genetic
sequences.
Sequence databases have long-since outgrown a
hardbound atlas that you can pull off of a library shelf.
They have become gargantuan and have evolved
through many, many changes.
What are sequence databases like?
Just what are primary sequences?
(Central Dogma: DNA —> RNA —> protein)
Primary refers to one dimension — all of the ‘symbol’ information
written in sequential order necessary to specify a particular
biological molecular entity, be it polypeptide or nucleotide.
The symbols are the one letter codes for all of the biological
nitrogenous bases and amino acid residues and their ambiguity
codes. Biological carbohydrates, lipids, and structural and
functional information are not sequence data. Not even DNA
CDS translations in a DNA database are sequence data!
However, much of this feature and bibliographic type information is
available in the annotation associated with primary sequences in
the databases.
Sequence database organization
Nucleic acid sequence databases are split into subdivisions based
on taxonomy and data type. TrEMBL sequences are merged into
SWISS-PROT as they receive increased levels of annotation. Both
together comprise UNIPROT. GenPept has minimal annotation.
Nucleic Acid DB’s
GenBank/EMBL/DDBJ
all Taxonomic
categories +
WGS, HTC & HTG +
STS, EST, & GSS,
a.k.a. “Tags”
Amino Acid DB’s
UNIPROT =
SWISS-PROT +
TrEMBL (with
help from PIR)
Genpept
Format complications
Each major database and suite of software tools has its own distinct
format requirement. Standards are argued upon, e.g. XML, but progress
is slow to nonexistent. Format issues remain one of the most confusing
and troubling aspects of working with sequence data. Specialized format
conversion tools expedite the chore, but becoming familiar with some of
the common formats helps a lot.
Furthermore, indels and
missing data symbols (i.e.
gaps) present designation
discrepancy headaches —
., -, ~, ?, N, or X
. . . . . Help!
Specialized ‘sequence’ -type databases
Databases that contain special types of sequence
information, such as patterns, motifs, and profiles.
These include: REBASE, EPD, PROSITE, BLOCKS,
ProDom, Pfam . . . .
Databases that contain multiple sequence entries
aligned, e.g. PopSet, RDP and ALN.
Databases that contain families of sequences ordered
functionally, structurally, or phylogenetically, e.g.
iProClass and HOVERGEN.
Databases of species specific sequences, e.g. the HIV
Database and the Giardia lamblia Genome Project.
And on and on . . . . See Amos Bairoch’s excellent links
page: http://us.expasy.org/alinks.html.
What about other types of biological databases?
Three-dimensional structure databases
the Protein Data Bank and Rutgers Nucleic Acid Database.
And see Molecules to Go at http://molbio.info.nih.gov/cgibin/pdb/.
These databases contain all of the 3D atomic coordinate data
necessary to define the tertiary shape of a particular biological
molecule. The data is usually experimentally derived, either by
X-ray crystallography or by NMR, sometimes it’s hypothetical.
The source of the structure and its resolution is always given.
Secondary structure boundaries, sequence data, and reference
information are often associated with the coordinate data, but it is
the 3D data that really matters, not the annotation.
And still other types of bioinfo’ databases
Consider these ‘non-molecular’ but they often link to molecules:
Reference Databases (all w/ pointers to sequences): e.g.
Gene — integrated knowledge base of genetic loci
OMIM — Online Mendelian Inheritance in Man
PubMed/MedLine — over 11 million citations from more
than 4 thousand bio/medical scientific journals.
Phylogenetic Tree Databases: e.g. the Tree of Life.
Metabolic Pathway Databases: e.g. WIT (What Is There),
Japan’s GenomeNet KEGG (the Kyoto Encyclopedia of
Genes and Genomes), and the human Reactome.
Population studies data — which strains, where, etc.
And then databases that many biocomputing people don’t even
usually consider: e.g. GIS/GPS/remote sensing data, medical
records, census counts, mortality and birth rates . . . .
OK, given your own experimentally derived
nucleotide or amino acid sequence, or one
that you’ve found in a database, what more
can we learn about its biological function?
Enter pairwise alignment,
similarity searching,
significance, and
homology.
First, just what is homology and
similarity — are they the same?
Don’t confuse homology with similarity:
there is a huge difference! Similarity is a
statistic that describes how much two
(sub)sequences are alike according to
some set scoring criteria. It can be
normalized to ascertain statistical
significance, but it’s still just a number.
Homology, in contrast and by definition,
implies an evolutionary relationship — more than just
everything evolving from the same primordial ‘ooze.’
Reconstruct the phylogeny of the organisms or genes of
interest to demonstrate homology. Better yet, show
experimental evidence — structural, morphological,
genetic, and/or fossil — that corroborates your claim.
There is no such thing as percent homology; something
is either homologous or it is not. Walter Fitch said
“homology is like pregnancy — you can’t be 45%
pregnant, just like something can’t be 45% homologous.
You either are or you are not.” Highly significant
similarity can argue for homology, never the inverse.
OK, so how can we see if two
sequences are similar? First, to
introduce the concept, a graphical
method . . .
One way — dot matrices.
Provide a ‘Gestalt’ of all possible alignments
between two sequences.
To begin — very simple 0, 1 (match, nomatch)
identity scoring function.
Put a dot wherever symbols match.
Identities and insertion/deletion events (indels)
identified (zero:one match score matrix, no window).
Noise due to random composition effects contributes to confusion. To ‘clean up’
the plot consider a filtered windowing approach. A dot is placed at the middle of
a window if some ‘stringency’ is met within that defined window size. Then the
window is shifted one position and the entire process is repeated (zero:one
match score, window of size three and a stringency level of two out of three).
Exact alignment — but how can we ‘see’ the
correspondence of individual residues?
We can compare one molecule against another by
aligning them. However, a ‘brute force’ approach just
won’t work. Even without considering the introduction of
gaps, the computation required to compare all possible
alignments between two sequences requires time
proportional to the product of the lengths of the two
sequences. Therefore, if the two sequences are
approximately the same length (N), this is a N2 problem.
To include gaps, we would have to repeat the
calculation 2N times to examine the possibility of gaps
at each possible position within the sequences, now a
N4N problem. There’s no way! We need an algorithm.
But —
Just what the heck is an algorithm?
Merriam-Webster’s says: “A rule
of procedure for solving a
problem [often mathematical]
that frequently involves repetition
of an operation.”
So, you could write an algorithm
for tying your shoe! It’s just a set
of explicit instructions for doing
some routine task.
Enter the Dynamic Programming Algorithm!
Computer scientists figured it out long ago; Needleman and Wunsch
applied it to the alignment of the full lengths of two sequences in
1970. An optimal alignment is defined as an arrangement of two
sequences, 1 of length i and 2 of length j, such that:
1)
2)
3)
you maximize the number of matching symbols between 1 and 2;
you minimize the number of indels within 1 and 2; and
you minimize the number of mismatched symbols between 1 and 2.
Therefore, the actual solution can be represented by:
Sij = sij + max
Si-1
max
2 <
max
2 <
j-1
Si-x j-1 + wx-1
x < i
Si-1 j-y + wy-1
y < I
or
or
Where Sij is the score for the alignment ending at i in sequence 1 and j in
sequence 2,
sij is the score for aligning i with j,
wx is the score for making a x long gap in sequence 1,
wy is the score for making a y long gap in sequence 2,
allowing gaps to be any length in either sequence.
An oversimplified path matrix example
total penalty = gap opening penalty {zero here} + ([length of gap][gap extension penalty {one here}])
Optimum Alignments
There may be more than one best path through the matrix (and
optimum doesn’t guarantee biologically correct). Starting at the top
and working down, then tracing back, the two best trace-back routes
define the following two alignments:
cTATAtAagg
| ||||| and
cg.TAtAaT.
cTATAtAagg
|||||
.cgTAtAaT.
With the example’s scoring scheme these alignments have a score
of 5, the highest bottom-right score in the trace-back path graph,
and the sum of six matches minus one interior gap. This is the
number optimized by the algorithm, not any type of a similarity or
identity percentage, here 75% and 62% respectively! Software will
report only one optimal solution.
This was a Needleman Wunsch global solution. Smith Waterman
style local solutions use negative numbers in the match matrix and
pick the best diagonal within the overall graph.
What about proteins — conservative replacements and similarity as
opposed to identity. The nitrogenous bases are either the same or
they’re not, but amino acids can be similar, genetically, evolutionarily,
and structurally! The BLOSUM62 table (Henikoff and Henikoff, 1992).
A
B
C
D
E
F
G
H
I
K
L
M
N
P
Q
R
S
T
V
W
X
Y
Z
A
4
-2
0
-2
-1
-2
0
-2
-1
-1
-1
-1
-2
-1
-1
-1
1
0
0
-3
-1
-2
-1
B
-2
6
-3
6
2
-3
-1
-1
-3
-1
-4
-3
1
-1
0
-2
0
-1
-3
-4
-1
-3
2
C
0
-3
9
-3
-4
-2
-3
-3
-1
-3
-1
-1
-3
-3
-3
-3
-1
-1
-1
-2
-1
-2
-4
D
-2
6
-3
6
2
-3
-1
-1
-3
-1
-4
-3
1
-1
0
-2
0
-1
-3
-4
-1
-3
2
E
-1
2
-4
2
5
-3
-2
0
-3
1
-3
-2
0
-1
2
0
0
-1
-2
-3
-1
-2
5
F
-2
-3
-2
-3
-3
6
-3
-1
0
-3
0
0
-3
-4
-3
-3
-2
-2
-1
1
-1
3
-3
G
0
-1
-3
-1
-2
-3
6
-2
-4
-2
-4
-3
0
-2
-2
-2
0
-2
-3
-2
-1
-3
-2
H
-2
-1
-3
-1
0
-1
-2
8
-3
-1
-3
-2
1
-2
0
0
-1
-2
-3
-2
-1
2
0
I
-1
-3
-1
-3
-3
0
-4
-3
4
-3
2
1
-3
-3
-3
-3
-2
-1
3
-3
-1
-1
-3
K
-1
-1
-3
-1
1
-3
-2
-1
-3
5
-2
-1
0
-1
1
2
0
-1
-2
-3
-1
-2
1
L
-1
-4
-1
-4
-3
0
-4
-3
2
-2
4
2
-3
-3
-2
-2
-2
-1
1
-2
-1
-1
-3
M
-1
-3
-1
-3
-2
0
-3
-2
1
-1
2
5
-2
-2
0
-1
-1
-1
1
-1
-1
-1
-2
N
-2
1
-3
1
0
-3
0
1
-3
0
-3
-2
6
-2
0
0
1
0
-3
-4
-1
-2
0
P
-1
-1
-3
-1
-1
-4
-2
-2
-3
-1
-3
-2
-2
7
-1
-2
-1
-1
-2
-4
-1
-3
-1
Q
-1
0
-3
0
2
-3
-2
0
-3
1
-2
0
0
-1
5
1
0
-1
-2
-2
-1
-1
2
R
-1
-2
-3
-2
0
-3
-2
0
-3
2
-2
-1
0
-2
1
5
-1
-1
-3
-3
-1
-2
0
S
1
0
-1
0
0
-2
0
-1
-2
0
-2
-1
1
-1
0
-1
4
1
-2
-3
-1
-2
0
T
0
-1
-1
-1
-1
-2
-2
-2
-1
-1
-1
-1
0
-1
-1
-1
1
5
0
-2
-1
-2
-1
V
0
-3
-1
-3
-2
-1
-3
-3
3
-2
1
1
-3
-2
-2
-3
-2
0
4
-3
-1
-1
-2
W
-3
-4
-2
-4
-3
1
-2
-2
-3
-3
-2
-1
-4
-4
-2
-3
-3
-2
-3
11
-1
2
-3
X
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
-1
Y
-2
-3
-2
-3
-2
3
-3
2
-1
-2
-1
-1
-2
-3
-1
-2
-2
-2
-1
2
-1
7
-2
Z
-1
2
-4
2
5
-3
-2
0
-3
1
-3
-2
0
-1
2
0
0
-1
-2
-3
-1
-2
5
Identity values range from 4 to 11, some similarities are as high as 3, and negative values for those
substitutions that rarely occur go as low as –4. The most conserved residue is tryptophan with a
score of 11; cysteine is next with a score of 9; both proline and tyrosine get scores of 7 for identity.
We can imagine screening databases for sequences
similar to ours using the concepts of dynamic
programming and substitution scoring matrices and
some yet to be described algorithmic tricks. But what do
database searches tell us; what can we gain from them?
Why even bother? Inference through
homology is a fundamental principle
of biology!
When a sequence is found to fall into a preexisting
family we may be able to infer function, mechanism,
evolution, perhaps even structure, based on homology
with its neighbors.
Independent of all that, what is a
‘good’ alignment?
So, first — significance:
when is any alignment worth
anything biologically?
An old statistics trick — Monte Carlo simulations:
Z score = [ ( actual score ) - ( mean of randomized scores ) ]
( standard deviation of randomized score distribution )
The Normal distribution —
Many Z scores measure the distance from the mean
using this simplistic Monte Carlo model assuming a
Gaussian distribution, a.k.a. the Normal distribution
(http://mathworld.wolfram.com/NormalDistribution.html),
in spite of the fact that ‘sequence-space’ actually
follows what is know as the ‘Extreme Value distribution.’
However, the Monte Carlo method does approximate
significance estimates fairly well.
0:==
< 20 650
0:
0
22
0:=
3
24
8:*
26 22
28 98 87:*
30 289 528:*
32 1714 2042:===*
34 5585 5539:=========*
36 12495 11375:==================*==
38 21957 18799:===============================*=====
40 28875 26223:===========================================*====
42 34153 32054:=====================================================*===
44 35427 35359:==========================================================*
46 36219 36014:===========================================================*
48 33699 34479:======================================================== *
50 30727 31462:=================================================== *
52 27288 27661:=============================================*
54 22538 23627:====================================== *
56 18055 19736:============================== *
58 14617 16203:========================= *
60 12595 13125:=====================*
62 10563 10522:=================*
64 8626 8368:=============*=
66 6426 6614:==========*
68 4770 5203:========*
70 4017 4077:======*
72 2920 3186:=====*
74 2448 2484:====*
76 1696 1933:===*
78 1178 1503:==*
80 935 1167:=*
82 722 893:=*
84 454 707:=*
86 438 547:*
88 322 423:*
90 257 328:*
92 175 253:*
94 210 196:*
96 102 152:*
98 63 117:*
100 58 91:*
102 40 70:*
104 30 54:*
106 17 42:*
108 14 33:*
110 14 25:*
112 12 20:*
9 15:*
114
6 12:*
116
9:*
8
118
7:*=
>120 1030
‘Sequence-space’ (Huh, what’s that?)
actually follows the ‘Extreme Value distribution’
(http://mathworld.wolfram.com/ExtremeValueDistribution.html).
Based on this known statistical
distribution, and robust
statistical methodology, a
realistic Expectation function,
the E Value, can be calculated
from database searches.
The ‘take-home’ message is . . .
The Expectation Value!
The higher the E value is, the more probable that the
observed match is due to chance in a search of the
same size database, and the lower its Z score will be,
i.e. is NOT significant. Therefore, the smaller the E
value, i.e. the closer it is to zero, the more significant it
is and the higher its Z score will be! The E value is the
number that really matters. In other words, in order to
assess whether a given alignment constitutes evidence
for homology, it helps to know how strong an alignment
can be expected from chance alone.
Rules of thumb for a protein search
The Z score represents the number of standard deviations some
particular alignment is from a distribution of random alignments
(often the Normal distribution).
They very roughly correspond to the listed E Values (based on
the Extreme Value distribution) for a typical protein sequence
similarity search through a database with ~250,000 protein entries.
On to the searches —
How can you search the databases for similar
sequences, if pairwise alignments take N2
time?! Significance and heuristics . . .
Database searching programs use the two concepts of
dynamic programming and substitution scoring matrices;
however, dynamic programming takes far too long when
used against most sequence databases with a ‘normal’
computer. Remember how big the databases are!
Therefore, the programs use tricks to make things
happen faster. These tricks fall into two main categories,
that of hashing, and that of approximation.
Corn beef hash? Huh . . .
Hashing is the process of breaking your sequence into
small ‘words’ or ‘k-tuples’ (think all chopped up, just like
corn beef hash) of a set size and creating a ‘look-up’
table with those words keyed to position numbers.
Computers can deal with numbers way faster than they
can deal with strings of letters, and this preprocessing
step happens very quickly.
Then when any of the word positions match part of an
entry in the database, that match, the ‘offset,’ is saved.
In general, hashing reduces the complexity of the search
problem from N2 for dynamic programming to N, the
length of all the sequences in the database.
OK. Heuristics . . . What’s that?
Approximation techniques are collectively known as ‘heuristics.’
Webster’s defines heuristic as “serving to guide, discover, or reveal;
. . . but unproved or incapable of proof.”
In database similarity searching techniques the heuristic usually
restricts the necessary search space by calculating some sort of a
statistic that allows the program to decide whether further scrutiny
of a particular match should be pursued. This statistic may miss
things depending on the parameters set — that’s what makes it
heuristic. ‘Worthwhile’ results at the end are compiled and the
longest alignment within the program’s restrictions is created.
The exact implementation varies between the different programs,
but the basic idea follows in most all of them.
Two predominant versions exist: BLAST and Fast
Both return local alignments, and are not a single program, but
rather a family of programs with implementations designed to
compare a sequence to a database in about every which way.
These include:
1) a DNA sequence against a DNA database (not recommended unless
forced to do so because you are dealing with a non-translated region of
the genome — DNA is just too darn noisy, only identity & four bases!),
2) a translated (where the translation is done ‘on-the-fly’ in all six frames)
version of a DNA sequence against a translated (‘on-the-fly’ six-frame)
version of the DNA database (not available in the Fast package),
3) a translated (‘on-the-fly’ six-frame) version of a DNA sequence against
a protein database,
4) a protein sequence against a translated (‘on-the-fly’ six-frame) version
of a DNA database,
5) or a protein sequence against a protein database.
Translated comparisons allow penalty-free frame shifts.
The BLAST and Fast programs — some generalities
BLAST — Basic Local Alignment
Search Tool, developed at NCBI.
FastA — and its family of relatives,
developed by Bill Pearson at the
1) Normally NOT a good idea
to use for DNA against
DNA searches w/o
translation (not optimized);
2) Pre-filters repeat and “low
complexity” sequence
regions;
4) Can find more than one
region of gapped similarity;
5) Very fast heuristic and
parallel implementation;
6) Restricted to precompiled,
specially formatted
databases;
University of Virginia.
1) Works well for DNA against
DNA searches (within limits
of possible sensitivity);
2) Can find only one gapped
region of similarity;
3) Relatively slow, but parallel
implementations avail’;
4) Does not require specially
prepared, preformatted
databases.
The algorithms, in brief
BLAST:
Two word hits on the
same diagonal above
some similarity
threshold triggers
ungapped extension until
the score isn’t improved
enough above another
threshold:
the HSP.
Initiate gapped extensions
using dynamic programming for
those HSP’s above a third
threshold up to the point where
the score starts to drop below a
fourth threshold: yields
alignment.
Find all ungapped exact
word hits; maximize the
ten best continuous
regions’ scores: init1.
Fast:
Combine nonoverlapping init
regions on different
diagonals:
initn.
Use dynamic
programming ‘in a
band’ for all regions
with initn scores
better than some
threshold: opt score.
What’s the deal with DNA versus protein for
searches and alignment?
All similarity searching and sequence alignment, regardless of
algorithm, is far more sensitive at the amino acid level than at the
DNA level. This is because proteins have twenty match criteria
versus DNA’s four, and those four DNA bases can generally only be
identical, not similar, to each other; and many DNA base changes
(especially third position changes) do not change the encoded
protein. Furthermore, indels cannot occur within codons. All of
these factors drastically increase the ‘noise’ level of DNA against
DNA search and alignment, and give protein searches a much
greater ‘look-back’ time, at least doubling it.
Therefore, whenever dealing with coding sequence, it is always
prudent to search and align at the protein level!
On to multiple sequence alignment & analysis
So what; why even bother?
More data yields stronger analyses — as
long as it is done carefully!
Mosaic ideas and evolutionary ‘importance.’
Applications:
Probe, primer, and motif design;
Graphical illustrations;
Comparative ‘homology’ inference;
Molecular evolutionary analysis.
All right — how do you do it?
Dynamic programming’s complexity
increases exponentially with the number of
sequences being compared
N-dimensional matrix . . . .
complexity=[sequence length]number of sequences
i.e. complexity is O(en)
Multiple Sequence Dynamic Programming
Therefore, the most
common implementation,
pairwise, progressive
dynamic programming,
restricts the solution to the
neighborhood of only two
sequences at a time.
All sequences are
compared, pairwise, and
then each is aligned to its
most similar partner or
group of partners. Each
group of partners is then
aligned to finish the
complete multiple
sequence alignment.
Web resources for pairwise,
progressive multiple alignment
in the USA, include the Baylor College of
Medicine’s Search Launcher —
http://searchlauncher.bcm.tmc.edu/
However, problems with large datasets and
huge multiple alignments make doing multiple
sequence alignment on the Web impractical
after your dataset has reached a certain size.
You’ll know it when you’re there!
So, what else is available?
Stand-alone ClustalW is available for all
operating systems; its graphical user interface
ClustalX, makes running it very easy.
And dedicated biocomputing server suites, like
the GCG Wisconsin Package, which includes
ClustalW and the SeqLab graphical user
interface, are another powerful solution.
Furthermore, newer software such as TCoffee,
MUSCLE, ProbCons, POA, MAFFT, etc. add
various tweaks and tricks to make the entire
process more accurate and/or faster.
Reliability and the
Comparative Approach
explicit homologous correspondence;
manual adjustments based on
knowledge,
especially structural, regulatory, and
functional sites.
Therefore, editors like SeqLab and
the Ribosomal Database Project:
http://rdp.cme.msu.edu/index.jsp
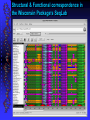
Structural & Functional correspondence in
the Wisconsin Package’s SeqLab
Beware of aligning apples and
oranges [and grapefruit]!
Receptor versus
activator or associated,
on ad nauseam;
parologue versus
orthologue;
genomic versus cDNA;
mature versus
precursor.
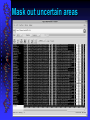
Mask out uncertain areas
Complications
Order dependence.
Not that big of a deal.
Substitution matrices and gap penalties.
A very big deal!
Regional ‘realignment’ becomes
incredibly important, especially with
sequences that have areas of high and
low similarity
Homology inference is especially
powerful for finding functional
domains
The information within a multiple sequence
alignment can dramatically point to
evolutionarily constrained elements in the
sequences. Furthermore, often functions
can experimentally be ascribed to them.
Therefore, we can search for those elements
in unknown sequences to attempt to
identify the unknown’s function.
How does this work?
The consensus and motifs
HMG
box
Conserved
regions in
alignments can
be visualized
with a sliding
window
approach and
appear as
peaks.
Refer to the peak
seen here in a
SRY/SOX
alignment.
The HMG box DNA binding domain
of SRY/SOX
A consensus isn’t
necessarily the
biologically
“correct”
combination.
A simple
consensus
throws much
information away!
Therefore, motif
consensus
KRPMNAFMVYXKXXRRKIXXXXPXXHNXEISKRLGXXWKXLXXXEKXPYIXEAXR
definition.
PROSITE, a simple fast approach
The trick is to define a motif such that it minimizes false positives
and maximizes true positives — it needs to be just discriminatory
enough.
Development is largely empirical; a pattern is made,
tested against the database, then refined, over and over, although
when
experimental
evidence
is
available,
it
is
always
incorporated. This is known as motif definition and Amos Bairoch
of ExPASy, has done it a bunch!
His database of catalogued structural, regulatory, and enzymatic
consensus patterns or ‘signatures’ is the PROSITE Database of
protein families and domains. It contains almost 3,000 different
patterns, rules, and profiles/matrices. Pattern descriptions for
these characteristic local sequence areas are variously and
confusingly known as motifs, templates, signatures, patterns, and
even fingerprints.
The HMG box
Defined as:
[FI]-S-[KR]-K-C-x[EK]-R-W-K-T-M.
A one-dimensional
‘regular-expression’
of a conserved site.
QuickTime™ and a
Graphics decompressor
are needed to see this picture.
Not necessarily
biologically
meaningful though,
and motifs are
limited in their ability
to discriminate a
residue’s
‘importance.’
So how do we include ‘all’ the information of a
multiple sequence alignment, or of a region
within an alignment, in a description that
doesn’t throw anything away?
Enter — two-dimensional techniques
for remote homology searching — the ‘profile’
algorithms, including PsiBLAST, MEME, and HMMer . . .
Michael Gribskov envisioned special weight
matrices in which conserved areas of the
alignment receive the most importance,
variable regions hardly matter, and gaps are
variably weighted depending where they are!
The basic idea is to tabulate how often every possible residue occurs at each
position, scale conserved positions up, variable positions down, and store the
whole thing in a matrix twenty residues wide by the length of your pattern.
A small piece of a profile —
Cons A
B
C
D
E
F
G
H
I
K
L
M
N
P
Q
R
S
T
-3
-41
-8
-6
-84
-4
-42
-78
-7
-78
-43
38
-43
-6
-38
135
-7 -146
-52
-50 -139
223
-92
-43
-5
-53
55
91
31
-20
2
-25
-56
8
37
140 -141
275
S
45
K
-49
R
-28
L
-66 -279
-41
-68
-57
45 -145 -102
-16
-69 -279 -209
-61
-77
-38
-2 -278 -210
-31
W
X
Y
40
-71 -123
-28
-81
-6 -163 100 100
-4
-49
-92 -146
-44
-95
48 -199 100 100
-22
-14
-26
-33
-49
-10 -123 100 100
137 -210 -209 -141 -141 -138
-69
-80
71 -142 -108
Z
*
Gap Len
-71 -209 -281 100 100
G
6
-63 -185
-62 -118 -187
360 -124 -246 -122 -246 -185
K
2
-14
-75
-19
37
-76
-47
-23
-72
48
-58
-36
-13
-39
20
27
8
-21
-51
-87
-27
-53
30 -123 100 100
R
-22
-39
-66
-41
2
-55
-70
-33
-34
7
-14
14
-27
-54
14
20
-17
-25
-29
-74
-31
-48
4 -120 100 100
W -300 -400 -200 -400 -300
K
-42
L
-6
14 -105
-41
-47
-25
-48
2 -122 -183 -129 -108 -186 -119 -252 100 100
100 -200 -200 -300 -300 -200 -100 -400 -400 -200 -300 -300 -200 -300 1100 -188
24 -100
-30
-4 -123 -121 -123
V
-46
-58
-54
4 -106
-49
-15
200 -300 -400 100 100
116
-79
-43
38
-47
30
59
4
-31
-82 -109
-31
-59
25 -142 100 100
-25
7
4
-16
-59
-21
-33
-7
-12
-14
-34
-49
-30 -122 100 100
-80
The greatest conservation is the invariant tryptophan. It’s the only residue
absolutely conserved — it gets the highest score, 1100! The -400 scores are
from substituting that tryptophan with an aspartate, asparagine, or proline. In
the BLOSUM matrix series tryptophan has the highest identity score of any
residue, and the most negative substitution scores include those from
tryptophan to aspartate, asparagine, and proline, times the highest
conservation in the region, equals the most negative scores in the profile.
Profile variations
Bailey and Elkan’s Expectation Maximization (MEME) uses Bayesian
probabilities and unsupervised learning to find, de novo, unknown
conserved motifs among a group of unaligned, ungapped
sequences. The motifs do not have to be in congruent order among
the different sequences; i.e. it has the power to discover ‘unalignable’
motifs between sequences. This characteristic differentiates MEME
from the other profile building techniques.
QuickTime™ and a
TIFF (LZW) decompressor
are needed to see this picture.
Profile variations, continued
As powerful as ‘traditional’
Gribskov style profiles are, they
require a lot of time and skill to
prepare and validate, and they
are heuristics based. Excess
subjectivity and a lack of formal
statistical rigor contribute as
drawbacks. Sean Eddy
developed the HMMer package,
which uses Hidden Markov
modeling, with a formal
probabilistic basis and consistent
gap insertion theory, to build and
manipulate HMMer profiles and
profile databases (PFam), to
search sequences against
HMMer profile databases and
visa versa, and to easily create
multiple sequence alignments
using HMMer profiles as a ‘seed.’
QuickTime™ and a
TIFF (LZW) decompres sor
are needed to see this picture.
These motif discovery tools can
assist to infer function
So, after finding potential genes in a
genome, one of the quickest and
most powerful means of inferring
potential function is to identify
described motifs and/or domains
within them.
But beware of gene duplication with
subsequent divergence. Enter
phylogenomics . . .
Function through phylogenomics
Information about the evolutionary
relationships among genes is used to
predict the functions of
uncharacterized genes. Two
hypothetical scenarios are presented
and the path of trying to infer the
function of two uncharacterized genes
in each case is traced. (A) A gene
family has undergone a gene
duplication that was accompanied by
functional divergence. (B) Gene
function has changed in one lineage.
The thin branches in the evolutionary
trees correspond to the gene
phylogeny and the thick gray branches
in A (bottom) correspond to the
phylogeny of the species in which the
duplicate genes evolve in parallel (as
paralogs). Different colors (and
symbols) represent different gene
functions; gray (with hatching)
represents either unknown or
unpredictable functions.
Jonathan A. Eisen Genome
Res. 1998; 8: 163-167
Genome scale analyses: map browsers and synteny viewers
try to tie it all together
Genetic linkage mapping databases for most large genome projects — H. sapiens,
Mus, Drosophila, C. elegans, Saccharomyces, Arabidopsis, E. coli — link to
other databases within the context of a genome browser/map viewer.
Examples include: NCBI’s Map Viewer (http://www.ncbi.nlm.nih.gov/mapview/),
the Ensemble Project (http://www.ensembl.org/), the UCSC Genome Browser
(http://genome.ucsc.edu/), and the Lawrence Livermore National Laboratory
ECR Browser (http://www.dcode.org/) — all provide resources for exploring
and comparing genomes.
The colinearity of orthologous markers between chromosomes is called synteny.
Precompiled synteny maps and dedicated synteny viewers, e.g. Sanger Institute’s
“Apollo” tool (http://www.fruitfly.org/annot/apollo/), and “Oxford Grids”
(http://www.informatics.jax.org/searches/oxfordgrid_form.shtml) from the Mouse
Genome Informatics group at the Jackson Laboratory, and
PipMaker/MultiPipMaker (http://pipmaker.bx.psu.edu/pipmaker/) at the Penn
State University Center for Comparative Genomics and Bioinformatics — all
assist in the visualization and alignment of similar regions within genomes.
The comparative approach and
noncoding elements
A key to genomics data
mining potential lie in
syntenic segment alignments.
Segments conserved through
evolution that do not code for
structure are often inferred to
relate to regulation. These
are sometimes called HCRs
for highly conserved regions,
or CNEs for conserved
noncoding elements, and can
be seen across vast
phylogenetic distances.
Adam Siepel et al. Genome
Res. 2005; 15: 1034-1050
CNEs from human to fish
CNEs shared
Human/shark
Human/Fugu
Human/zebrafish
Number
4782
2107
2838
Total length (kb)
1003
379
530
Average length (bp)
210
180
187
Maximum length (bp)
937
982
880
Venkatesh, et al. Science 22 December 2006:
Vol. 314. no. 5807, p. 1892
In particular, it is suggested that in mammals
there is at least twice as much conserved
genomic DNA as there is protein coding
DNA! So, if you accept 1.5% as the amount
of protein coding DNA in the human
genome, around 3% of the remaining falls
into this CNE class of regulatory elements.
CNEs evolved in Vertebrates very early on
McEwen, et al. Genome Res. 2006 Apr;16(4):451-65. Epub 2006 Mar 13
And the sort of functional genomics
that lots of folks like to think about
QuickTime™ and a
TIFF (Uncompressed) decompressor
are needed to see this picture.
DNA and RNA
microarrays, SAGE,
as well as yeast twohybrid assays, phage
display, 2D gels and
mass spec’ tech’s, are
all at the interface
between
bioinformatics and
wet-lab techniques to
gain understanding of
biological function. I
do not have a good
working knowledge of
these systems.
Conclusions
There’s a bewildering assortment of bioinformatics databases and tools.
The key is to learn how to use the data and the methods in the most
efficient manner! The better you understand the chemical, physical, and
biological systems involved, the better your chance of success in analyzing
them. Certain strategies are inherently more appropriate to others in
certain circumstances. Making these types of subjective, discriminatory
decisions is one of the most important ‘take-home’ messages I can offer!
Gunnar von Heijne in his old but incredibly readable treatise, Sequence
Analysis in Molecular Biology; Treasure Trove or Trivial Pursuit (1987),
provides a very appropriate conclusion:
“Think about what you’re doing; use your knowledge of the molecular
system involved to guide both your interpretation of results and your
direction of inquiry; use as much information as possible; and do not
blindly accept everything the computer offers you.”
“. . . if any lesson is to be drawn . . . it surely is that to be able to make
a useful contribution one must first and foremost be a biologist, and
only second a theoretician . . . . We have to develop better algorithms,
we have to find ways to cope with the massive amounts of data, and
above all we have to become better biologists. But that’s all it takes.”
Some key references
Altschul, S. F., Gish, W., Miller, W., Myers, E. W., and Lipman, D. J. (1990) Basic Local Alignment Tool. Journal of Molecular Biology 215, 403-410.
Altschul, S.F., Madden, T.L., Schaffer, A.A., Zhang, J., Zhang, Z., Miller, W., and Lipman, D.J. (1997) Gapped BLAST and PSI-BLAST: a New
Generation of Protein Database Search Programs. Nucleic Acids Research 25, 3389-3402.
Bailey, T.L. and Elkan, C., (1994) Fitting a mixture model by expectation maximization to discover motifs in biopolymers, in Proceedings of the
Second International Conference on Intelligent Systems for Molecular Biology, AAAI Press, Menlo Park, California, U.S.A. pp. 28–36.
Bairoch A. (1992) PROSITE: A Dictionary of Sites and Patterns in Proteins. Nucleic Acids Research 20, 2013-2018.
Eddy, S.R. (1996) Hidden Markov models. Current Opinion in Structural Biology 6, 361–365.
Eddy, S.R. (1998) Profile hidden Markov models. Bioinformatics 14, 755--763
Felsenstein, J. (1993) PHYLIP (Phylogeny Inference Package) version 3.5c. Distributed by the author. Dept. of Genetics, University of Washington,
Seattle, Washington, U.S.A.
Feng, D.F. and Doolittle, R. F. (1987) Progressive sequence alignment as a prerequisite to correct phylogenetic trees. Journal of Molecular Evolution
25, 351–360 .
Genetics Computer Group (GCG) (Copyright 1982-2008) Program Manual for the Wisconsin Package, Version 11., Accelrys, Inc. A Pharmocopeia
Company, San Diego, California, U.S.A.
Gilbert, D.G. (1993 [C release] and 1999 [Java release]) ReadSeq, public domain software distributed by the author.
http://iubio.bio.indiana.edu/soft/molbio/readseq/ Bioinformatics Group, Biology Department, Indiana University, Bloomington, Indiana,U.S.A.
Gribskov, M. and Devereux, J., editors (1992) Sequence Analysis Primer. W.H. Freeman and Company, New York, New York, U.S.A.
Gribskov M., McLachlan M., Eisenberg D. (1987) Profile analysis: detection of distantly related proteins. Proc. Natl. Acad. Sci. U.S.A. 84, 4355-4358.
Gupta, S.K., Kececioglu, J.D., and Schaffer, A.A. (1995) Improving the practical space and time efficiency of the shortest-paths approach to sum-ofpairs multiple sequence alignment. Journal of Computational Biology 2, 459–472.
Henikoff, S. and Henikoff, J.G. (1992) Amino Acid Substitution Matrices from Protein Blocks. Proceedings of the National Academy of Sciences
U.S.A. 89, 10915-10919.
Needleman, S.B. and Wunsch, C.D. (1970) A General Method Applicable to the Search for Similarities in the Amino Acid Sequence of Two Proteins.
Journal of Molecular Biology 48, 443-453.
Pearson, W.R. and Lipman, D.J. (1988) Improved Tools for Biological Sequence Analysis. Proceedings of the National Academy of Sciences U.S.A.
85, 2444-2448.
Schwartz, R.M. and Dayhoff, M.O. (1979) Matrices for Detecting Distant Relationships. In Atlas of Protein Sequences and Structure, (M.O. Dayhoff
editor) 5, Suppl. 3, 353-358, National Biomedical Research Foundation, Washington D.C., U.S.A.
Smith, R.F. and Smith, T.F. (1992) Pattern-induced multi-sequence alignment (PIMA) algorithm employing secondary structure-dependent gap
penalties for comparative protein modelling. Protein Engineering 5, 35–41.
Smith, T.F. and Waterman, M.S. (1981) Comparison of Bio-Sequences. Advances in Applied Mathematics 2, 482-489.
Swofford, D.L., PAUP* (Phylogenetic Analysis Using Parsimony and other methods) version 4.0+ (1989–2007) Florida State University, Tallahassee,
Florida, U.S.A. http://paup.csit.fsu.edu/ distributed through Sinaeur Associates, Inc. http://www.sinauer.com/ Sunderland, Massachusetts, U.S.A.
Thompson, J.D., Gibson, T.J., Plewniak, F., Jeanmougin, F. and Higgins, D.G. (1997) The ClustalX windows interface: flexible strategies for multiple
sequence alignment aided by quality analysis tools. Nucleic Acids Research 24, 4876–4882.
Thompson, J.D., Higgins, D.G. and Gibson, T.J. (1994) CLUSTALW: improving the sensitivity of progressive multiple sequence alignment through
sequence weighting, positions-specific gap penalties and weight matrix choice. Nucleic Acids Research, 22, 4673-4680.
von Heijne, G. (1987) Sequence Analysis in Molecular Biology; Treasure Trove or Trivial Pursuit. Academic Press, Inc., San Diego, CA.
Wilbur, W.J. and Lipman, D.J. (1983) Rapid Similarity Searches of Nucleic Acid and Protein Data Banks. Proceedings of the National Academy of
Sciences U.S.A. 80, 726-730.