Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
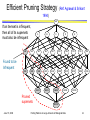
Association Analysis for Finding Patterns in Large Amounts of Biological Data Vipin Kumar William Norris Professor and Head, Department of Computer Science [email protected] www.cs.umn.edu/~kumar Association Analysis • Given a set of records, find dependency rules which will predict occurrence of an item based on occurrences of other items in the record Rules Discovered: TID Items 1 Bread, Coke, Milk 2 3 4 5 Beer, Bread Beer, Coke, Diaper, Milk Beer, Bread, Diaper, Milk Coke, Diaper, Milk • Applications {Milk} --> {Coke} (s=0.6, c=0.75) {Diaper, Milk} --> {Beer} (s=0.4, c=0.67) Support, s # transacti ons that contain X and Y Total transacti ons # transacti ons that contain X and Y X Confidence , c – Marketing and Sales Promotion # transacti ons that contain – Supermarket shelf management – Traffic pattern analysis (e.g., rules such as "high congestion on Intersection 58 implies high accident rates for left turning traffic") June 15, 2006 Finding Patterns in Large Amounts of Biological Data ‹#› Association Rule Mining Task • Given a set of transactions T, the goal of association rule mining is to find all rules having – support ≥ minsup threshold – confidence ≥ minconf threshold • Brute-force approach: Two Steps – Frequent Itemset Generation • Generate all itemsets whose support minsup – Rule Generation • Generate high confidence rules from each frequent itemset, where each rule is a binary partitioning of a frequent itemset • Frequent itemset generation is computationally expensive June 15, 2006 Finding Patterns in Large Amounts of Biological Data ‹#› Efficient Pruning Strategy (Ref: Agrawal & Srikant 1994) null If an itemset is infrequent, then all of its supersets must also be infrequent A B C D E AB AC AD AE BC BD BE CD CE DE ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE Found to be Infrequent ABCD Pruned supersets June 15, 2006 ABCE ABDE ACDE BCDE ABCDE Finding Patterns in Large Amounts of Biological Data ‹#› Illustrating Apriori Principle Item Bread Coke Milk Beer Diaper Eggs Count 4 2 4 3 4 1 Items (1-itemsets) Itemset {Bread,Milk} {Bread,Beer} {Bread,Diaper} {Milk,Beer} {Milk,Diaper} {Beer,Diaper} Minimum Support = 3 Pairs (2-itemsets) (No need to generate candidates involving Coke or Eggs) Triplets (3-itemsets) If every subset is considered, 6C + 6C + 6C = 41 1 2 3 With support-based pruning, 6 + 6 + 1 = 13 June 15, 2006 Count 3 2 3 2 3 3 Itemset {Bread,Milk,Diaper} Finding Patterns in Large Amounts of Biological Data Count 3 ‹#› Counting Candidates • • Frequent Itemsets are found by counting candidates. Simple way: – Search for each candidate in each transaction. Expensive!!! Candidates Count Transactions ABCD ACE BCD N ABDE BCE BD June 15, 2006 AB 0 1 2 Naïve approach AC 1 2 0 requires O(NM) A D 1 2 AD 0 comparisons A 0 1 2 AE E 0 BC 1 3 BC 0 Reduce the number BD 1 4 M BD 0 of comparisons ABE 0 2 (NM) by using hash ABE 0 BCD 1 2 tables to store the BCD 0 ABDE 0 1 candidate itemsets 0 AABBCDDEE 0 A inBLarge C DAmounts E Finding Patterns of0Biological Data ‹#› How many roles can these play? How flexible and adaptable are they mechanically? What are the shared parts (bolt, nut, washer, spring, bearing), unique parts (cogs, levers)? What are the common parts - types of parts (nuts & washers)? Where are the parts located? Which parts interact? © Mark Gerstein, Yale Association Analysis for Finding Connections of Disease and Medical and Genomic Characteristics • Create a data set that records the presence and absence of – Phenotypic characteristics – Genetic characteristics (SNPs) – Disease • Apply association analysis to find groups of phenotypic and genetic characteristics that are highly associated with disease – Uses characteristics of the patterns to prune the search space • Clustering and classification can also be applied June 15, 2006 Finding Patterns in Large Amounts of Biological Data ‹#› The Need for Error-Tolerant Itemsets • An error-tolerant itemset (ETI) can have a fraction of the items missing in each transaction. Example: see the data in the table – Let = 1/4. In other words, each transaction needs to have 3/4 (75%) of the items. – X = {i1, i2, i3, i4} and Y = {i5, i6, i7, i8} are both ETIs with a support of 4. • Algorithms to find ETIs are still in development • You can think of these ETIs as blocks in the data matrix June 15, 2006 Finding Patterns in Large Amounts of Biological Data ‹#› ETIs in For Finding Patterns in Phenotypic and Genomic Data • ETIs consist of – A set of patients and – A set of attributes such that – The block is relatively dense • These blocks identify sets of patients that are highly associated with certain sets of attributes and vice-versa • If most of these patients share a disease, then these attributes (genetic and/or phenotypic) are candidate markers for the disease June 15, 2006 X: Set of patients Y: Set of attributes, i.e., SNPs, medical characteristics Finding Patterns in Large Amounts of Biological Data ‹#›