Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
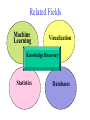
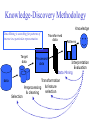
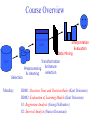
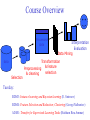
Knowledge Discovery and Data Mining Evgueni Smirnov Outline • Data Flood • Definition of Knowledge Discovery and Data Mining • Possible Tasks: – Classification Task – Regression Task – Clustering Task – Association-Rule Task Data Flood Trends Leading to Data Flood • Moore’s law – Computer Speed doubles every 18 months • Storage law – total storage doubles every 9 months As a result: • More data is captured: – Storage technology faster and cheaper – DBMS capable of handling bigger DB Trends Leading to Data Flood • More data is generated: – Business: • • • • Supermarket chains Banks, Telecoms, E-commerce, etc. – Web – Science: • • • • astronomy, physics, biology, medicine etc. Consequence • Very little data will ever be looked at by a human, and thus, we need to automate the process of Knowledge Discovery to make sense and use of data. Definition of Knowledge Discovery • Knowledge Discovery in Data is non-trivial process of identifying – – – – valid novel potentially useful and ultimately understandable patterns in data. • from Advances in Knowledge Discovery and Data Mining, Fayyad, Piatetsky-Shapiro, Smyth, and Uthurusamy, (Chapter 1), AAAI/MIT Press 1996. Related Fields Machine Learning Visualization Knowledge Discovery Statistics Databases Knowledge-Discovery Methodology Knowledge Data Mining is searching for patterns of interest in a particular representation. Target data data Selection Processed data Transformed data Patterns Interpretation Evaluation Data Mining Transformation Preprocessing & feature selection & cleaning Data-Mining Tasks • • • • Classification Task Regression Task Clustering Task Association-Rule Task Classification Task • Given: a collection of instances (training set) – Each instances is represented by a set of attributes, one of the attributes is the class attribute. • Find: a classifier for the class attribute as a function of the values of other attributes. • Goal: previously unseen instances should be assigned a class as accurately as possible. Example 1 Tid Refund Marital Status Taxable Income Cheat Refund Marital Status Taxable Income Cheat 1 Yes Single 125K No No Single 75K ? 2 No Married 100K No Yes Married 50K ? 3 No Single 70K No No Married 150K ? 4 Yes Married 120K No Yes Divorced 90K ? 5 No Divorced 95K Yes No Single 40K ? 6 No Married No No Married 80K ? 60K 10 7 Yes Divorced 220K No 8 No Single 85K Yes 9 No Married 75K No 10 10 No Single 90K Yes Training Set Learn Classifier Test Set Classifier Example 2 • Fraud Detection – Goal: Predict fraudulent cases in credit card transactions. – Approach: • Use credit card transactions and the information on its account-holder as attributes. – When does a customer buy, what does he buy, how often he pays on time, etc • Label past transactions as fraud or fair transactions. This forms the class attribute. • Learn a model for the class of the transactions. • Use this model to detect fraud by observing credit card transactions on an account. Regression Task • Predict a value of a given continuous valued variable based on the values of other variables, assuming a linear or nonlinear model of dependency. Examples: • Predicting sales amounts of new product based on advertising expenditure. • Predicting wind velocities as a function of temperature, humidity, air pressure, etc. • Time series prediction of stock market indices. Clustering Task • Given a set of data points, each having a set of attributes, and a similarity measure among them, find clusters such that: – Data points in one cluster are more similar; – Data points in separate clusters are less similar. Intra-cluster distances are minimized Inter-cluster distances are maximized Example • Market Segmentation: – Goal: subdivide a market into distinct subsets of customers where any subset may conceivably be selected as a market target to be reached with a distinct marketing mix. – Approach: • Collect different attributes of customers based on their geographical and lifestyle related information. • Find clusters of similar customers. • Measure the clustering quality by observing buying patterns of customers in same cluster vs. those from different clusters. Association-Rule Task • Given a set of records each of which contain some number of items from a given collection; – Produce dependency rules which will predict occurrence of an item based on occurrences of other items. TID Items 1 2 3 4 5 Bread, Coke, Milk Beer, Bread Beer, Coke, Diaper, Milk Beer, Bread, Diaper, Milk Coke, Diaper, Milk Rules Discovered: Milk --> Coke Diaper, Milk --> Beer Example • Supermarket shelf management. – Goal: To identify items that are bought together by sufficiently many customers. – Approach: Process the point-of-sale data collected with barcode scanners to find dependencies among items. – A classic rule -• If a customer buys diaper and milk, then he is very likely to buy beer. • So, don’t be surprised if you find six-packs stacked next to diapers! Course Overview Processed data data Selection Monday: Interpretation Evaluation Data Mining Transformation Preprocessing & feature selection & cleaning BDM1: Decision Trees and Decision Rules (Kurt Driessens) BDM2: Evaluation of Learning Models (Kurt Driessens) S1: Regression Analysis (Georgi Nalbantov) S2: Survival Analysis (Nasser Davarzani) Course Overview Processed data data Selection Interpretation Evaluation Data Mining Transformation Preprocessing & feature selection & cleaning Tuesday: BDM3: Instance learning and Bayesian learning (E. Smirnov) BDM4: Feature Selection and Reduction; Clustering (Georgi Nalbantov) ADM1: Transfer for Supervised-Learning Tasks (Haitham Bou Ammar) Course Overview Processed data data Selection Interpretation Evaluation Data Mining Transformation Preprocessing & feature selection & cleaning Wednesday : BDM5: Association Rules (E. Smirnov) ADM2: Ensemble Methods (E. Smirnov)