Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Lecture 10
FMM CMSC 878R/AMSC 698R
• SLFMM: S and R-expansions, S|R translation (O(N4/3))
• MLFMM: S and R-expansions, S|S, S|R and R|R
translations (O(N log N))
– Factorizations in terms of near or far-field functions
– O(N3/2) for optimal number of boxes
– Need boxes to organize source or target sets, and manage those
pairs that require direct summation
• Pre-FMM: S-expansions and R-expansions (O(N3/2))
– Factorization needed, no data-structure
– Factorization not always available
• Middleman: Degenerate Factorizations (O(N))
– No data structures
• Direct (O(N2))
Progression
Total number of operations: O(NM)
N
M
N
Total number of operations: O(N+M)
M
Standard algorithm
Middleman algorithm
Evaluation
Evaluation
Points
Points
Sources
Sources
Middleman Algorithm
Total number of operations: O(NM)
N
M
Total number of operations: O(N+M+KL)
M N
K groups
Standard algorithm
SLFMM
Evaluation
Evaluation
Points
Sources
Sources L groups Points
Idea of a Single Level FMM
• Expansions can be valid in domains smaller than the
computational domain.
• Even though expansion can be valid everywhere, the
truncation number can be huge for large domains to
provide accuracy.
• Sources and evaluation points can be spatially close,
and there is a problem to evaluate singular potentials.
• Important theoretical question: determining optimal
number of groups automatically
Why do we need SLFMM if Middleman
has smaller complexity?
Ε1
n
n
Ε3
Φ3(n)(y)
n
I3(n) = {All boxes}\ I2(n)
I2(n) = {Neighbors(n)}∪ n
Ε2
Φ2(n)(y)
Boxes with these numbers belong to these spatial domains
I1(n) = n
Φ1(n)(y)
Potentials due to sources in these spatial domains
Spatial Domains
Definition of potentials
C(n) = 0;
loop over all sources in the box
For xi ∈ E1(n)
Get B (xi, xc(n)) , the S-expansion coefficients
near the center of the box;
C(n) = C(n) + uiB (xi, xc(n));
End;
End;
Implementation can be different!
All we need is to get C(n).
For n ∈ NonEmptySource
Get xc(n) , the center of the box;
loop over all non-empty source boxes
Step 1. Generate S-expansion coefficients
for each box
SLFMM Algorithm
End;
End;
Implementation can be different!
All we need is to get D(n).
Get xc(m) , the center of the box;
D(n) = D(n) + (S|R)(xc(n)- xc(m)) C(m) ;
3
For n ∈ NonEmptyEvaluation
Get xc(n) , the center of the box;
D(n) = 0;
loop over all non-empty source boxes
outside the neighborhood of the n-th box
For m ∈ I (n)
loop over all non-empty
evaluation boxes
Step 2. (S|R)-translate expansion coefficients
SLFMM Algorithm
S|R-translation
loop over all boxes
containing evaluation points
End;
End;
End;
Implementation can be different!
All we need is to get vj
For n ∈ NonEmptyEvaluation
Get xc(n) , the center of the box;
For yj ∈ E1(n)
loop over all evaluation points in the box
vj = D(n) R(yj - xc(n)) ;
loop over all sources in the
For xi ∈ E2(n)
neighborhood of the n-th box
vj = vj +Φ(yj , xi);
ui
Step 3. Final Summation
SLFMM Algorithm
• Translation is performed by straightforward P×P matrix-vector
multiplication, where P(p) is the total length of the translation
vector. So the complexity of a single translation is O(P2).
• The source and evaluation points are distributed uniformly, and
there are K boxes, with s source points in each box (s=N/K). We
call s the grouping (or clustering) parameter.
• The number of neighbors for each box is O(1).
– Assume that cost of finding these is less than the most expensive operation
– Magic will come from data-structures
• By some magic we can easily find neighbors, and lists of points in
each box.
Asymptotic Complexity of SLFMM
•
•
•
•
For Step 1:
O(PN)
For Step 2:
O(P2K2)
For Step 3:
O(PM+Ms)
Total:
O(PN+ P2K2 +PM+Ms) =
O(PN+ P2K2 +PM+MN/K)
Then Complexity is:
0
Kopt
F(K)
Selection of Optimal K (or s)
Κ
Complexity of Optimized SLFMM
•
•
•
•
– Consolidate S series from all xi in the cluster
– For each evaluation box find clusters that are outside min. radius
at which S expansion converges. Translate S series to R series
– Evaluate R series at the evaluation points
– Clean-up by evaluating at points which are inside min. radius
Find the cluster center (x*) for each cluster
Find distances from cluster center to points in cluster
Find distances between clusters
Build a S representation for points in each source cluster
Φ(xi, y) = ∑m=1p bm(xi,x*) Sm (y-x*)
– Group evaluation points into clusters
• Group source points into clusters
SLFMM Characteristics
– Hierarchical grouping, center finding
– Finding parents, children, siblings
– Finding neighbors
Space division and grouping of points
Center finding for groups
Distance between points (group centers)
Neighbor finding
Hierarchical division in FMM adds
• Spatial data-structures
• Also, the structures used to store these relationships
require memory
• Determine optimal parameters and “break-even” point
•
•
•
•
•
Algorithms needed
• Next class …
– Use asymptotically optimal algorithms for performing
operations on them
• For effective “generalization” we need to use state-of-theart spatial data structures
• Optimal data structures for FMM is an open research area
• In this course we will mostly use hierarchical division
into boxes using 2d trees
– So don’t use the latest spatial data structure algorithms
• FMM developed over the same period
– Aside: one of the founders of the field (Hanan Samet) is local
• Spatial data structures have developed since late 1980s,
Spatial Data Structures
• Use bit interleaving and bit shift
• Apply to the general d- dimensional case
• Storage is also minimized as most necessary relations are
directly generated from point coordinates
– number the boxes in a way that can be generated from the
coordinate
– assign points to boxes using their binary coordinates
– find box centers
– Find neighboring boxes
• Constant time methods to
Summary of formal requirements for
functions that can be used in FMM
Summary of formal requirements for
functions that can be used in FMM (2)
F(Ω)
F
Representation of a Linear Operator
F(Ω’)
A(Ω)
A(Ω’)
Matrix Representation of Linear Operators
F(Ω)
Fp(Ω)
A(Ω)
Pr(p)
Rp(Ω)
p-Truncation (Projection) Operator
y+t
t
y
Translation Operator
– Φ(xi,y)
– ∑m bm(xi,x*1) Sm(y-x*)
– ∑m am(xi,x*2) Rm(y-x*2) with am= T bm
• Take a function or equivalently a function expressed as a
series expansion and express it in another coordinate
system (reference frame)
• Function is the same on the common parts of domains of
definition
• but is represented in different forms
Translation (Passive view point)
• In a fixed coordinate system move the vector (or
function), and evaluate it at the same point
• Φ(xi,y) → Φ(xi+t,y)
• Functions evaluated at the same point are not the same
• Operator transforms the reference frame
Translation (Active view point)
R|R-reexpansion
Example of R|R-reexpansion
R|R-translation operator
The second letter
shows the basis
for Φ(y +t)
Needed only to show the expansion basis
(for operator representation)
The first letter shows
the basis for Φ(y)
Different translation operators
Consider
Matrix representation of
R|R-translation operator
Coefficients of
original function
Coefficients of
shifted function
We have:
Reexpansion of the same function
over shifted basis
x **1
t
2
Ω1
r1
x*x+t*2
(R|R)
Ωr(x*)
R
x
y
R
Ωr1(x*+t)
Ω
r
Since Ωr1(x*+t) ⊂ Ωr(t) !
|y - x* - t| < r 1 = r - |t|
Original expansion
Is valid only here!
R|R-reexpansion of the same
function over shifted basis (2)
Example of power series
reexpansion
Check for Al
For Al we
obtained Taylor
series for the l-th
derivative!
For A0 this yields Taylor series again!
Let’s check this for Taylor series, when expansion coefficients are
Example of power series reexpansion (2).
Relation to Taylor series.
S|S-reexpansion
S|S-translation operator
S|R-translation operator
(t cannot be zero)
S|R-operator has almost the same
properties as S|S and R|R
xi
x*2
r
(S|S)
S
Ω1
x**1
(S|R)
S t
x*+t r1
Ωr1(x*+t)
y
Ωr(x*)
|xi - x* | < r
singular point !
Also
Since
Ωr1(x*+t) ⊂ Ωr(t) !
|y - x* - t| < r 1 = |t| - r
Original expansion
Is valid only here!
Picture is different…
S-expansion
R-expansion
S
x*
R
Example from previous lectures
xi
In this case we have
•
•
•
•
•
Factorization
Error
Translation
Grouping
Data Structure
Five Key Stones of FMM
Definitions:
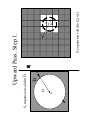
Upward Pass: Going Up on SOURCE Hierarchy
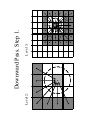
Downward Pass: Going Down on EVALUATION Hierarchy
Complexity of MLFMM
Summary of requirements for functions
that can be used in FMM
Summary of requirements for functions
that can be used in FMM (2)
If iterative or multiple solutions of the same system are
required, the MLFMM Constructor should be called
only once.
• MLFMM Solver O(N+M) or O(NlogqN+MlogqM),
Will evaluate the complexity in more details later.
• Setting Hierarchical Data Structure
(MLFMM Constructor) O(NlogN+MlogM)
Two Parts of the MLFMM
• Scale source and evaluation data to have the computational
domain of size of a unit box.
• Sort data (spatially order data) using bit interleaving
technique (Next week)
• Determine the level of space subdivision with 2d-tree to have
s sources at the finest subdivision level, Lmax (Next week)
• If you choose to spend memory for trees, neighbor lists, and
so on, compute and store information that does not change in
the process of execution of the MLFMM solver.
Setting Hierarchical Data Structure
Level 0
Level 1
Level 2
Level 3
Child Child
Self
Neighbor
Neighbor Neighbor Neighbor
(Sibling)
Child Child
Parent
Neighbor
Neighbor Neighbor
Neighbor
(Sibling) (Sibling)
Hierarchy in 2d-tree
3
2
1
0
Parent
Children
Self
22-tree (quad)
Maybe
Neighbor
2-tree (binary)
Neighbor
(Sibling)
Level
2d-trees
2d-tree
23d
22d
2d
Number
of Boxes
1
• We assign to each box on level l some number (index) n;
Global index of any box is (n,l).
• We assume that functions, such as Parent(n), ChildrenAll(n),
Children(X;n,l), NeighborsAll(n,l), Neighbors(X;n,l), for given
d-dimensional data set, X, are available
•(will consider their implementation next week).
•These functions return sets of indexes of boxes at proper
levels which are relatives (or neighbors) to the given box
(n,l).
• We drop X in many cases, to have shorter notation.
Hierarchical Indexing and Functions
Ε2
Ε4
Ε1
Ε3
Hierarchical Spatial Domains
Ε1
Ε2
Ε3
Ε4
Hierarchical
Spatial Domains
0.5a√d
In fact, we will show later that
1-neighborhoods can be used only
for dimensions d < 4.
a
1.5a
For larger dimensions larger
neighborhoods could be
considered
However all issues have to
be reconsidered … not
practical to use 2d-trees in
this case
0.5a√d < 1.5a,
√d < 3,
d < 9.
With Such Neighborhood
the dimensionality of space
in FMM cannot exceed d=9.
Ε2
Ε4
Ε1
Ε3
Hierarchical Potentials (Functions)
– Upward Pass;
– Downward Pass;
– Final Summation;
• ``Build Function” or ``Build Potential” means find its
expansion coefficients over some basis;
• The MLFMM Algorithm consists of
The MLFMM Algorithm (Solver)
Upward Pass. Step 1.
xi
x*
R
Ω
Ω
S-expansion valid in Ω
y
Ε3
xc(n,L)
xi
S-expansion valid in E3(n,L)
y
Upward Pass. Step 1.
Upward Pass. Step 2.
S|S-translation.
Build potential for the parent box (find its S-expansion).
Upward Pass. Step 2.
In the entire hierarchy of boxes containing sources
S-expansion coefficients for potentials due to
sources in each box (domains E1) are found.
Expansions are valid in E3 domains.
Result of the Upward Pass
Note that this is conversion from the Source Hierarchy to
Evaluation Hierarchy!
Downward Pass. Step 1.
Level 2:
Level 3:
Downward Pass. Step 1.
THIS IS USUALLY THE
MOST EXPENSIVE STEP OF
THE ALGORITHM
Downward Pass. Step 1.
Exponential
Growth
It is worth to think about optimizations
(far from the domain boundaries)
Total number of S|R-translations
per 1 box in d-dimensional space
Downward Pass. Step 1.
Downward Pass. Step 2.
Downward Pass. Step 2.
In the entire hierarchy of boxes containing
evaluation points R-expansion coefficients for
potentials due to sources outside each evaluation
point neighborhood (domains E3) are found.
Expansions are valid in E1 domains.
Result of the Downward Pass
Contribution of E2
yj
Contribution of E3
Final Summation