Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
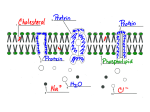
WEEK #20: Probabilistic Models, Diffusion and Genetics Goals: Textbook reading for Week #20: Study Adler Section 6.1, 6.2. Course Information For the rest of the course, we will be working with fundamental ideas in probability, and how they relate to biological models, as well as to our earlier work with calculus. The textbook references for the remaining material comes from the original course text, “Modeling the Dynamics of Life” by Adler, Chapters 6, 7, and 8. Introduction To Probabilistic Models From Section 6.1 Contrast the underlying assumptions of deterministic vs stochastic models. Give two examples of deterministic population models, one with discrete time, and one with continuous time. Example: A discrete-time stochastic population model could be defined by the following statements: • 60% chance a population will have a per capita production of 1.2 in a given year, • 20% chance that the production rate will be 1.0 per capita (population remains the same), and • 20% chance that the production rate will be 1.4 per capita. What do you think the average per capita production rate will be under this model? Simulation For the purposes of comparison, let us define two models, one stochastic. 1.2Pt 60% Pt+1 = 1.2Pt Pt+1 = 1.0Pt 20% 1.4P 20% t deterministic and one chance chance chance If we start both models at an initial population of P0 = 1000, can we predict exactly when each model will reach P = 150, 000? For the stochastic or probabilistic model, there is an element of chance to the future predictions about population. In an era of inexpensive computing, an easy way to explore the predictions of a model are to simulate them. We program a computer to simulate a random number being drawn, choose a population rate as a result of the number, and then update the population according to that randomly-selected rate. Repeating this work over and over, we can predict the population curve several times to understand the possible range of behaviour in the model. 0 5 10 15 Years 20 25 0 100000 200000 + + + + + + + + ++ ++ + + + + ++++++++++++++ 30 + + Pop. 100000 200000 0 Pop. + + + + + ++ + + + + + ++ + + + ++++ + + + ++ + + +++ ++ ++ ++ +++ + + ++ + + + ++ + + + + ++ ++ ++++ +++ ++++ +++++ +++ 0 5 10 15 Years 20 25 30 What would be some stochastic alternatives to the deterministic question “At what time does the population reach 150,000”? What other questions might be relevant, given the stochastic population model? One way to help answer some of the questions about a model’s predictions is to use the simulation approach to generate a large number of predicted populations, and then display the range and popularity of various outcomes using a histogram. 0 5000 15000 First Year The Population Exceeded 150,000 Freq (out of 100,000) 30000 10000 0 Freq (out of 100,000) Population at Year 30 0 500000 1500000 Population 20 25 30 35 40 Cross Year Which of our earlier questions can be answered based on these histograms? 45 As we will see several times in our study of probability, the logarithm transform is an important tool. Consider the range of year 30 populations we simulated earlier. The histogram had an odd, asymmetric shape to it. Compare that to the histogram of the log transformed populations (log base 10): 0 5000 10000 Population at Year 30 Freq (out of 100,000) 30000 10000 0 Freq (out of 100,000) Population at Year 30 0 500000 1500000 Population 4.5 5.0 5.5 6.0 6.5 Log10(Population) On the graph, indicate the original units of the logged populations shown. Use the histogram to determine (roughly) the average or expected population at year 30. Markov Chains An exciting development in modeling tools for biologists and geneticists in the last 20 years are Markov Chains or Markov Models. They were studied heavily in the 1960s, and starting in 1989 they were used to identify different region types in DNA, RNA, and protein sequences; today they are used to mine the ever-growing genetic databases for alignments of DNA and RNA sequences across different organisms for evolutionary comparison, and to identify common protein sequence and structure motifs for drug development. Markov chains have also been used in fields of synthetic music generation and authorship identification, speech recognition and generation, and other sequence classification tasks.1 In eukaryotes, we have long regions of so-called “junk”, or non-coding, DNA. These sequences are not entirely random, however: certain bases are more likely than other, and certain short subsequences are more likely than others. If we consider a simple two-base DNA universe to start with, one way to model these sequences is with a state diagram like the one shown below: Here are some sample sequences from that model A A A A A A G A G A A A G A G A A G A A A A A A A A G A A A ... G G A A A G A G A A G A G A G A G A A A A A A G A G A A G A ... G A A A G A A A G A A A A G A A A A G A A A A A G A A G G A ... A A G A A A G A G G G G A G G G A A A A A A G G A A G A G G ... 1 Typically, these applications are actually using Hidden Markov Models, or HMMs. HMMs models are a relatively simple extension of the Markov chains we will study in this course. http://www.comp.leeds.ac.uk/roger/HiddenMarkovModels/html dev/main.html http://www.research.ibm.com/journal/rd/453/birney.html Question: Which of the following sequences is not likely to have come from this model? A) G A G A A G G A G G G G A G G G A G G A A G G G G G G A A G ... B) A A G G G G G G G A A G G A A G A G G G G G A A A A A G G G ... C) G A A A A G G G A G A G A G G G A G A G G A A G A A G A A A ... D) A G A G A G G A G G A A A A A G A G A G A A A A A G A G G A ... E) A A G A A A G A G A G G A G G A G G G A G A A G A A A A A G ... How sure can you be of your answer? Stochastic Models of Diffusion From Section 6.2 Diffusion is something we have studied in both discrete and continuous time, but in a deterministic way. In fact, chemists and physicists would argue that diffusion is more accurately a random or stochastic process, because individual molecules pass through the membrane based on collision angles, energy levels, steady and transient polar charge forces, etc. Sketch: However, we can still keep an eye on the process from a macroscopic level, by measuring concentrations on both sides of the membrane. Example: By repeated experiments we find that, on average, the concentration of a toxin inside a membrane drops by 20% per hour. Draw a digram for a stochastic model for an individual toxin molecule over time. We now define pt = probability that the molecule is inside the membrane at time t (hours). If we assume that the molecule is inside the membrane initially, write the next few values for pt , and then a general formula. What kind of equation is this? How does it differ from similar models we have seen before? The discrete time models we have seen before are related to these stochastic ones. In this case, they are associated by expectation. Question: After 2 hours, we have p2 = 0.64. This means that at t = 2, A) there is a 64% chance of a particular molecule still being inside the membrane. B) exactly 64% of all the molecules we started with will still be inside the membrane C) approximately 64% of all the molecules we started with will still be inside the membrane D) There is a 64% chance that all of the molecules will still be inside the membrane Effects of Sample Size Consider the following simulation graphs. 10 15 20 4 3 2 0 1 # Molec. Inside 3 2 0 5 0 5 10 15 20 0 5 10 15 20 Simulation of 40 molecules Simulation of 40 molecules Simulation of 40 molecules 0 5 10 15 20 30 20 0 10 # Molec. Inside 30 20 # Molec. Inside 0 10 30 20 10 40 t 40 t 40 t 0 0 5 10 15 20 0 5 10 15 20 t t Simulation of 400 molecules Simulation of 400 molecules Simulation of 400 molecules 0 5 10 t 15 20 400 300 200 100 # Molec. Inside 300 200 0 0 0 100 200 # Molec. Inside 300 400 400 t 100 # Molec. Inside 1 # Molec. Inside 3 2 1 # Molec. Inside 0 0 # Molec. Inside Simulation of 4 molecules 4 Simulation of 4 molecules 4 Simulation of 4 molecules 0 5 10 t 15 20 0 5 10 15 20 t What graph you think we’re approaching as we increase the number of molecules in our simulation? Here are similar simulations, but with the function p(t) = p0 (0.8)t overlayed for comparison. 5 10 t 15 20 600 # Molec. Inside 0 0 0 200 80 60 40 # Molec. Inside 20 10 8 6 4 2 0 # Molec. Inside Simulation of 1000 molecules 1000 Simulation of 100 molecules 100 Simulation of 10 molecules 0 5 10 t 15 20 0 5 10 15 20 t We can also view these simulations in tabular form. The values shown here are the same as those used to generate the graphs above. t 0 1 2 3 4 5 6 7 8 9 10 11 t pt = 0.8 1.000 0.800 0.640 0.512 0.409 0.327 0.262 0.209 0.167 0.134 0.107 0.08 Sim N0 = 10 10 9 8 7 7 6 4 3 2 1 0 0 Sim N0 = 100 100 77 69 52 36 26 22 17 17 17 12 11 Sim N0 = 1000 1000 805 641 522 401 310 238 191 151 120 92 74 You should note that the values of the simulations do not get closer to the expected values as we use more molecules. e.g. at t = 6, the individual simulations were off by 1, 3, and 18 molecules respectively for N0 = 10, 100, and 1000. Why then does the graph for N0 = 1000 look so much closer to the ideal curve than the smaller sample simulations? If there are billions of molecules in a sample, what are the trade-offs of using a deterministic model instead of a stochastic model for diffusion? Give an example of a scenario or experiment where a deterministic model for diffusion would not be appropriate. Markov Chain Model for Diffusion So far we have only modeled one-way flow through the membrane. However, our earlier studies covered the more realistic case of two-way flow through the membrane. We can construct a stochastic model for this using a Markov chain. Describe the assumptions in this model in words. The original scenario, where the molecules could only leave the membrane, can also be written as a Markov chain. Sketch the transition diagram for our original model. Using the leave-and-enter model, assume a single molecule starts inside the membrane. Compute the probability that it is in the membrane for the next few time points. Find the general formula for pt+1 , the probability that an individual molecule with be inside the membrane at time t + 1. It will depend on pt . Find the long-term probability that an individual molecule will be inside the cell. Here are some simulations, showing both the ideal number of molecules and simulated number, for different numbers of initial molecules. Note the long-term stable level indicated in the graphs. 0 10 20 30 t 40 50 600 0 200 # Molec. Inside 80 60 40 # Molec. Inside 0 20 10 8 6 4 2 0 # Molec. Inside Simulation of 1000 molecules 1000 Simulation of 100 molecules 100 Simulation of 10 molecules 0 10 20 30 t 40 50 0 10 20 30 40 50 t Comment on the agreement between the ideal probabilities and the simulation results. Genetics You should read the presentation of selfing and inbreeding effects, pages 498-500, on your own. The case of self-reproduction or inbreeding is an interesting one, especially on its effects on genetic diversity, but we do not have time to cover it in class. Genetics are a rich source of probabilistic models. To start with, we will explore some simple models applied to plant breeding. Nomenclature • an allele is a variant of a gene. • an organism is diploid if it has two separate copies of a gene • a diploid organism is homozygous if both alleles for a gene are the same, and heterozygous if the alleles are different. • The set of alleles of an organism is its genotype. This is usually not directly measured, but inferred from the visible or macroscopic properties of the organism, its phenotype. The presence of different alleles for a set of genes can affect the phenotype of an organism in a variety of ways. Give some examples of genotype/phenotype relationships. Probability Theory From Section 6.3 It will be helpful, before we go too much further, to define some nomenclature and properties of probabilities and experiments. Sample space for an idealized experiment: Experiment: Measuring the height of a random student in the class. Experiment: Throwing a dart at a wall with a dart board on it. Experiment: Measuring the per-capita reproductive rate for a population over one year. Event in an experiment: Experiment: Measuring the height of a random student in the class. Experiment: Throwing a dart at a wall with a dart board on it. Experiment: Measuring the per-capita reproductive rate for a population over one year. Representing Sample Space and Events Venn diagrams and line graphs are often used to represent the sample space, events, and their interrelationships. Draw a Venn Diagram and line diagram for the annual per-capita reproductive rate experiment, showing the event “population grew”. Add to the diagrams the second event “population grew at a rate r = 0.5 or higher”. Add to the diagrams the third event “population was constant or shrunk.” Nomenclature Define the following terms, then give some examples of each. • Mutually exclusive events • Union of two events • Intersection of two events • Complement of an event • Collectively Exhaustive Set of events Formal Probability Models A probability model assigns probabilities to all events. We will write Pr(A) for the probability of an event A. To be self-consistent, the assigned probabilities must satisfy the following 4 requirements (or “axioms”). For each rule, draw a Venn diagram representing it. 1. If S is the the sample space, Pr(S) = 1. 2. 0 ≤ Pr(A) ≤ 1 for any event A. 3. If A and B are mutually exclusive events, Pr(A ∪ B) = Pr(A) + Pr(B). 4. If Ac is the complement of A, then Pr(Ac ) = 1 − Pr(A). We see now why our earlier models had certain properties. Example: For the diffusion model shown below, describe the sub-experiment that occurs at each step, the sample space for each step, and what constraints there are on the transition probabilities as a result. If we were to run the diffusion model for 10 time steps, how would we define the sample space? Give examples of events we could describe based on the sample space for the 10-step diffusion experiment.