Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
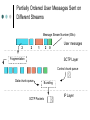
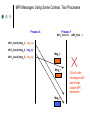
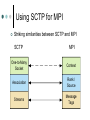
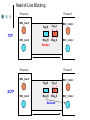
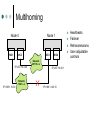
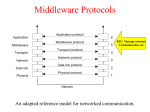
SCTP-based Middleware for MPI Humaira Kamal, Brad Penoff, Alan Wagner Department of Computer Science University of British Columbia What is MPI and SCTP? Message Passing Interface (MPI) Library that is widely used to parallelize scientific and compute-intensive programs Stream Control Transmission Protocol (SCTP) General purpose unicast transport protocol for IP network data communications Recently standardized by IETF Can be used anywhere TCP is used What is MPI and SCTP? Message Passing Interface (MPI) Library that is widely used to parallelize scientific and compute-intensive programs Stream Control Transmission Protocol (SCTP) General purpose unicast transport protocol for IP network data communications Recently standardized by IETF Can be used anywhere TCP is used Question Can we take advantage of SCTP features to better support parallel applications using MPI? Communicating MPI Processes TCP is often used as transport protocol for MPI MPI Process MPI Process MPI Middleware MPI Middleware SCTP TCP SCTP TCP IP IP SCTP Key Features Reliable in-order delivery, flow control, full duplex transfer. SACK is built in the protocol TCP-like congestion control SCTP Key Features Message oriented Use of associations Multihoming Multiple streams within an association Logical View of Multiple Streams in an Association Endpoint X Endpoint Y SEND Outbound Streams Stream 0 RECEIVE Stream 1 Stream 2 SEND RECEIVE Inbound Streams Stream 0 Stream 1 Stream 2 Partially Ordered User Messages Sent on Different Streams Message Stream Number (SNo) 2 2 1 2 0 Fragmentation User messages SCTP Layer Control chunk queue Data chunk queue SCTP Packets Bundling IP Layer MPI Middleware MPI_Send(msg,count,type,dest-rank,tag,context) MPI_Recv(msg,count,type,source-rank,tag,context) Message matching is done based on Tag, Rank and Context (TRC). Combinations such as blocking, non-blocking, synchronous, asynchronous, buffered, unbuffered. Use of wildcards for receive Envelope Context Rank Tag Payload Format of MPI Message MPI Messages Using Same Context, Two Processes Process X MPI_Send(Msg_1,Tag_A) MPI_Send(Msg_2,Tag_B) MPI_Send(Msg_3,Tag_A) Process Y MPI_Irecv(..ANY_TAG..) Msg_1 Msg_2 Msg_3 Process X MPI_Send(Msg_1,Tag_A) Process Y MPI_Irecv(..ANY_TAG..) Msg_1 MPI_Send(Msg_2,Tag_B) MPI_Send(Msg_3,Tag_A) Msg_3 Msg_2 MPI Messages Using Same Context, Two Processes Process X Process Y MPI_Irecv(..ANY_TAG..) MPI_Send(Msg_1,Tag_A) MPI_Send(Msg_2,Tag_B) MPI_Send(Msg_3,Tag_A) Msg_3 Msg_1 Msg_2 Out of order messages with same tags violate MPI semantics MPI Middleware Message Progression Layer Receive Request is Issued Application Layer Receive Request Queue MPI Middleware Runtime Short Messages vs. Long Messages Unexpected Message Queue SCTP Layer Socket Incoming Message is Received Design and Implementation LAM (Local Area Multi-computer) is an open source implementation of MPI library We redesigned LAM-MPI to use SCTP Three-phased iterative process Use of One-to-One Style Sockets Use of Multiple Streams Use of One-to-Many Style Sockets Using SCTP for MPI Striking similarities between SCTP and MPI SCTP MPI One-to-Many Socket Context Association Rank / Source Streams Message Tags Implementation Issues Maintaining State Information Message Demultiplexing Extend RPI initialization to map associations to rank. Demultiplexing of each incoming message to direct it to the proper receive function. Concurrency and SCTP Streams Maintain state appropriately for each request function to work with the one-to-many style. Consistently map MPI tag-rank-context to SCTP streams, maintaining proper MPI semantics. Resource Management Make RPI more message-driven. Eliminate the use of the select() system call, making the implementation more scalable. Eliminating the need to maintain a large number of socket descriptors. Implementation Issues Eliminating Race Conditions Reliability Modify out-of-band daemons and request progression interface (RPI) to use a common transport layer protocol to allow for all components of LAM to multihome successfully. Support for large messages Finding solutions for race conditions due to added concurrency. Use of barrier after association setup phase. Devised a long-message protocol to handle messages larger than socket send buffer. Experiments with different SCTP stacks Features of Design Head-of-Line Blocking Multihoming and Reliability Security Head-of-Line Blocking Process X Process Y MPI_Send TCP MPI_Send Tag_B Tag_A Msg_B Msg_A MPI_Irecv MPI_Irecv Blocked Process X Process Y MPI_Send Tag_B Tag_A Msg_B Msg_A MPI_Irecv SCTP MPI_Send Delivered MPI_Irecv Multihoming Node 0 Node 1 NIC1 NIC2 NIC3 NIC4 Network 207.10.x.x IP=207.10.3.20 IP=168.1.10.30 Network 168.1.x.x IP=207.10.40.1 IP=168.1.140.10 Heartbeats Failover Retransmissions User adjustable controls Added Security P0 P1 INIT INIT-ACK COOKIE-ECHO User data can be piggy-backed on third and fourth leg COOKIE-ACK SCTP’s Use of Signed Cookie Limitations Comprehensive CRC32c checksum – offload to NIC not yet commonly available SCTP bundles messages together so it might not always be able to pack a full MTU SCTP stack is in early stages and will improve over time Performance is stack dependant (Linux lksctp stack << FreeBSD KAME stack) Experiments for Loss LAM_SCTP LAM_TCP Total Run Time LAM_SCTP versus LAM_TCP 40 35 30 25 20 15 10 5 0 34.64 16.56 5.76 0.43 7.90 0.63 0% 1% 2% Loss Rate Performance of MPI Program that Uses Multiple Tags Experiments: Head-of-Line Blocking Total Run Time Comparison of Same Tags and Different Tags in a Latency Tolerant Program 1500 1450 1400 1350 1300 1250 1200 1150 1100 LAM_SCTP Same Tags LAM_SCTP Different Tags 1% 2% 10% Loss Rate Use of Different Tags vs. Same Tags Experiments: SCTP versus TCP MPBench Ping Pong Test 1.2 1 0.8 LAM_SCTP LAM_TCP 0.6 0.4 0.2 Message Size (bytes) MPBench Ping Pong Test under No Loss 131069 98302 65535 32768 0 1 Throughput Normalized to LAM_TCP values 1.4 Conclusions SCTP is a better suited for MPI Avoids unnecessary head-of-line blocking due to use of streams Increased fault tolerant in presence of multihomed hosts In-built security features SCTP might be key to moving MPI programs from LANs to WANs. Thank you! More information about our work is at: http://www.cs.ubc.ca/labs/dsg/mpi-sctp/