Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Computer network wikipedia , lookup
Zero-configuration networking wikipedia , lookup
Deep packet inspection wikipedia , lookup
Network tap wikipedia , lookup
Distributed firewall wikipedia , lookup
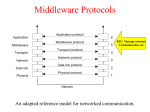
Internet protocol suite wikipedia , lookup
Cracking of wireless networks wikipedia , lookup
TCP congestion control wikipedia , lookup
Recursive InterNetwork Architecture (RINA) wikipedia , lookup
GridMPI: Grid Enabled MPI Yutaka Ishikawa University of Tokyo and AIST http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 1 Motivation • MPI has been widely used to program parallel applications • Users want to run such applications over the Grid environment without any modifications of the program • However, the performance of existing MPI implementations is not scaled up on the Grid environment computing resource site A computing resource site B Wide-area Network Single (monolithic) MPI application over the Grid environment http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 2 Motivation • Focus on metropolitan-area, high-bandwidth environment: 10Gpbs, 500miles (smaller than 10ms one-way latency) – Internet Bandwidth in Grid Interconnect Bandwidth in Cluster • 10 Gbps vs. 1 Gbps • 100 Gbps vs. 10 Gbps computing resource site A computing resource site B Wide-area Network Single (monolithic) MPI application over the Grid environment http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 3 Motivation • Focus on metropolitan-area, high-bandwidth environment: 10Gpbs, 500miles (smaller than 10ms one-way latency) – We have already demonstrated that the performance of the NAS parallel benchmark programs are scaled up if one-way latency is smaller than 10ms using an emulated WAN environment Motohiko Matsuda, Yutaka Ishikawa, and Tomohiro Kudoh, ``Evaluation of MPI Implementations on Grid-connected Clusters using an Emulated WAN Environment,'' CCGRID2003, 2003 computing resource site A computing resource site B Wide-area Network Single (monolithic) MPI application over the Grid environment http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 4 Issues Bandwidth (MB/s) TCP MPI • High Performance Communication Facilities for MPI on Long and Fat Designed for streams. Repeat the computation Networks and communication phases. – TCP vs. MPI communication Burst traffic. Change traffic by patterns communication patterns. – Network Topology Repeating 10MB data transfer • Latency and Bandwidth with two second intervals • Interoperability 125 – Most MPI library phase • The slow-start 100 implementations useistheir own •window size set to 1 75 network protocol. 50 • Fault Tolerance and Migration 25 – To survive a site failure 0 • Security 100 200 300 400 500 • These silences results from burst traffic 0 Time (ms) Observed during one 10MB data transfer http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 5 Issues Bandwidth (MB/s) TCP MPI • High Performance Communication Facilities for MPI on Long and Fat Designed for streams. Repeat the computation Networks and communication phases. – TCP vs. MPI communication Burst traffic. Change traffic by patterns communication patterns. – Network Topology Start one-to-one communication • Latency and Bandwidth at time 0 after all-to-all • Interoperability 125 – Most MPI library 100 implementations use their own network protocol. 75 50 • Fault Tolerance and Migration 25 – To survive a site failure 0 • Security 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 Time (sec) http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 6 Issues TCP MPI • High Performance Communication Facilities for MPI on Long and Fat Designed for streams. Repeat the computation Networks and communication phases. – TCP vs. MPI communication Burst traffic. Change traffic by patterns communication patterns. – Network Topology • Latency and Bandwidth • Interoperability – Most MPI library implementations use their own network protocol. Internet • Fault Tolerance and Migration – To survive a site failure • Security http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 7 Issues • High Performance Communication TCP MPI Facilities for MPI on Long and Fat Designed for streams. Repeat the computation Networks and communication – TCP vs. MPI communication phases. Burst traffic. patterns Change traffic by – Network Topology communication patterns. • Latency and Bandwidth • Interoperability – Many MPI library implementations. Most Using Vendor implementations use their own Using Vendor B’s MPI library A’s MPI library network protocol Interne • Fault Tolerance and Migration t – To survive a site failure • Security http://www.gridmpi.org Using Vendor C’s MPI library Yutaka Ishikawa, The University of Tokyo Using Vendor D’s MPI library 8 GridMPI Features IMPI • MPI-2 implementation MPI API • YAMPII, developed at the RPIM Interface LAC Layer University of Tokyo, is used as (Collectives) the core implementation Request Interface • Intra communication by YAMPII Request Layer (TCP/IP、SCore) P2P Interface • Inter communication by IMPI (Interoperable MPI), protocol and extension to Grid – MPI-2 – New Collective protocols LAC: Latency Aware Collectives • Integration of Vendor MPI • bcast/allreduce algorithms have been developed (to appear at the cluster06 conference) – IBM Regatta MPI, MPICH2, Solaris MPI, Fujitsu MPI, (NEC SX MPI) IPMI/TCP • Incremental checkpoint Interne • High Performance TCP/IP implementation t Vendor MPI O2G MX PMv2 Yutaka Ishikawa, The University of Tokyo TCP/IP http://www.gridmpi.org IMPI Vendor MPI Globus SCore rsh ssh Vendor’s MPI YAMPII 9 High-performance Communication Mechanisms in the Long and Fat Network • Modifications of TCP Behavior – M Matsuda, T. Kudoh, Y. Kodama, R. Takano, and Y. Ishikawa, “TCP Adaptation for MPI on Long-and-Fat Networks,” IEEE Cluster 2005, 2005. • Precise Software Pacing – R. Takano, T. Kudoh, Y. Kodama, M. Matsuda, H. Tezuka, Y. Ishikawa, “Design and Evaluation of Precise Software Pacing Mechanisms for Fast Long-Distance Networks”, PFLDnet2005, 2005. • Collective communication algorithms with respect to network latency and bandwidth. – M. Matsuda, T. Kudoh, Y. Kodama, R. Takano, Y. Ishikawa, “Efficient MPI Collective Operations for Clusters in Long-andFast Networks”, to appear at IEEE Cluster 2006. http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 10 Evaluation • It is almost impossible to reproduce the execution behavior of communication performance in the wide area network • A WAN emulator, GtrcNET-1, is used to scientifically examine implementations, protocols, communication algorithms, etc. GtrcNET-1 GtrcNET-1 is developed at AIST. • injection of delay, jitter, error, … • traffic monitor, frame capture http://www.gridmpi.org •Four 1000Base-SX ports •One USB port for Host PC •FPGA (XC2V6000) http://www.gtrc.aist.go.jp/gnet/ Yutaka Ishikawa, The University of Tokyo 11 Experimental Environment 8 PCs •Bandwidth:1Gbps •Delay: 0ms -- 10ms Node8 Host 0 Host 0 Host 0 ……… WAN Emulator GtrcNET-1 Catalyst 3750 Node7 Catalyst 3750 ……… Node0 Host 0 Host 0 Host 0 8 PCs Node15 CPU: Pentium4/2.4GHz, Memory: DDR400 512MB NIC: Intel PRO/1000 (82547EI) OS: Linux-2.6.9-1.6 (Fedora Core 2) Socket Buffer Size: 20MB http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 12 GridMPI vs. MPICH-G2 (1/4) FT (Class B) of NAS Parallel Benchmarks 3.2 on 8 x 8 processes 1.2 FT(GridMPI) Relative Performance 1 FT(MPICH-G2) 0.8 0.6 0.4 0.2 0 0 2 4 6 8 10 12 One way delay (msec) http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 13 GridMPI vs. MPICH-G2 (2/4) IS (Class B) of NAS Parallel Benchmarks 3.2 on 8 x 8 processes 1.2 Relative Performance 1 IS(GridMPI) IS(MPICH-G2) 0.8 0.6 0.4 0.2 0 0 2 4 6 8 10 12 One way delay (msec) http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 14 GridMPI vs. MPICH-G2 (3/4) LU (Class B) of NAS Parallel Benchmarks 3.2 on 8 x 8 processes 1.2 LU(GridMPI) Relative Performance 1 LU(MPICH-G2) 0.8 0.6 0.4 0.2 0 0 2 4 6 8 10 12 One way delay (msec) http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 15 GridMPI vs. MPICH-G2 (4/4) NAS Parallel Benchmarks 3.2 Class B on 8 x 8 processes 1.2 SP(GridMPI) BT (GridMPI) MG(GridMPI) CG(GridMPI) SP(MPICH-G2) BT(MPICH-G2) MG(MPICH-G2) CG(MPICH-G2) Relative Performance 1 0.8 0.6 0.4 0.2 No parameters tuned in GridMPI 0 0 2 4 6 8 10 12 One way delay (msec) http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 16 • NAS Parallel Benchmarks run using 8 node (2.4GHz) cluster at Tsukuba and 8 node (2.8GHz) cluster at Akihabara – 16 nodes • Comparing the performance with – result using 16 node (2.4 GHz) – result using 16 node (2.8 GHz) Relative performance GridMPI on Actual Network 1.2 1 0.8 0.6 0.4 0.2 0 2.4 GHz 2.8 GHz BT CG EP FT IS LU MG SP Benchmarks JGN2 Network 10Gbps Bandwidth 1.5 msec RTT Pentium-4 2.4GHz x 8 Pentium-4 2.8 GHz x 8 connected by 1G Ethernet 60 Km (40mi.) Connected by 1G Ethernet @ Tsukuba @ Akihabara http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 17 GridMPI Now and Future • GridMPI version 1.0 has been released – Conformance Tests • MPICH Test Suite: 0/142 (Fails/Tests) • Intel Test Suite: 0/493 (Fails/Tests) – GridMPI is integrated into the NaReGI package • Extension of IMPI Specification – Refine the current extensions – Collective communication and check point algorithms could not be fixed. The current idea is specifying • The mechanism of – dynamic algorithm selection – dynamic algorithm shipment and load » virtual machine to implement algorithms http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 18 Dynamic Algorithm Shipment • A collective communication algorithm implemented in the virtual machine • The code is shipped to all MPI processes • The MPI runtime library interprets the algorithm to perform the collective communication for inter-clusters Internet http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 19 Concluding Remarks • Our Main Concern is the metropolitan area network – high-bandwidth environment: 10Gpbs, 500miles (smaller than 10ms one-way latency) • Overseas ( 100 milliseconds) – Applications must be aware of the communication latency – data movement using MPI-IO ? • Collaborations – We would like to ask people, who are interested in this work, for collaborations http://www.gridmpi.org Yutaka Ishikawa, The University of Tokyo 20