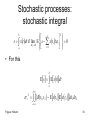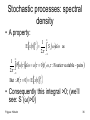Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Communication Theory
I. Frigyes
2009-10/II.
http://docs.mht.bme.hu/~frigyes/hirkelm
hirkelm01bEnglish
Frigyes: Hírkelm
2
Topics
• (0. Math. Introduction: Stochastic processes, Complex
envelope)
• 1. Basics of decision and estimation theory
• 2. Transmission of digital signels over analog channels:
noise effects
• 3. Transmission of digital signels over analog channels:
dispersion effects
• 4. Analóg jelek átvitele – analóg modulációs eljárások (?)
• 5. Channel characterization: wireless channels, optical
fibers
•
•
•
•
•
6. A digitális jelfeldolgozás alapjai: mintavételezés, kvantálás, jelábrázolás
7. Elvi határok az információközlésben.
8. A kódelmélet alapjai
9. Az átvitel hibáinak korrigálása: hibajavító kódolás; adaptív kiegyenlítés
10. Spektrális hatékonyság – hatékony digitális átviteli eljárások
Frigyes: Hírkelm
3
(0. Stochastic processes, the
complex envelope)
Stochastic processes
• Also called random waveforms.
• 3 different meanings:
• As a function of ξ number of realizations:
a series of infinite number of random
variables ordered in time
• As a function of time t: a member of a
time-function family of irregular variation
• As a function of ξ and t: one member of a
family of time functions drawn at random
Frigyes: Hírkelm
5
Stochastic processes
• example:
f(t,ξ3)
2
f(t,ξ2)
ξ
f(t,ξ1)
f(t1,ξ)
t
Frigyes: Hírkelm
f(t2,ξ)
1
f(t 3,ξ)
3
6
Stochastic processes: how to
characerize them?
• According to the third definition
• And with some probability distribution.
• As the number of random variables is
infinite: with their joint distribution (or
density)
• (not only infinite but continuum cardinality)
• Taking these into account:
Frigyes: Hírkelm
7
Stochastic processes: how to
characerize them?
• (Say: density)
• First prob. density of x(t) p xt t
x
• second:
joint t1,t2
p x1, x 2 xt1 , xt 2 t1 , t 2
• nth:n-fold joint
p x1 , x2 ,... xn xt1 , xt 2 ,.... xt n t1 , t 2 ,...t n
• The stochastic process is completly
characterized, if there is a rule to compose
density of any order (even for n→).
• (We’ll see processes depending on 2
parameters)
Frigyes: Hírkelm
8
Stochastic processes: how to
characerize them?
• Comment: although precisely the process
(function of t and ξ) and one sample
function (function of t belonging to say ξ16)
are distinguished we’ll not always make
this distinction.
Frigyes: Hírkelm
9
Stochastic processes: how to
characerize them?
•
•
•
•
•
Example: semi-random binary signal:
Values : ±1 (P0=P1= 0,5)
Change: only at t=k×T
1
1
p x x 1 x 1
2
2
First density_:
1
1
Second::
x1 1, x2 1,
x
1
,
x
1
1
2
2
2
if t1 , t 2 in the same time slot ;
p x1, x 2 xt1 , xt 2 1
1
4 x1 1, x2 1 4 x1 1, x2 1
1 x 1, x 1 1 x 1, x 1, otherwise
1
2
1
2
4
4
Frigyes: Hírkelm
10
Continuing the example:
In the same time-slot
45o
Frigyes: Hírkelm
In two distinct time-slots
45o
11
Stochastic processes: the
Gaussian process
• A stoch. proc. is Gaussian if its n-th density is
that of an n-dimensional vector random variable
px ti X
1
det K 2
n
e
1
X m T K 1 X m
2
• m is the expected value vector, K the covariance
matrix.
• nth density can be produced if are given
mx t Ext és K x t1 , t2 Ext1 mx t1 xt2 mx t2
• are given
Frigyes: Hírkelm
12
Stochastic processes: the
Gaussian process
• An interesting property of Gaussian
processes (more precisely: of Gaussian
variables):
Ex y z w Ex y Ez w
Ex z Ey w Ex w Ez y
• These can be realizations of one process
at different times
Frigyes: Hírkelm
13
Stochastic processes: stationary
processes
• A process is stationary if it does not
change (much) as time is passing
• E.g. the semirandom binary signal is
(almost) like that
• Phone: to transmit 300-3400 Hz sufficient
(always, for everybody). (What could we
do if this didn’t hold?)
• etc.
Frigyes: Hírkelm
14
Stochastic processes: stationary
processes
• Precise definitions: what is almost unchanged:
• A process is stationary (in the strict sense) if for
the distribution function of any order and any at
any time and time difference
Fx t1 , t 2 ...t n , t n 1 ,... Fx t1 , t 2 ...t n , t n 1 ,...
• Is stationary in order n if the first n distributions
are stationary
• E.g.: the seen example is first order stationary
• In general: if stationary in order n also in any
order <n
Frigyes: Hírkelm
15
Stochastic processes: stationary
processes
• Comment: to prove strict sense stationarity
is difficult
• But: if a Gaussian process is second order
stationary (i.e. in this case: if K(t1,t2) does
not change if time is shifted) it is strict
sense (i.e. any order) stationary. As: if we
know K(t1,t2) nth density can be computed
(any n)
Frigyes: Hírkelm
16
Stochastic processes:
stationarity in wide sense
• Wide sense stationary: if the correlation
function is unchanged if time is shifted (to
be defined)
• A few definitions:.
• a process is called a Hilbert-process if
E xt
2
• (That means: instantaneous power is
finite.)
Frigyes: Hírkelm
17
Stochastic processes: wide
sense stationary processes
• (Auto)correlation function of a Hilbertprocess:
Rt1 , t 2 Ext1 .xt 2
• The process is wide sense stationary if
• the expected value is time-invariant and
• R depends only on τ=t2-t1 for any time and
any τ.
Frigyes: Hírkelm
18
Stochastic processes: wide sense
– strict sense stationary processes
• If a process is strict-sense stationary then also
wide-sense
• If at least second order stationary: then also
wide sense.
Rt1 , t 2 Ext1 , xt2
X
X
• I.e.:
Frigyes: Hírkelm
t1
t1
X t2 p x1x2 X t 1 , X t 2 dX t1 dX t2
X t2 p x1x2 X t 1 , X t dX t1 dX t2 Rt1 , t2
2
Rt1 , t 2 Rt1 , t1 R
19
Stochastic processes: wide sense
– strict sense stationary processes
• Further: if wide sense stationary, not strict
sense stationary in any sense
• Exception: Gaussian process. This: if wide
sense stationary, also in stict sense.
Frigyes: Hírkelm
20
Stochastic processes: once
again on binary transmission
• As seen: only first order stationary (Ex=0)
• Correlation:
•
if t1 and t2 in the same time-slot:
Rt1 , t 2 Ext1 .xt 2 1
•
if in different:
Rt1 , t 2 Ext1 Ext 2 0
Frigyes: Hírkelm
21
Stochastic processes: once
again on binary transmission
• The semi-random binary transmission can
be transformed in random by introducing a
dummy random variable e distributed
uniformly in (0,1)
yt xt e
T
• like x:
Frigyes: Hírkelm
e
Eyt 0
22
Stochastic processes: once
again on binary transmission
• Correlation:
• If |t1-t2|>T,
(as e T)
• if |t1-t2| T
Eyt1 yt2 EEyt1 .yt2 e 0
1; e T t1 t2
Ry t1 , t2
0; otherwise
• so
Ry 1 Ee T 1
Frigyes: Hírkelm
T
23
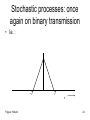
Stochastic processes: once
again on binary transmission
• I.e. :
-T
Frigyes: Hírkelm
T
τ
24
Stochastic processes: other
type of stationarity
• Given two processes, x and y, these are
jointly stationary, if their joint distributions
are alle invariant on any τ time shift.
• Thus a complex process zt xt jy t
is stationary in the strict sense if x and y
are jointly stationary.
• A process is periodic (or ciklostat.) if
distributions are invariant to kT time shift
Frigyes: Hírkelm
25
Stochastic processes: other
type of stationarity
• Cross-correlation:
R x , y t1 , t 2 Ext1 y t 2
• Two processes are jointly stationary in the
wide sense if their cross correlation is
invariant on any time shift t 2 t1
Frigyes: Hírkelm
26
Stochastic processes: comment
on complex processes
• Appropriate definition of correlation for
these:
Rt , t Ext .x t
1
2
1
2
• A complex process is stationary in the
wide sense if both real and imaginary
parts are wide sense stationary and they
are that jointly as well
Frigyes: Hírkelm
27
Stochastic processes: continuity
• There are various definitions
• Mean square continuity
E xt xt , ha
2
2
• That is valid if the correlation is continuous
Frigyes: Hírkelm
28
Stochastic processes:
stochastic integral
• x(t) be a stoch. proc. Maybe that Rieman
integral exists for all realizations:
b
s x t dt
a
• Then s is a random variable (RV). But if
not, we can define an RV converging (e.g.
mean square) to the integral-approximate
sum:
Frigyes: Hírkelm
29
Stochastic processes:
stochastic integral
2
n
s xt dt if lim E s xti ti 0
ti 0
a
i 1
b
• For this
b
Es Ext dt
a
b b
s 2 Rt1 , t 2 Ext1 Ext 2 dt1dt2
a a
Frigyes: Hírkelm
30
Stochastic processes:
stochastic integral - comment
• In σs2 the integrand is the
(auto)covariancie-function:
C t1 , t 2 ˆ Ext1 xt 2 Ext1 Ext 2
• This depends only on t1-t2=τ if x is
stationary (at least wide sense)
Frigyes: Hírkelm
31
Stochastic processes: time
average
• Integral is needed – among others –to define
time average
• Time average of a process is its DC component;
• time average of its square is the mean power
• definition:
1
n x lim
T 2T
Frigyes: Hírkelm
T
xt dt
T
32
Stochastic processes: time
average
• In general this is a random variable. It
would be nice if this were the statistical
average. This is really the case if
2
nx Ext and n 0
• Similarly we can define
1
R lim
T 2T
Frigyes: Hírkelm
T
xt xt dt
T
33
Stochastic processes: time
average
• This is in general also a RV. But equal to
the correlation if
2
Rx Rx , with R 0
• If these equalities hold the process is
called ergodic
• The process is mean square ergodic if
1
lim
T 2T
Frigyes: Hírkelm
T
R d Ext
2
x
T
34
Stochastic processes: spectral
density
• Spectral density of a process is, by
definition the Fourier transform of the
correlation function
S x
R e
x
j
d
Frigyes: Hírkelm
35
Stochastic processes: spectral
density
• A property:
E xt
2
1
2
S d
x
as
1
Fu d u 0; , : Fourier va riable - pairs
2 -
But : R 0 E xt
2
• Consequently this integral >0; (we’ll
see: S˙(ω)>0)
Frigyes: Hírkelm
36
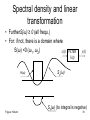
Spectral density and linear
transformation
• As known in time functions output function
is convolution
x(t)
FILTER
y(t)
h(t)
y t xt ht
xu ht u du
• h(t): impulse response
Frigyes: Hírkelm
37
Spectral density and linear
transformation
• Comment.: h(t<0)≡ 0; (why?);
and: h(t) = F-1[H(ω)]
• It is plausible: the same for stochastic
processes
• Based on that it can be shown :
S y H S x
2
• (And also
Frigyes: Hírkelm
Eyt Ext H 0
)
38
Spectral density and linear
transformation
• FurtherS(ω) ≥ 0 (all frequ.)
• For: if not, there is a domain where
S(ω) <0 (ω1, ω2)
x(t)
FILTER
y(t)
h(t)
H(ω)
Frigyes: Hírkelm
Sx(ω)
Sy(ω) (its integral is negative)
39
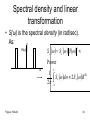
Spectral density and linear
transformation
• S(ω) is the spectral density (in rad/sec).
As:
2
H(ω)
S y S x H
Power
ω
Frigyes: Hírkelm
1
2
S d 2S B
x
Hz
x
40
Modulated signals – the complex
envelope
• In previous studies we’ve seen that in
radio, optical transmission
• one parameter is influenced (e.g. made
proportional)
•
of a sinusoidal carrier
•
by the modulating signal
.
• A general modulated signal:
xt 2 Ad t cosc t t
Frigyes: Hírkelm
41
Modulated signals – the
complex envelope
• Here d(t) and/or (t) carries the
information – e.g. are in linear relationship
with the modulating signal
• An other description method (quadrature
form):
xt Aat cosc t Aqt sinc t
• d, , a and q are real time functions –
deterministic or realizations of a stoch.
proc.
Frigyes: Hírkelm
42
Modulated signals – the
complex envelope
• Their relationship:
d t
at qt
2
2
2
qt
; t arctg
at
at 2d t cos t ; qt 2d t sin t
• As known x(t) can also be written as:
xt Reat jqt e
jct
Frigyes: Hírkelm
43
Modulated signals – the
complex envelope
• Here a+jq is the complex envelope.
Question: when, how to apply.
• To beguine with: Fourier transform of a
real function is conjugate symmetric:
X ˆ Fxt ; and Fx- t X
• But if so: X(ω>0) describes the signal
completly: knowing that we can form the
ω<0 part and, retransform.
Frigyes: Hírkelm
44
Modulated signals – the
complex envelope
• Thus instead of X(ω) we can take that:
X ˆ X sign X X j jsign X
• By the way:
2 X ; 0
X
0; 0
↓
„Hilbert” filter
• The relevant time function:
xt F X xt jF1 jsign X
Frigyes: Hírkelm
1
45
Modulated signals – the
complex envelope
We can write: xt xt jx t F1 - jsign
•
• The shown inverse Fourier transform is
1/t.
x
xt xt j
d
• So
t
xt xt jHxt xt jxˆ t
• Imaginary part is the so-callerd Hilberttranszform of x(t)
Frigyes: Hírkelm
46
Modulated signals – the
complex envelope
• Now introduced function xt is the analytic
function assigned to x(t) (as it is an
analytic function of the z=t+ju complex
variable).
• An analytic function can be assigned to
any (baseband or modulated) function;
relationship between the time function and
the analytic function is
Frigyes: Hírkelm
47
Modulated signals – the
complex envelope
• It is applicable to modulated signals: analytic signal of
cosωct is ejωct. Similarly that of sinωct is jejωct. So if
quadrature components of the modulated signal a(t), q(t)
are
•
band limited and
•
their band limiting frequency is < ωc/2π (narrow band
signal)
xt at cos ct xt at e jct
• then
or
NB. Modulation is a linear
operation in a,q: frequency
x t qt sin ct xt jqt e jct
displacement.
Frigyes: Hírkelm
48
Modulated signals – the
complex envelope
• Thus ~
x t ̂ a t jq t complex envelope
determines uniquely the modulated signals. In the time
domain
~
x t at jq t xt ~
x t e jct xt
Re xt at cos c t qt sin c t
• Comment: ~
x t according to its name can be complex.
(X(ω) is not conjugate symmetricaround ωc.)
• Comment 2: if the bandwidt B>fc,xt is not analytic, its
real part does not define the modulated signal.)
• Comment 3: a és q can be independent signals (QAM)
or can be related (FM or PM).
Frigyes: Hírkelm
49
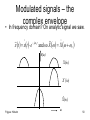
Modulated signals – the
complex envelope
• In frequency domain? On analytic signal we saw.
~
x t xt e
j c t
~
and so X X c
X(ω)
X(ω)
X˚(ω)
X̃(ω)
Frigyes: Hírkelm
ω
50
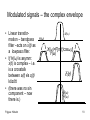
Modulated signals – the complex envelope
• Linear transformation – bandpass
filter –acts on x̃(t) as
a lowpass filter.
• If H(ω) is asymm:
x̃(t) is complex – i.e.
is a crosstalk
between a(t) és q(t)
között
• (there was no sin
component – now
there is.)
Frigyes: Hírkelm
M(ω)
H(ω)
X(ω)=F[m(t)cosωct]
Y(ω)
Y˚(ω)
X˚(ω)
X̃ (ω)
Ỹ(ω)
51
Modulated signals – the complex envelope,
stochastic processes
• Analytic signal and complex envelope are
defined for deterministic signals
• It is possible for stochastic processes as
well
• No detailed discussion
• One point:
Frigyes: Hírkelm
52
Modulált jelek – a komplex burkoló;
sztochasztikus folyamatok
• x(t) is stationary (Rx is independent from t),
iff
Eat Eqt 0; Ra Rq ; Raq Rqa
xt at cos c t qt sin c t és
Rx t , Ra Rq cos c Rqa Raq sin c
Ra Rq cos c 2t Raq Rqa sin c 2t
Frigyes: Hírkelm
53
Narrow band (white) noise
• White noise is of course not narrow band
• Usually it can be made narrow band by a
(fictive) bandpass filter:
H(ω)
X(ω)
X(ω)
Sn(ω) =N0/2
Frigyes: Hírkelm
ω
54
Narrow band (white) noise
properties
jc t
jc t
~
nt n t e
nc t jn s t e
Rc Rs ; Rc , s Rs ,c
Rn~ Rc jR c , s
1
S n S n~ c S n~ c
2
Frigyes: Hírkelm
55
1. Basics of decision theory and
estimation theory
Detection-estimation problems in
communications
• 1. Digital communication: one among signals
known (by the receiver) – in presence of noise
DIGITAL
SOURCE
Transmission
channel
SINK
• E.g.: (baseband binary communication)
s1 t U nt ; s0 t nt
• Decide: which was sent?
Frigyes: Hírkelm
57
Detection-estimation problems in
communications
• 2. (Otherwise) known signal has unknown
parameter(s) (statistics are known) • Same block schematic; example: noncoherent FSK
s1 t 2 A cos c1t 1 nt ; s2 t 2 A cos c 2t 2 nt
1
; ,
p1 p 2 2
0; otherwise
Frigyes: Hírkelm
58
Detection-estimation problems
in communications
• Other example: non-coherent FSK, over nonselective Rayleigh fading channel
s1 t 2 A cos c1t 1 nt ; s2 t 2 A cos c 2t 2 nt
1
; ,
p1 p 2 2
0; otherwise
Frigyes: Hírkelm
2
p A 2 e
2 2
59
Detection-estimation problems
in communications
• 3. Signalshape undergoes random changes
• Example: antipodal signal set in very fast fading
DIGITAL
SOURCE
Transmission
channel
T(t)
SINK
s1 t st T t nt ; s2 t st T t nt
Frigyes: Hírkelm
60
Detection-estimation problems
in communications
• 4. Analog radio communications: one parameter
of the carrier is proportional to the time-contous
modulating signal.
• E.g..: analog FM; estimate: m(t)
st 2 A cos c t 2 .F.mt nt
• Or: digial transmission over frequency-selective
fading. For decision: h(t) must be known (i.e.
estimated
r t
ht si d nt ; i 1,2,... M
Frigyes: Hírkelm
61
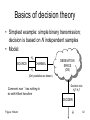
Basics of decision theory
• Simplest example: simple binary transmission;
decision is based on N independent samples
• Model:
H0
SOURCE
CHANNEL
H1
OBSEVATION
SPACE
(OS)
(Only statistics are known)
Comment: now ˆ has nothing to
do with Hilbert transform
Decision rule
H0? H1?
DECIDER
Frigyes: Hírkelm
Ĥ
62
Basics of decision theory
• Two hypothesis (H0 és H1)
• Observation: N samples→the OS is of Ndimensions
• Observation: rT=(r1,r2…,rN)
• Decision: which was sent
• Results: 4 possibilities
•
1. H0 sent & Ĥ=H0 (correct)
•
2. H0 sent & Ĥ=H1 (erroneous)
•
3. H1 sent & Ĥ=H1 (correct)
•
4. H1 sent & Ĥ=H0 (erroneous)
Frigyes: Hírkelm
63
Bayes decision
• Bayes decision :
•
a.) probabilities of sending H0 or H1 are apriori known:
Pr H 0 ˆ P0 ; Pr H1 ˆ P1
•
• b.) each decision has some cost (Cik) (we decide
in favor of i while sent was k)
• c.) it is sure: false decision is more expensive
than correct:
C10 C00 ; C01 C11
Frigyes: Hírkelm
64
Bayes decision
•
d.) decision rule: the average cost (so called
risk, K) should be minimal
K C11 P1 Pr Hˆ H1 | H1 C01 P1 Pr Hˆ H 0 | H1
C P Pr Hˆ H | H C P Pr Hˆ H | H
00 0
0
0
10 0
1
0
OS
pr|H1(R|H1)
(Z1)
FORRÁS
„H1”
pr|H0(R|H0)
„H0”
(Z0)
domain of r; two pdf-s
correspond to each point.
Frigyes: Hírkelm
65
Bayes decision
• Question: how to partition OS in order to
get minimal K?
• For that: K in detail:
K C00 P0
C11P1
pr|H 0 R | H 0 dR C10 P0 pr|H 0 R | H 0 dR
Z 0
Z1
pr|H 1 R | H1 dR C01P1 pr|H 1 R | H1 dR
Z1
Z 0
• As some decision is taken:
• And so
1
Z1
Frigyes: Hírkelm
Z1 Z 0 Z 0
p 1
Z 0 Z1
Z 0
66
Bayes decision
• From that:
K P0 C10 P1C11
P1 C01 C11 pr|H 1 pR | H1 dR
Z 0
P0 C10 C00 pr|H 0 pR | H 0 dR
Z 0
• Term 1 & 2 are constant
(Z )
FORRÁS
„H ”
„H ”
• And: both integrands >0
(Z )
p (R|H )
• Thus: Z1, where the first integrand is larger
Z0, where the second
pr|H1(R|H1)
1
0
1
r|H0
Frigyes: Hírkelm
0
0
67
Bayes decision
Z1 : P1 C01 C11 pr | H 1 pR | H 1
P0 C10 C00 pr | H 0 pR | H 0
• And here we decide in favor of H1: Hˆ H1
Z 0 : P1 C01 C11 pr | H 1 pR | H1
P0 C10 C00 pr | H 0 pR | H 0
• decision: H0
Frigyes: Hírkelm
Hˆ H 0
68
Bayes decision
• It can also be written: decide for H1 if
pr | H 1 R | H1
P0 C10 C00
pr | H 0 R | H 0 P1 C01 C11
•
•
•
•
Otherwise for H0
Lefthand side: likelyhood ratio, Λ(R)
Righthand: (from certain aspect) the treshold, η
Comment: Λ depends only on the realisation of r
(on: what did we measure?)
•
η only on the a-priori probabilities and costs
Frigyes: Hírkelm
69
Example on Baysean decision
• H1: constant voltage + Gaussian noise
• H0: Gaussian noise only (designation:
φ(r;mr,σ2)
• Decision: on N independent samples of r
• At sample #i
pri | H 1 Ri ; m, 2 ; pri | H 0 Ri ;0, 2
N
p r | H 1 R | H 1 Ri ; m, 2 ;
• This resulting in
i 1
N
p r | H 0 R | H 0 Ri ;0, 2
Frigyes: Hírkelm
i 1
70
Example on Baysean decision
Ri m 2
2 exp 2 2
i 1
R
N
Ri 2
1
2 exp 2 2
i 1
N
• its logaritm
1
ln R
• resulting in
m
2
N
Nm 2
Ri 2 2
i 1
2
N
Nm
Nm
ˆ
ˆ
H H1 : Ri
ln
; H H 0 : Ri
ln
m
2
m
2
i 1
i 1
N
2
threshold
Frigyes: Hírkelm
71
Comments to the example
• 1. The threshold contains known quantities only,
independent of the measured values
• 2. Result depends only on the sum of ri-s – we
have to know only that; so called sufficient
statistics l(R):
N
l R Ri
i 1
• 2.a Like in this example: OS dimension is
whatever, l(R) is always 1D
• i.e.„1 coordinate” – the others are independent
on hypothesis
Frigyes: Hírkelm
72
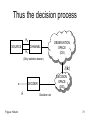
Thus the decision process
H0
SOURCE
CHANNEL
H1
OBSERVATION
SPACE
(OS)
(Only statistics known)
l R
DECISION
SPACE
(DS)
DECIDER
Ĥ
Frigyes: Hírkelm
Decision rule
73
Comments to the example
• 3. Special case: C00=C11=0 és C01=C10=1
K P0
pr|H 0 R | H 0 dR P1 pr|H 1 R | H1 dR
Z1
Z 0
• (i.e. probability of erroneous decision)
• If P0,1≡0,5, the treshold N.m/2
Frigyes: Hírkelm
74
An other example, for home
• Similar but now the signal is not constant
but Gaussian noise with variance σS2
• I.e.
H1:Π φ(Ri;0,σS2+σ2)
•
H0:Π φ(Ri;0,σ2)
• Questions: threshold; sufficient statistics
Frigyes: Hírkelm
75
Third example - discrete
• Given two Poisson sources with different
expected values; which was sent?
• Remember: Poisson-distribution:
mn e n
Pr n
n!
• Hypotheses:
n m1
m1 e
H1 : Pr n
n!
Frigyes: Hírkelm
n m0
m0 e
; H 0 : Pr n
n!
76
Third example - discrete
n
m1 m1 m0
e
n
• Likelihood-ratio:
m
0
ln m1 m0
if n
: H1 ;
• Decision rule:
ln m1 m0
(m1>m0)
ln m1 m0
if n
: H0
ln m1 m0
• For sake of precision:
ln m1 m0
if n
: H1Q H 0 1 Q ;
ln m1 m0
Pr(Q 0) Pr(Q 1) 0,5
Frigyes: Hírkelm
77
Comment
• A possible situation: a-priori probebilities
are not known
• A possible method then:
compute maximal K (as a function of Pi;
and chose the decision rule wich
minimizes that (so called minimax
decision)
• (Note: this is not optimal at any Pi )
• But we don’t deal with this in detail.
Frigyes: Hírkelm
78
Probability of erroneous decision
• For that: compute relevant integral
• In example 1 (with N=1): Gs pdf should be
integrated over the hatched domains
d0
Threshold:
Frigyes: Hírkelm
d1
m
d 0 ln
m
2
79
Probability of erroneous decision
• Thus:
PE P0 P1 | 0 P1P0 | 1
1
d0
P1 | 0 R ;0, dR erfc
2
d0
2
1
m d0
P0 | 1 R ; m, dR erfc
2
d0
2
• If lnη=0: d0=d1=m/2 (threshold: the point of
intersection)
• Comment: N samples:
m N
d0
ln
2
m N
Frigyes: Hírkelm
80
Decision with more than 2
hypotheses
• M possible outcomes (e.g.:non-binary
digital communication – we’ll see: why for)
• Like before: each decision has a cost
• Their average is the risk
• With Bayes-decision: this is minimized
• Like before: Observation Space
•
decision rule: partitioning of the OS
Frigyes: Hírkelm
81
•
Decision with more than 2
hypotheses
M 1M 1
Like before, risk:
K ˆ Cij Pj p R| Hj R | H j dR
i 0 j 0
• From that (with M = 3)
Z i
K P0 C00 P1C11 P2 C22
P2 C02 C22 pr|H 2 R | H 2 P1 C01 C11 pr|H 1 R | H1 dR
Z 0
P2 C12 C22 pr|H 2 R | H 2 P0 C10 C00 pr|H 0 R | H 0 dR
Z1
P1 C21 C11 pr|H 1 R | H1 P0 C20 C00 pr|H 0 R | H 0 dR
Z 2
Frigyes: Hírkelm
82
Döntés kettőnél több hipotézisnél
• Likelyhood ratio-series :
1 R
pr| H 1 R | H1
pr| H 0 R | H 0
; 2 R
pr| H 2 R | H 2
pr| H 0 R | H 0
• Decision rule(s):
Hˆ H1 or H 2 : P1 C01 C11 1 R P0 C10 C00 P2 C12 C02 2 R
Hˆ H or H if less;
0
2
Hˆ H 2 or H1 : P2 C02 C22 2 R P0 C20 C00 P1 C21 C01 1 R
Hˆ H or H if less;
0
1
Hˆ H 2 or H1 : P2 C12 C22 2 R P0 C20 C10 P1 C21 C11 1 R
Hˆ H or H if less;
Frigyes: Hírkelm
1
0
83
Döntés kettőnél több hipotézisnél
(M =3)
• This defines 3 streight lines (in the 2D decision
space)
Λ2(R)
H0
H2
H1
Λ1(R)
Frigyes: Hírkelm
84
Ecample: special case – error
probability
• The average error
probability is
minimized
Cii 0; Ci j 1
Λ2(R)
H2
• Then we get:
Λ2 = (P1/P2)Λ1.
P0 /P2
H1
H0
Frigyes: Hírkelm
P0 /P1
Λ1(R)
85
The previous, detailed
Hˆ H 1 vagy H 2 : P11 R P0
Hˆ H vagy H ha kisebb;
0
Cii 0; Ci j 1
2
Hˆ ˆ H 1 vagy H 2 : P1 C01 C11 1 R P0 C10 C00 P2 C12 C02 2 R
H H 2 vagy H 1 : P2 2 R P0
Hˆ H vagy H ha kisebb;
0
Hˆ H 0 vagy H 1 ha kisebb;
2
C20 CH00 P1 C21 C01 1 R
Hˆ H 2 vagy H 1 : P2 C02 C22 2 R ΛP20(R)
2
Hˆ H 2 vagy H 1 : P2 ˆ2 R P11 R
Λ2 = (P1/P2)Λ1.
H H vagy H ha kisebb;
ˆ
0
P01 /P2
H
H 1 Hvagy
H
kisebb;
0 ha
Hˆ H
vagy
:
P
C
C
2
1
2
12
22 2 R P0 C 20 C10 P1 C 21H C11 1 R
1
H0
Hˆ H vagy H ha kisebb;
1
Frigyes: Hírkelm
0
P0 /P1
Λ1(R)
86
Example –special case, error
probability: a-posteriori prob.
• Very important, based on the precedings: we have
H1 vagy H 2 : P1 pr| H 1 R | H1 P0 pr| H 0 R | H 0
H 2 vagy H1 : P2 pr| H 2 R | H 2 P0 pr| H 0 R | H 0
H 2 vagy H 0 : P2 pr| H 2 R | H 2 P1 pr| H 1 R | H1
• If we divide each by pr(R) and apply Bayes theorem we
get:
Pr b | a Pra
Bayes theorem : Pra | b
Pr b
Pr H1 | R Pr H 0 | R; Pr H 2 | R Pr H 0 | R; Pr H 2 | R Pr H1 | R
Frigyes: Hírkelm
(these
are a-posteriori probabilities)
87
Example –special case, error
probability: a-posteriori prob.
• I.e. we have to decide on the max. aposteriori probabilities.
• Rather plausible: probability of correct
decision is the highest if we decide on
what is the most probable
Frigyes: Hírkelm
88
Bayes- theorem (conditional
probabilities)
Pr a, b
Pr a, b
Pr a | b ˆ
; Pr b | a ˆ
Pr b
Pr a
Pr b | a . Pr a
Pr a | b
Pr b
• For discrete variables:
pb | a . pa
pa | b
pb
• Continuous:
• a discrete, b continuous:
pb | a . Pr a
Pr a | b
pb
Frigyes: Hírkelm
89
Comments
• 1. The Observation Space is N dimensional (N
is number of the observations).
•
The Decision Space is M-1 dimensional (M is
number of the hypotheses).
• 2. Explicitly we dealt only with independent
samples; investigation is much more
complicated is these are correlated
• 3. We’ll see that in digital transmission the case
N>1 is often not very important
Frigyes: Hírkelm
90
Basics of estimation theory:
parameter-estimation
• Task is to estimate unknown parameter(s)
of an analog or digital signal
• Examples: voltage measurment in noise
x s; r s n
•
digital signal; phase measurement
2
si t ai t cos c t
i ;
M
(i 0,1,... M 1)
Frigyes: Hírkelm
91
Basics of estimation theory:
parameter-estimation
• Frequency estimation
•
synchronizing an unaccurate oscillator
• Power estimation of interfering signals
•
interference cancellation (via the
antenna or multiuser detection)
• SNR estimation
• etc
Frigyes: Hírkelm
92
Basics of estimation theory:
parameter-estimation
• The parameter can be:
•
i. a random variable (pdf is assumed to be known) or
ii. means: we
•
ii. an unknown deterministic value
have no a-priori
• Model:
i. means: we have
knowledge about
some a-priori knowledge
its magnitude
Mapping to
OS
Domain of
the estimated
parameter
a
PARAMETER
SPACE
Frigyes: Hírkelm
pa(A)
Becslési
szabály
OBSERVATION
SPACE (OS)
âR
ESTIMATION
SPACE
93
Example – details (estimation 1)
• We want to measure
voltage a
• We know that a V
• And that Gaussian
noise is added
φ(r;0,σn2)
• Observable
parameter is r = a+n
R A2
1
• Mapping of the
pr |a R | A
exp
2
2 n
parameter to OS:
2 n
Frigyes: Hírkelm
94
Parameter estimation –parameter
is a RV
• Similar principle: estimation ha some cost; its
average is the risk; we want to minimize that
• realization of the parameter : a
• Observation vector: R
• Estimated value: â(R)
• Cost is in the general case a 2-variable function:
C(a,â)
• Error of the estimation is ε = a-â(R)
• Often the cost depnds only on that: C = C (ε)
Frigyes: Hírkelm
95
Parameter estimation –
parameter is a RV
• Examples:
0; / 2
C ; C ; C
1; / 2
2
• Risk is
K EC
C A aˆ R pa,r A, R dRdA
• Joint pdf can be
written:
pa ,r A, R pr R pa|R A | R
Frigyes: Hírkelm
96
Parameter estimation –
parameter is a RV
• Applying to the square cost function
(subscript ms: mean square)
2
pR A aˆ R pa|r A | R dAdR
K ms
• K=min (i.e. dK / daˆ 0)where the inner
integral = min (as the outer is i. pozitiv and
ii. does not depend on A); this holds where
Frigyes: Hírkelm
97
Parameter estimation –
parameter is a RV
d
2
ˆ
A
a
R
pa|r A | R dA
daˆ
2 Ap a|r A | R dA 2aˆ R pa|r A | R dA 0
• The second integral =1, thus
aˆ R ms
Ap A | R dA
a|r
• i.e. a-posteriori expected value of a.
• (According to the previous definition : a-posteriori knowledge: what
is gained from measurement/investigation.)
Frigyes: Hírkelm
98
Comment
• Comming back to the risk:
K ms
2
ˆ
p r R dR A aR pa|r A | R dA
• Inner integral is now: the conditional
variance, σa2(R). Thus
2
2
•
K p R R dR E
ms
r
a
a
Frigyes: Hírkelm
99
Parameter estimation –
parameter is a RV
• An other cost function: 0 in a band Δ
elsewhere 1. The risk is now
Δ
aˆ R 2
K un pr R dR 1 pa|r A | R dA
aˆ R 2
• (un: uniform)
• K=min, if result of the estimation is
maximum of the conditional pdf (if Δ is
small): max. a-posteriori – MAP-estimation
Frigyes: Hírkelm
100
Parameter estimation –
parameter is a RV
• Than derivative of the log conditional
pdf=0
ln p A | R
0
a|r
A
A aˆ R
• (so called MAP-equation)
• Applying Bayes-theorem log-cond. pdf
can be written
p R | A. p A
pa|r A | R
r |a
pr R
a
ln pa|r A | R ln pr|a R | A ln pa A ln pr R
Frigyes: Hírkelm
101
Parameter estimation –
parameter is a RV
• First term is the statistical relationship between
A-R
• Secnd is the a-priori knowledge
• Last term does not depend on A.
• Thus what is maximal is
l A ˆ ln pr|a R | A ln pa A
• And so the MAP equation is:
ln pr|a R | A ln pa A
A aˆ R , ahol :
0
A
A
Frigyes: Hírkelm
102
Once again
• Minimum Mean Square Error (MMSE)
estimate is the average of the a-posteriori.
pdf
• Maximum a-posteriori (MAP) estimate is
the maximum of the a-posteriori. pdf
Frigyes: Hírkelm
103
Example (estimate-2)
• Again we have Gauss
ian a+n, but N
independent samples 1
A2
pa ( A)
exp
2
2 a
2 a
N
pr|a R | A
i 1
2
Ri A
1
exp
2
2 a
2 n
• What we need to p A | R pr|a R | A pa A
a |r
pr R
(any) estimate is
Frigyes: Hírkelm
104
Example (estimate-2)
• Note that p(R) is constant from the point of
view of the conditional pdf, thus its form is
irrelevant.
• Thus
N
2
Ri A
1
A2
1 i 1
pa|r A | R k1 R
exp
2
N
2
n
a
2
2 a 2 n
i 1
Frigyes: Hírkelm
105
Example (estimate-2)
• This is a Gaussian distribution and we need its
expected value. For that the square must be
completed in the exponent, resulting in
1
pa|r A | R k 2 R exp
2
2
2
with 2
Frigyes: Hírkelm
a
1
A 2
2
a n N N
2
a n
2
2
N a n
2
2
Ri
i 1
N
2
106
2
Example (estimate-2)
• In Gaussian pdf average = mode thus
a2
1 N
aˆms R aˆmap R 2
Ri
2
a n / N N i 1
Frigyes: Hírkelm
107
Example (estimate-3)
• a is now also φ(A;0,σn2), but only
s(A), a nonlinear function of it can be
observed (e.g. phase of a carrier);
noise is added: ri s A ni
• Az a-posteriori sűrűségfüggvény
N
2
Ri s A
2
1 i 1
A
pa|r A | R k R exp
2
2
2
n
a
Frigyes: Hírkelm
108
Példa (becslés-3)
• Remember: the MAP equation:
ln pr|a R | A ln pa A
A aˆ R , ahol :
0
A
A
• Aplying that to the preceding
a
aˆ MAP R 2
n
2
Frigyes: Hírkelm
s A
Ri s A A
i 1
N
109
Parameter estimation – the
parameter is a real constant
• In that case it is the measurement result what is
a RV. E.g. in the case of a square cost function
the risk is:
2
ˆ
K A aR A pr|a R | AdR
• This is minimal if â(R)=A. But this has no sense:
that’s the value what we want to estimate.
• In that case – i.e. if we have no a-priori
knowledge – the method can be:
• we search for a function of A – an estimator –
which is „good” (has average close to A and low
Frigyes: Hírkelm
110
variance)
Közbevetve: a tételek eddig
• 1. Sztohasztikus folyamatok: főként a
fogalmak definiciója
• (sztoh. foly.; val. sűrűségek-eloszlások, erős
stacioanaritás; korrelációs fv. gyenge
stacionaritás, időátlag, ergodicitás spektrális
sűrűség, lin. transzformáció)
• 2. Modulált jelek – komplex burkoló
• (mod. jelek leírása, időfüggv., analitikus függv.
(frekv-idő) komplex burkoló, egyikből a másik,
szűrő)
Frigyes: Hírkelm
111
Közbevetve: a tételek eddig/2
• 3. A döntéselmélet alapjai
• (Milyen feladatok; költség, kockázat, a-priori val,
Bayes-f. döntés; a megfigyelési tér opt.
felosztása, küszöb, elégséges statisztika, M
hipotézis (nem kell rész-letezni, csak az
eredmény), a-post. val.)
• 4. A becsléselmélet alapjai
• (Val.-vált paraméter, költségfüggv. min. ms. max.
a-post.; determ. param, likelyhood fv. ML, MVU
becslés, torzítatlan; Cramér-Rao; hatékony)
Frigyes: Hírkelm
112
Parameter estimation – the parameter is
a real constant – criteria for the estimator
• Average of the – somehow chosen – estimator:
A
Eâ R ˆ â R p r|A R | A dR A B
A B(A)
• If this is = A: unbiased estimate; operation of
estimation is searching of the average
• If bias B is constant: can be subtracted from the
average (e.g. in optics: background radiation)
• if B=f(A): biased estimate
Frigyes: Hírkelm
113
Parameter estimation – the parameter is
a real constant – criteria for the estimator
• Error variance:
aˆ R A E aˆ R A B 2 A
2
•
•
•
•
•
•
•
•
2
2
Best would be:
unbiased and
low variance
more precisely: unbiased and minimális variance
for any A (MVU)
Such estimator does or does not exist
An often applied estimator: maximum likelihood
Likelihood function.: pr|a R | A as a function of A
Estimator of A then: maximum of the likelihood function
Frigyes: Hírkelm
114
A few of details
This is certainly better
than that:
variance of the
measuring result is lower
Θ
Further:
Frigyes: Hírkelm
115
Max. likelihood (ML) estimation
• Necessary condition of max of ln likelihood
A aˆ R , ahol :
ln pr|a R | A
A
0
• Remember: in the case of a RV: MAP estimate
ln pr|a R | A ln pa A
A aˆ R , ahol :
0
A
A
• Thus: ML is the same without a-priori knowledge
Frigyes: Hírkelm
116
Max. likelihood (ML) estimation
• For any unbiased estimate: variance cannot be lower
than Cramér-Rao lower bound, CRLB,
2 aˆ R A
ln p R | A
r|a
E
A
2
1
• or an other form:
ln pr|a R | A
-E
2
A
2
2 aˆ R A
Frigyes: Hírkelm
1
117
Max. likelihood (ML) estimation
• Proof of CRLB: via Schwartz- unequality
• If the estimate is equal to CRLB: efficient
estimate.
Example of existing MVU
but no (or unknown)
efficient estimate
(var θ^1>CRLB)
Frigyes: Hírkelm
118
Example 1 (estimation,
nonrandom)
• Voltage + noise, but the voltage is a real,
nonrandom
• Max likelihood estimation
ri A ni ; i 1,2,... N ; pn (n) n;0, n
ln pr| A
N 1
2
A
n N
1 N
aˆ ML R Ri
N i 1
Frigyes: Hírkelm
2
Ri A 0
i 1
N
119
Example 1 (estimation,
nonrandom)
• Is it biased??
1 N
1
Eaˆ ML R ERi NA A
N i 1
N
• Expected value of â is the (a-priori not
known) true value; i.e. it is unbiased
Frigyes: Hírkelm
120
Example 2 (estimation,
nonrandom): phase of a sinusoid
• What can be measured is a function of the
quantity to be estimated
• (Independent Samples are taken at equal
times)
• A likelyhood function to be maximized:
Frigyes: Hírkelm
121
Example 2 (estimation,
nonrandom): phase of a sinusoid
• This is = max, if the function below = min
•
=0
• The righthand side tends to 0, with large N
Frigyes: Hírkelm
122
Example 2 (estimation,
nonrandom): phase of a sinusoid
• And then finally:
Frigyes: Hírkelm
123
2. Transmission of digital signals
over analog channels: effect of
noise
Introductory comments
• Theory of digital transmission is (at least
partly) application of decision theory
• Definition of digital signals/transmission:
•
Finite number of signal shapes (M)
•
Each has the same finite duration (T)
•
The receiver knows (a priori) the signal
shapes (they are stored)
• So the task of the receiver is hypothesis
testing.
Frigyes: Hírkelm
125
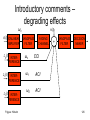
Introductory comments –
degrading effects
ωc
s(t)NONLINEAR
AMPLIFIER
n(t)
BANDPASS
FILTER
FADING
CHANNEL
z0(t)
ωc
z1(t)
ω1
ACI
ω2
ACI
INTERFERENCE
INTERFERENCE
z2(t)
INTERFERENCE
Frigyes: Hírkelm
+
BANDPASS
FILTER
DECISION
MAKER
CCI
126
Introductory comments
• Quality parameter: error probability
• (I.e. the costs are:
•
Cii 0; Ci k 1; i, k 1,2,..., M )
• Erroneous decision may be caused by:
•
additíve noise
•
linear distortion
•
nonlinear distortion
•
additive interference (CCI, ACI)
•
false knowlledge of a parameter
•
e.g. synchronizing error
Frigyes: Hírkelm
127
Introductory comments
• Often it is not one signal of which the error
probability is of interest but of a group of
signals – e.g. of a frame.
• (A secondquality parameter: erroneous
recognition of T : the jitter.)
Frigyes: Hírkelm
128
Transmission of single signals in
additive Gaussian noise
• Among the many sources of error now we
regard only this one
• Model to be investigated:
TIMING (T)
n(t)
SIGNAL
GENERATOR
SOURCE
{mi}, Pi
Frigyes: Hírkelm
mi
+
si(t)
ˆm
DECISION
MAKER
SINK
r(t)= si(t)+n(t)
129
Transmission of single signals in
additive Gaussian noise
•
Specifications:
• a-priori probabilities Pi are known
• support of the real time finctions s t is
i
•
(0,T)
•
their energy is finite (E: square integral
of the time functions)
mi si t relationship is mutual and
•
unique (i.e. there is no error in the
transmitter)
Frigyes: Hírkelm
130