Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Statistical inference
• Population - collection of all subjects or objects of interest
(not necessarily people)
• Sample - subset of the population used to make inferences
about the characteristics of the population
• Population parameter - numerical characteristic of a
population, a fixed and usually unknown quantity.
• Data - values measured or recorded on the sample.
• Sample statistic - numerical characteristic of the sample
data such as the mean, proportion or variance. It can be
used to provide estimates of the corresponding population
parameter
POINT AND INTERVAL ESTIMATION
• Both types of estimates are needed for a given problem
• Point estimate: Single value guess for parameter e.g.
1. For quantitative variables, the sample mean X provides a
point estimate of the unknown population mean
2. For binomial, the sample proportion is a point estimate of
the unknown population proportion p.
• Confidence interval: an interval that contains the true
population parameter a high percentage (usually 95%) of
the time
• e.g. X= height of adult males in Ireland,
• = avg. height of all adult males in Ireland
• Point estimate: 5’10” 95 % C.I. : (5’ 8”, 6’0”)
Bias
• The sampling distribution determines the expected value
and variance of the sampling statistic.
• Bias = distance between parameter and expected value of
sample statistic.
• If bias = 0, then the estimator is unbiased
• Sample statistics can be classified as shown in the
following diagrams.
Low bias -high variability
Bias and variability
When can bias occur ?
• If the sample is not representative of the population being
studied.
•
To minimise bias, sample should be chosen by random
sampling, from a list of all individuals (sampling frame)
• e.g. Sky News asks: Do British people support lower fuel
prices ? Call 1-800-******* to register your opinion ?
• Is this a random sample ?
• In remainder of the course, we assume the samples are all
random and representative of the population, hence the
problem of bias goes away. Not always true in reality.
Convergence of probability
• Recall Kerrich's coin tossing experiment- In 10,000 tosses
of a coin you'd expect the number of heads (#heads) to
approximately equal the number of tails
• so #heads ½ #tosses
• (#heads - ½ #tosses) can become large in absolute terms as
the number of tosses increases (Fig 1).
• in relative terms ( % of heads - 50%) -> 0 (Fig 2).
Law of Averages
• as #tosses increases, you can think of this as
#heads = ½ #tosses + chance error
where chance error becomes large in absolute terms but small
as % of #tosses as #tosses increases.
• The Law of Averages states that an average result for n
independent trials converges to a limit as n increases.
• The law of averages does not work by compensation. A run
of heads is just as likely to be followed by a head as by a
tail because the outcomes of successive tosses are
independent events
Law of Large Numbers
• If X1,X2,….,Xn are independent random variables all with
the same probability distribution with expected value µ and
variance s 2 then
is very likely to become very close to µ as n becomes very large.
•Coin tossing is a simple example.
•Law of large numbers says that:
•But how close is it really ?
Sampling from exponential
1.0
Exponential distribution
0.217 1.372 0.125 0.030 0.221
0.430 0.986 0.131 1.345 0.606
0.889 0.113 1.026 1.874 3.042
0.2
0.4
0.6
=1
s2=1
0.0
0
2
4
……………………… ………
6
seq(0, 7, 0.01)
4000
Histogram of 10000 samples
from exponential distribution
3000
> mean(popsamp)
2000
[1] 0.9809146
1000
> var(popsamp)
[1] 0.9953904
0
exp1pop
0.8
Draw a sample
0
2
4
popsamp
6
8
1500
0
……………………… ………
1000
0.217 1.372 0.125 0.030 0.221
0.430 0.986 0.131 1.345 0.606
0.889 0.113 1.026 1.874 3.042
Histogram of means
of size 2 samples
500
Population
Samples of size 2
0
1
2
3
4
mss2
> mean(mss2)
Sample 1: 0.217 1.372 x1 = 0.795
Sample 2: 0.125 0.030 x2 = 0.078
Sample 3: 0.217 0.889 x3 = 0.553
…………………….
[1] 0.9809146
> var(mss2)
[1] 0.4894388
5
Samples of size 5
400
300
200
0
……………………… ………
100
0.217 1.372 0.125 0.030 0.221
0.430 0.986 0.131 1.345 0.606
0.889 0.113 1.026 1.874 3.042
Histogram of means
of size 5 samples
0
1
2
3
mss5
Sample 1: 0.217 1.372 0.125 0.030 0.221 x1 = 0.393
Sample 2: 0.217 1.372 0.131 1.345 0.606 x2 = 0.628
Sample 3: 0.889 0.113 1.026 1.874 3.042 > mean(mss5)
…………………….
[1] 0.9809146
> var(mss5)
[1] 0.201345
Sampling Distributions
• Different samples give different values for sample
statistics. By taking many different samples and
calculating a sample statistic for each sample (e.g. the
sample mean), you could then draw a histogram of all the
sample means. A statistic from a sample or randomised
experiment can be regarded as a random variable and the
histogram is an approximation to its probability
distribution. The term sampling distribution is used to
describe this distribution, i.e. how the statistic (regarded as
a random variable) varies if random samples are repeatedly
taken from the population.
• If the sampling distribution is known then the ability of
the sample statistic to estimate the corresponding
population parameter can be determined.
Sampling Distribution of the Sample Mean
• Usually both µ and s are unknown, and we want primarily
to estimate µ.
From the sample we can calculate x and s
•The sample mean is an estimate of µ, but how accurate ?
•Sampling distribution depends on sample size n:
Sampling distribution of sample mean
Histogram of means
of size 2 samples
0
0
1000
500
2000
1000
3000
1500
4000
Histogram of 10000 samples
from exponential distribution
0
2
4
6
8
0
popsamp
1
2
3
4
5
mss2
Histogram of means
of size 10 samples
250
0
0
100
50
100
200
150
300
200
400
Histogram of means
of size 5 samples
0.5
0
1
2
mss5
3
1.0
1.5
mss10
2.0
2.5
Sampling distribution of sample mean
Mean of sample means vs.
sample size
0.5
20
30
1.0
40
1.5
50
2.0
60
Histogram of means
of size 50 samples
0
0.0
10
Sample mean is unbiased
0.6
0.8
1.0
1.2
0
1.4
20
40
60
80
100
n
mss50
Var of sample means vs.
sample size
0
20
40
60
n
80
100
0.0
0.0
0.2
0.5
0.4
0.6
V ( xn ) n
1.0
1
V ( xn )
n
0.8
1.5
1.0
2.0
Var of sample means vs.
inverse of sample size
0.0
0.2
0.4
0.6
1/n
0.8
1.0
Central Limit Theorem
• The Central Limit Theorem says that the sample mean is
approximately Normally distributed even if the original
measurements were not Normally distributed.
s2
X N , as
n
n
0.0
0.05
0.10
0.15
0.20
0.25
0.30
regardless of the shape of the probability distributions
of X1, X2, ... .
Distributions of chi-squared means
0
2
4
6
ordinate
8
10
Properties of sample mean
s2
CLT : X N , as
n
n
• The sample mean is always unbiased
•As n increases, the distribution becomes narrower - that
is, the sample means cluster more tightly around µ. In
fact the variance is inversely proportional to n
•The square root of this variance, is called the
"standard error" of
s
X : SE( X ) =
n
This gives accuracy of the sample mean
Generating a sampling distribution
• Step 1: Collect samples of size n (=5) from distribution F:
xsample_rnorm(5000)
xsample_matrix(xsample,ncol=5)
> xsample[1,]
[1] -0.9177649 -1.3931840 -1.6566304 -0.6219027 -1.834399
xsample[10,]
[1] 0.3239556 -0.3127396 -1.3713074 0.9812672 -0.918144
• Step 2: Compute sample statistic
for( i in 1:1000){samplemean[i]_mean(sample[i,])}
> samplemeans[1]
[1] -1.284776
• Step 3: Compute histogram of sample statistics
hist(samplemean)
0
50
100
150
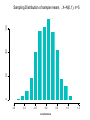
Sampling Distribution of sample means , X~N(0,1), n=5
-1.5
-1.0
-0.5
0.0
samplemeans
0.5
1.0
1.5
Sampling distribution of s2
1 n
2
s =
(
x
x
)
is the sample variance
i
n 1 i =1
2
• What is it’s sampling distribution ?
If X i are i.i.d N( , s 2 ) then X i2 ~ 12
•Sums of squares of i.i.d normals are chi-squared
with as many d.f. as there are terms.
X 12 X 22 ~ 22 etc.
s 2 = Y12 Y22 ... Yn21 , Yi i.id. N(0, s 2 )
If X i are i.i.d N(0,1) then
(n 1) s 2
s2
~ n21
Density of Z^2
3
0
0.0
1
2
f(x)
0.2
0.1
f(x)
0.3
4
0.4
Density of Z
-4
-2
0
2
4
0
1
X
2
3
4
X
Sampling Distribution of sample variances , X~ N(0,1), n= 5
0
0.0
100
0.05
f(x)
200
0.10
300
0.15
Chisquared densities
0
20
40
60
X
80
100
0
1
2
3
samplevars
4
5