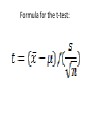Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Chapter 10: A First Look at Empirical Testing: Creating a Valid Research Design • Throughout this class we have argued that research involves creating a persuasive argument and that researchers persuade by providing theoretical and empirical evidence that supports their thesis. This chapter will explain how to develop convincing empirical evidence. Key Issues of Research Design: • Let’s imagine that we hava an interesting research question. We have reviewed the literature on the topic area. We have analyzed the issue using economic theory, and from that theoretical analysis we have derived our hypothesis. And what’s next? The answer is an easy one: testing our hypothesis! We need to consider a number of key issues. Two Types of Empirical Methodology: • Experimental and survey (nonexperimental) methods are available for the researchers. The first is illustrated by laboratory experiments. Let’s give an example. Imagine that we have two groups: an intervention (treatment) group and a control group. These two groups are designed identically except for the treatment. Thus, if the experiment between the two groups yields different outcomes, then that difference can be attributed to the treatment. • In economics we generally use survey or nonexperimental method. This procedure involves the passive observation and analysis of events as they occur in nature. For example, instead of the central bank (CB) inducing a recession, and then analysing the outcomes, economists of the CBs use data on recessions as they have occured in history to investigate their cause and effects. • Another significant factor in an empirical study is the degree to which the methodology is valid. The validity of the study has multiple dimensions. In the broadest sense, we must consider internal and external validity. What is internal validity? • The study has an internal validity if the impact observed can be attributed to the study variable. Let’s give an example. Assume that we have 2 identical classes except for the textbook used during the lectures. If our experiment has internal validity, the difference in grades between the two class sections is attributable to the different textbooks (i.e. X causes Y) The Components of Internal Validity: • The three important elements to be considered are: (i) instrument validity, (ii) relationship validity, and (iii) causal validity. Let us explain one by one. • Instrument validity asks whether the test instrument appropriately measures what it aims to. For instance, as researchers we generally experience some problems in finding the ideal data. Most of the time, we find ourselves asking the following questions: Are the data sufficient for our purpose? Do they serve as appropriate proxies for the theoretical framework? • Relationship validity asks how conclusive (decisive, irrefutable) the empirical testing was. Was the test appropriate and reasonable? In other words, if we have relationship validity, one can conclude based on our empirical tests that there is in fact a real statistical retationship. • Causal validity observes that since correlation does not imply causation can one be sure that the hypothesized causal relationship is valid? Can one be sure that the causation does not go in the opposite direction? Or can we suspect that there is no causation whatsoever? External validity? • Once we have established the internal validity, we need to ask whether our results or findings can be generalized to other situations, applications, or circumstances. If so, we have external validity. For example, suppose a study found a positive relationship between class attendance and high grades for a certain class. Would the same result hold for other class sections? If so, one can conclude that our study has external validity. How about an alternative hypothesis? • Our research aims to develop an argument by using logic and evidence in favor of our hypothesis. The point is that the data in the real world may be consistent with alternative hypotheses. So, we have to adopt an empirical procedure which would enable us to distinguish between our and alternative hypotheses. The power of a test: • Statisticians define the power of a test as the probability of correctly rejecting a null hypothesis when it is not true. So, we always have to ask the following question: how confident can I be that my hypothesis is confirmed? In other words, will the test appropriately distinguish between my hypothesis and alternatives? If not, then I should choose a more powerful testing procedure. How can we analyse the data? • At that specific point it is time to ask the following question: if our hypothesis is true, what evidence should one expect to see? The answer to this question is called the theoretical prediction of the analysis. Let’s make it clear by giving an example: • Think about how doctors look for symptoms to identify an illness. You visit the doctor’s office, saying you think you have the flu. The doctor thinks to himself: “if she/he has the flu, she/he should show the following symptoms: headache, fatigue, fever. So, the doctor will ask you: “what are your symptoms?” since the symptoms will allow the doctor to make a diagnosis. In the same way, it is the predictions of the theory that allow the researcher to test his/her analysis. Causal Empiricism It includes printing and graphing data, calculating descriptive statistics, and visually examining the results. It is quite easy to understand and perform. For example, Phillips curve hypothesis suggests that there is a negative relation between inflation and unemployment rates. This pathbreaking macroeconomic relationship was discovered by a simple visual examination of the data (i.e. by casual empiricism). Descriptive Statistics • Any data can be described in terms of its descriptive statistics. One can think of the descriptive statistics as statistics that summarize the data. Descriptive statistics include measure of central tendency and measures of dispersion (Remember that dispersion is the degree of scatter of data about an average value, such as the median). Descriptive Statistics (continued) • If we have to summarize the data using only one measure, what should we use? The answer is an average. There are 3 commonly used measures of central tendency or averages: (i) mean or arithmetic average, (ii) median or middle value in the sample, (iii) mode or most common or frequently occuring value in the sample. Descriptive Statistics (continued) • There are 3 commonly used measures of dispersion: (i) range between the highest and lowest values in the data sample, (ii) standard deviation, that roughly measures the average amount by which a data point differs from the mean value of the sample, (iii) variance, the square of the standard deviation. More on descriptive statistics: • We as researchers often assume that our data is normally distributed (the well-known bellshaped graph!). If so, all three measures of central tendency or averages will converge. If not, they can differ substantially, so we need to be careful about which measure of the average to report (Ex.: for personal income data we may choose median due to the reason that the data may not be normally distributed). Covariance and correlation? • The relationship between two variables is evaluated by examining the covariance. It shows how 2 variables change together. It is related mathematically to the standard deviation and the variance. However, researchers often use a closely related concept: correlation. It measures the degree of linear association (relationship) between 2 variables. Covariance and correlation? (continued) • Correlation ranges from +1 to -1, measuring both the direction and strength of the linear relationship. For example, -0.95 indicates a strong negative linear relationship. Random variation in human behavior • We face 3 major problems during the data analysis: (i) the effects of random variation in human behavior, (ii) the fact that relationships between 2 variables can be concealed by the effects of other variables, (iii) causal validity, the fact that correlation and causation do not imply the same thing. Random variation in human behavior (continued) • This variation creates a problem for relationship validity because the effects of random variation can hide or obscure any underlying relationships. In order to cope with this problem 2 questions should be answered: (i) is the sample large enough to show any underlying relationship in the data, (ii) is the sample random? Let’s explain in details. Random variation in human behavior (continued) • Most social science statistics are based on sample data rather than population data. So, the data set should represent the underlying population data. A true underlying relationship may be obtained by taking a large random sample of the data. Random variation in human behavior (continued) How large a sample is large enough? Strictly speaking, the sample should include 30 or more random data points. Naturally, it is difficult and expensive to acquire a truly random sample. If the data is not large enough or random enough we may have the problem of sampling error. In such a case, the relationship that we find between the 2 variables would not reflect the true relationship. Statistical Methods • When employing statistical methods it is critical to differentiate between the null hypothesis and the alternative (maintained) hypothesis. The latter is the theoretical prediction of the model. When we test the theory, we test the null. For this reason it is sometimes called as the statistical hypothesis. Let’s give an example. Statistical Methods (continued) • Assume that we formulate the relationship between consumption (C) and income (Y) as follows: • C = bY + e • The null in here is that parameter b is zero. The maintained hypothesis is that b is not zero. Even if the null is true, there is a chance that the data for a sample will show a relationship where an estimate of b will be nonzero. Such result would support the alternative hypothesis. Statistical Methods (continued) • How certain do we need to be to reject the null in favor of the alternative? The answer is called the level of significance. It is the risk taken by the researcher that the null will be rejected when it is true. It is the probability that the researcher will accept (not reject) the alternative hypothesis when it is not true. If the level of significance is 5%, then we will risk a 5 % chance that we will reject the null when it is true. Similarly, there is a 95% chance that we will not reject the null when it is true. Statistical Hypothesis Testing • Suppose that we want to know whether the mean of some sample is significantly different from the default mean. For example, we can investigate whether the average unemployment rate among high school dropouts (i.e., the sample mean) is different from that of the labor force in general (i.e., the default mean). We can use a t-test. Formula for the t-test: Formula for the t-test: (continued) • “X bar” is the average unemployment rate among the dropouts. • “Mu” is the unemployment rate in the general labor force. • “s” is the standard deviation of the unemployment rate among the dropouts. • “Square root n” is the square root of the sample size of the data set. Formula for the t-test: (continued) • The null in this example is that the mean unemployment rate among the dropouts is NOT significantly different from that of the labor force in general. What we have to do in here is to calculate the t-statistic by using the abovementioned formula. And then, we compare the estimated t with the critical t value for a certain level of statistical significance (1%, 5%). Formula for the t-test: (continued) • If the calculated t value is greater than the critical t value, then we should reject the null. Which means that the probability of the sample mean being the same as the default mean is LOW. The P-Value: • This is an alternative approach to performing t-tests. The p-value is the exact or the observed level of significance. If the observed probability is smaller than the level of significance, the null should be rejected. Confounding of explanatory variables: • We have mentioned that we face 3 major problems during the data analysis. The second one was the fact that relationships between 2 variables can be concealed by the effects of other variables. This problem is called the confounding of explanatory variables. It affects both causal empiricism and t-tests. Let us give an example. Confounding of explanatory variables: (continued) • Now, assume that C is affected by another variable, interest rates (i). The equation for C becomes: • C = b1Y + b2i + e • Now, suppose that interest rates noticeably decreased, while income did not. Remember that we had Y in the horizontal axis and C in the vertical axis. So, the decrease in i would lead to a shift in the C function, rather than a movement along the function. Confounding of explanatory variables: (continued) • To appropriately measure the relationship between C and Y, we must take into consideration i, which has its own effect on C. Thus, a control variable is what is held constant in a study (remember the famous “ceteris paribus” assumption when we are sketching a demand curve). The 3rd problem: causal validity • We have a higher ability to control for the outside factors in experimental designs in comparison with the survey (nonexperimental) designs. For this reason, the first is said to be more powerful for determining causation. Survey designs usually establish correlation or association (not causation!).