Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
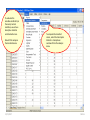
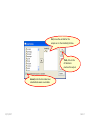
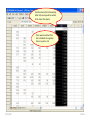
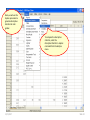
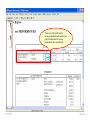
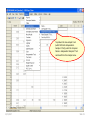
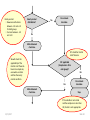
SOLVING THE PROBLEM The one sample t-test compares two values for the population mean of a single variable. The two-sample test of a population means compares the population means for two groups of subjects on a single variable. The null hypothesis for this test is: there is no difference between the population mean of the variable for one group of subjects and the population mean of the same variable for a second group of subjects. In addition to our concern with the assumption of normality for each group and the number of cases in each group if we are to apply the Central Limit Theorem, but this test also requires us to examine the spread or dispersion of both groups so that the measure of standard error used in the t-test fairly represents both group. While there is a test of Equality of Variance and a formula to use when the test is satisfied and a formula to use when the test is violated, the authors of our text suggest we always use the formula that assumes the test is violated. If we use this version of the statistic when the variances are in fact equal, the results of the test are comparable to what we would obtain using the formula for equal variances. We will the authors advice and restrict our attention to the “Equal variances not assumed” row in the SPSS output table without examining the Levene test of equality of variance. 5/25/2017 Slide 1 The introductory statement in the question indicates: • The data set to use (GSS2000R) • The variables to use in the analysis: socioeconomic index [sei] for groups of survey respondents defined by the variable sex [sex] • The task to accomplish (two-sample t-test for the difference between sample means) • The level of significance (0.05, two-tailed) 5/25/2017 Slide 2 The first statement asks about the level of measurement. A two-sample t-test for the difference between sample means requires a quantitative dependent variable and a dichotomous independent variable. 5/25/2017 Slide 3 "Socioeconomic index" [sei] is quantitative, satisfying the level of measurement requirement for the dependent variable. "Sex" [sex] is dichotomous, satisfying the level of measurement requirement for the independent variable. Mark the statement as correct. 5/25/2017 Slide 4 To justify the use of probabilities based on a normal sampling distribution in testing hypotheses, either the distribution of the variable must satisfy the nearly normal condition or the size of the sample must be sufficiently large to generate a normal sampling distribution under the Central Limit Theorem. A two-sample t-test for the difference between sample means requires that the distribution of the variable satisfy the nearly normal condition for both groups. We will operationally define the nearly normal condition as having skewness and kurtosis between -1.0 and +1.0 for both groups, and not having any outliers with standard scores equal to or smaller than -3.0 or equal to or larger than +3.0 in the distribution of scores for either group. 5/25/2017 Slide 5 To evaluate the variables conformity to the nearly normal condition, we will use descriptive statistics and standard scores. We will first compute the standard scores. 5/25/2017 To compute the standard scores, select the Descriptive Statistics > Descriptives command from the Analyze menu. Slide 6 First, move the variable for the analysis sei to the Variable(s) list box. Third, click on the OK button to produce the output. Second, mark the check box Save standardized values as variables. 5/25/2017 Slide 7 Sort the column Zsei in ascending order to show any negative outliers at the top of the column. There were no outliers that had a standard score less than or equal to -3.0. 5/25/2017 Slide 8 Sort the column Zsei in descending order to show any positive outliers at the top of the column. There were no outliers that had a standard score greater than or equal to +3.0. 5/25/2017 Slide 9 Next, we will use the Explore procedure to generate descriptive statistics for each gender.. To compute the descriptive statistics, select the Descriptive Statistics > Explore command from the Analyze menu. 5/25/2017 Slide 10 First, move the dependent variable sei to the Dependent List. Fourth, click on the OK button to produce the output. Second, move the group variable sex to the Factor List. Third, mark the option button to display Statistics only. 5/25/2017 Slide 11 For survey respondents who were male, "socioeconomic index" satisfied the criteria for a normal distribution. The skewness of the distribution (0.539) was between -1.0 and +1.0 and the kurtosis of the distribution (-0.852) was between -1.0 and +1.0. 5/25/2017 Slide 12 For survey respondents who were female, "socioeconomic index" satisfied the criteria for a normal distribution. The skewness of the distribution (0.610) was between -1.0 and +1.0 and the kurtosis of the distribution (-0.921) was between -1.0 and +1.0. 5/25/2017 Slide 13 For survey respondents who were male, "socioeconomic index" satisfied the criteria for a normal distribution. The skewness of the distribution (0.539) was between -1.0 and +1.0 and the kurtosis of the distribution (-0.852) was between -1.0 and +1.0. For survey respondents who were female, "socioeconomic index" satisfied the criteria for a normal distribution. The skewness of the distribution (0.610) was between -1.0 and +1.0 and the kurtosis of the distribution (-0.921) was between -1.0 and +1.0. There were no outliers that had a standard score less than or equal to -3.0 or greater than or equal to +3.0. Mark the statement as correct. 5/25/2017 Slide 14 Though we have satisfied the nearly normal condition and do not need to utilize the Central Limit Theorem to justify the use of probabilities based on the normal distribution, we will still examine the sample size. To apply the Central Limit Theorem for a two-sample t-test for the difference between sample means requires that both groups defined by the independent variable have 40 or more cases. 5/25/2017 Slide 15 There were 110 valid cases for survey respondents who were male and 145 valid cases for survey respondents who were female. 5/25/2017 Slide 16 Both groups had 40 or more cases, so the Central Limit Theorem would be applicable. However, since the distribution of "socioeconomic index" satisfied the nearly normal condition, we do not need to rely upon the Central Limit Theorem to satisfy the sampling distribution requirements of a two-sample t-test for the difference between sample means. Mark the statement as correct. 5/25/2017 Slide 17 The next statement asks us to identify the mean for each group in the sample data and the standard error of the sampling distribution. To answer this question, we need to produce the output for the two-sample t-test. 5/25/2017 Slide 18 To produce the two-sample t-test (which SPSS calls IndependentSamples T-Test), select the Compare Means > Independent Samples T Test command from the Analyze menu. 5/25/2017 Slide 19 First, move the variable sei to the Test Variable(s) list box. Second, move the grouping variable sex to the text box. SPSS adds ?’s after the variable name to remind us that we need to specify the numeric codes for the groups. 5/25/2017 Third, click on the Define Groups button to enter the group codes. Slide 20 First, enter 1 for males as Group 1. Third, click on the Continue button to close the dialog box. First, enter 2 for females as Group 2. If I did not remember the code numbers for male and female, I would look them up in the Variable View of the SPSS Data Editor. 5/25/2017 Slide 21 Third, click on the OK button to produce the output. SPSS replaces the question marks with the codes I entered. 5/25/2017 Slide 22 The mean "socioeconomic index" for survey respondents who were male was 50.29 and the mean for survey respondents who were female was 47.51 5/25/2017 The standard error of the differences between group means was 2.446. Slide 23 The mean "socioeconomic index" for survey respondents who were male was 50.29 and the mean for survey respondents who were female was 47.51. The standard error of the differences between group means was 2.446. Mark the question as correct. 5/25/2017 Slide 24 The next statement asks us about the null hypothesis for the one-sample t-test. We should check to make certain the relationship is stated correctly. 5/25/2017 Slide 25 The null hypothesis for the test is: there is no difference between the population mean of "socioeconomic index" for survey respondents who were male and the population mean of "socioeconomic index" for survey respondents who were female. Since the hypothesis is stated correctly, mark the question as correct. 5/25/2017 Slide 26 The next statement asks us to relate the t-test to the data in our problem. 5/25/2017 Slide 27 Following the convention in the text book, we will only focus on the “Equal variances not assumed” option. Within this option, the difference and standard error are correctly identified. 5/25/2017 The t-test statistic is based on the difference between the means of the two groups (2.777) relative to the standard error of the differences between sample means (2.446). Slide 28 The statement is correct and contains the correct values for both the difference in means and the sampling error that we would typically expect to find in the sampling distribution for differences in means. Mark the statement as correct. 5/25/2017 Slide 29 The next statement asks about the probability for the comparison made by the t-test. i.e. what is the probability that the population means for each group are not different. In the last question, the difference in means was only slightly larger than the standard error of the differences, so we should expect a ratio near one and a high value for the probability. 5/25/2017 Slide 30 The probability that the population mean for survey respondents who were male (50.3) was not different from the population mean for survey respondents who were female (47.5) was p = .257. 5/25/2017 Slide 31 The probability that the population mean for survey respondents who were male (50.3) was not different from the population mean for survey respondents who were female (47.5) was p = .257. Since the probability was correctly stated, mark the question as true. 5/25/2017 Slide 32 When the p-value for the statistical test is less than or equal to alpha, we reject the null hypothesis and interpret the results of the test. If the p-value is greater than alpha, we fail to reject the null hypothesis and do not interpret the result. 5/25/2017 Slide 33 The p-value for this test (p = .257) is larger than the alpha level of significance (p = .050) supporting the conclusion to fail to reject the null hypothesis. The check box is not marked. 5/25/2017 Slide 34 The final statement asks us to interpret the result of our statistical test as a finding in the context of the problem we created. We only interpret the results when the null hypothesis is rejected. 5/25/2017 Slide 35 If we had a significant p-value, we would have looked at the means of the two groups to identify the direction of the relationship. 5/25/2017 Slide 36 Since we did not have a significant p-value, we cannot reject the null hypothesis and interpret the relationship. The check box is not marked. 5/25/2017 Slide 37 Dependent variable is quantitative? No Yes Independent variable is dichotomous? Do not mark check box. No Mark only “None of the above.” Stop. Yes Mark statement check box. 5/25/2017 Slide 38 Nearly normal: • Skewness and kurtosis between -1.0 and +1.0 for both groups • Z-scores between -3.0 and +3.0 Nearly normal distribution? No Do not mark check box. Yes Mark statement check box. CLT stands for Central Limit Theorem. CLT applicable (Sample size ≥ 40 in each group)? No Yes Mark statement check box. Do not mark check box. Stop. If the variable is not normal and the sample size is less than 40, the test is not appropriate. 5/25/2017 Slide 39 Nearly normal: • Skewness and kurtosis between -1.0 and +1.0 for both groups • Z-scores between -3.0 and +3.0 Nearly normal distribution? No Do not mark check box. Yes Mark statement check box. CLT stands for Central Limit Theorem. We will check the applicability of the Central Limit Theorem based on sample size, even when our data satisfies the nearly normal condition. CLT applicable (Sample size ≥ 40 in each group)? No Yes Mark statement check box. Do not mark check box. Stop. If the variable is not normal and the sample size is less than 40, the test is not appropriate. 5/25/2017 Slide 40 Sample means and standard error correct? No Do not mark check box. Yes Mark statement check box. H0: no difference between sample means No Do not mark check box. Yes Mark statement check box. 5/25/2017 Slide 41 T-test accurately described? No Do not mark check box. No Do not mark check box. Yes Mark statement check box. P-value (sig.) stated correctly? Yes Mark statement check box. 5/25/2017 Slide 42 Reject H0 is correct decision (p ≤ alpha)? No Do not mark check box. Stop. Yes We interpret results only if we reject null hypothesis. Mark statement check box. Interpretation is stated correctly? No Do not mark check box. Yes Mark statement check box. 5/25/2017 Slide 43