Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
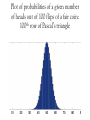
Statistical decision making Frequentist statistics frequency interpretation of probability: any given experiment can be considered as one of an infinite sequence of possible repetitions of the same experiment, each capable of producing statistically independent results. the frequentist inference approach to drawing conclusions from data is effectively to require that the correct conclusion should be drawn with a given (high) probability, among this notional set of repetitions. Sample mean and population mean X1, X2 ,…, Xn random events m= (X1+X2 +…+Xn )/n sample mean μ= true expected value of X. The central limit theorem implies that the sample mean should converge to the true mean. If n is large then with high probability, the sample mean is close to the true mean. How large is large? How close is close? Central limit theorem A sum of independent, identically distributed random variables is approximately normally distributed. Normal distribution: Some normal distributions Probability that variable takes value between a and b is the area under the graph Confidence interval One would like a relationship between N and the probability that m- μ is smaller than a given fixed value. Error: how precise do you need to be versus Probability of error: what risk are you willing to take that you are correct? Confidence interval example You want to know whether a coin is fair. You flip it 100 times. You observe that it comes up heads 60 times. Your question: what is the probability that it would come up heads 60 times (or more) if the coin is a fair coin? Plot of probabilities of a given number of heads out of 100 flips of a fair coin: 100th row of Pascal’s triangle The odds of 60 or more heads from 100 coin flips is about 3 percent. Fair coin example Example: Suppose that a coin has an unknown probability r of landing on heads. Bayesian approach: compute the posterior probability, assuming a uniform prior distribution… F(f|H)=[(N+1)!/H!(N-H)!] r^H (1-r)^(N-H). The best estimate of r is H/N. The error margin is (H+1)/(N+2). One needs a course in calculus to understand the nature of the error! Confidence intervals Hypothesis: the expected value of h, the proportion of trials on which the coin should land on heads in the long run, will be within a certain error of the sample average, with high probability. E: experiment of repeating the coin flip N times H: the number of heads. Desired: if E is repeated infinitely often then the sample mean m will be within Err of the true mean h a high proportion P of the time. We are 100P percent confident that the true mean lies in the interval (H/N-err, H/N+err) Measures of central tendency cont. Coin flips: can compute the binomial distribution explicitly and the probabilities associated with various outcomes. The confidence interval derives from adding the probabilities of the various outcomes corresponding to that interval and excluding the remaining probabilities. The precise statement is a subtle reflection of the approximability of the Gaussian curve by a binomial curve. [*** pictures here***] Bayesian Approaches Posterior probability Current age 10 years 20 years 30 years 30 0.43 1.86 4.13 40 1.45 3.75 6.87 50 2.38 5.60 8.66 60 3.45 6.71 8.65 †Source: Altekruse SF, Kosary CL, Krapcho M, Neyman N, Aminou R, Waldron W, Ruhl J, Howlader N, Tatalovich Z, Cho H, Mariotto A, Eisner MP, Lewis DR, Cronin K, Chen HS, Feuer EJ, Stinchcomb DG, Edwards BK (eds). SEER Cancer Statistics Review, 1975– 2007, National Cancer Institute. Bethesda, MD, based on November 2009 SEER data submission, posted to the SEER Web site, 2010. The mammogram question In 2009, the U.S. Preventive Services Task Force (USPSTF) — a group of health experts that reviews published research and makes recommendations about preventive health care — issued revised mammogram guidelines. Those guidelines include the following: Screening mammograms should be done every two years beginning at age 50 for women at average risk of breast cancer. Screening mammograms before age 50 should not be done routinely and should be based on a woman's values regarding the risks and benefits of mammography. Doctors should not teach women to do breast self-exams. The mammogram question (cont) These guidelines differ from those of the American Cancer Society (ACS). The ACS mammogram guidelines call for yearly mammogram screening beginning at age 40 for women at average risk of breast cancer. Meantime, the ACS says the breast self-exam is optional in breast cancer screening. According to the USPSTF, women who have screening mammograms die of breast cancer less frequently than do women who don't get mammograms. However, the USPSTF says the benefits of screening mammograms don't outweigh the harms for women ages 40 to 49. Potential harms may include false-positive results that lead to unneeded breast biopsies and accompanying anxiety and distress. A statistical question The rate of incidence of new cancer in women aged 40 is about 1 percent Of existing tumors, about 80 percent show up in mammograms. 9.6% of women who do not have breast cancer will have a false positive mammogram Suppose a woman aged 40 has a positive mammogram. What is the probability that the woman actually has breast cancer? According to See Casscells, Schoenberger, and Grayboys 1978; Eddy 1982; Gigerenzer and Hoffrage 1995; and many other studies, only about 15% of doctors can compute this probability correctly. prob(C|P)=(prob(P|C)*prob(C)/prob(P) =0.8*0.01/0.096=0.08333… False positives in a medical test False positives: a medical test for a disease may return a positive result indicating that patient could have disease even if the patient does not have the disease. Bayes' formula: probability that a positive result is a false positive. The majority of positive results for a rare disease may be false positives, even if the test is accurate. Example A test correctly identifies a patient who has a particular disease 99% of the time, or with probability 0.99 The same test incorrectly identifies a patient who does not have the disease 5% of the time, or with probability 0.05. Is it true that only 5% of positive test results are false? Suppose that only 0.1% of the population has that disease: a randomly selected patient has a 0.001 prior probability of having the disease. A: the condition in which the patient has the disease B: evidence of a positive test result. Bayes: p(A|B)= p(B|A) p(A)/p(B) =.99x .0001/.05=.00198 The probability that a positive result is a false positive is about 1 − 0.0198 = 0.998, or 99.8%. The vast majority of patients who test positive do not have the disease: The fraction of patients who test positive who do have the disease (0.019) is 19 times the fraction of people who have not yet taken the test who have the disease (0.001). Retesting may help. To reduce false positives, a test should be very accurate in reporting a negative result when the patient does not have the disease. If the test reported a negative result in patients without the disease with probability 0.999, then False negatives: a medical test for a disease may return a negative result indicating that patient does not have a disease even though the patient actually has the disease. Bayes formual for negations: p(A|-B)= p(-B|A)p(A)/(p(-B|A)p(A)+p(-B|-A)p(-A)) In our example = 0.01 x .001/(.01x.001 + .05x .999)=0.0000105 or about 0.001 percent. When a disease is rare, false negatives will not be a major problem with the test. If 60% of the population had the disease, false negatives would be more prevalent, happening about 1.55 percent of the time Prosecutors fallacy the context in which the accused has been brought to court is falsely assumed to be irrelevant to judging how confident a jury can be in evidence against them with a statistical measure of doubt. This fallacy usually results in assuming that the prior probability that a piece of evidence would implicate a randomly chosen member of the population is equal to the probability that it would implicate the defendant. Defendant’s fallacy Comes from not grouping the evidence together. In a city of ten million, a one in a million DNA characteristic gives any one person that has it a 1 in 10 chance of being guilty, or a 90% chance of being innocent. Factoring in another piece of incriminating would give much smaller probability of innocence. OJ Simpson In the courtroom Bayesian inference can be used by an individual juror to see whether the evidence meets his or herpersonal threshold for 'beyond a reasonable doubt. G: the event that the defendant is guilty. E: the event that the defendant's DNA is a match crime scene. P(E | G): probability of observing E if the defendant is guilty. P(G | E): probability of guilt assuming the DNA match (event E). P(G): juror's “personal estimate” of the probability that the defendant is guilty, based on the evidence other than the DNA match. Bayesian inference: P(G | E)= P(E|G) p(G)/p(E) On the basis of other evidence, a juror decides that there is a 30% chance that the defendant is guilty. Forensic testimony suggests that a person chosen at random would have DNA 1 in a million, or 10−6 change of having a DNA match to the crime scene. E can occur in two ways: the defendant is guilty (with prior probability 0.3) so his DNA is present with probability 1, or he is innocent (with prior probability 0.7) and he is unlucky enough to be one of the 1 in a million matching people. P(G|E)= (0.3x1.0)/(0.3x1.0 + 0.7/1 million) =0.99999766667 The approach can be applied successively to all the pieces of evidence presented in court, with the posterior from one stage becoming the prior for the next. P(G)? for a crime known to have been committed by an adult male living in a town containing 50,000 adult males, the appropriate initial prior probability might be 1/50,000. Posterior odds = prior odds x Bayes factor In the example above, the juror who has a prior probability of 0.3 for the defendant being guilty would now express that in the form of odds of 3:7 in favour of the defendant being guilty, the Bayes factor is one million, and the resulting posterior odds are 3 million to 7 or about 429,000 to one in favour of guilt. In the UK, Bayes' theorem was explained to the jury in the odds form by a statistician expert witness in the rape case of Regina versus Denis John Adams. The Court of Appeal upheld the conviction, but it also gave their opinion that "To introduce Bayes' Theorem, or any similar method, into a criminal trial plunges the jury into inappropriate and unnecessary realms of theory and complexity, deflecting them from their proper task.” Bayesian assessment of forensic DNA data remains controversial. Gardner-Medwin : criterion is not the probability of guilt, but rather the probability of the evidence, given that the defendant is innocent (akin to a frequentist p-value). If the posterior probability of guilt is to be computed by Bayes' theorem, the prior probability of guilt must be known. A: The known facts and testimony could have arisen if the defendant is guilty, B: The known facts and testimony could have arisen if the defendant is innocent, C: The defendant is guilty. Gardner-Medwin : the jury should believe both A and not-B in order to convict. A and not-B implies the truth of C, but B and C could both be true. Lindley's paradox. Other court cases in which probabilistic arguments played some role: the Howland will forgery trial, the Sally Clark case, and the Lucia de Berk case.