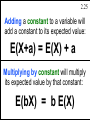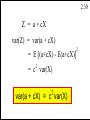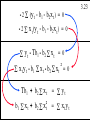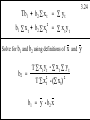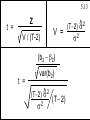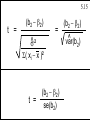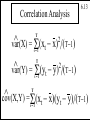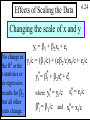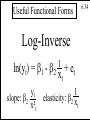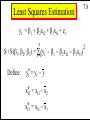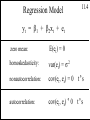Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Copyright 1996 Lawrence C. Marsh
PowerPoint Slides
for
Undergraduate Econometrics
by
Lawrence C. Marsh
To accompany: Undergraduate Econometrics
by R. Carter Hill, William E. Griffiths and George G. Judge
Publisher: John Wiley & Sons, 1997
Copyright 1996 Lawrence C. Marsh
Chapter 1
1.1
The Role of
Econometrics
in Economic Analysis
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
The Role of Econometrics
Using Information:
1. Information from economic theory.
2. Information from economic data.
1.2
Copyright 1996 Lawrence C. Marsh
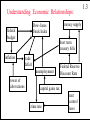
Understanding Economic Relationships:
money supply
Dow-Jones
Stock Index
federal
budget
short term
treasury bills
inflation
trade
deficit
unemployment
power of
labor unions
Federal Reserve
Discount Rate
capital gains tax
crime rate
rent
control
laws
1.3
Copyright 1996 Lawrence C. Marsh
Economic Decisions
To use information effectively:
economic theory
economic data
}
economic
decisions
*Econometrics* helps us combine
economic theory and economic data .
1.4
Copyright 1996 Lawrence C. Marsh
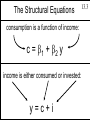
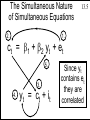
The Consumption Function
1.5
Consumption, c, is some function of income, i :
c = f(i)
For applied econometric analysis
this consumption function must be
specified more precisely.
Copyright 1996 Lawrence C. Marsh
demand, qd, for an individual commodity:
qd = f( p, pc, ps, i )
1.6
demand
p = own price; pc = price of complements;
ps = price of substitutes; i = income
supply, qs, of an individual commodity:
qs = f( p, pc, pf )
supply
p = own price; pc = price of competitive products;
ps = price of substitutes; pf = price of factor inputs
Copyright 1996 Lawrence C. Marsh
How much ?
Listing the variables in an economic relationship is not enough.
For effective policy we must know the amount of change
needed for a policy instrument to bring about the desired
effect:
• By how much should the Federal Reserve
raise interest rates to prevent inflation?
• By how much can the price of football tickets
be increased and still fill the stadium?
1.7
Copyright 1996 Lawrence C. Marsh
Answering the How Much? question
Need to estimate parameters
that are both:
1. unknown
and
2. unobservable
1.8
Copyright 1996 Lawrence C. Marsh
The Statistical Model
Average or systematic behavior
over many individuals or many firms.
Not a single individual or single firm.
Economists are concerned with the
unemployment rate and not whether
a particular individual gets a job.
1.9
Copyright 1996 Lawrence C. Marsh
1.10
The Statistical Model
Actual vs. Predicted Consumption:
Actual = systematic part + random error
Consumption, c, is function, f, of income, i, with error, e:
c = f(i) + e
Systematic part provides prediction, f(i),
but actual will miss by random error, e.
Copyright 1996 Lawrence C. Marsh
The Consumption Function
c = f(i) + e
Need to define f(i) in some way.
To make consumption, c,
a linear function of income, i :
f(i) = b1 + b2 i
The statistical model then becomes:
c = b1 + b2 i + e
1.11
Copyright 1996 Lawrence C. Marsh
1.12
The Econometric Model
y = b 1 + b 2 X2 + b 3 X 3 + e
• Dependent variable, y, is focus of study
(predict or explain changes in dependent variable).
• Explanatory variables, X2 and X3, help us explain
observed changes in the dependent variable.
Copyright 1996 Lawrence C. Marsh
1.13
Statistical Models
Controlled (experimental)
vs.
Uncontrolled (observational)
Controlled experiment (“pure” science) explaining mass, y :
pressure, X2, held constant when varying temperature, X3,
and vice versa.
Uncontrolled experiment (econometrics) explaining consumption, y : price, X2, and income, X3, vary at the same time.
Copyright 1996 Lawrence C. Marsh
1.14
Econometric model
• economic model
economic variables and parameters.
• statistical model
sampling process with its parameters.
• data
observed values of the variables.
Copyright 1996 Lawrence C. Marsh
1.15
The Practice of Econometrics
•
•
•
•
•
•
•
•
•
Uncertainty regarding an outcome.
Relationships suggested by economic theory.
Assumptions and hypotheses to be specified.
Sampling process including functional form.
Obtaining data for the analysis.
Estimation rule with good statistical properties.
Fit and test model using software package.
Analyze and evaluate implications of the results.
Problems suggest approaches for further research.
Copyright 1996 Lawrence C. Marsh
1.16
Note: the textbook uses the following symbol
to mark sections with advanced material:
“Skippy”
Copyright 1996 Lawrence C. Marsh
Chapter 2
2.1
Some Basic
Probability
Concepts
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
Random Variable
random variable:
A variable whose value is unknown until it is observed.
The value of a random variable results from an experiment.
The term random variable implies the existence of some
known or unknown probability distribution defined over
the set of all possible values of that variable.
In contrast, an arbitrary variable does not have a
probability distribution associated with its values.
2.2
Copyright 1996 Lawrence C. Marsh
Controlled experiment values
of explanatory variables are chosen
with great care in accordance with
an appropriate experimental design.
Uncontrolled experiment values
of explanatory variables consist of
nonexperimental observations over
which the analyst has no control.
2.3
Copyright 1996 Lawrence C. Marsh
Discrete Random Variable
discrete random variable:
A discrete random variable can take only a finite
number of values, that can be counted by using
the positive integers.
Example: Prize money from the following
lottery is a discrete random variable:
first prize: $1,000
second prize: $50
third prize: $5.75
since it has only four (a finite number)
(count: 1,2,3,4) of possible outcomes:
$0.00; $5.75; $50.00; $1,000.00
2.4
Copyright 1996 Lawrence C. Marsh
Continuous Random Variable
continuous random variable:
A continuous random variable can take
any real value (not just whole numbers)
in at least one interval on the real line.
Examples:
Gross national product (GNP)
money supply
interest rates
price of eggs
household income
expenditure on clothing
2.5
Copyright 1996 Lawrence C. Marsh
Dummy Variable
A discrete random variable that is restricted
to two possible values (usually 0 and 1) is
called a dummy variable (also, binary or
indicator variable).
Dummy variables account for qualitative differences:
gender (0=male, 1=female),
race (0=white, 1=nonwhite),
citizenship (0=U.S., 1=not U.S.),
income class (0=poor, 1=rich).
2.6
Copyright 1996 Lawrence C. Marsh
2.7
A list of all of the possible values taken
by a discrete random variable along with
their chances of occurring is called a probability
function or probability density function (pdf).
die
one dot
two dots
three dots
four dots
five dots
six dots
x
1
2
3
4
5
6
f(x)
1/6
1/6
1/6
1/6
1/6
1/6
Copyright 1996 Lawrence C. Marsh
A discrete random variable X
has pdf, f(x), which is the probability
that X takes on the value x.
f(x) = P(X=x)
Therefore,
0 < f(x) < 1
If X takes on the n values: x1, x2, . . . , xn,
then f(x1) + f(x2)+. . .+f(xn) = 1.
2.8
Copyright 1996 Lawrence C. Marsh
Probability, f(x), for a discrete random
variable, X, can be represented by height:
0.4
0.3
f(x)
0.2
0.1
0
1
2
3
X
number, X, on Dean’s List of three roommates
2.9
Copyright 1996 Lawrence C. Marsh
2.10
A continuous random variable uses
area under a curve rather than the
height, f(x), to represent probability:
f(x)
red area
0.1324
green area
0.8676
.
.
$34,000
$55,000
per capita income, X, in the United States
X
Copyright 1996 Lawrence C. Marsh
2.11
Since a continuous random variable has an
uncountably infinite number of values,
the probability of one occurring is zero.
P[X=a] = P[a<X<a]=0
Probability is represented by area.
Height alone has no area.
An interval for X is needed to get
an area under the curve.
Copyright 1996 Lawrence C. Marsh
2.12
The area under a curve is the integral of
the equation that generates the curve:
b
P[a<X<b]=
ٍ
a
f(x) dx
For continuous random variables it is the
integral of f(x), and not f(x) itself, which
defines the area and, therefore, the probability.
Copyright 1996 Lawrence C. Marsh
Rules of Summation
n
Rule 1:
Rule 2:
xi = x1 + x2 + . . . + xn
S
i=1
n
n
i=1
i=1
S axi = a S xi
n
Rule 3:
n
n
i=1
i=1
(xi + yi) = S xi + S yi
S
i=1
Note that summation is a linear operator
which means it operates term by term.
2.13
Copyright 1996 Lawrence C. Marsh
2.14
Rules of Summation (continued)
n
Rule 4:
Rule 5:
n
n
i=1
i=1
(axi + byi) = a S xi + b S yi
S
i=1
x
n
= n S xi =
i=1
1
x1 + x2 + . . . + xn
n
The definition of x as given in Rule 5 implies
the following important fact:
n
(xi - x) = 0
S
i=1
Copyright 1996 Lawrence C. Marsh
2.15
Rules of Summation (continued)
n
Rule 6:
f(xi) = f(x1) + f(x2) + . . . + f(xn)
S
i=1
Notation:
n m
Rule 7:
n
Sx f(xi) = Si f(xi) = i =S1 f(xi)
n
[ f(xi,y1) + f(xi,y2)+. . .+ f(xi,ym)]
S S f(xi,yj) = i S
=1
i=1 j=1
The order of summation does not matter :
n m
m n
f(xi,yj)
S S f(xi,yj) =j =S1 i S
=1
i=1 j=1
Copyright 1996 Lawrence C. Marsh
2.16
The Mean of a Random Variable
The mean or arithmetic average of a
random variable is its mathematical
expectation or expected value, EX.
Copyright 1996 Lawrence C. Marsh
Expected Value
2.17
There are two entirely different, but mathematically
equivalent, ways of determining the expected value:
1. Empirically:
The expected value of a random variable, X,
is the average value of the random variable in an
infinite number of repetitions of the experiment.
In other words, draw an infinite number of samples,
and average the values of X that you get.
Copyright 1996 Lawrence C. Marsh
Expected Value
2.18
2. Analytically:
The expected value of a discrete random
variable, X, is determined by weighting all
the possible values of X by the corresponding
probability density function values, f(x), and
summing them up.
In other words:
E[X] = x1f(x1) + x2f(x2) + . . . + xnf(xn)
Copyright 1996 Lawrence C. Marsh
Empirical vs. Analytical
As sample size goes to infinity, the
empirical and analytical methods
will produce the same value.
In the empirical case when the
sample goes to infinity the values
of X occur with a frequency
equal to the corresponding f(x)
in the analytical expression.
2.19
Copyright 1996 Lawrence C. Marsh
2.20
Empirical (sample) mean:
n
x = S xi
i=1
where n is the number of sample observations.
Analytical mean:
n
E[X] = S xi f(xi)
i=1
where n is the number of possible values of xi.
Notice how the meaning of n changes.
Copyright 1996 Lawrence C. Marsh
2.21
The expected value of X:
n
EX =
S
xi f(xi)
i=1
The expected value of X-squared:
2
EX =
n
S
i=1
2
xi f(xi)
It is important to notice that f(xi) does not change!
The expected value of X-cubed:
3
EX =
n
S
i=1
3
xi f(xi)
Copyright 1996 Lawrence C. Marsh
2.22
EX
= 0 (.1) + 1 (.3) + 2 (.3) + 3 (.2) + 4 (.1)
= 1.9
2
2
2
2
2
2
EX = 0 (.1) + 1 (.3) + 2 (.3) + 3 (.2) + 4 (.1)
= 0 + .3 + 1.2 + 1.8 + 1.6
= 4.9
3
3
3
3
3
3
EX = 0 (.1) + 1 (.3) + 2 (.3) + 3 (.2) +4 (.1)
= 0 + .3 + 2.4 + 5.4 + 6.4
= 14.5
Copyright 1996 Lawrence C. Marsh
2.23
n
E[g(X)] =
S
g(xi)
i=1
f(xi)
g(X) = g1(X) + g2(X)
n
E[g(X)] =
S
[
g1(xi) + g2(xi)] f(xi)
i=1
n
E[g(X)] =
n
S
g1(xi) f(xi) +i S
g
(x
)
f(x
)
2
i
i
=1
i=1
E[g(X)] = E[g1(X)] + E[g2(X)]
Copyright 1996 Lawrence C. Marsh
Adding and Subtracting
Random Variables
2.24
E(X+Y) = E(X) + E(Y)
E(X-Y) = E(X) - E(Y)
Copyright 1996 Lawrence C. Marsh
2.25
Adding a constant to a variable will
add a constant to its expected value:
E(X+a) = E(X) + a
Multiplying by constant will multiply
its expected value by that constant:
E(bX) = b E(X)
Copyright 1996 Lawrence C. Marsh
2.26
Variance
var(X) = average squared deviations
around the mean of X.
var(X) = expected value of the squared deviations
around the expected value of X.
2
var(X) = E [(X - EX) ]
Copyright 1996 Lawrence C. Marsh
2.27
2
var(X) = E [(X - EX) ]
2
var(X) = E [(X - EX) ]
2
2
= E [X - 2XEX + (EX) ]
2
2
= E(X ) - 2 EX EX + E (EX)
2
2
2
= E(X ) - 2 (EX) + (EX)
2
2
= E(X ) - (EX)
2
2
var(X) = E(X ) - (EX)
Copyright 1996 Lawrence C. Marsh
2.28
variance of a discrete
random variable, X:
n
var (X) =
ه
2
(xi - EX ) f (xi )
i=1
standard deviation is square root of variance
Copyright 1996 Lawrence C. Marsh
2.29
calculate the variance for a
discrete random variable, X:
2
xi
f(xi)
(xi - EX)
(xi - EX) f(xi)
2
3
4
5
6
.1
.3
.1
.2
.3
2 - 4.3 = -2.3
3 - 4.3 = -1.3
4 - 4.3 = - .3
5 - 4.3 = .7
6 - 4.3 = 1.7
5.29 (.1) =
1.69 (.3) =
.09 (.1) =
.49 (.2) =
2.89 (.3) =
.529
.507
.009
.098
.867
n
S xi f(xi) = .2 + .9 + .4 + 1.0 + 1.8 = 4.3
i=1
n
2
S (xi - EX) f(xi) = .529 + .507 + .009 + .098 + .867
= 2.01
i=1
Copyright 1996 Lawrence C. Marsh
2.30
Z = a + cX
var(Z) = var(a + cX)
2
= E [(a+cX) - E(a+cX)]
2
= c var(X)
2
var(a + cX) = c var(X)
Copyright 1996 Lawrence C. Marsh
Joint pdf
2.31
A joint probability density function,
f(x,y), provides the probabilities
associated with the joint occurrence
of all of the possible pairs of X and Y.
Copyright 1996 Lawrence C. Marsh
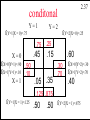
Survey of College City, NY
joint pdf
f(x,y)
vacation X = 0
homes
owned
X=1
college grads
in household
Y=2
Y=1
f(0,1)
.45
f(0,2)
.15
.05
f(1,1)
.35
f(1,2)
2.32
Copyright 1996 Lawrence C. Marsh
2.33
Calculating the expected value of
functions of two random variables.
E[g(X,Y)] = S S g(xi,yj) f(xi,yj)
i
j
E(XY) = S S xi yj f(xi,yj)
i
j
E(XY) = (0)(1)(.45)+(0)(2)(.15)+(1)(1)(.05)+(1)(2)(.35)=.75
Copyright 1996 Lawrence C. Marsh
2.34
Marginal pdf
The marginal probability density functions,
f(x) and f(y), for discrete random variables,
can be obtained by summing over the f(x,y)
with respect to the values of Y to obtain f(x)
with respect to the values of X to obtain f(y).
f(xi) = S f(xi,yj)
j
f(yj) = S f(xi,yj)
i
Copyright 1996 Lawrence C. Marsh
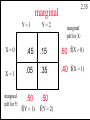
marginal
Y=1
Y=2
2.35
marginal
pdf for X:
X=0
.45
.15
.60 f(X = 0)
X=1
.05
.35
.40 f(X = 1)
.50
.50
f(Y = 2)
marginal
pdf for Y:
f(Y = 1)
Copyright 1996 Lawrence C. Marsh
Conditional pdf
2.36
The conditional probability density
functions of X given Y=y , f(x|y),
and of Y given X=x , f(y|x),
are obtained by dividing f(x,y) by f(y)
to get f(x|y) and by f(x) to get f(y|x).
f(x,y)
f(x|y) =
f(y)
f(x,y)
f(y|x) =
f(x)
Copyright 1996 Lawrence C. Marsh
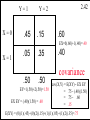
2.37
conditonal
f(Y=1|X = 0)=.75
Y=1
.75
X=0
f(X=0|Y=1)=.90 .90
f(X=1|Y=1)=.10 .10
X=1
.45
Y=2
f(Y=2|X= 0)=.25
.25
.60
.15
.05 .35
.30
.70
f(X=0|Y=2)=.30
f(X=1|Y=2)=.70
.40
.125 .875
f(Y=1|X = 1)=.125
.50
.50 f(Y=2|X = 1)=.875
Copyright 1996 Lawrence C. Marsh
Independence
X and Y are independent random
variables if their joint pdf, f(x,y),
is the product of their respective
marginal pdfs, f(x) and f(y) .
f(xi,yj) = f(xi) f(yj)
for independence this must hold for all pairs of i and j
2.38
Copyright 1996 Lawrence C. Marsh
not independent
Y=1
Y=2
.50x.60=.30
.50x.60=.30
2.39
marginal
pdf for X:
X=0
.45
.15
.60 f(X = 0)
X=1
.05
.35
.40 f(X = 1)
.50x.40=.20
marginal
pdf for Y:
.50
f(Y = 1)
.50x.40=.20
.50
f(Y = 2)
The calculations
in the boxes show
the numbers
required to have
independence.
Copyright 1996 Lawrence C. Marsh
2.40
Covariance
The covariance between two random
variables, X and Y, measures the
linear association between them.
cov(X,Y) = E[(X - EX)(Y-EY)]
Note that variance is a special case of covariance.
2
cov(X,X) = var(X) = E[(X - EX) ]
Copyright 1996 Lawrence C. Marsh
2.41
cov(X,Y) = E [(X - EX)(Y-EY)]
cov(X,Y) = E [(X - EX)(Y-EY)]
= E [XY - X EY - Y EX + EX EY]
= E(XY) - EX EY - EY EX + EX EY
= E(XY) - 2 EX EY + EX EY
= E(XY) - EX EY
cov(X,Y) = E(XY) - EX EY
Y=1
X=0
.45
Copyright 1996 Lawrence C. Marsh
2.42
Y=2
.15
.60
EX=0(.60)+1(.40)=.40
X=1
.05
.50
.35
.50
EY=1(.50)+2(.50)=1.50
EX EY = (.40)(1.50) = .60
.40
covariance
cov(X,Y) = E(XY) - EX EY
= .75 - (.40)(1.50)
= .75 - .60
= .15
E(XY) = (0)(1)(.45)+(0)(2)(.15)+(1)(1)(.05)+(1)(2)(.35)=.75
Copyright 1996 Lawrence C. Marsh
Correlation
2.43
The correlation between two random
variables X and Y is their covariance
divided by the square roots of their
respective variances.
r(X,Y) =
cov(X,Y)
var(X) var(Y)
Correlation is a pure number falling between -1 and 1.
Y=1
Copyright 1996 Lawrence C. Marsh
Y=2
2.44
EX=.40
2
2
2
EX=0(.60)+1(.40)=.40
X=0
.45
.05
X=1
.15
.35
.60
2
var(X) = E(X ) - (EX)
2
= .40 - (.40)
= .24
.40
cov(X,Y) = .15
.50
EY=1.50
2 2
2
.50
EY=1(.50)+2(.50)
2
2
var(Y) = E(Y ) - (EY)
= .50 + 2.0
= 2.50 - (1.50)2
= 2.50
= .25
correlation
r(X,Y) =
cov(X,Y)
var(X) var(Y)
r(X,Y) = .61
2
Copyright 1996 Lawrence C. Marsh
2.45
Zero Covariance & Correlation
Independent random variables
have zero covariance and,
therefore, zero correlation.
The converse is not true.
Copyright 1996 Lawrence C. Marsh
2.46
Since expectation is a linear operator,
it can be applied term by term.
The expected value of the weighted sum
of random variables is the sum of the
expectations of the individual terms.
E[c1X + c2Y] = c1EX + c2EY
In general, for random variables X1, . . . , Xn :
E[c1X1+...+ cnXn] = c1EX1+...+ cnEXn
Copyright 1996 Lawrence C. Marsh
2.47
The variance of a weighted sum of random
variables is the sum of the variances, each times
the square of the weight, plus twice the covariances
of all the random variables times the products of
their weights.
Weighted sum of random variables:
2
2
var(c1X + c2Y)=c1 var(X)+c2 var(Y) + 2c1c2cov(X,Y)
Weighted difference of random variables:
var(c1X - c2Y) = c21 var(X)+c22var(Y) - 2c1c2cov(X,Y)
Copyright 1996 Lawrence C. Marsh
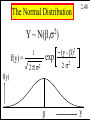
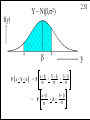
The Normal Distribution
Y~
f(y) =
2.48
2
N(b,s )
(y - b)2
exp
2
1
2s
2 p s2
f(y)
b
y
Copyright 1996 Lawrence C. Marsh
The Standardized Normal
Z = (y - b)/s
Z ~ N(0,1)
f(z) =
1
2p
exp
- z2
2
2.49
Copyright 1996 Lawrence C. Marsh
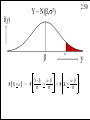
Y~
2.50
N(b,s2)
f(y)
b
P[Y>a]
= P
Y-b
s
>
a
a-b
s
= P Z >
y
a-b
s
Copyright 1996 Lawrence C. Marsh
Y~
N(b,s2)
2.51
b
y
f(y)
a
P[a<Y<b] = P
=
P
a-b
s
a-b
s
b
<
Y-b
s
<Z<
<
b-b
b-b
s
s
Copyright 1996 Lawrence C. Marsh
2.52
Linear combinations of jointly
normally distributed random variables
are themselves normally distributed.
Y1 ~ N(b1,s12), Y2 ~ N(b2,s22), . . . , Yn ~ N(bn,sn2)
W = c1Y1 + c2Y2 + . . . + cnYn
W ~ N[ E(W), var(W) ]
Copyright 1996 Lawrence C. Marsh
Chi-Square
2.53
If Z1, Z2, . . . , Zm denote m independent
N(0,1) random variables, and
2
2
2
2
V = Z1 + Z2 + . . . + Zm, then V ~ c(m)
V is chi-square with m degrees of freedom.
mean:
E[V] = E[ c(m) ] = m
variance:
2
var[V] = var[ c(m) ] = 2m
2
Copyright 1996 Lawrence C. Marsh
2.54
Student - t
If Z ~ N(0,1) and V ~ c(m) and if Z and V
are independent then,
Z
2
t=
V
~ t(m)
m
t is student-t with m degrees of freedom.
mean:
E[t] = E[t(m) ] = 0 symmetric about zero
variance:
var[t] = var[t(m) ] = m / (m-2)
Copyright 1996 Lawrence C. Marsh
2.55
F Statistic
If V1 ~ c(m ) and V2 ~ c(m ) and if V1 and V2
1
2
are independent, then
V1
2
2
F=
m1
V2
~ F(m1,m2)
m2
F is an F statistic with m1 numerator
degrees of freedom and m2 denominator
degrees of freedom.
Copyright 1996 Lawrence C. Marsh
Chapter 3
3.1
The Simple Linear
Regression
Model
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
3.2
Purpose of Regression Analysis
1. Estimate a relationship among
economic
variables, such as y = f(x).
2. Forecast or predict the value of one
variable, y, based on the value of
another variable, x.
Copyright 1996 Lawrence C. Marsh
Weekly Food Expenditures
y = dollars spent each week on food items.
x = consumer’s weekly income.
The relationship between x and the expected
value of y , given x, might be linear:
E(y|x) = b1 + b2 x
3.3
Copyright 1996 Lawrence C. Marsh
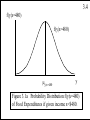
f(y|x=480)
f(y|x=480)
my|x=480
y
Figure 3.1a Probability Distribution f(y|x=480)
of Food Expenditures if given income x=$480.
3.4
Copyright 1996 Lawrence C. Marsh
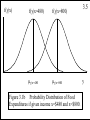
f(y|x)
f(y|x=480)
f(y|x=800)
my|x=480
my|x=800
Figure 3.1b Probability Distribution of Food
Expenditures if given income x=$480 and x=$800.
3.5
y
Copyright 1996 Lawrence C. Marsh
Average
Expenditure
E(y|x)
3.6
E(y|x)=b1+b2x
DE(y|x)
Dx
b 2=
DE(y|x)
Dx
b1{
x (income)
Figure 3.2 The Economic Model: a linear relationship
between avearage expenditure on food and income.
Copyright 1996 Lawrence C. Marsh
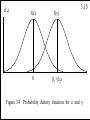
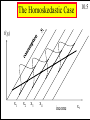
Homoskedastic Case
f(yt)
.
.
x1=480
x2=800
income
xt
Figure 3.3. The probability density function
for yt at two levels of household income, x t
3.7
Copyright 1996 Lawrence C. Marsh
Heteroskedastic Case
f(yt)
.
.
x1
x2
x3
.
income
Figure 3.3+. The variance of yt increases
as household income, x t , increases.
xt
3.8
Copyright 1996 Lawrence C. Marsh
Assumptions of the Simple Linear
Regression Model - I
1. The average value of y, given x, is given by
the linear regression:
E(y) = b1 + b2x
2. For each value of x, the values of y are
distributed around their mean with variance:
var(y) = s2
3. The values of y are uncorrelated, having zero
covariance and thus no linear relationship:
cov(yi ,yj) = 0
4. The variable x must take at least two different
values, so that x ° c, where c is a constant.
3.9
Copyright 1996 Lawrence C. Marsh
3.10
One more assumption that is often used in
practice but is not required for least squares:
5. (optional) The values of y are normally
distributed about their mean for each
value of x:
y ~ N [(b1+b2x), s2 ]
Copyright 1996 Lawrence C. Marsh
The Error Term
3.11
y is a random variable composed of two parts:
I. Systematic component:
This is the mean of y.
E(y) = b1 + b2x
II. Random component:
e = y - E(y)
= y - b 1 - b 2x
This is called the random error.
Together
E(y) and e form the model:
y = b1 + b2x + e
Copyright 1996 Lawrence C. Marsh
3.12
y
.
y4
e4 {
y3
y2
y1
e2 {.
E(y) = b1 + b2x
.} e3
e1
}
.
x1
x2
x3
x4
Figure 3.5 The relationship among y, e and
the true regression line.
x
Copyright 1996 Lawrence C. Marsh
3.13
y
y^3
y2
^e {.
2 .
y^1.
y4
.
^e {
4
.y^
^y = b + b x
1
2
x4
x
4
.} ^e3
.
y
3
y^2
^
} e1
.
y
1
x1
x2
x3
Figure 3.7a The relationship among y, e^ and
the fitted regression line.
Copyright 1996 Lawrence C. Marsh
3.14
y
. y4
y^*1.
{
y^*2
.
^e* { y
2 . 2
y^*3
.
^e* {
3
.
y
{.
^e*
4
y^*4
^y = b + b x
1
2
^y*= b* + b* x
1
2
3
^e*
1
.
y
1
x1
x2
x3
x4
Figure 3.7b The sum of squared residuals
from any other line will be larger.
x
f(.)
Copyright 1996 Lawrence C. Marsh
f(e)
f(y)
0
b1+b2x
3.15
Figure 3.4 Probability density function for e and y
Copyright 1996 Lawrence C. Marsh
The Error Term Assumptions
3.16
1. The value of y, for each value of x, is
y = b1 + b2x + e
2. The average value of the random error e is:
E(e) = 0
3. The variance of the random error e is:
var(e) = s2 = var(y)
4. The covariance between any pair of e’s is:
cov(ei ,ej) = cov(yi ,yj) = 0
5. x must take at least two different values so that
x ° c, where c is a constant.
6. e is normally distributed with mean 0, var(e)=s2
(optional)
e ~ N(0,s2)
Copyright 1996 Lawrence C. Marsh
Unobservable Nature
of the Error Term
3.17
1. Unspecified factors / explanatory variables,
not in the model, may be in the error term.
2. Approximation error is in the error term if
relationship between y and x is not
exactly
a perfectly linear relationship.
3. Strictly unpredictable random behavior that
may be unique to that observation is in error.
Copyright 1996 Lawrence C. Marsh
Population regression values:
y t = b1 + b2x t + e t
Population regression line:
E(y t|x t) = b1 + b2x t
Sample regression values:
y t = b1 + b2x t + ^e t
Sample regression line:
y^ t = b1 + b2x t
3.18
Copyright 1996 Lawrence C. Marsh
3.19
y t = b1 + b2x t + e t
e t = y t - b1 - b2x t
Minimize error sum of squared deviations:
S(b1,b2) =
T
S(y t
t=1
- b1 - b2x t )2
(3.3.4)
Copyright 1996 Lawrence C. Marsh
Minimize w.r.t. b1 and b2:
S(b1,b2) =
S(.)
b1
S(.)
b2
T
S(y t
t =1
- b1 - b2x t )2
= - 2 S (y t
= -2S
3.20
(3.3.4)
- b1 - b2x t )
x t (y t - b 1 - b 2 x t )
Set each of these two derivatives equal to zero and
solve these two equations for the two unknowns:
b1 b2
Copyright 1996 Lawrence C. Marsh
Minimize w.r.t. b1 and b2:
S(.) =
S(.)
T
S
t =1
(y t
3.21
- b1 - b2x t )2
S(.)
.
S(.) <
0
bi
S(.) =
0
bi
.
bi
.S(.)
bi
>0
bi
Copyright 1996 Lawrence C. Marsh
To minimize S(.), you set the two
derivatives equal to zero to get:
S(.)
b1
S(.)
b2
= - 2 S (y t
= -2S
3.22
- b1 - b2x t ) = 0
x t (y t - b1 - b2x t ) = 0
When these two terms are set to zero,
b1 and b2 become b1 and b2 because they no longer
represent just any value of b1 and b2 but the special
values that correspond to the minimum of S(.) .
Copyright 1996 Lawrence C. Marsh
- 2 S (y t
-2S
- b1 - b2x t ) = 0
x t (y t - b1 - b2x t ) = 0
S y t - Tb1 - b2 S x t
= 0
S x t y t - b1 S x t - b2 S xt
2
= 0
Tb1 + b2 S x t = S y t
2
b1 S x t + b2 S xt = S x t y t
3.23
Copyright 1996 Lawrence C. Marsh
Tb1 + b2 S x t = S y t
2
b1 S x t + b2 S xt = S x t y t
Solve for b1 and b2 using definitions of
b2 =
x and y
T S x t yt - S x t S y t
T S x t - (S x t )
2
b1 = y - b2 x
2
3.24
Copyright 1996 Lawrence C. Marsh
elasticities
Dy x
Dy/y
percentage change in y
h =
=
=
Dx y
percentage change in x
Dx/x
Using calculus, we can get the elasticity at a point:
h = lim
Dx 0
Dy x
y x
=
Dx y
x y
3.25
Copyright 1996 Lawrence C. Marsh
applying elasticities
E(y) = b1 + b2 x
E(y)
x
=
b2
E(y) x
x
= b2
h =
x E(y)
E(y)
3.26
Copyright 1996 Lawrence C. Marsh
estimating elasticities
y x
h =
x y
^
^
y
t
3.27
x
= b2
y
= b1 + b2 x t = 4 + 1.5 x t
x = 8 = average number of years of experience
y = $10 = average wage rate
x
h = b2
y
^
8
= 1.5
= 1.2
10
Copyright 1996 Lawrence C. Marsh
Prediction
3.28
Estimated regression equation:
^
y
t
= 4 + 1.5 x t
x t = years of experience
^
yt = predicted wage rate
^
If x t = 2 years, then yt = $7.00 per hour.
^
If x t = 3 years, then yt = $8.50 per hour.
Copyright 1996 Lawrence C. Marsh
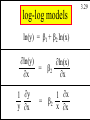
log-log models
ln(y) = b1 + b2 ln(x)
ln(y)
=
x
1 y
y x
=
b2
ln(x)
x
b2
1 x
x x
3.29
1 y
y x
Copyright 1996 Lawrence C. Marsh
x y
y x
= b2
=
3.30
1 x
x x
b2
elasticity of y with respect to x:
h =
x y
y x
=
b2
Copyright 1996 Lawrence C. Marsh
Chapter 4
4.1
Properties of
Least Squares
Estimators
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
Simple Linear Regression Model
4.2
y t = b1 + b2 x t + e t
yt = household weekly food expenditures
x t = household weekly income
For a given level of x t, the expected
level of food expenditures will be:
E(yt|x t) =
b1 + b 2 x t
Copyright 1996 Lawrence C. Marsh
Assumptions of the Simple
Linear Regression Model
4.3
1. yt = b1 + b2x t + e t
2. E(e t) = 0 <=> E(yt) = b1 + b2x t
3. var(e t) =
s 2 = var(yt)
4. cov(e i,e j) = cov(yi,yj) = 0
5.
x t ° c for every observation
6.
e t~N(0,s 2) <=> yt~N(b1+ b2x t,s 2)
Copyright 1996 Lawrence C. Marsh
The population parameters b1 and b2
are unknown population constants.
The formulas that produce the
sample estimates b1 and b2 are
called the estimators of b1 and
b2.
When b0 and b1 are used to represent
the formulas rather than specific values,
they are called estimators of b1 and b2
which are random variables because
they are different from sample to sample.
4.4
Copyright 1996 Lawrence C. Marsh
4.5
Estimators are Random Variables
( estimates are not )
• If the least squares estimators b0 and b1
are random variables, then what are their
their means, variances, covariances and
probability distributions?
• Compare the properties of alternative
estimators to the properties of the
least squares estimators.
Copyright 1996 Lawrence C. Marsh
4.6
The Expected Values of b1 and b2
The least squares formulas (estimators)
in the simple regression case:
b2 =
TSxtyt - Sxt Syt
TSxt -(Sxt)
2
b1 = y - b2x
where
2
(3.3.8a)
(3.3.8b)
y = Syt / T and x = Sx t / T
Substitute in
to get:
yt = b1 + b2x t + e t
Copyright 1996 Lawrence C. Marsh
TSxtet - Sxt Set
b2 = b2 +
2
2
TSxt -(Sxt)
The mean of b2 is:
TSxtEet - Sxt SEet
Eb2 = b2 +
2
2
TSxt -(Sxt)
Since
Eet = 0, then Eb2 = b2 .
4.7
Copyright 1996 Lawrence C. Marsh
An Unbiased Estimator
The result Eb2 = b2 means that
the distribution of b2 is centered at b2.
Since the distribution of b2
is centered at b2 ,we say that
b2 is an unbiased estimator of b2.
4.8
Copyright 1996 Lawrence C. Marsh
Wrong Model Specification
The unbiasedness result on the
previous slide assumes that we
are using the correct model.
If the model is of the wrong form
or is missing important variables,
then Eet ° 0, then Eb2 ° b2 .
4.9
Copyright 1996 Lawrence C. Marsh
4.10
Unbiased Estimator of the Intercept
In a similar manner, the estimator b1
of the intercept or constant term can be
shown to be an unbiased estimator of b1
when the model is correctly specified.
Eb1 = b1
Copyright 1996 Lawrence C. Marsh
4.11
Equivalent expressions for b2:
S(xt - x )(yt - y )
b2 =
2
S(xt - x )
(4.2.6)
Expand and multiply top and bottom by T:
b2 =
TSxtyt - Sxt Syt
TSxt -(Sxt)
2
2
(3.3.8a)
Copyright 1996 Lawrence C. Marsh
4.12
Variance of b2
Given that both yt and et have variance s 2,
the variance of the estimator b2 is:
var(b2) =
s2
S(x t - x)
2
b2 is a function of the yt values but
var(b2) does not involve yt directly.
Copyright 1996 Lawrence C. Marsh
4.13
Variance of b1
Given
b1 = y - b2x
the variance of the estimator b1 is:
Sx t
var(b1) = s 2
2
T S(x t - x)
2
Copyright 1996 Lawrence C. Marsh
Covariance of b1 and b2
cov(b1,b2) = s2
4.14
-x
S(x t - x)
2
If x = 0, slope can change without affecting
the variance.
Copyright 1996 Lawrence C. Marsh
What factors determine
variance and covariance ?
4.15
1. s 2: uncertainty about yt values uncertainty about
b1, b2 and their relationship.
2. The more spread out the xt values are then the more
confidence we have in b1, b2, etc.
3. The larger the sample size, T, the smaller the
variances and covariances.
4. The variance b1 is large when the (squared) xt values
are far from zero (in either direction).
5. Changing the slope, b2, has no effect on the intercept,
b1, when the sample mean is zero. But if sample
mean is positive, the covariance between b1 and
b2 will be negative, and vice versa.
Copyright 1996 Lawrence C. Marsh
Gauss-Markov Theorm
4.16
Under the first five assumptions of the
simple, linear regression model, the
ordinary least squares estimators b1
and b2 have the smallest variance of
all linear and unbiased estimators of
b1 and b2. This means that b1and b2
are the Best Linear Unbiased Estimators
(BLUE) of b1 and b2.
Copyright 1996 Lawrence C. Marsh
4.17
implications of Gauss-Markov
1. b1 and b2 are “best” within the
class
of linear and
unbiased estimators.
2. “Best” means smallest variance
within the class of linear/unbiased.
3. All of the first five assumptions must
hold to satisfy Gauss-Markov.
4. Gauss-Markov does not require
assumption six: normality.
5. G-Markov is not based on the
Copyright 1996 Lawrence C. Marsh
4.18
G-Markov implications (continued)
6. If we are not satisfied with restricting
our estimation to the class of linear and
unbiased estimators, we should ignore
the Gauss-Markov Theorem and use
some nonlinear and/or biased estimator
instead. (Note: a biased or nonlinear
estimator could have smaller variance
than those satisfying Gauss-Markov.)
7. Gauss-Markov applies to the b1 and b2
estimators and not to particular sample
values (estimates) of b1 and b2.
Copyright 1996 Lawrence C. Marsh
Probability Distribution
of Least Squares Estimators
b1 ~ N b 1 ,
s2
Sx t
2
T S(x t - x) 2
b2 ~ N b 2 ,
s2
S(x t - x)
2
4.19
Copyright 1996 Lawrence C. Marsh
yt and e t normally distributed
4.20
The least squares estimator of b2 can be
expressed as a linear combination of yt’s:
b2 = S wt yt
(x t - x)
where wt =
2
S(x t - x)
b1 = y - b2x
This means that b1and b2 are normal since
linear combinations of normals are normal.
Copyright 1996 Lawrence C. Marsh
normally distributed under
The Central Limit Theorem
4.21
If the first five Gauss-Markov assumptions
hold, and sample size, T, is sufficiently large,
then the least squares estimators, b1 and b2,
have a distribution that approximates the
normal distribution with greater accuracy
the larger the value of sample size, T.
Copyright 1996 Lawrence C. Marsh
Consistency
4.22
We would like our estimators, b1 and b2, to collapse
onto the true population values, b1 and b2, as
sample size, T, goes to infinity.
One way to achieve this consistency property is
for the variances of b1 and b2 to go to zero as T
goes to infinity.
Since the formulas for the variances of the least
squares estimators b1 and b2 show that their
variances do, in fact, go to zero, then b1 and b2,
are consistent estimators of b1 and b2.
Copyright 1996 Lawrence C. Marsh
Estimating the variance
of the error term, s 2
^e
t
= yt - b1 - b2 x t
T
^2
s =
Set
^2
t =1
T- 2
2
^
s is an unbiased estimator of s 2
4.23
Copyright 1996 Lawrence C. Marsh
4.24
The Least Squares
Predictor, y^o
Given a value of the explanatory
variable, Xo, we would like to predict
a value of the dependent variable, yo.
The least squares predictor is:
^y = b + b x
o
1
2 o
(4.7.2)
Copyright 1996 Lawrence C. Marsh
Chapter 5
5.1
Inference
in the Simple
Regression Model
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
Assumptions of the Simple
Linear Regression Model
1. yt = b1 + b2x t + e t
2. E(e t) = 0 <=> E(yt) = b1 + b2x t
3. var(e t) =
s 2 = var(yt)
4. cov(e i,e j) = cov(yi,yj) = 0
5. x t ° c for every observation
6.
e t~N(0,s 2) <=> yt~N(b1+ b2x t,s 2)
5.2
Copyright 1996 Lawrence C. Marsh
Probability Distribution
of Least Squares Estimators
b1 ~ N b 1 ,
s2
Sx t
2
T S(x t - x) 2
b2 ~ N b 2 ,
s2
S(x t - x)
2
5.3
Copyright 1996 Lawrence C. Marsh
Error Variance Estimation
5.4
Unbiased estimator of the error variance:
^2 =
s
S
2
^
e
t
T-2
Transform to a chi-square distribution:
^2
(T - 2) s
s
2
~
c
T-2
Copyright 1996 Lawrence C. Marsh
We make a correct decision if:
5.5
• The null hypothesis is false and we decide to reject it.
• The null hypothesis is true and we decide not to reject it.
Our decision is incorrect if:
• The null hypothesis is true and we decide to reject it.
This is a type I error.
• The null hypothesis is false and we decide not to reject it.
This is a type II error.
Copyright 1996 Lawrence C. Marsh
b2 ~ N b 2 ,
s2
S(x t - x)
2
Create a standardized normal random variable, Z,
by subtracting the mean of b2 and dividing by its
standard deviation:
Z =
b2 - b2
var(b2)
~ N(0,1)
5.6
Copyright 1996 Lawrence C. Marsh
Simple Linear Regression
yt = b1 + b2x t + e t
where E e t = 0
yt ~ N(b1+ b2x t , s 2)
since Eyt = b1 + b2x t
e t = yt - b1 - b2x t
Therefore,
e t ~ N(0,s 2) .
5.7
Copyright 1996 Lawrence C. Marsh
5.8
Create a Chi-Square
e t ~ N(0,s 2) but want N(0,1) .
(e t /s) ~ N(0,1) Standard Normal .
(e t
2
/s)
~ c2(1)
Chi-Square .
Copyright 1996 Lawrence C. Marsh
5.9
Sum of Chi-Squares
St =1(e t /s)2 =
(e1 /s)2 + (e 2 /s)2 +. . .+ (e T /s)2
c2(1) + c2(1) +. . .+c2(1)
Therefore,
=
c2(T)
St =1(e t /s)2 ~ c2(T)
Copyright 1996 Lawrence C. Marsh
Chi-Square degrees of freedom
5.10
Since the errors e t = yt - b1 - b2x t
are not observable, we estimate them with
the sample residuals e t = yt - b1 - b2x t.
Unlike the errors, the sample residuals are
not independent since they use up two degrees
of freedom by using b1 and b2 to estimate b1 and b2.
We get only T-2 degrees of freedom instead of T.
Copyright 1996 Lawrence C. Marsh
5.11
Student-t Distribution
t=
Z
~ t(m)
V/m
where Z ~ N(0,1)
and V ~
c
2
(m)
Copyright 1996 Lawrence C. Marsh
t =
Z
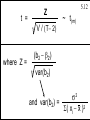
5.12
~ t(m)
V / (T- 2)
where Z =
(b2 - b2)
var(b2)
and var(b2) =
s2
S( xi - x )2
Copyright 1996 Lawrence C. Marsh
5.13
Z
t =
V / (T-2)
V =
(b2 - b2)
t =
var(b2)
2
^
(T-2) s
(T2)
s2
(T-2)
2
s
^2
s
s
Copyright 1996 Lawrence C. Marsh
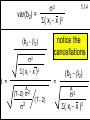
2
5.14
var(b2) =
S( xi - x )2
(b2 - b2)
s2
notice the
cancellations
S( xi - x )2
t =
=
^
(T-2) s 2
(T2)
s2
(b2 - b2)
^2
s
S( xi - x )2
Copyright 1996 Lawrence C. Marsh
5.15
t =
(b2 - b2)
=
^2
s
S( xi - x )2
t =
(b2 - b2)
se(b2)
(b2 - b2)
^
var(b2)
Copyright 1996 Lawrence C. Marsh
5.16
Student’s
t =
t - statistic
(b2 - b2)
se(b2)
~ t (T-2)
t has a Student-t Distribution
with T- 2 degrees of freedom.
Copyright 1996 Lawrence C. Marsh
5.17
Figure 5.1 Student-t Distribution
f(t)
(1-a)
a/2
-tc
0
a/2
tc
t
red area = rejection region for 2-sided test
Copyright 1996 Lawrence C. Marsh
5.18
probability statements
P( t < -tc ) = P( t > tc ) = a/2
P(-tc ٹt ٹtc) = 1 - a
P(-tc ٹ
(b2 - b2)
se(b2)
ٹtc) = 1 - a
Copyright 1996 Lawrence C. Marsh
5.19
Confidence Intervals
Two-sided (1-a)x100% C.I. for b1:
b1 - ta/2[se(b1)], b1 + ta/2[se(b1)]
Two-sided (1-a)x100% C.I. for b2:
b2 - ta/2[se(b2)], b2 + ta/2[se(b2)]
Copyright 1996 Lawrence C. Marsh
5.20
Student-t vs. Normal Distribution
1. Both are symmetric bell-shaped distributions.
2. Student-t distribution has fatter tails than the normal.
3. Student-t converges to the normal for infinite sample.
4. Student-t conditional on degrees of freedom (df).
5. Normal is a good approximation of Student-t for the first few
decimal places when df > 30 or so.
Copyright 1996 Lawrence C. Marsh
5.21
Hypothesis Tests
1. A null hypothesis, H0.
2. An alternative hypothesis, H1.
3. A test statistic.
4. A rejection region.
Copyright 1996 Lawrence C. Marsh
Rejection Rules
5.22
1. Two-Sided Test:
If the value of the test statistic falls in the critical region in either
tail of the t-distribution, then we reject the null hypothesis in favor
of the alternative.
2. Left-Tail Test:
If the value of the test statistic falls in the critical region which lies
in the left tail of the t-distribution, then we reject the null
hypothesis in favor of the alternative.
2. Right-Tail Test:
If the value of the test statistic falls in the critical region which lies
in the right tail of the t-distribution, then we reject the null
hypothesis in favor of the alternative.
Copyright 1996 Lawrence C. Marsh
5.23
Format for Hypothesis Testing
1. Determine null and alternative hypotheses.
2. Specify the test statistic and its distribution
as if the null hypothesis were true.
3. Select a and determine the rejection region.
4. Calculate the sample value of test statistic.
5. State your conclusion.
Copyright 1996 Lawrence C. Marsh
practical vs. statistical
significance in economics
5.24
Practically but not statistically significant:
When sample size is very small, a large average gap between
the salaries of men and women might not be statistically
significant.
Statistically but not practically significant:
When sample size is very large, a small correlation (say, r =
0.00000001) between the winning numbers in the PowerBall
Lottery and the Dow-Jones Stock Market Index might be
statistically significant.
Copyright 1996 Lawrence C. Marsh
Type I and Type II errors
5.25
Type I error:
We make the mistake of rejecting the null
hypothesis when it is true.
a = P(rejecting H0 when it is true).
Type II error:
We make the mistake of failing to reject the null
hypothesis when it is false.
b = P(failing to reject H0 when it is false).
Copyright 1996 Lawrence C. Marsh
5.26
Prediction Intervals
A (1-a)x100% prediction interval for yo is:
^
yo ± tc se( f )
f = y^ o - yo
se( f ) =
^
var( f )
2
(
x
x
)
1
o
^
^
2
var( f ) = s 1 +
+
T
S(x t - x)2
Copyright 1996 Lawrence C. Marsh
Chapter 6
6.1
The Simple Linear
Regression Model
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
Explaining Variation in yt
6.2
Predicting yt without any explanatory variables:
yt = b1 + et
T
S(yt - b1) = 0
t=1
T
S
T
S
2
et = (yt
t=1
t=1
T
- b1)
2
T
S
b1
2
e
t=1 t
T
= -2 tS
(y
b
)
=
0
t
1
=1
Syt - Tb1 = 0
t=1
b1 = y
Why not y?
Copyright 1996 Lawrence C. Marsh
Explaining Variation in yt
6.3
^
yt = b1 + b2xt + et
^
Explained variation: yt = b1 + b2xt
Unexplained variation:
^e = y - ^y = y - b - b x
t
t
t
t
1
2 t
Copyright 1996 Lawrence C. Marsh
Explaining Variation in yt
^
^
yt = yt + et
6.4
using y as baseline
^
^
yt - y = yt - y + et Why not y?
T
T
cross
^2 product
t=1 t
term
drops
out
T
2
^
S(yt-y) = S(yt-y) +Se
t=1
2
t=1
SST = SSR + SSE
Copyright 1996 Lawrence C. Marsh
Total Variation in yt
SST = total sum of squares
SST measures variation of yt around y
T
SST
= S(yt - y)
t=1
2
6.5
Copyright 1996 Lawrence C. Marsh
Explained Variation in yt
SSR = regression sum of squares
^
yt = b1 + b2xt
^
Fitted yt values:
^
SSR measures variation of yt around y
T
SSR
= S(yt - y)
t=1
^
2
6.6
Copyright 1996 Lawrence C. Marsh
Unexplained Variation in yt
SSE = error sum of squares
^
^
et = yt-yt = yt - b1 - b2xt
^
SSE measures variation of yt around yt
T
SSE
T
= S(yt - yt) = S
t=1
^ 2
t=1
^e 2
t
6.7
Copyright 1996 Lawrence C. Marsh
Analysis of Variance Table
Table 6.1 Analysis of Variance Table
Source of
Sum of
Mean
Variation
DF
Squares
Square
Explained
1
SSR
SSR/1
Unexplained T-2
SSE SSE/(T-2)
^ 2]
[= s
Total
T-1
SST
6.8
Copyright 1996 Lawrence C. Marsh
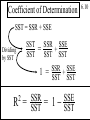
Coefficient of Determination
What proportion of the variation
in yt is explained?
0 ٹR 1ٹ
2
2
R =
SSR
SST
6.9
Copyright 1996 Lawrence C. Marsh
Coefficient of Determination
SST = SSR + SSE
SST
SST
Dividing
by SST
=
SSR SSE
+
SST SST
1 =
2
R =
SSR
SST
SSR + SSE
SST SST
= 1-
SSE
SST
6.10
Copyright 1996 Lawrence C. Marsh
Coefficient of Determination
6.11
R2 is only a descriptive measure.
2
R
does not measure the quality
of the regression model.
Focusing solely on maximizing
R2 is not a good idea.
Copyright 1996 Lawrence C. Marsh
Correlation Analysis
Population:
r=
Sample:
r=
6.12
cov(X,Y)
var(X) var(Y)
^
cov(X,Y)
^
var(X)
^
var(Y)
Copyright 1996 Lawrence C. Marsh
Correlation Analysis
T
6.13
^ =S
var(X)
(x
x)
(
T-1)
/
t
t=1
2
T
2
^
var(Y) = S(yt - y) /(T-1)
t=1
T
^
cov(X,Y)
= S(xt - x)(yt - y)/(T-1)
t=1
Copyright 1996 Lawrence C. Marsh
6.14
Correlation Analysis
Sample Correlation Coefficient
S(xt - x)(yt - y)
T
r=
t=1
T
S(xt - x) S(yt - y)
T
t=1
2
t=1
2
Copyright 1996 Lawrence C. Marsh
Correlation Analysis and R
2
6.15
For simple linear regression analysis:
2
r = R
2
2
R is also the correlation
^
between yt and yt
measuring “goodness of fit”.
Copyright 1996 Lawrence C. Marsh
Regression Computer Output
6.16
Typical computer output of regression estimates:
Table 6.2 Computer Generated Least Squares Results
(1)
(2)
(3)
(4)
(5)
Parameter Standard T for H0:
Variable
Estimate
Error Parameter=0 Prob>|T|
INTERCEPT 40.7676 22.1387
1.841
0.0734
X
0.1283
0.0305
4.201
0.0002
Copyright 1996 Lawrence C. Marsh
Regression Computer Output
b1 = 40.7676
b2 = 0.1283
se(b1) =
^ 1) = 490.12
var(b
se(b2) =
^ 2) = 0.0009326 = 0.0305
var(b
t =
t =
= 22.1287
=
40.7676
22.1287
= 1.84
b2
=
se(b2)
0.1283
0.0305
= 4.20
b1
se(b1)
6.17
Copyright 1996 Lawrence C. Marsh
Regression Computer Output
6.18
Sources of variation in the dependent variable:
Table 6.3 Analysis of Variance Table
Sum of
Mean
Source
DF
Squares
Square
Explained
1 25221.2229 25221.2229
Unexplained 38 54311.3314 1429.2455
Total
39 79532.5544
R-square: 0.3171
Copyright 1996 Lawrence C. Marsh
Regression Computer Output
SST = S(yt-y) = 79532
2
^
SSR = S(yt-y) = 25221
2
^
SSE = e = 54311
2
S
t
SSE /(T-2) = s^2
2
R =
SSR
SST
= 1429.2455
= 1-
SSE
SST
= 0.317
6.19
Copyright 1996 Lawrence C. Marsh
Reporting Regression Results
6.20
yt = 40.7676 + 0.1283xt
(s.e.) (22.1387) (0.0305)
yt = 40.7676 + 0.1283xt
(t) (1.84) (4.20)
Copyright 1996 Lawrence C. Marsh
Reporting Regression Results
6.21
2
R = 0.317
2
This R value may seem low but it is
typical in studies involving cross-sectional
data analyzed at the individual or micro level.
2
A considerably higher R value would be
expected in studies involving time-series data
analyzed at an aggregate or macro level.
Copyright 1996 Lawrence C. Marsh
Effects of Scaling the Data
6.22
Changing the scale of x
The estimated
coefficient and
standard error
change but the
other statistics
are unchanged.
yt = b1 + b2xt + et
yt = b1 + (cb2)(xt/c) + et
yt = b1 + b*2x*t + et
where
*
b =
2
cb2 and x*t = xt/c
Copyright 1996 Lawrence C. Marsh
Effects of Scaling the Data
6.23
Changing the scale of y
yt = b1 + b2xt + et
yt/c = (b1/c) + (b2/c)xt + et/c
All statistics
are changed
except for
the t-statistics
2
and R value.
*
*
*
y =b +b x
t
1
2
*
+
e
t
t
where y*t = yt/c
b* = b /c and
1
1
e*t = et/c
b*2 = b2/c
Copyright 1996 Lawrence C. Marsh
Effects of Scaling the Data
6.24
Changing the scale of x and y
yt = b1 + b2xt + et
No change in
the R2 or the
t-statistics or
in regression
results for b2
but all other
stats change.
yt/c = (b1/c) + (cb2/c)xt/c + et/c
*
*
y =b +
t
1
b2x*t + e*t
where y*t = yt/c
b* = b /c and
1
1
e*t = et/c
x*t = xt/c
Copyright 1996 Lawrence C. Marsh
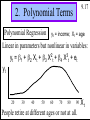
Functional Forms
6.25
The term linear in a simple
regression model does not mean
a linear relationship between
variables, but a model in which
the parameters enter the model
in a linear way.
Copyright 1996 Lawrence C. Marsh
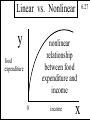
Linear vs. Nonlinear
6.27
Linear Statistical Models:
yt = b1 + b2xt + et
yt = b1 + b2 ln(xt) + et
ln(yt) = b1 + b2xt + et
yt = b1 +
2
b2xt +
et
Nonlinear Statistical Models:
yt = b1 +
b3
b2xt +
et
b3
yt
yt = b1 + b2xt + exp(b3xt) + et
= b1 + b2xt + et
Copyright 1996 Lawrence C. Marsh
6.27
Linear vs. Nonlinear
y
nonlinear
relationship
between food
expenditure and
income
food
expenditure
0
income
x
Copyright 1996 Lawrence C. Marsh
Useful Functional Forms
Look at
each form
and its
slope and
elasticity
1.
2.
3.
4.
5.
6.
Linear
Reciprocal
Log-Log
Log-Linear
Linear-Log
Log-Inverse
6.28
Copyright 1996 Lawrence C. Marsh
Useful Functional Forms
6.29
Linear
yt = b1 + b2xt + et
slope: b2
xt
elasticity: b2 y
t
Copyright 1996 Lawrence C. Marsh
6.30
Useful Functional Forms
Reciprocal
yt = b1 + b2 xt + et
1
slope:
1
- b2 2
xt
elasticity:
1
- b2 x y
t
t
Copyright 1996 Lawrence C. Marsh
Useful Functional Forms
Log-Log
ln(yt)= b1 + b2ln(xt) + et
yt
slope: b2 x
t
elasticity: b2
6.31
Copyright 1996 Lawrence C. Marsh
Useful Functional Forms
Log-Linear
ln(yt)= b1 + b2xt + et
slope: b2 yt
elasticity: b2xt
6.32
Copyright 1996 Lawrence C. Marsh
6.33
Useful Functional Forms
Linear-Log
yt= b1 + b2ln(xt) + et
slope:
1
_
b2
xt
elasticity:
1
_
b2
yt
Copyright 1996 Lawrence C. Marsh
Useful Functional Forms
Log-Inverse
ln(yt) = b1 - b2 x + et
1
t
yt
slope: b2 2
xt
1
elasticity: b2 x
t
6.34
Copyright 1996 Lawrence C. Marsh
Error Term Properties
1.
2.
3.
4.
E (et) = 0
2
var (et) = s
cov(ei, ej) = 0
2
et ~ N(0, s )
6.35
Copyright 1996 Lawrence C. Marsh
Economic Models
1.
2.
3.
4.
5.
Demand Models
Supply Models
Production Functions
Cost Functions
Phillips Curve
6.36
Copyright 1996 Lawrence C. Marsh
Economic Models
6.37
1. Demand Models
* quality demanded (yd) and price (x)
* constant elasticity
ln(yt )= b1 + b2ln(x)t + et
d
Copyright 1996 Lawrence C. Marsh
Economic Models
6.38
2. Supply Models
* quality supplied (ys) and price (x)
* constant elasticity
ln(yt )= b1 + b2ln(xt) + et
s
Copyright 1996 Lawrence C. Marsh
Economic Models
6.39
3. Production Functions
* output (y) and input (x)
* constant elasticity
Cobb-Douglas Production Function:
ln(yt)= b1 + b2ln(xt) + et
Copyright 1996 Lawrence C. Marsh
Economic Models
4a. Cost Functions
* total cost (y) and output (x)
yt = b1 + b2
2
x
+
e
t
t
6.40
Copyright 1996 Lawrence C. Marsh
Economic Models
6.41
4b. Cost Functions
* average cost (x/y) and output (x)
(yt/xt) = b1/xt + b2xt + et/xt
Copyright 1996 Lawrence C. Marsh
Economic Models
6.42
5. Phillips Curve
nonlinear in both variables and parameters
* wage rate (wt) and time (t)
wt - wt-1
1
% Dwt = w
= ga + gh u
t-1
t
unemployment rate, ut
Copyright 1996 Lawrence C. Marsh
Chapter 7
7.1
The Multiple
Regression Model
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
Two Explanatory Variables
yt = b1 + b2xt2 + b3xt3 + et
xt‘s affect yt
separately
yt
= b2
xt2
yt
= b3
xt3
But least squares estimation of b2
now depends upon both xt2 and xt3 .
7.2
Copyright 1996 Lawrence C. Marsh
Correlated Variables
yt = b1 + b2xt2 + b3xt3 + et
yt = output
xt2 = capital
xt3 = labor
Always 5 workers per machine.
If number of workers per machine
is never varied, it becomes impossible
to tell if the machines or the workers
are responsible for changes in output.
7.3
Copyright 1996 Lawrence C. Marsh
The General Model
7.4
yt = b1 + b2xt2 + b3xt3 +. . .+ bKxtK + et
The parameter b1 is the intercept (constant) term.
The “variable” attached to b1 is xt1= 1.
Usually, the number of explanatory variables
is said to be K-1 (ignoring xt1= 1), while the
number of parameters is K. (Namely: b1 . . . bK).
Copyright 1996 Lawrence C. Marsh
Statistical Properties of et
1. E(et) = 0
2
s
2. var(et) =
3. cov(et , es) = 0 for t ° s
4. et ~ N(0,
2
s)
7.5
Copyright 1996 Lawrence C. Marsh
Statistical Properties of yt
7.6
1. E (yt) = b1 + b2xt2 +. . .+ bKxtK
2. var(yt) = var(et) = s2
3. cov(yt ,ys) = cov(et , es) = 0 t°s
4. yt ~ N(b1+b2xt2 +. . .+bKxtK, s2)
Copyright 1996 Lawrence C. Marsh
Assumptions
7.7
1. yt = b1 + b2xt2 +. . .+ bKxtK + et
2. E (yt) = b1 + b2xt2 +. . .+ bKxtK
2
s
3. var(yt) = var(et) =
4. cov(yt ,ys) = cov(et ,es) = 0
t°s
5. The values of xtk are not random
6. yt ~ N(b1+b2xt2 +. . .+bKxtK, s2)
Copyright 1996 Lawrence C. Marsh
Least Squares Estimation
7.8
yt = b1 + b2xt2 + b3xt3 + et
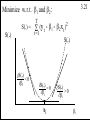
T
S ؛S(b1, b2, b3) = tS= 1(yt - b1 - b2xt2 - b3xt3)
Define:
y*t = yt - y
x*t2 = xt2 - x2
x*t3 = xt3 - x3
2
Copyright 1996 Lawrence C. Marsh
Least Squares Estimators
b1 = y - b1 - b2x2 - b3x3
b2 =
b3 =
(S
2
*
t2)(Sxt3
y*x*
t
(S
(S
2
*
x
t2
)
- (Sy*t x*t3)(Sx*t2x*t3)
2
*
)(Sx )
t3
2
*
-
2
*
*
(Sx x )
t2 t3
)(Sxt2 ) - (S t t2)(S t3 t2)
2
2
2
*
*
*
*
(Sxt2 )(Sxt3 ) - (Sxt2xt3)
*
y x*
t t3
*
*
yx
*
*
x x
7.9
Copyright 1996 Lawrence C. Marsh
Dangers of Extrapolation
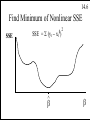
7.10
Statistical models generally are good only
“within the relevant range”. This means
that extending them to extreme data values
outside the range of the original data often
leads to poor and sometimes ridiculous results.
If height is normally distributed and the
normal ranges from minus infinity to plus
infinity, pity the man minus three feet tall.
Copyright 1996 Lawrence C. Marsh
Error Variance Estimation
7.11
Unbiased estimator of the error variance:
^2 =
s
S
2
^
e
t
T-K
Transform to a chi-square distribution:
^2
(T - K) s
s
2
~
c
T-K
Copyright 1996 Lawrence C. Marsh
Gauss-Markov Theorem
7.12
Under the assumptions of the
multiple regression model, the
ordinary least squares estimators
have the smallest variance of
all linear and unbiased estimators.
This means that the least squares
estimators are the Best Linear
Unbiased Estimators (BLUE).
Copyright 1996 Lawrence C. Marsh
7.13
Variances
yt = b1 + b2xt2 + b3xt3 + et
var(b2) =
var(b3) =
s
2
(1- r23)
2
S(xt2 - x2)
s
2
(1- r23)
2
2
S(xt3 - x3)
where r23 =
When r23 = 0
these reduce
to the simple
regression
formulas.
2
S(xt2 - x2)(xt3 - x3)
S(xt2 - x2) S(xt3 - x3)
2
2
Copyright 1996 Lawrence C. Marsh
7.14
Variance Decomposition
The variance of an estimator is smaller when:
1. The error variance, s , is smaller: s
2
2. The sample size, T, is larger:
T
2
(xt2 - x2)
S
t=1
0.
2
.
3. The variable’s values are more spread out:
(xt2 - x2) .
2
4. The correlation is close to zero: r23
0.
2
Copyright 1996 Lawrence C. Marsh
7.15
Covariances
yt = b1 + b2xt2 + b3xt3 + et
cov(b2,b3) =
- r23 s
2
(1- r23)
where r23 =
2
S(xt2 - x2) S(xt3 - x3)
2
2
S(xt2 - x2)(xt3 - x3)
S(xt2 - x2) S(xt3 - x3)
2
2
Copyright 1996 Lawrence C. Marsh
Covariance Decomposition
7.16
The covariance between any two estimators
is larger in absolute value when:
1. The error variance, s , is larger.
2
2. The sample size, T, is smaller.
3. The values of the variables are less spread out.
4. The correlation, r23, is high.
Copyright 1996 Lawrence C. Marsh
Var-Cov Matrix
7.17
yt = b1 + b2xt2 + b3xt3 + et
The least squares estimators b1, b2, and b3
have covariance matrix:
var(b1) cov(b1,b2) cov(b1,b3)
cov(b1,b2,b3) = cov(b1,b2) var(b2) cov(b2,b3)
cov(b1,b3) cov(b2,b3) var(b3)
Copyright 1996 Lawrence C. Marsh
7.18
Normal
yt = b1 + b2x2t + b3x3t +. . .+ bKxKt + et
yt ~N (b1 + b2x2t + b3x3t +. . .+ bKxKt), s 2
This implies and is implied by: et ~ N(0, s )
2
Since bk is a linear
function of the yt’s:
bk ~ N bk, var(bk)
bk - bk
z =
~ N(0,1)
var(bk)
for k = 1,2,...,K
Copyright 1996 Lawrence C. Marsh
Student-t
7.19
Since generally the population variance
of bk , var(bk) , is unknown, we estimate
^ k) which uses s
^ 2 instead of s 2.
it with var(b
t =
bk - b k
^ k)
var(b
bk - b k
=
se(bk)
t has a Student-t distribution with df=(T-K).
Copyright 1996 Lawrence C. Marsh
Interval Estimation
7.20
bk - bk
P -tc ٹ
ٹtc = 1 - a
se(bk)
tc is critical value for (T-K) degrees of freedom
such that P(t چtc) = a /2.
P bk - tc se(bk) ٹbk ٹbk + tc se(bk)
Interval endpoints:
= 1-a
bk - tc se(bk) , bk + tc se(bk)
Copyright 1996 Lawrence C. Marsh
Chapter 8
8.1
Hypothesis Testing
and
Nonsample Information
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
Chapter 8: Overview
1.
2.
3.
4.
5.
6.
7.
Student-t Tests
Goodness-of-Fit
F-Tests
ANOVA Table
Nonsample Information
Collinearity
Prediction
8.2
Copyright 1996 Lawrence C. Marsh
Student - t Test
8.3
yt = b1 + b2Xt2 + b3Xt3 + b4Xt4 + et
Student-t tests can be used to test any linear
combination of the regression coefficients:
H0: b1 = 0
H0: b2 + b3 + b4 = 1
H0: 3b2 - 7b3 = 21 H0: b2 - b3 5 ٹ
Every such t-test has exactly T-K degrees of freedom
where K=#coefficients estimated(including the intercept).
Copyright 1996 Lawrence C. Marsh
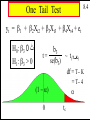
One Tail Test
8.4
yt = b1 + b2Xt2 + b3Xt3 + b4Xt4 + et
H0: b3 0 ٹ
H1: b3 > 0
b3
~ t (T-K)
t=
se(b3)
df = T- K
= T- 4
a
(1 - a)
0
tc
Copyright 1996 Lawrence C. Marsh
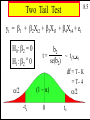
Two Tail Test
8.5
yt = b1 + b2Xt2 + b3Xt3 + b4Xt4 + et
H0: b2 = 0
H1: b2 ° 0
b2
~ t (T-K)
t=
se(b2)
df = T- K
= T- 4
a/2
(1 - a)
a/2
-tc
0
tc
Copyright 1996 Lawrence C. Marsh
Goodness - of - Fit
Coefficient of Determination
T
2
R =
SSR
=
SST
0 ٹR 1ٹ
2
S(yt - y)
^
2
t=1
T
S(yt - y)
t=1
2
8.6
Copyright 1996 Lawrence C. Marsh
Adjusted R-Squared
8.7
Adjusted Coefficient of Determination
Original:
2
R =
SSR
SST
= 1-
SSE
SST
Adjusted:
R = 12
SSE/(T-K)
SST/(T-1)
Copyright 1996 Lawrence C. Marsh
Computer Output
Table 8.2 Summary of Least Squares Results
Variable Coefficient Std Error t-value p-value
constant
104.79
6.48
16.17
0.000
price
-6.642
3.191
-2.081
0.042
advertising 2.984
0.167 17.868
0.000
b2
-6.642
t=
=
= -2.081
se(b2)
3.191
8.8
Copyright 1996 Lawrence C. Marsh
Reporting Your Results
8.9
Reporting standard errors:
^y = 104.79 - 6.642 X + 2.984 X
t
t2
t3
(6.48)
(3.191)
(0.167)
(s.e.)
Reporting t-statistics:
^y = 104.79 - 6.642 X + 2.984 X
t
t2
t3
(16.17)
(-2.081)
(17.868)
(t)
Copyright 1996 Lawrence C. Marsh
Single Restriction F-Test
8.10
yt = b1 + b2Xt2 + b3Xt3 + b4Xt4 + et
(SSER - SSEU)/J
F =
SSEU/(T-K)
=
(1964.758 - 1805.168)/1
1805.168/(52 - 3)
= 4.33
H0: b2 = 0
H1: b2 ° 0
dfn = J = 1
dfd = T- K = 49
By definition this is the t-statistic squared:
t = - 2.081
F = t2 = 4.33
Copyright 1996 Lawrence C. Marsh
Multiple Restriction F-Test
8.11
yt = b1 + b2Xt2 + b3Xt3 + b4Xt4 + et
H0: b2 = 0, b4 = 0
H1: H0 not true
(SSER - SSEU)/J
F =
SSEU/(T-K)
dfn = J = 2
First run the restricted
regression by dropping
dfd = T- K = 49
Xt2 and Xt4 to get SSER.
Next run unrestricted regression to get SSEU .
Copyright 1996 Lawrence C. Marsh
8.12
F-Tests
F-Tests of this type are always right-tailed,
even for left-sided or two-sided hypotheses,
f(F) because any deviation from the null will
make the F value bigger (move rightward).
(SSER - SSEU)/J
F =
SSEU/(T-K)
a
(1 - a)
0
Fc
F
Copyright 1996 Lawrence C. Marsh
F-Test of Entire Equation
8.13
yt = b1 + b2Xt2 + b3Xt3 + et
We ignore b1. Why?
(SSER - SSEU)/J
F =
SSEU/(T-K)
H0: b2 = b3 = 0
H1: H0 not true
dfn = J = 2
(13581.35 - 1805.168)/2
dfd = T- K = 49
=
1805.168/(52 - 3)
a = 0.05
= 159.828
Reject H ! Fc = 3.187
0
Copyright 1996 Lawrence C. Marsh
8.14
ANOVA Table
Table 8.3 Analysis of Variance Table
Sum of
Mean
Source
DF Squares
Square F-Value
Explained
2 11776.18 5888.09 158.828
Unexplained 49 1805.168
36.84
Total
51 13581.35
p-value: 0.0001
2
R =
SSR
=
SST
11776.18
13581.35
=
0.867
Copyright 1996 Lawrence C. Marsh
Nonsample Information
8.15
A certain production process is known to be
Cobb-Douglas with constant returns to scale.
ln(yt) = b1 + b2 ln(Xt2) + b3 ln(Xt3) + b4 ln(Xt4) + et
b4 = (1 - b2 - b3)
where b2 + b3 + b4 = 1
ln(yt /Xt4) = b1 + b2 ln(Xt2/Xt4) + b3 ln(Xt3 /Xt4) + et
y*t = b1 + b2 X*t2 + b3 X*t3 + b4 X*t4 + et
Run least squares on the transformed model.
Interpret coefficients same as in original model.
Copyright 1996 Lawrence C. Marsh
Collinear Variables
8.16
The term “independent variable” means
an explanatory variable is independent of
of the error term, but not necessarily
independent of other explanatory variables.
Since economists typically have no control
over the implicit “experimental design”,
explanatory variables tend to move
together which often makes sorting out
their separate influences rather problematic.
Copyright 1996 Lawrence C. Marsh
Effects of Collinearity
8.17
A high degree of collinearity will produce:
1. no least squares output when collinearity is exact.
2. large standard errors and wide confidence intervals.
2
3. insignificant t-values even with high R and a
significant F-value.
4. estimates sensitive to deletion or addition of a few
observations or “insignificant” variables.
5. good “within-sample”(same proportions) but poor
“out-of-sample”(different proportions) prediction.
Copyright 1996 Lawrence C. Marsh
Identifying Collinearity
8.18
Evidence of high collinearity include:
1. a high pairwise correlation between two
explanatory variables.
2. a high R-squared when regressing one
explanatory variable at a time on each of the
remaining explanatory variables.
3. a statistically significant F-value when the
t-values are statistically insignificant.
4. an R-squared that doesn’t fall by much when
dropping any of the explanatory variables.
Copyright 1996 Lawrence C. Marsh
Mitigating Collinearity
8.19
Since high collinearity is not a violation of
any least squares assumption, but rather a
lack of adequate information in the sample:
1.
2.
3.
4.
collect more data with better information.
impose economic restrictions as appropriate.
impose statistical restrictions when justified.
if all else fails at least point out that the poor
model performance might be due to the
collinearity problem (or it might not).
Copyright 1996 Lawrence C. Marsh
Prediction
yt = b1 + b2Xt2 + b3Xt3 + et
Given a set of values for the explanatory
variables, (1 X02 X03), the best linear
unbiased predictor of y is given by:
^y = b + b X + b X
0
1
2 02
3 03
This predictor is unbiased in the sense
that the average value of the forecast
error is zero.
8.20
Copyright 1996 Lawrence C. Marsh
Chapter 9
9.1
Extensions
of the Multiple
Regression Model
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
Topics for This Chapter
1.
2.
3.
4.
5.
6.
7.
Intercept Dummy Variables
Slope Dummy Variables
Different Intercepts & Slopes
Testing Qualitative Effects
Are Two Regressions Equal?
Interaction Effects
Dummy Dependent Variables
9.2
Copyright 1996 Lawrence C. Marsh
Intercept Dummy Variables
Dummy variables are binary (0,1)
yt = b1 + b2Xt + b3Dt + et
yt = speed of car in miles per hour
Xt = age of car in years
Dt = 1 if red car, Dt = 0 otherwise.
Police: red cars travel faster.
H0: b3 = 0
H1: b3 > 0
9.3
Copyright 1996 Lawrence C. Marsh
yt = b1 + b2Xt + b3Dt + et
red cars: yt = (b1 + b3) + b2xt + et
other cars: yt = b1 + b2Xt + et
yt
b1 + b 3
b1
miles
per
hour
b2
b2
0
age in years
Xt
9.4
Copyright 1996 Lawrence C. Marsh
Slope Dummy Variables
9.5
yt = b1 + b2Xt + b3DtXt + et
Stock portfolio: Dt = 1 Bond portfolio: Dt = 0
yt
yt = b1 + (b2 + b3)Xt + et
value
of
porfolio
stocks
bonds
b1
b1 = initial
investment
0
yt = b1 + b2Xt + et
years
Xt
Copyright 1996 Lawrence C. Marsh
Different Intercepts & Slopes
9.6
yt = b1 + b2Xt + b3Dt + b4DtXt + et
“miracle” seed: Dt = 1
harvest
weight
of corn
yt
b1 + b3
b1
regular seed: Dt = 0
yt = (b1 + b3) + (b2 + b4)Xt + et
“miracle”
yt = b1 + b2Xt + et
regular
rainfall
Xt
Copyright 1996 Lawrence C. Marsh
yt = b1 + b2 Xt + b3 Dt + et
9.7
For men: Dt = 1.
For women: Dt = 0.
yt
yt = (b1+ b3) + b2 Xt + et
wage
rate
Men
Women
b2
yt = b1 + b2 Xt + et
b 1+ b 3
.
b1
.
Testing for
discrimination
in starting wage
0
years of experience
b2
H0: b3 = 0
H1: b3 > 0
Xt
C. Marsh
9.8
yt = b1 + Copyright
b5 Xt +1996
b6 DLawrence
X
+
e
t t
t
For men Dt = 1.
For women Dt = 0.
yt
yt = b1 + (b5 + b6 )Xt + et
wage
rate
b5 + b6
Men
Women
yt = b1 + b5 Xt + et
b5
b1
Men and women have the same
starting wage, b1 , but their wage rates
increase at different rates (diff.= b6 ).
b6 > 0 means that men’s wage rates are
increasing faster than women's wage rates.
0
years of experience
Xt
Copyright 1996 Lawrence C. Marsh
An Ineffective Affirmative Action Plan
9.9
yt = b1 + b2 Xt + b3 Dt + b4 Dt Xt + et
yt
women are started
at a higher wage.
wage
rate
yt = (b1 + b3) + (b2 + b4) Xt + et
Men
Women
b2
b1
b1 + b3
Note:
( b3 < 0 )
0
yt = b1 + b2 Xt + et
Women are given a higher starting wage, b1 ,
while men get the lower starting wage, b1 + b3 ,
(b3 < 0 ). But, men get a faster rate of increase
in their wages, b2 + b4 , which is higher than the
rate of increase for women, b2 , (since b4 > 0 ).
years of experience
Xt
Copyright 1996 Lawrence C. Marsh
Testing Qualitative Effects
9.10
1. Test for differences in intercept.
2. Test for differences in slope.
3. Test for differences in both
intercept and slope.
Copyright 1996 Lawrence C. Marsh
9.11
men: Dt = 1 ; women: Dt = 0
Yt = b 1 + b 2 X t + b 3 Dt + b 4 D t X t + e t
H0: b3 0 vs. H1: b3 > 0
Testing for
discrimination in
starting wage.
b3 - 0
Est. Var b3
H0: b4 0 vs. H1: b4 > 0
Testing for
discrimination in
wage increases.
intercept
b4 - 0
Est. Var b 4
tn-4
ک
slope
tn-4
ک
Copyright 1996 Lawrence C. Marsh
9.12
Ho: b3 = b4 = 0
H1 : otherwise
Testing:
( SSE R - SSE U ) / 2
SSE U / ( T - 4 )
~ F
2
T -4
T
SSE U = ( هyt -b1-b2Xt -b3 Dt -b4 Dt Xt )
t=1
and
SSE R =
T
ه
t =1
intercept and slope
( yt - b 1 - b 2 X t )
2
2
Copyright 1996 Lawrence C. Marsh
Are Two Regressions Equal?
9.13
variations of “The Chow Test”
I. Assuming equal variances (pooling):
men: Dt = 1 ;
women: Dt = 0
yt = b1 + b2 Xt + b3 Dt + b4 Dt Xt + et
Ho: b3 = b4 = 0
vs. H1: otherwise
yt = wage rate
Xt = years of experience
This model assumes equal wage rate variance.
Copyright 1996 Lawrence C. Marsh
II. Allowing for unequal variances:
(running three regressions)
9.14
Forcing men and women to have same b1, b2.
Everyone: yt = b1 + b2 Xt + et
SSER
Allowing men and women to be different.
Men only: ytm = d1 + d2 Xtm + etm
SSEm
Women only: ytw = g1 + g2 Xtw + etw
SSEw
J = # restrictions
(SSER - SSEU)/J
F=
K=unrestricted coefs.
SSEU /(T-K)
J=2
K = 4 where SSEU = SSEm + SSEw
Copyright 1996 Lawrence C. Marsh
9.15
Interaction Variables
1. Interaction Dummies
2. Polynomial Terms
(special case of continuous interaction)
3. Interaction Among Continuous Variables
Copyright 1996 Lawrence C. Marsh
1. Interaction Dummies
9.16
Wage Gap between Men and Women
yt = wage rate; Xt = experience
For men: Mt = 1. For women: Mt = 0.
For black: Bt = 1. For nonblack: Bt = 0.
No Interaction: wage gap assumed the same:
yt = b1 + b2 Xt + b3 Mt + b4 Bt + et
Interaction: wage gap depends on race:
yt = b1 + b2 Xt + b3 Mt + b4 Bt + b5 Mt Bt + et
Copyright 1996 Lawrence C. Marsh
9.17
2. Polynomial Terms
Polynomial Regression
yt = income; Xt = age
Linear in parameters but nonlinear in variables:
yt = b1 + b2 X t +
2
b3 X t +
3
b4 X t
+ et
yt
20
30
40
50
60
70
80
90
People retire at different ages or not at all.
Xt
Copyright 1996 Lawrence C. Marsh
Polynomial Regression
yt = income; Xt = age
yt = b1 + b2 X t +
2
b3 X t +
3
b4 X t
+ et
Rate income is changing as we age:
yt
2
= b2 + 2 b 3 X t + 3 b 4 X t
Xt
Slope changes as X t changes.
9.18
Copyright 1996 Lawrence C. Marsh
3. Continuous Interaction
9.19
Exam grade = f(sleep:Zt , study time:Bt)
yt = b1 + b2 Zt + b3 Bt + b4 Zt Bt + et
Sleep and study time do not act independently.
More study time will be more effective
when combined with more sleep and less
effective when combined with less sleep.
Copyright 1996 Lawrence C. Marsh
continuous interaction
9.20
Exam grade = f(sleep:Zt , study time:Bt)
yt = b1 + b2 Zt + b3 Bt + b4 Zt Bt + et
Your studying is
more effective
with more sleep.
yt
= b2 + b4 Zt
Bt
yt
Your mind sorts
= b2 + b4 Bt
Zt
things out while
you sleep (when you have things to sort out.)
Exam grade =
Copyright 1996 Lawrence C. Marsh
9.21
f(sleep:Zt , study time:Bt)
If Zt + Bt = 24 hours, then Bt = (24 - Zt)
yt = b1 + b2 Zt + b3 Bt + b4 Zt Bt + et
yt = b1+ b2 Zt +b3(24 - Zt) +b4 Zt (24 - Zt) + et
yt = (b1+24 b3) + (b2-b3+24 b4)Zt -
2
b4Z t
+ et
yt = d1 + d2 Zt + d3 Z2t + et
Sleep needed to maximize your exam grade:
- d2
yt
= d2 + 2d3 Zt = 0
Zt =
2d3
Zt
where d2 > 0 and d3 < 0
Copyright 1996 Lawrence C. Marsh
Dummy Dependent Variables
9.22
1. Linear Probability Model
2. Probit Model
3. Logit Model
Copyright 1996 Lawrence C. Marsh
Linear Probability Model
yi =
1 quits job
0 does not quit
yi = b1 + b2 Xi2 + b3 Xi3 + b4 Xi4 + ei
Xi2 = total hours of work each week
Xi3 = weekly paycheck
Xi4 = hourly pay (Xi3 divided by Xi2)
9.23
Copyright 1996 Lawrence C. Marsh
Linear Probability Model
9.24
yi = b1 + b2 Xi2 + b3 Xi3 + b4 Xi4 + ei
Read predicted values of yi off the regression line:
^y = b + b X + b X + b X
i
1
2 i2
3 i3
4 i4
^y
i
yt = 1
yt = 0
total hours of work each week
Xi2
Copyright 1996 Lawrence C. Marsh
Linear Probability Model
Problems with Linear Probability Model:
1. Probability estimates are sometimes
less than zero or greater than one.
2. Heteroskedasticity is present in that
the model generates a nonconstant
error variance.
9.25
Copyright 1996 Lawrence C. Marsh
9.26
Probit Model
zi = b1 + b2 Xi2 + . . .
latent variable, zi :
Normal probability density function:
f(zi) =
1
2p
e
-0.5zi2
Normal cumulative probability function:
F(zi) = P[ Z zi ] =
zi
ٍ
-
1
2p
e
-0.5u2
du
Copyright 1996 Lawrence C. Marsh
Probit Model
9.27
Since zi = b1 + b2 Xi2 + . . . , we can
substitute in to get:
pi = P[ Z b1 + b2Xi2 ] = F(b1 + b2Xi2)
yt = 1
yt = 0
total hours of work each week
Xi2
Copyright 1996 Lawrence C. Marsh
9.28
Logit Model
pi
is the probability of quitting the job.
pi =
Define pi :
1
1
+ e - (b1 + b2 Xi2 + . . .)
For b2 > 0,
pi
will approach 1 as Xi2
+
For b2 > 0,
pi
will approach 0 as Xi2
-
Copyright 1996 Lawrence C. Marsh
Logit Model
pi
9.29
is the probability of quitting the job.
pi =
1
1
+e
- (b + b X + . . .)
1
2 i2
yt = 1
yt = 0
total hours of work each week
Xi2
Copyright 1996 Lawrence C. Marsh
Maximum Likelihood
9.30
Maximum likelihood estimation (MLE)
is used to estimate Probit and Logit functions.
The small sample properties of MLE
are not known, but in large samples
MLE is normally distributed, and it is
consistent and asymptotically efficient.
Copyright 1996 Lawrence C. Marsh
Chapter 10
10.1
Heteroskedasticity
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
10.2
The Nature of Heteroskedasticity
Heteroskedasticity is a systematic pattern in
the errors where the variances of the errors
are not constant.
Ordinary least squares assumes that all
observations are equally reliable.
For efficiency (accurate estimation/prediction)
reweight observations to ensure equal error
variance.
Copyright 1996 Lawrence C. Marsh
Regression Model
10.3
yt = b1 + b2xt + et
zero mean:
E(et) = 0
homoskedasticity:
var(et) = s 2
nonautocorrelation:
cov(et, es) = 0
heteroskedasticity:
var(et) = st 2
t°s
Copyright 1996 Lawrence C. Marsh
10.4
Homoskedastic pattern of errors
consumption
yt
.
.
.
..
.
.
.
.
.
.
.
.
.
. ..
.
.
.
..
.
.
.
.
.
.
.
.
.
. . . . .
..
. .
.
income
xt
Copyright 1996 Lawrence C. Marsh
10.5
The Homoskedastic Case
f(yt)
.
.
x1
x2
x3
x4
.
.
income
xt
Copyright 1996 Lawrence C. Marsh
10.6
Heteroskedastic pattern of errors
consumption
.
yt
.
.
.
.
. . .
. .
. .
.
.
. .
.
.
.
.
. .. . .
.
.
.
.
.
.
.
.
.
. .
.
.
.
. . . .
.
. .
income
xt
Copyright 1996 Lawrence C. Marsh
The Heteroskedastic Case
10.7
f(yt)
.
.
.
rich people
poor people
x1
x2
x3
income
xt
Copyright 1996 Lawrence C. Marsh
10.8
Properties of Least Squares
1. Least squares still linear and unbiased.
2. Least squares not efficient.
3. Usual formulas give incorrect standard
errors for least squares.
4. Confidence intervals and hypothesis tests
based on usual standard errors are wrong.
Copyright 1996 Lawrence C. Marsh
yt = b1 + b2xt + et
heteroskedasticity:
var(et) = st 2
incorrect formula for least squares variance:
2
s
var(b2) =
S (xt - x )2
correct formula for least squares variance:
S st 2(xt - x )2
var(b2) =
[S (xt - x )2]2
10.9
Copyright 1996 Lawrence C. Marsh
Hal White’s Standard Errors
10.10
White’s estimator of the least squares variance:
est.var(b2) =
^e 2 x - x 2
S t ( t )
2 2
x
x
[S ( t ) ]
In large samples White’s standard error
(square root of estimated variance) is a
correct / accurate / consistent measure.
Copyright 1996 Lawrence C. Marsh
10.11
Two Types of Heteroskedasticity
1. Proportional Heteroskedasticity.
(continuous function(of xt, for example))
2. Partitioned Heteroskedasticity.
(discrete categories/groups)
Copyright 1996 Lawrence C. Marsh
10.12
Proportional Heteroskedasticity
yt = b1 + b2xt + et
E(et) = 0
var(et) = st 2
where st 2 = s 2 xt
cov(et, es) = 0 t ° s
The variance is
assumed to be
proportional to
the value of xt
Copyright 1996 Lawrence C. Marsh
std.dev. proportional to
xt
10.13
yt = b1 + b2xt + et
variance: var(et) = st 2
standard deviation:
st 2 = s 2 x t
st = s x t
To correct for heteroskedasticity divide the model by
yt
1
xt
et
= b1
+ b2
+
xt
xt
xt
xt
xt
Copyright 1996 Lawrence C. Marsh
yt
1
xt
et
= b1
+ b2
+
xt
xt
xt
xt
10.14
yt = b1xt1 + b2xt2 + et
*
*
var(et )
*
*
*
et
1
1
= var(
)=
var(et) = x s 2 xt
xt
xt
t
var(e*t ) = s 2
et is heteroskedastic, but et* is homoskedastic.
Copyright 1996 Lawrence C. Marsh
Generalized Least Squares
10.15
These steps describe weighted least squares:
1. Decide which variable is proportional to the
heteroskedasticity (xt in previous example).
2. Divide all terms in the original model by the
square root of that variable (divide by xt ).
3. Run least squares on the transformed model
which has new yt*, x*t1 and x*t2 variables
but no intercept.
Copyright 1996 Lawrence C. Marsh
Partitioned Heteroskedasticity
10.16
yt = b1 + b2xt + et
t = 1, ,100
yt = bushels per acre of corn
xt = gallons of water per acre (rain or other)
...
error variance of “field” corn: var(et) = s1 2
t = 1, . . . ,80
error variance of “sweet” corn: var(et) = s2 2
t = 81, . . . ,100
Copyright 1996 Lawrence C. Marsh
Reweighting Each Group’s Observations
10.17
“field” corn: yt = b1 + b2xt + et var(et) = s1 2
yt
1
xt
et
=
b
+
b
+
1
2
s1
s1
s1
s1
t = 1, . . . ,80
“sweet” corn: yt = b1 + b2xt + et var(et) = s2 2
yt
1
xt
et
=
b
+
b
+
1
2
s2
s2
s2
s2
t = 81, . . . ,100
Copyright 1996 Lawrence C. Marsh
10.18
Apply Generalized Least Squares
Run least squares separately on data for each group.
^ 2 provides estimator of s 2 using
s
1
1
the 80 observations on “field” corn.
^
s2 2 provides estimator of s2 2 using
the 20 observations on “sweet” corn.
Copyright 1996 Lawrence C. Marsh
10.19
Detecting Heteroskedasticity
Determine existence and nature of heteroskedasticity:
1. Residual Plots provide information on the
exact nature of heteroskedasticity (partitioned
or proportional) to aid in correcting for it.
2. Goldfeld-Quandt Test checks for presence
of heteroskedasticity.
Copyright 1996 Lawrence C. Marsh
Residual Plots
10.20
Plot residuals against one variable at a time
after sorting the data by that variable to try
to find a heteroskedastic pattern in the data.
et
0
.
.
.
.
.
.
.
.
.
.
. .
. .
. . . .. . . . . ..
.
.
.
.
..
.
.
.
.
.
.
.
.
xt
..
.
.
.
Copyright 1996 Lawrence C. Marsh
10.21
Goldfeld-Quandt Test
The Goldfeld-Quandt test can be used to detect
heteroskedasticity in either the proportional case
or for comparing two groups in the discrete case.
For proportional heteroskedasticity, it is first necessary
to determine which variable, such as xt, is proportional
to the error variance. Then sort the data from the
largest to smallest values of that variable.
Copyright 1996 Lawrence C. Marsh
10.22
In the proportional case, drop the middle
r observations where r T/6, then run
separate least squares regressions on the first
T1 observations and the last T2 observations.
Ho:
s1 2 = s2 2
H1:
s1 2 > s2 2
Goldfeld-Quandt
Test Statistic
GQ =
^
s
1
^
s
2
Use F
Table
2
2
~ F[T1-K1, T2-K2]
Small values of GQ support Ho while large values support H1.
Copyright 1996 Lawrence C. Marsh
More General Model
10.23
Structure of heteroskedasticity could be more complicated:
st 2 = s 2 exp{a1 zt1 + a2 zt2}
zt1 and zt2 are any observable variables upon
which we believe the variance could depend.
Note: The function exp{.} ensures that st2 is positive.
Copyright 1996 Lawrence C. Marsh
More General Model
10.24
st2 = s 2 exp{a1 zt1 + a2 zt2}
ln(st2) = ln(s 2) + a1 zt1 + a2 zt2
ln(st2) = a0 + a1 zt1 + a2 zt2
where a0 = ln(s 2)
Ho: a1 = 0, a2 = 0
H1: a1 ° 0, a2 ° 0
and/or
Least squares residuals, ^et
ln(e^t2) =a0 +a1zt1+a2zt2 + nt
the usual F test
Copyright 1996 Lawrence C. Marsh
Chapter 11
11.1
Autocorrelation
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
11.2
The Nature of Autocorrelation
For efficiency (accurate estimation/prediction)
all systematic information needs to be incorporated into the regression model.
Autocorrelation is a systematic pattern in the
errors that can be either attracting (positive)
or repelling (negative) autocorrelation.
Copyright 1996 Lawrence C. Marsh
11.3
Postive
Auto.
No
Auto.
et
0
et
0
et
Negative
Auto.
0
crosses line not enough (attracting)
.
.
. . ..
.. . .
.
. .
...
crosses line randomly
. ..
.
..
t
. . .. . . . . .
. . .
.
.
..
.
. .
..
.
.
.
.
. .t
.
too much (repelling)
. . crosses line
.
. . .
.
.
.
.
. . . t
.
.
.
.
.
Copyright 1996 Lawrence C. Marsh
Regression Model
11.4
yt = b1 + b2xt + et
zero mean:
E(et) = 0
homoskedasticity:
var(et) = s 2
nonautocorrelation:
cov(et, es) = 0
autocorrelation:
cov(et, es) ° 0 t ° s
t°s
Copyright 1996 Lawrence C. Marsh
Order of Autocorrelation
11.5
yt = b1 + b2xt + et
1st Order: et = r et-1 + nt
2nd Order: et = r1 et-1 + r2 et-2 + nt
3rd Order: et = r1 et-1 + r2 et-2 + r3 et-3 + nt
We will assume First Order Autocorrelation:
AR(1) :
et = r et-1 + nt
Copyright 1996 Lawrence C. Marsh
11.6
First Order Autocorrelation
yt = b1 + b2xt + et
et = r et-1 + nt
where -1 < r < 1
E(nt) = 0 var(nt) = sn2
cov(nt, ns) = 0 t ° s
These assumptions about nt imply the following about et :
E(et) = 0
2
s
var(et) = s e2 = n 2
1- r
cov(et, et-k) = se2 rk
for k > 0
corr(et, et-k) = rk
for k > 0
Copyright 1996 Lawrence C. Marsh
Autocorrelation creates some
Problems for Least Squares:
1. The least squares estimator is still linear
and unbiased but it is not efficient.
2. The formulas normally used to compute
the least squares standard errors are no
longer correct and confidence intervals and
hypothesis tests using them will be wrong.
11.7
Copyright 1996 Lawrence C. Marsh
Generalized Least Squares
AR(1) :
et = r et-1 + nt
yt = b1 + b2xt + et
substitute
in for et
yt = b1 + b2xt + r et-1 + nt
Now we need to get rid of et-1
(continued)
11.8
Copyright 1996 Lawrence C. Marsh
11.9
yt = b1 + b2xt + r et-1 + nt
yt = b1 + b2xt + et
et = yt - b1 - b2xt
et-1 = yt-1 - b1 - b2xt-1
lag the
errors
once
yt = b1 + b2xt + r(yt-1 - b1 - b2xt-1) + nt
(continued)
Copyright 1996 Lawrence C. Marsh
11.10
yt = b1 + b2xt + r(yt-1 - b1 - b2xt-1) + nt
yt = b1 + b2xt + ryt-1 - r b1 - r b2xt-1 + nt
yt - ryt-1 = b1(1-r) + b2(xt-rxt-1) + nt
*
yt
*
yt =
=
*
b1
+ b2x*t2 + nt
yt - ryt-1
x*t2 = (xt-rxt-1)
*
b1 =
b1(1-r)
*
yt =
yt - ryt-1
x*t2 = xt - rxt-1
Copyright
1996 Lawrence C. Marsh
*
11.11
b1 = b1(1-r)
*
yt
=
*
b1
+ b2x*t2 + nt
Problems estimating this model with least squares:
1. One observation is used up in creating the
transformed (lagged) variables leaving only
(T-1) observations for estimating the model.
2. The value of r is not known. We must find
some way to estimate it.
Copyright 1996 Lawrence C. Marsh
11.12
Recovering the 1st Observation
Dropping the 1st observation and applying least squares
is not the best linear unbiased estimation method.
Efficiency is lost because the variance
of the error associated with the 1st observation
is not equal to that of the other errors.
This is a special case of the heteroskedasticity
problem except that here all errors are assumed
to have equal variance except the 1st error.
Copyright 1996 Lawrence C. Marsh
11.13
Recovering the 1st Observation
The 1st observation should fit the original model as:
y1 = b1 + b2x1 + e1
with error variance: var(e1) = se2 = sn2 /(1-r2).
We could include this as the 1st observation for our
estimation procedure but we must first transform it so
that it has the same error variance as the other observations.
Note: The other observations all have error variance sn2.
Copyright 1996 Lawrence C. Marsh
y1 = b1 + b2x1 + e1
11.14
with error variance: var(e1) = se2 = sn2 /(1-r2).
The other observations all have error variance sn2.
Given any constant c :
var(ce1) = c2 var(e1).
If c = 1-r2 , then var( 1-r2 e1) = (1-r2) var(e1).
= (1-r2) se2
= (1-r2) sn2 /(1-r2)
=
The transformation n1 =
sn2
1-r2 e1 has variance sn2 .
Copyright 1996 Lawrence C. Marsh
11.15
y1 = b1 + b2x1 + e1
Multiply through by
1-r2
y1 =
1-r2
b1 +
The transformed error n1 =
1-r2 to get:
1-r2
b2x1 +
1-r2
e1
1-r2 e1 has variance sn2 .
This transformed first observation may now be
added to the other (T-1) observations to obtain
the fully restored set of T observations.
Copyright 1996 Lawrence C. Marsh
Estimating Unknown r Value
11.16
If we had values for the et’s, we could estimate:
et = r et-1 + nt
First, use least squares to estimate the model:
yt = b1 + b2xt + et
The residuals from this estimation are:
^e = y - b - b x
t
t
1
2 t
Copyright 1996 Lawrence C. Marsh
^e = y - b - b x
t
t
1
2 t
11.17
Next, estimate the following by least squares:
^e = r e^ + ^n
t
t-1
t
The least squares solution is:
T
^r =
^
^
e
e
S
t
t-1
t=2
T
2
^
e
S
t-1
t=2
Copyright 1996 Lawrence C. Marsh
Durbin-Watson Test
Ho: r = 0
11.18
vs. H1: r ° 0 , r > 0, or r < 0
The Durbin-Watson Test statistic, d, is :
T
d =
2
^
^
e
e
S
(
t
t-1)
t=2
T
2
^
e
S t
t=1
Copyright 1996 Lawrence C. Marsh
Testing for Autocorrelation
11.19
The test statistic, d, is approximately related to ^
r as:
^
d 2(1-r)
When ^
r = 0 , the Durbin-Watson statistic is d 2.
When ^
r = 1 , the Durbin-Watson statistic is d 0.
Tables for critical values for d are not always
readily available so it is easier to use the p-value
that most computer programs provide for d.
Reject Ho if p-value < a, the significance level.
Copyright 1996 Lawrence C. Marsh
Prediction with AR(1) Errors
11.20
When errors are autocorrelated, the previous period’s
error may help us predict next period’s error.
The best predictor, yT+1 , for next period is:
^
^
~
^
^
yT+1 = b1 + b2xT+1 + r eT
^
^
where b1 and b2 are generalized least squares
~
estimates and eT is given by:
~
^
^
eT = yT - b1 - b2xT
Copyright 1996 Lawrence C. Marsh
11.21
For h periods ahead, the best predictor is:
^
^
~
^
^
h
yT+h = b1 + b2xT+h + r eT
~
^
^
h
Assuming | r | < 1, the influence of r eT
diminishes the further we go into the future
(the larger h becomes).
Copyright 1996 Lawrence C. Marsh
Chapter 12
12.1
Pooling
Time-Series and
Cross-Sectional Data
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
12.2
Pooling Time and Cross Sections
yit = b1it + b2itx2it + b3itx3it + eit
for the ith firm in the tth time period
If left unrestricted,
this model requires different equations
for each firm in each time period.
Copyright 1996 Lawrence C. Marsh
12.3
Seemingly Unrelated Regressions
SUR models impose the restrictions:
b1it = b1i
b2it = b2i
b3it = b3i
yit = b1i + b2ix2it + b3ix3it + eit
Each firm gets its own coefficients: b1i , b2i and b3i
but those coefficients are constant over time.
Copyright 1996 Lawrence C. Marsh
Two-Equation SUR Model
12.4
The investment expenditures (INV) of General Electric (G)
and Westinghouse(W) may be related to their stock market
value (V) and actual capital stock (K) as follows:
INVGt = b1G + b2GVGt + b3GKGt + eGt
INVWt = b1W + b2WVWt + b3WKWt + eWt
i = G, W
t = 1, . . . , 20
Copyright 1996 Lawrence C. Marsh
12.5
Estimating Separate Equations
We make the usual error term assumptions:
E(eGt) = 0
E(eWt) = 0
var(eGt) = sG2
cov(eGt, eGs) = 0
var(eWt) = sW
2
cov(eWt, eWs) = 0
For now make the assumption of no correlation
between the error terms across equations:
cov(eGt, eWt) = 0
cov(eGt, eWs) = 0
Copyright 1996 Lawrence C. Marsh
12.6
homoskedasticity assumption:
2
2
sG = sW
2
2
Dummy variable model assumes that sG = sW :
INVt = b1G + d1Dt + b2GVt + d2DtVt + b3GKt + d3DtKt + et
For Westinghouse observations Dt = 1; otherwise Dt = 0.
b1W = b1G + d1
b2W = b2G + d2
b3W = b3G + d3
Copyright 1996 Lawrence C. Marsh
12.7
Problem with OLS on Each Equation
The first assumption of the Gauss-Markov
Theorem concerns the model specification.
If the model is not fully and correctly specified
the Gauss-Markov properties might not hold.
Any correlation of error terms across equations
must be part of model specification.
Copyright 1996 Lawrence C. Marsh
12.8
Correlated Error Terms
Any correlation between the
dependent variables of two or
more equations that is not due
to their explanatory variables
is by default due to correlated
error terms.
Copyright 1996 Lawrence C. Marsh
Which of the following models would
be likely to produce positively correlated
errors and which would produce
negatively correlations errors?
12.9
1. Sales of Pepsi vs. sales of Coke.
(uncontrolled factor: outdoor temperature)
2. Investments in bonds vs. investments in stocks.
(uncontrolled factor: computer/appliance sales)
3. Movie admissions vs. Golf Course admissions.
(uncontrolled factor: weather conditions)
4. Sales of butter vs. sales of bread.
(uncontrolled factor: bagels and cream cheese)
Copyright 1996 Lawrence C. Marsh
12.10
Joint Estimation of the Equations
INVGt = b1G + b2GVGt + b3GKGt + eGt
INVWt = b1W + b2WVWt + b3WKWt + eWt
cov(eGt, eWt) = sGW
Copyright 1996 Lawrence C. Marsh
12.11
Seemingly Unrelated Regressions
When the error terms of two or more equations
are correlated, efficient estimation requires the use
of a Seemingly Unrelated Regressions (SUR)
type estimator to take the correlation into account.
Be sure to use the Seemingly Unrelated Regressions (SUR)
procedure in your regression software program to estimate
any equations that you believe might have correlated errors.
Copyright 1996 Lawrence C. Marsh
Separate vs. Joint Estimation
12.12
SUR will give exactly the same results as estimating
each equation separately with OLS if either or both
of the following two conditions are true:
1. Every equation has exactly the same set of
explanatory variables with exactly the same
values.
2. There is no correlation between the error
terms of any of the equations.
Copyright 1996 Lawrence C. Marsh
12.13
Test for Correlation
Test the null hypothesis of zero correlation
Ho: sGW = 0
2
rGW =
2
^
s
GW
sG sW
l = T rGW
2
^2 ^2
l ~ c(1)
asy.
2
Copyright 1996 Lawrence C. Marsh
12.14
Start with
the residuals
^eGt and ^eWt
from each
equation
estimated
separately.
2
rGW =
^
s
GW
2
^
s
1
T
S
^e e
^
=
2
^
s
G
=
1
T
2
^
Se
2
^
s
=
1
T
S
W
GW
Gt Wt
Gt
2
^
e
Wt
sG sW
^2 ^2
l = T rGW
2
l ~ c(1)
asy.
2
Copyright 1996 Lawrence C. Marsh
Fixed Effects Model
12.15
yit = b1it + b2itx2it + b3itx3it + eit
Fixed effects models impose the restrictions:
b1it = b1i
b2it = b2
b3it = b3
For each ith cross section in the tth time period:
yit = b1i + b2x2it + b3x3it + eit
Each ith cross-section has its own constant b1i intercept.
Copyright 1996 Lawrence C. Marsh
The Fixed Effects Model is conveniently
represented using dummy variables:
D1i=1 if North
D1i=0 if not N
D2i=1 if East
D2i=0 if not E
D3i=1 if South
D3i=0 if not S
12.16
D4i=1 if West
D4i=0 if not W
yit = b11D1i + b12D2i + b13D3i + b14D4 i+ b2x2it + b3x3it + eit
yit = millions of bushels of corn produced
x2it = price of corn in dollars per bushel
x3it = price of soybeans in dollars per bushel
Each cross-sectional unit gets its own intercept,
but each cross-sectional intercept is constant over time.
Copyright 1996 Lawrence C. Marsh
Test for Equality of Fixed Effects
12.17
Ho : b11 = b12 = b13 = b14
H1 : Ho not true
The Ho joint null hypothesis may be tested with F-statistic:
F=
(SSER - SSEU) / J
SSEU / (NT - K)
J
~ F(NT - K)
SSER is the restricted error sum of squares (one intercept)
SSEU is the unrestricted error sum of squares (four intercepts)
N is the number of cross-sectional units (N = 4)
K is the number of parameters in the model (K = 6)
J is the number of restrictions being tested (J = N-1 = 3)
T is the number of time periods
Copyright 1996 Lawrence C. Marsh
Random Effects Model
12.18
yit = b1i + b2x2it + b3x3it + eit
b1i = b1 + mi
b1 is the population mean intercept.
mi is an unobservable random error that
accounts for the cross-sectional differences.
Copyright 1996 Lawrence C. Marsh
Random Intercept Term
b1i = b1 + mi
12.19
where i = 1, ... ,N
mi are independent of one another and of eit
E(mi) = 0
Consequently,
var(mi) =
E(b1i) = b1
2
sm
var(b1i) = sm2
Copyright 1996 Lawrence C. Marsh
Random Effects Model
yit = b1i + b2x2it + b3x3it + eit
yit = (b1+mi) + b2x2it + b3x3it + eit
yit = b1 + b2x2it + b3x3it + (mi +eit)
yit = b1 + b2x2it + b3x3it + nit
12.20
Copyright 1996 Lawrence C. Marsh
12.21
yit = b1 + b2x2it + b3x3it + nit
nit = (mi +eit)
nit has zero mean:
nit
is homoskedastic:
E(nit) = 0
var(nit) = sm2 + se2
The errors from the same firm in different time periods
are correlated:
2
cov(nit,nis) = sm
t°s
The errors from different firms are always uncorrelated:
cov(nit,njs) = 0
i°j
Copyright 1996 Lawrence C. Marsh
Chapter 13
13.1
Simultaneous
Equations
Models
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
Keynesian Macro Model
13.2
Assumptions of Simple Keynesian Model
1. Consumption, c, is function of income, y.
2. Total expenditures = consumption + investment.
3. Investment assumed independent of income.
Copyright 1996 Lawrence C. Marsh
The Structural Equations
consumption is a function of income:
c = b1 + b2 y
income is either consumed or invested:
y=c+i
13.3
Copyright 1996 Lawrence C. Marsh
The Statistical Model
The consumption equation:
ct = b1 + b2 yt + et
The income identity:
yt = ct + it
13.4
Copyright 1996 Lawrence C. Marsh
The Simultaneous Nature
of Simultaneous Equations
2.
13.5
1.
ct = b1 + b2 yt + et
5.
3.
4.
yt = ct + it
Since yt
contains et
they are
correlated
Copyright 1996 Lawrence C. Marsh
13.6
The Failure of Least Squares
The least squares estimators of
parameters in a structural simultaneous equation is biased and
inconsistent because of the correlation between the random error
and the endogenous variables on
the right-hand side of the equation.
Copyright 1996 Lawrence C. Marsh
13.7
Single vs. Simultaneous Equations
Single Equation:
Simultaneous Equations:
yt
ct
et
yt
et
ct
it
Copyright 1996 Lawrence C. Marsh
Deriving the Reduced Form
ct = b1 + b2 yt + et
yt = c t + i t
ct = b1 + b2(ct + it) + et
(1 - b2)ct = b1 + b2 it + et
13.8
Copyright 1996 Lawrence C. Marsh
Deriving the Reduced Form
13.9
(1 - b2)ct = b1 + b2 it + et
b2
b1
1
ct =
+
it +
et
(1-b2)
(1-b2) (1-b2)
ct = p11 + p21 it + nt
The Reduced Form Equation
Copyright 1996 Lawrence C. Marsh
13.10
Reduced Form Equation
ct = p11 + p21 it + nt
p11 =
b1
(1-b2)
and
nt =
b2
p21 = (1-b )
2
1
(1-b2)
+ et
Copyright 1996 Lawrence C. Marsh
13.11
yt = ct + it
where ct = p11 + p21 it + nt
yt = p11 + (1+p21) it + nt
It is sometimes useful to give this equation
its own reduced form parameters as follows:
yt = p12 + p22 it + nt
Copyright 1996 Lawrence C. Marsh
ct = p11 + p21 it + nt
yt = p12 + p22 it + nt
13.12
Since ct and yt are related through the identity:
yt = ct + it , the error term, nt, of these two
equations is the same, and it is easy to
show that:
b1
11
12
(1-b2)
p =p =
p22 = (1-p21) =
1
(1-b2)
Copyright 1996 Lawrence C. Marsh
13.13
Identification
The structural parameters are b1 and b2.
The reduced form parameters are
p11 and p21.
Once the reduced form parameters are estimated,
the identification problem is to determine if the
orginal structural parameters can be expressed
uniquely in terms of the reduced form parameters.
p11
b1 =
^
(1+p 21)
^
^
p21
b2 =
^
(1+p 21)
^
^
Copyright 1996 Lawrence C. Marsh
Identification
13.14
An equation is under-identified if its structural
(behavorial) parameters cannot be expressed
in terms of the reduced form parameters.
An equation is exactly identified if its structural
(behavorial) parameters can be uniquely expressed in terms of the reduced form parameters.
An equation is over-identified if there is more
than one solution for expressing its structural
(behavorial) parameters in terms of the reduced
form parameters.
Copyright 1996 Lawrence C. Marsh
The Identification Problem
13.15
A system of M equations
containing M endogenous
variables must exclude at least
M-1 variables from a given
equation in order for the
parameters of that equation to
be identified and to be able to
be consistently estimated.
Copyright 1996 Lawrence C. Marsh
Two Stage Least Squares
yt1 = b1 + b2 yt2 + b3 xt1 + et1
yt2 = a1 + a2 yt1 + a3 xt2 + et2
Problem: right-hand endogenous variables
yt2 and yt1 are correlated with the error terms.
13.16
Copyright 1996 variables
Lawrence C. Marsh
Problem: right-hand endogenous
13.17
yt2 and yt1 are correlated with the error terms.
Solution: First, derive the reduced form equations.
yt1 = b1 + b2 yt2 + b3 xt1 + et1
yt2 = a1 + a2 yt1 + a3 xt2 + et2
Solve two equations for two unknowns, yt1, yt2 :
yt1 = p11 + p21 xt1 + p31 xt2 + nt1
yt2 = p12 + p22 xt1 + p32 xt2 + nt2
Copyright 1996 Lawrence C. Marsh
13.18
2SLS: Stage I
yt1 = p11 + p21 xt1 + p31 xt2 + nt1
yt2 = p12 + p22 xt1 + p32 xt2 + nt2
Use least squares to get fitted values:
^y = ^p + p^ x + ^p x
t1
11
21 t1
31 t2
yt1 = ^yt1 + ^nt1
^yt2 = ^p12 + ^p22 xt1 + ^p32 xt2
yt2 = ^yt2 + ^nt2
Copyright 1996 Lawrence C. Marsh
2SLS: Stage II
yt1 = ^yt1 + ^nt1
Substitue in
for yt1 , yt2
and
13.19
yt2 = ^yt2 + ^nt2
yt1 = b1 + b2 yt2 + b3 xt1 + et1
yt2 = a1 + a2 yt1 + a3 xt2 + et2
^ t2 + ^nt2) + b3 xt1 + et1
yt1 = b1 + b2 (y
^ t1 + ^nt1) + a3 xt2 + et2
yt2 = a1 + a2 (y
Copyright 1996 Lawrence C. Marsh
2SLS: Stage II (continued)
13.20
yt1 = b1 + b2 ^yt2 + b3 xt1 + ut1
yt2 = a1 + a2 ^yt1 + a3 xt2 + ut2
where
ut1 = b2^nt2 + et1
and
ut2 = a2^nt1 + et2
Run least squares on each of the above equations
to get 2SLS estimates:
~
~
~
~
~
~
b1 , b2 , b3 , a1 , a2 and a3
Copyright 1996 Lawrence C. Marsh
Chapter 14
14.1
Nonlinear
Least
Squares
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh
Review of Least Squares Principle
14.2
(minimize the sum of squared errors)
(A.) “Regression” model with only an intercept term:
SSE = - 2 S (y - ^a) = 0
t
a
yt = a + e t
et = yt - a
S yt - S ^a = 0
2
S et = S (yt - a)
2
S yt - T ^
a = 0
Yields an exact analytical solution:
2
SSE = S (yt - a)
^ = 1 Sy = y
a
t
T
Copyright 1996 Lawrence C. Marsh
14.3
Review of Least Squares
(B.) Regression model without an intercept term:
SSE = - 2 S x (y - ^bx )= 0
t t
t
a
^
2
S xtyt - S bxt = 0
yt = bxt + et
et = yt - bxt
S et = S (yt - bxt)
2
2
2
SSE = S (yt - bxt)
^
Sxt yt - b Sx2t = 0
^b Sx2 = S x y
t
This yields an exact
analytical solution:
t t
^b = S xtyt
Sxt
2
Copyright 1996 Lawrence C. Marsh
Review of Least Squares
14.4
(C.) Regression model with both an intercept and a slope:
2
SSE = S (yt - a - bxt)
yt = a + bxt + et
SSE = - 2 S x (y - ^a - ^bx ) = 0
t t
t
b
SSE = - 2 S (y - ^a - ^bx ) = 0
t
t
a
This yields an exact
analytical solution:
^
^
y- a - b x = 0
^
^
Sxtyt - aSxt - bSx2t = 0
^
^
a = y- b x
^b = S (xt-x)(yt-y)
2
S(xt-x)
Copyright 1996 Lawrence C. Marsh
Nonlinear Least Squares
14.5
(D.) Nonlinear Regression model:
yt = xtb + et
SSE = S (yt -
2
b
xt )
PROBLEM: An exact
analytical solution to
this does not exist.
SSE = - 2 S x ^b ln(x )(y - x ^b) = 0
t
t
t
t
b
^b
S [xt ln(xt)yt] - S
^
[xt2b ln(xt)]
Must use numerical
search algorithm to
try to find value of
b to satisfy this.
=0
Copyright 1996 Lawrence C. Marsh
14.6
Find Minimum of Nonlinear SSE
SSE
SSE = S (yt -
^
b
2
b
xt )
b
Copyright 1996 Lawrence C. Marsh
14.7
Conclusion
The least squares principle
is still appropriate when the
model is nonlinear, but it is
harder to find the solution.
Copyright 1996 Lawrence C. Marsh
Optional Appendix
Nonlinear least squares
optimization methods:
The Gauss-Newton Method
14.8
Copyright 1996 Lawrence C. Marsh
14.9
The Gauss-Newton Algorithm
1. Apply the Taylor Series Expansion to the
nonlinear model around some initial b(o).
2. Run Ordinary Least Squares (OLS) on the
linear part of the Taylor Series to get b(m).
3. Perform a Taylor Series around the new b(m)
to get b(m+1) .
4. Relabel b(m+1) as b(m) and rerun steps 2.-4.
5. Stop when (b(m+1) - b(m) ) becomes very small.
Copyright 1996 Lawrence C. Marsh
The Gauss-Newton Method
yt = f(Xt,b) +
et
14.10
for t = 1, . . . , n.
Do a Taylor Series Expansion around the vector b = b(o) as follows:
f(Xt,b) = f(Xt,b(o)) + f’(Xt,b(o))(b - b(o))
+ (b - b(o))Tf’’(Xt,b(o))(b - b(o)) + Rt
yt = f(Xt,b(o)) + f’(Xt,b(o))(b - b(o)) + et*
where
et* ؛
(b - b(o))Tf’’(Xt,b(o))(b - b(o)) + Rt +
et
Copyright 1996 Lawrence C. Marsh
14.11
yt = f(Xt,b(o)) + f’(Xt,b(o))(b - b(o)) + et*
yt - f(Xt,b(o)) =
f’(Xt,b(o))b - f’(Xt,b(o)) b(o) + et*
yt - f(Xt,b(o)) + f’(Xt,b(o)) b(o) =
yt*(o) =
f’(Xt,b(o))b + et*
f’(Xt,b(o))b + et*
This is linear in b .
where yt*(o) ؛yt - f(Xt,b(o)) + f’(Xt,b(o)) b(o)
Gauss-Newton just runs OLS on this
transformed truncated Taylor series.
Copyright 1996 Lawrence C. Marsh
Gauss-Newton
just runs OLS on this 14.12
transformed truncated Taylor series.
yt*(o) =
f’(Xt,b(o))b + et* or
for t = 1, . . . , n
^b
y*(o) =
f’(X,b(o))b + *خ
in matrix terms
= [ f’(X,b(o))T f’(X,b(o))]-1 f’(X,b(o))T y*(o)
This is analogous to linear OLS where
^b = (XTX)-1XTy
y = Xb + خled to the solution:
except that X is replaced with the matrix of first
partial derivatives: f’(Xt,b(o)) and y is replaced by y*(o)
(i.e. “y” = y*(o) and “X” =
f’(X,b(o))
)
Copyright 1996 Lawrence C. Marsh
14.13
Recall that: y*(o) ؛y - f(X,b(o)) + f’(X,b(o)) b(o)
Now define: y**(o) ؛y - f(X,b(o))
Therefore:
y*(o) =
y**(o)
+
f’(X,b(o)) b(o)
Now substitute in for y* in Gauss-Newton solution:
^b = [ f’(X,b )T f’(X,b )]-1 f’(X,b )T y*
(o)
(o)
(o)
(o)
to get:
^b
= b(o) +
[ f’(X,b(o))T f’(X,b(o))]-1 f’(X,b(o))T y**(o)
Copyright 1996 Lawrence C. Marsh
14.14
^b
= b(o) +
[ f’(X,b(o))T f’(X,b(o))]-1 f’(X,b(o))T y**(o)
^
Now call this b value b(1) as follows:
b(1) = b(o) +
[ f’(X,b(o))T f’(X,b(o))]-1 f’(X,b(o))T y**(o)
More generally, in going from interation m to
iteration (m+1) we obtain the general expression:
b(m+1) = b(m) +
[ f’(X,b(m))T f’(X,b(m))]-1 f’(X,b(m))T y**(m)
Copyright 1996 Lawrence C. Marsh
14.15
Thus, the Gauss-Newton (nonlinear OLS) solution
can be expressed in two alternative, but equivalent,
forms:
1. replacement form:
b(m+1) = [ f’(X,b(m))T f’(X,b(m))]-1 f’(X,b(m))T y*(m)
2. updating form:
b(m+1) = b(m) +
[ f’(X,b(m))T f’(X,b(m))]-1 f’(X,b(m))T y**(m)
Copyright 1996 Lawrence C. Marsh
14.16
For example, consider Durbin’s Method of estimating
the autocorrelation coefficient under a first-order
autoregression regime:
y t = b1 + b2 Xt 2 + . . . + bK Xt K +
et
= r e t - 1 + ut
et
for t = 1, . . . , n.
where u t satisfies the conditions
E u t = 0 , E u 2t = su2, E u t u s = 0 for s ° t.
Therefore, u t is nonautocorrelated and homoskedastic.
Durbin’s Method is to set aside a copy of the equation,
lag it once, multiply by r and subtract the new equation
from the original equation, then move the ryt-1 term to
the right side and estimate r along with the bs by OLS.
Copyright 1996 Lawrence C. Marsh
14.17
Durbin’s Method is to set aside a copy of the equation,
lag it once, multiply by r and subtract the new equation
from the original equation, then move the ryt-1 term to
the right side and estimate r along with the b’s by OLS.
y t = b1 + b2 X t 2 + b3 X t 3 +
Lag once and multiply by r:
et
for t = 1, . . . , n.
where
et
= r et - 1 + ut
r y t-1 = r b1 + r b2 Xt -1, 2 + r b3 Xt -1, 3 + r et -1
Subtract from the original and move r y t-1 to right side:
yt = b1(1-r) + b2(Xt 2 - rXt-1, 2) + b3(Xt 3 - rXt-1, 3)+ ry t-1+ ut
Copyright 1996 Lawrence C. Marsh
14.18
The structural (restricted,behavorial) equation is:
yt = b1(1-r) + b2(Xt 2 - rXt-1, 2) + b3(Xt 3 - rXt-1, 3) + ry t-1+ ut
Now Durbin separates out the terms as follows:
yt = b1(1-r) + b2Xt 2 - b2rXt-1 2 + b3Xt 3 - b3rXt-1 3+ ry t-1+ ut
The corresponding reduced form (unrestricted) equation is:
yt = a1 + a2Xt, 2 + a3Xt-1, 2 + a4Xt, 3 + a5Xt-1, 3 + a6yt-1+ u t
a1 = b1(1-r)
a2 = b2
a3= - b2r
a4 = b3
a5= - b3r
a 6= r
Copyright 1996 Lawrence C. Marsh
14.19
a1 = b1(1-r)
a2 = b2
a3= - b2r
a4 = b3
a5= - b3r
a 6= r
^ a^ ^
^
^ ^a
Given OLS estimates: a
a
a
a
1
2
3
4
5 6
we can get three separate and distinct estimates for r :
^
a3
^
r=
^2
a
^a 5
r^ =
^a4
^r = a
^
6
These three separate estimates of r are in conflict !!!
It is difficult to know which one to use as “the”
legitimate estimate of r. Durbin used the last one.
Copyright 1996 Lawrence C. Marsh
14.20
The problem with Durbin’s Method is that it ignores
the inherent nonlinear restrictions implied by this
structural model. To get a single (i.e. unique) estimate
for r the implied nonlinear restrictions must be
incorporated directly into the estimation process.
Consequently, the above structural equation should be
estimated using a nonlinear method such as the
Gauss-Newton algorithm for nonlinear least squares.
yt = b1(1-r) + b2Xt 2 - b2rXt -1, 2 + b3Xt 3 - b3rXt -1, 3+ ryt-1+ ut
Copyright 1996 Lawrence C. Marsh
14.21
yt = b1(1-r) + b2Xt 2 - b2rXt-1, 2 + b3Xt 3 - b3rXt-1, 3+ ryt-1+ ut
f’(Xt,b) =
yt
b1
= (1 - r)
[
yt yt yt yt
b1 b2 b 3 r
yt
b2
= (X t, 2 - r X t-1,2)
yt
= (X t, 3 - r X t-1,3)
b 3
yt
r
]
= ( - b1 - b2Xt-1,2 - b3Xt-1,3+ y t-1 )
Copyright 1996 Lawrence C. Marsh
^b
14.22
(m+1)
= [ f’(X,b(m))T f’(X,b(m))]-1 f’(X,b(m))T y*(m)
where yt*(m) ؛yt - f(Xt,b(m)) + f’(Xt,b(m)) b(m)
Iterate until convergence.
b(m) =
yt yt yt yt
f’(Xt,b(m)) = [ b b b r ]
1(m)
(m)
2(m)
3(m)
b1(m)
b2(m)
b3(m)
r(m)
f(Xt,b) = b1(1-r) + b2Xt 2 - b2rXt-1 2 + b3Xt 3 - b3rXt-1 3+ ry t-1
Chapter 15
Copyright 1996 Lawrence C. Marsh15.1
Distributed
Lag Models
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh15.2
The Distributed Lag Effect
Effect
at time t
Economic action
at time t
Effect
at time t+1
Effect
at time t+2
Copyright 1996 Lawrence C. Marsh15.3
Unstructured Lags
yt = a + b0 xt + b1 xt-1 + b2 xt-2 + . . . + bn xt-n + et
“n” unstructured lags
no systematic structure imposed on the b’s
the b’s are unrestricted
Copyright 1996 Lawrence C. Marsh15.4
Problems with Unstructured Lags
1. n observations are lost with n-lag setup.
2. high degree of multicollinearity among xt-j’s.
3. many degrees of freedom used for large n.
4. could get greater precision using structure.
Copyright 1996 Lawrence C. Marsh15.5
The Arithmetic Lag Structure
proposed by Irving Fisher (1937)
the lag weights decline linearly
Imposing the relationship:
b# = (n - # + 1) g
only need to estimate one coefficient, g ,
instead of n+1 coefficients, b0 , ... , bn .
b0
b1
b2
b3
= (n+1) g
=
ng
= (n-1) g
= (n-2) g
.
.
bn-2 =
3g
bn-1 =
2g
bn =
g
Copyright 1996 Lawrence C. Marsh15.6
Arithmetic Lag Structure
yt = a + b0 xt + b1 xt-1 + b2 xt-2 + . . . + bn xt-n + et
Step 1: impose the restriction: b# = (n - # + 1) g
yt = a + (n+1) gxt + n gxt-1 + (n-1) gxt-2 + . . . + gxt-n + et
Step 2: factor out the unknown coefficient, g .
yt = a + g [(n+1)xt + nxt-1 + (n-1)xt-2 + . . . + xt-n] + et
Copyright 1996 Lawrence C. Marsh15.7
Arithmetic Lag Structure
yt = a + g [(n+1)xt + nxt-1 + (n-1)xt-2 + . . . + xt-n] + et
Step 3: Define zt .
zt = [(n+1)xt + nxt-1 + (n-1)xt-2 + . . . + xt-n]
Step 4: Decide number of lags, n.
For n = 4:
zt = [ 5xt + 4xt-1 + 3xt-2 + 2xt-3 + xt-4]
Step 5: Run least squares regression on:
y t = a + g z t + et
Copyright 1996 Lawrence C. Marsh15.8
Arithmetic Lag Structure
bi
b0 = (n+1)g
.
b1 = ng
.
b2 = (n-1)g
.
linear
.
.
.
lag
structure
bn = g
.
0
1
2
.
.
.
.
.
n
n+1
i
Copyright 1996 Lawrence C. Marsh15.9
Polynomial Lag Structure
proposed by Shirley Almon (1965)
n = the length of the lag
p = degree of polynomial
the lag weights fit a polynomial
bi = g0 + g1i + g2i +...+ gpi
2
For example, a quadratic polynomial:
bi = g0 + g1i + g2i
2
where i = 1, . . . , n
p = 2 and n = 4
p
where i = 1, . . . , n
b0
b1
b2
b3
b4
=
=
=
=
=
g0
g0
g0
g0
g0
+
+
+
+
g1 + g2
2g1 + 4g2
3g1 + 9g2
4g1 + 16g2
Copyright 1996 Lawrence C. Marsh
15.10
Polynomial Lag Structure
yt = a + b0 xt + b1 xt-1 + b2 xt-2 + b3 xt-3 + b4 xt-4 + et
Step 1: impose the restriction: bi = g0 + g1i + g2i 2
yt = a + g0 xt + (g0 + g1 + g2)xt-1 + (g0 + 2g1 + 4g2)xt-2
+ (g0 + 3g1 + 9g2)xt-3+ (g0 + 4g1 + 16g2)xt-4 + et
Step 2: factor out the unknown coefficients: g0, g1, g2.
yt = a + g0 [xt + xt-1 + xt-2 + xt-3 + xt-4]
+ g1 [xt + xt-1 + 2xt-2 + 3xt-3 + 4xt-4]
+ g2 [xt + xt-1 + 4xt-2 + 9xt-3 + 16xt-4] + et
Copyright 1996 Lawrence C. Marsh
15.11
Polynomial Lag Structure
yt = a + g0 [xt + xt-1 + xt-2 + xt-3 + xt-4]
+ g1 [xt + xt-1 + 2xt-2 + 3xt-3 + 4xt-4]
+ g2 [xt + xt-1 + 4xt-2 + 9xt-3 + 16xt-4] + et
Step 3: Define zt0 , zt1 and zt2 for g0 , g1 , and g2.
z t0 = [xt + xt-1 + xt-2 + xt-3 + xt-4]
z t1 = [xt + xt-1 + 2xt-2 + 3xt-3 + 4xt- 4 ]
z t2 = [xt + xt-1 + 4xt-2 + 9xt-3 + 16xt- 4]
Copyright 1996 Lawrence C. Marsh
15.12
Polynomial Lag Structure
Step 4: Regress yt on zt0 , zt1 and zt2 .
yt = a + g0 z t0 + g1 z t1 + g2 z t2 + et
Step 5: Express b^i‘s in terms of g^0 , ^g1 , and ^g2.
b^0
^
b1
^
b2
^
b3
^
b4
= ^g0
= ^g0 +
= ^g +
^g + ^g
1
2
2g^ + 4g^
= ^g0 +
= g^ +
3g^1 + 9g^2
4g^ + 16g^
0
0
1
1
2
2
Copyright 1996 Lawrence C. Marsh
15.13
Polynomial Lag Structure
bi
b0
.
0
b2
. . .b
b1
3
b4
.
1
2
3
4
Figure 15.3
i
Copyright 1996 Lawrence C. Marsh
15.14
Geometric Lag Structure
infinite distributed lag model:
yt = a + b0 xt + b1 xt-1 + b2 xt-2 + . . . + et
yt = a + i=0
S bi xt-i + et
(15.3.1)
geometric lag structure:
bi = b fi
where |f| < 1 and bfi > 0 .
Copyright 1996 Lawrence C. Marsh
15.15
Geometric Lag Structure
infinite unstructured lag:
yt = a + b0 xt + b1 xt-1 + b2 xt-2 + b3 xt-3 + . . . + et
Substitute bi = b fi
infinite geometric lag:
b0
b1
b2
b3
=
=
=
=
..
.
b
bf
b f2
b f3
yt = a + b(xt + f xt-1 + f2 xt-2 + f3 xt-3 + . . .) + et
Copyright 1996 Lawrence C. Marsh
15.16
Geometric Lag Structure
yt = a + b(xt + f xt-1 + f2 xt-2 + f3 xt-3 + . . .) + et
impact multiplier :
b
interim multiplier (3-period) :
b + b f + b f2
long-run multiplier :
b(1 + f +
f2
+
f3
b
+ . . . ) = 1- f
Copyright 1996 Lawrence C. Marsh
15.17
Geometric Lag Structure
bi
b0 = b
.
.
b1 = b f
b2 = b f2
b3 = b f3
b4 = b f4
0
1
geometrically
declining
weights
.
2
. .
3
4
Figure 15.5
i
Copyright 1996 Lawrence C. Marsh
15.18
Geometric Lag Structure
yt = a + b(xt + f xt-1 + f2 xt-2 + f3 xt-3 + . . .) + et
Problem:
How to estimate the infinite number
of geometric lag coefficients ???
Answer:
Use the Koyck transformation.
Copyright 1996 Lawrence C. Marsh
15.19
The Koyck Transformation
Lag everything once, multiply by f and subtract from original:
yt = a + b(xt + f xt-1 + f2 xt-2 + f3 xt-3 + . . .) + et
f yt-1 = fa + b(f xt-1 + f2 xt-2 + f3 xt-3 + . . .) + f et-1
yt - f yt-1 = a(1- f) + bxt + (et - fet-1)
Copyright 1996 Lawrence C. Marsh
15.20
The Koyck Transformation
yt - f yt-1 = a(1- f) + bxt + (et - fet-1)
Solve for yt by adding f yt-1 to both sides:
yt = a(1- f) + f yt-1 + bxt + (et - fet-1)
yt = d1 + d2 yt-1 + d3xt + nt
Copyright 1996 Lawrence C. Marsh
15.21
The Koyck Transformation
yt = a(1- f) + f yt-1 + bxt + (et - fet-1)
Defining d1 = a(1- f) , d2 = f , and d3 = b ,
use ordinary least squares:
yt = d1 + d2 yt-1 + d3xt + nt
The original structural
parameters can now be
estimated in terms of
these reduced form
parameter estimates.
^ ^
b = d3
^f = ^d
2
^a = ^d / (1- ^d )
1
2
Copyright 1996 Lawrence C. Marsh
15.22
Geometric Lag Structure
^ + f^ x + f^2 x + f^3 x + . . .) + ^e
yt = ^a + b(x
t
t-1
t-2
t-3
t
^b = ^b
0
^
^
b1 = b f^
^
b2 = ^b ^f2
^b = ^b ^f3
3
.
.
.
^
^
^
^
^
yt = a + b0 xt + b1 xt-1 + b2 xt-2 + b3 xt-3 + . . . + ^et
Copyright 1996 Lawrence C. Marsh
15.23
Durbin’s h-test
for autocorrelation
Estimates inconsistent if geometric lag model is autocorrelated,
but Durbin-Watson test is biased in favor of no autocorrelation.
h= 1- d
2
T-1
1 - (T - 1)[se(b2)]2
h = Durbin’s h-test statistic
d = Durbin-Watson test statistic
se(b2) = standard error of the estimate b2
T = sample size
Copyright 1996 Lawrence C. Marsh
15.24
Adaptive Expectations
yt = a + b x*t + et
yt =
x*t =
credit card debt
expected (anticipated) income
(x*t is not observable)
Copyright 1996 Lawrence C. Marsh
15.25
Adaptive Expectations
adjust expectations
based on past realization:
x*t - x*t-1 = l (xt-1 - x*t-1)
Copyright 1996 Lawrence C. Marsh
15.26
Adaptive Expectations
x*t - x*t-1 = l (xt-1 - x*t-1)
rearrange to get:
x*t
= l xt-1 + (1- l) x*t-1
or
l xt-1 =
[x*t - (1- l) x*t-1]
Copyright 1996 Lawrence C. Marsh
15.27
Adaptive Expectations
yt = a + b x*t + et
Lag this model once and multiply by (1- l):
(1- l)yt-1 = (1- l)a + (1- l)b x*t-1 + (1- l)et-1
subtract this from the original to get:
yt = al - (1- l)yt-1+ b [x*t - (1- l)x*t-1]
+ et - (1- l)et-1
Copyright 1996 Lawrence C. Marsh
15.28
Adaptive Expectations
yt = al - (1- l)yt-1+ b [x*t - (1- l)x*t-1]
+ et - (1- l)et-1
Since l xt-1 =
we get:
[x*t - (1- l) x*t-1]
yt = al - (1- l)yt-1+ blxt-1 + ut
where
ut = et - (1- l)et-1
Copyright 1996 Lawrence C. Marsh
15.29
Adaptive Expectations
yt = al - (1- l)yt-1+ blxt-1 + ut
Use ordinary least squares regression on:
yt = b1 + b2yt-1+ b3xt-1 + ut
^
and we get:
^
^
l = (1- b2)
^ =
a
b1
^
(1- b2)
^
b=
^
b3
^
(1- b2)
Copyright 1996 Lawrence C. Marsh
15.30
Partial Adjustment
y*t = a + b xt + et
inventories partially adjust , 0 < g < 1,
towards optimal or desired level, y*t :
yt - yt-1 = g (y*t - yt-1)
Copyright 1996 Lawrence C. Marsh
15.31
Partial Adjustment
yt - yt-1 = g (y*t - yt-1)
= g (a + bxt + et - yt-1)
= ga + gbxt - gyt-1+ get
Solving for yt :
yt = ga + (1 - g)yt-1 + gbxt + get
Copyright 1996 Lawrence C. Marsh
15.32
Partial Adjustment
yt = ga + (1 - g)yt-1 + gbxt + get
yt = b1 + b2yt-1+ b3xt + nt
Use ordinary least squares regression to get:
^
^g = (1- b
2)
^
^a =
b1
^
(1- b2)
^
b=
^
b3
^
(1- b2)
Chapter 16
Copyright 1996 Lawrence C. Marsh16.1
Time
Series
Analysis
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh16.2
Previous Chapters used Economic Models
1. economic model for dependent variable of interest.
2. statistical model consistent with the data.
3. estimation procedure for parameters using the data.
4. forecast variable of interest using estimated model.
Times Series Analysis does not use this approach.
Copyright 1996 Lawrence C. Marsh16.3
Time Series Analysis does not generally
incorporate all of the economic relationships
found in economic models.
Times Series Analysis uses
more statistics and less economics.
Time Series Analysis is useful for short term forecasting only.
Long term forecasting requires incorporating more involved
behavioral economic relationships into the analysis.
Copyright 1996 Lawrence C. Marsh16.4
Univariate Time Series Analysis can be used
to relate the current values of a single economic
variable to:
1. its past values
2. the values of current and past random errors
Other variables are not used
in univariate time series analysis.
Copyright 1996 Lawrence C. Marsh16.5
Three types of Univariate Time Series Analysis
processes will be discussed in this chapter:
1. autoregressive (AR)
2. moving average (MA)
3. autoregressive moving average (ARMA)
Copyright 1996 Lawrence C. Marsh16.6
Multivariate Time Series Analysis can be
used to relate the current value of each of
several economic variables to:
1. its past values.
2. the past values of the other forecasted variables.
3. the values of current and past random errors.
Vector autoregressive models discussed later in
this chapter are multivariate time series models.
Copyright 1996 Lawrence C. Marsh16.7
First-Order Autoregressive Processes, AR(1):
yt = d + q1yt-1+ et,
t = 1, 2,...,T.
(16.1.1)
d is the intercept.
q1 is parameter generally between -1 and +1.
et is an uncorrelated random error with
mean zero and variance se 2 .
Copyright 1996 Lawrence C. Marsh16.8
Autoregressive Process of order p, AR(p) :
yt = d + q1yt-1 + q2yt-2 +...+ qpyt-p + et
(16.1.2)
d is the intercept.
qi’s are parameters generally between -1 and +1.
et is an uncorrelated random error with
mean zero and variance se 2 .
Copyright 1996 Lawrence C. Marsh16.9
Properties of least squares estimator:
AR models always have one or more lagged
dependent variables on the right hand side.
Consequently, least squares is no longer a
best linear unbiased estimator (BLUE),
but it does have some good asymptotic
properties including consistency.
Copyright 1996 Lawrence C. Marsh
16.10
AR(2) model of U.S. unemployment rates
yt = 0.5051 + 1.5537 yt-1
(0.1267)
(0.0707)
- 0.6515 yt-2
(0.0708)
positive
negative
Note: Q1-1948 through Q1-1978 from J.D.Cryer (1986) see unempl.dat
Copyright 1996 Lawrence C. Marsh
16.11
Choosing the lag length, p, for AR(p):
The Partial Autocorrelation Function (PAF)
The PAF is the sequence of correlations between
(yt and yt-1), (yt and yt-2), (yt and yt-3), and so on,
given that the effects of earlier lags on yt are
held constant.
Copyright 1996 Lawrence C. Marsh
16.12
Partial Autocorrelation Function
Data simulated
from this model:
^
qkk 1
yt = 0.5 yt-1
+ 0.3 yt-2 + et
qkk is the last (kth) coefficient
in a kth order AR process.
2/ T
0
-2/ T
-1
k
This sample PAF suggests a second
order process AR(2) which is correct.
Copyright 1996 Lawrence C. Marsh
16.13
Using AR Model for Forecasting:
unemployment rate: yT-1 = 6.63 and yT = 6.20
^ ^
^
^y
=
d
+
q
y
+
q2 yT-1
T+1
1 T
= 0.5051 + (1.5537)(6.2) - (0.6515)(6.63)
= 5.8186
^ ^
^
^y
=
d
+
q
y
T+2
1 T+1 + q2 yT
= 0.5051 + (1.5537)(5.8186) - (0.6515)(6.2)
= 5.5062
^ ^
^
^y
=
d
+
q
y
+
q2 yT-1
T+1
1 T
= 0.5051 + (1.5537)(5.5062)
= 5.2693
- (0.6515)(5.8186)
Copyright 1996 Lawrence C. Marsh
16.14
Moving Average Process of order q, MA(q):
yt = m + et + a1et-1 + a2et-2 +...+ aqet-q + et
m is the intercept.
ai‘s are unknown parameters.
et is an uncorrelated random error with
mean zero and variance se 2 .
(16.2.1)
Copyright 1996 Lawrence C. Marsh
16.15
An MA(1) process:
yt = m + et + a1et-1
(16.2.2)
Minimize sum of least squares deviations:
T
T
S(m,a1) = S et = t=1S(yt - m - a1et-1)
t=1
2
2
(16.2.3)
Copyright 1996 Lawrence C. Marsh
16.16
Stationary vs. Nonstationary
stationary:
A stationary time series is one whose mean, variance,
and autocorrelation function do not change over time.
nonstationary:
A nonstationary time series is one whose mean,
variance or autocorrelation function change over time.
Copyright 1996 Lawrence C. Marsh
16.17
First Differencing is often used to transform
a nonstationary series into a stationary series:
yt = z t - z t-1
where z t is the original nonstationary series
and yt is the new stationary series.
Copyright 1996 Lawrence C. Marsh
16.18
Choosing the lag length, q, for MA(q):
The Autocorrelation Function (AF)
The AF is the sequence of correlations between
(yt and yt-1), (yt and yt-2), (yt and yt-3), and so on,
without holding the effects of earlier lags
on yt constant.
The PAF controlled for the effects of previous lags
but the AF does not control for such effects.
Copyright 1996 Lawrence C. Marsh
16.19
Autocorrelation Function
Data simulated
yt = et - 0.9 et-1
from this model:
This sample AF suggests a first order
rkk 1
process MA(1) which is correct.
2/ T
0
-2/ T
k
rkk is the last (kth) coefficient
-1
in a kth order MA process.
Copyright 1996 Lawrence C. Marsh
16.20
Autoregressive Moving Average
ARMA(p,q)
An ARMA(1,2) has one autoregressive lag
and two moving average lags:
yt = d + q1yt-1 + et + a1et-1 + a2 et-2
Copyright 1996 Lawrence C. Marsh
16.21
Integrated Processes
A time series with an upward or downward
trend over time is nonstationary.
Many nonstationary time series can be made
stationary by differencing them one or more times.
Such time series are called integrated processes.
Copyright 1996 Lawrence C. Marsh
16.22
The number of times a series must be
differenced to make it stationary is the
order of the integrated process, d.
An autocorrelation function, AF,
with large, significant autocorrelations
for many lags may require more than
one differencing to become stationary.
Check the new AF after each differencing
to determine if further differencing is needed.
Copyright 1996 Lawrence C. Marsh
16.23
Unit Root
zt = q1zt-1 + m + et + a1et-1
-1 < q1 < 1
q1 = 1
(16.3.2)
stationary ARMA(1,1)
nonstationary process
q1 = 1 is called a unit root
Copyright 1996 Lawrence C. Marsh
16.24
Unit Root Tests
zt - zt-1 = (q1- 1)zt-1 + m + et + a1et-1
Dzt =
where
*
q1zt-1 +
m + et + a1et-1
(16.3.3)
Dzt = zt - zt-1 and q1 = q1- 1
*
Testing q1 = 0 is equivalent to testing q1 = 1
*
Copyright 1996 Lawrence C. Marsh
16.25
Unit Root Tests
H0: q1 = 0
*
vs.
H1: q1 < 0
*
(16.3.4)
Computer programs typically use one of
the following tests for unit roots:
Dickey-Fuller Test
Phillips-Perron Test
Copyright 1996 Lawrence C. Marsh
16.26
Autoregressive Integrated Moving Average
ARIMA(p,d,q)
An ARIMA(p,d,q) model represents an
AR(p) - MA(q) process that has been
differenced (integrated, I(d)) d times.
yt = d + q1yt-1 +...+ qpyt-p + et + a1et-1 +... + aq et-q
Copyright 1996 Lawrence C. Marsh
16.27
The Box-Jenkins approach:
1. Identification
determining the values of p, d, and q.
2. Estimation
linear or nonlinear least squares.
3. Diagnostic Checking
model fits well with no autocorrelation?
4. Forecasting
short-term forecasts of future yt values.
Copyright 1996 Lawrence C. Marsh
16.28
Vector Autoregressive (VAR) Models
Use VAR for two or more interrelated time series:
yt = q0 + q1yt-1 +...+ qpyt-p + f1xt-1 +... + fp xt-p + et
xt = d0 + d1yt-1 +...+ dpyt-p + a1xt-1 +... + ap xt-p + ut
Copyright 1996 Lawrence C. Marsh
16.29
Vector Autoregressive (VAR) Models
1.
2.
3.
4.
5.
extension of AR model.
all variables endogenous.
no structural (behavioral) economic model.
all variables jointly determined (over time).
no simultaneous equations (same time).
Copyright 1996 Lawrence C. Marsh
16.30
The random error terms in a VAR model
may be correlated if they are affected by
relevant factors that are not in the model
such as government actions or
national/international events, etc.
Since VAR equations all have exactly the
same set of explanatory variables, the usual
seemingly unrelation regression estimation
produces exactly the same estimates as
least squares on each equation separately.
Copyright 1996 Lawrence C. Marsh
16.31
Least Squares is Consistent
Consequently, regardless of whether
the VAR random error terms are
correlated or not, least squares estimation
of each equation separately will provide
consistent regression coefficient estimates.
Copyright 1996 Lawrence C. Marsh
16.32
VAR Model Specification
To determine length of the lag, p, use:
1. Akaike’s AIC criterion
2. Schwarz’s SIC criterion
These methods were discussed in Chapter 15.
Copyright 1996 Lawrence C. Marsh
16.33
Spurious Regressions
yt = b1 + b2 xt + et
where
et = q1 et-1 + nt
-1 < q1 < 1
I(0) (i.e. d=0)
q1 = 1
I(1) (i.e. d=1)
If q1 =1 least squares estimates of b2 may
appear highly significant even when true b2 = 0 .
Copyright 1996 Lawrence C. Marsh
16.34
Cointegration
yt = b1 + b2 xt + et
If xt and yt are nonstationary I(1)
we might expect that et is also I(1).
xt and yt are nonstationary I(1)
but et is stationary I(0), then xt and yt are
However, if
said to be cointegrated.
Copyright 1996 Lawrence C. Marsh
16.35
Cointegrated VAR(1) Model
VAR(1) model:
yt = q0 + q1yt-1 + f1xt-1 + et
xt = d0 + d1yt-1 + a1xt-1 + ut
If xt and yt are both I(1) and are cointegrated,
use an Error Correction Model, instead of VAR(1).
Copyright 1996 Lawrence C. Marsh
16.36
Error Correction Model
Dyt = yt - yt-1 and Dxt = xt - xt-1
Dyt = q0 + (q1-1)yt-1 + f1xt-1 + et
Dxt = d0 + d1yt-1 + (a1-1)xt-1 + ut
(continued)
Copyright 1996 Lawrence C. Marsh
16.37
Error Correction Model
*
q0
Dyt =
*
q0
+ g1(yt-1 - b1 - b2 xt-1) + et
Dxt =
*
d0
+ g2(yt-1 - b1 - b2 xt-1) + ut
= q0 + g1b1
- a1
b2 =
d1
1
*
d0
= d 0 + g2b 1
f1 d1
g1 =
a1 - 1
g2 = d 1
Copyright 1996 Lawrence C. Marsh
16.38
Estimating an Error Correction Model
Step 1:
Estimate by least squares:
yt-1 = b1 + b2 xt-1 + et-1
to get the residuals:
^e
=
t-1
^
^
yt-1 - b1 - b2 xt-1
Copyright 1996 Lawrence C. Marsh
16.39
Estimating an Error Correction Model
Step 2:
Estimate by least squares:
Dyt =
*
q0
Dxt =
*
d0
+ g1
^e
t-1
+ et
+ g2
^e
t-1
+ ut
Copyright 1996 Lawrence C. Marsh
16.40
Using cointegrated I(1) variables in a
VAR model expressed solely in terms
of first differences and lags of first
differences is a misspecification.
The correct specification is to use an
Error Correction Model
Chapter 17
Copyright 1996 Lawrence C. Marsh17.1
Guidelines for
Research Project
Copyright © 1997 John Wiley & Sons, Inc. All rights reserved. Reproduction or translation of this work beyond
that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the
copyright owner is unlawful. Request for further information should be addressed to the Permissions Department,
John Wiley & Sons, Inc. The purchaser may make back-up copies for his/her own use only and not for distribution
or resale. The Publisher assumes no responsibility for errors, omissions, or damages, caused by the use of these
programs or from the use of the information contained herein.
Copyright 1996 Lawrence C. Marsh17.2
What Book Has Covered
ً
ً
ً
ً
Formulation
economic ====> econometric.
Estimation
selecting appropriate method.
Interpretation
how the xt’s impact on the yt .
Inference
testing, intervals, prediction.
Copyright 1996 Lawrence C. Marsh17.3
Topics for This Chapter
1. Types of Data by Source
2. Nonexperimental Data
3. Text Data vs. Electronic Data
4. Selecting a Topic
5. Writing an Abstract
6. Research Report Format
Copyright 1996 Lawrence C. Marsh17.4
Types of Data by Source
i)
Experimental Data
from controlled experiments.
ii) Observational Data
passively generated by society.
iii) Survey Data
data collected through interviews.
Copyright 1996 Lawrence C. Marsh17.5
Time vs. Cross-Section
Time Series Data
data collected at distinct points in time
(e.g. weekly sales, daily stock price, annual
budget deficit, monthly unemployment.)
Cross Section Data
data collected over samples of units, individuals,
households, firms at a particular point in time.
(e.g. salary, race, gender, unemployment by state.)
Copyright 1996 Lawrence C. Marsh17.6
Micro vs. Macro
Micro Data:
data collected on individual economic
decision making units such as individuals,
households or firms.
Macro Data:
data resulting from a pooling or aggregating
over individuals, households or firms at the
local, state or national levels.
Copyright 1996 Lawrence C. Marsh17.7
Flow vs. Stock
Flow Data:
outcome measured over a period of time,
such as the consumption of gasoline during
the last quarter of 1997.
Stock Data:
outcome measured at a particular point in
time, such as crude oil held by Chevron in
US storage tanks on April 1, 1997.
Copyright 1996 Lawrence C. Marsh17.8
Quantitative vs. Qualitative
Quantitative Data:
outcomes such as prices or income that may
be expressed as numbers or some transformation of them (e.g. wages, trade deficit).
Qualitative Data:
outcomes that are of an “either-or” nature
(e.g. male, home owner, Methodist, bought
car last year, voted in last election).
Copyright 1996 Lawrence C. Marsh17.9
International Data
International Financial Statistics (IMF monthly).
Basic Statistics of the Community (OECD annual).
Consumer Price Indices in the European
Community (OECD annual).
World Statistics (UN annual).
Yearbook of National Accounts Statistics (UN).
FAO Trade Yearbook (annual).
Copyright 1996 Lawrence C. Marsh
17.10
United States Data
Survey of Current Business (BEA monthly).
Handbook of Basic Economic Statistics (BES).
Monthly Labor Review (BLS monthly).
Federal Researve Bulletin (FRB monthly).
Statistical Abstract of the US (BC annual).
Economic Report of the President (CEA annual).
Economic Indicators (CEA monthly).
Agricultural Statistics (USDA annual).
Agricultural Situation Reports (USDA monthly).
Copyright 1996 Lawrence C. Marsh
17.11
State and Local Data
State and Metropolitan Area Data Book
(Commerce and BC, annual).
CPI Detailed Report (BLS, annual).
Census of Population and Housing
(Commerce, BC, annual).
County and City Data Book
(Commerce, BC, annual).
Copyright 1996 Lawrence C. Marsh
17.12
Citibase on CD-ROM
•
•
•
•
•
•
•
•
Financial series: interest rates, stock market, etc.
Business formation, investment and consumers.
Construction of housing.
Manufacturing, business cycles, foreign trade.
Prices: producer and consumer price indexes.
Industrial production.
Capacity and productivity.
Population.
Copyright 1996 Lawrence C. Marsh
17.13
Citibase on CD-ROM
(continued)
•
•
•
•
•
•
Labor statistics: unemployment, households.
National income and product accounts in detail.
Forecasts and projections.
Business cycle indicators.
Energy consumption, petroleum production, etc.
International data series including trade
statistics.
Copyright 1996 Lawrence C. Marsh
17.14
Resources for Economists
Resources for Economists by Bill Goffe
http://econwpa.wustl.edu/EconFAQ/EconFAQ.html
Bill Goffe provides a vast database of information
about the economics profession including economic
organizations, working papers and reports,
and economic data series.
Copyright 1996 Lawrence C. Marsh
17.15
Internet Data Sources
A few of the items on Bill Goffe’s Table of Contents:
•
•
•
•
•
•
•
Shortcut to All Resources.
Macro and Regional Data.
Other U.S. Data.
World and Non-U.S. Data.
Finance and Financial Markets.
Data Archives.
Journal Data and Program Archives.
Copyright 1996 Lawrence C. Marsh
17.16
Useful Internet Addresses
http://seamonkey.ed.asu.edu/~behrens/teach/WWW_data.html
http://www.sims.berkeley.edu/~hal/pages/interesting.html
http://www.stls.frb.org FED RESERVE BK - ST. LOUIS
http://www.bls.gov BUREAU OF LABOR STATISTICS
http://nber.harvard.edu
NAT’L BUR. ECON. RESEARCH
http://www.inform.umd.edu:8080/EdRes/Topic/EconData/.w
ww/econdata.html UNIVERSITY OF MARYLAND
http://www.bog.frb.fed.us FEB BOARD OF GOVERNORS
http://www.webcom.com/~yardeni/economic.html
Copyright 1996 Lawrence C. Marsh
17.17
Data from Surveys
The survey process has four distinct aspects:
i) identify the population of interest.
ii) designing and selecting the sample.
iii) collecting the information.
iv) data reduction, estimation and inference.
Copyright 1996 Lawrence C. Marsh
17.18
Controlled Experiments
Controlled experiments were done on these topics:
1. Labor force participation: negative income tax:
guaranteed minimum income experiment.
2. National cash housing allowance experiment:
impact on demand and supply of housing.
3. Health insurance: medical cost reduction:
sensitivity of income groups to price change.
4. Peak-load pricing and electricity use:
daily use pattern of residential customers.
Copyright 1996 Lawrence C. Marsh
17.19
Economic Data Problems
I. poor implicit experimental design
(i) collinear explanatory variables.
(ii) measurement errors.
II. inconsistent with theory specification
(i) wrong level of aggregation.
(ii) missing observations or variables.
(iii) unobserved heterogeneity.
Copyright 1996 Lawrence C. Marsh
17.20
Selecting a Topic
General tips for selecting a research topic:
ً
ً
ً
ً
ً
ً
ً
•
•
•
•
•
•
•
“What am I interested in?”
Well-defined, relatively simple topic.
Ask prof for ideas and references.
Journal of Economic Literature (ECONLIT)
Make sure appropriate data are available.
Avoid extremely difficult econometrics.
Plan your work and work your plan.
Copyright 1996 Lawrence C. Marsh
17.21
Writing an Abstract
Abstract of less than 500 words should include:
(i) concise statement of the problem.
(ii) key references to available information.
(iii) description of research design including:
(a) economic model
(b) statistical model
(c) data sources
(d) estimation, testing and prediction
(iv) contribution of the work
Copyright 1996 Lawrence C. Marsh
17.22
Research Report Format
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
Statement of the Problem.
Review of the Literature.
The Economic Model.
The Statistical Model.
The Data.
Estimation and Inferences Procedures.
Empirical Results and Conclusions.
Possible Extensions and Limitations.
Acknowledgments.
References.