Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
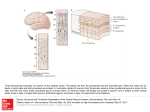
A Brain-Like Computer for Cognitive Applications: The Ersatz Brain Project James A. Anderson [email protected] Department of Cognitive and Linguistic Sciences Brown University, Providence, RI 02912 Paul Allopenna [email protected] Aptima, Inc. 12 Gill Street, Suite 1400, Woburn, MA Our Goal: We want to build a first-rate, second-rate brain. Participants Faculty: Jim Anderson, Cognitive Science. Gerry Guralnik, Physics. Gabriel Taubin, Engineering. Students, Past and Present: Socrates Dimitriadis, Cognitive Science. Dmitri Petrov, Physics. Erika Nesse, Cognitive Science. Brian Merritt, Cognitive Science. Staff: Samuel Fulcomer, Jim O’Dell, Center for Computation and Visualization. Private Industry: Paul Allopenna, Aptima, Inc. John Santini, Anteon, Inc. Why Build a Brain-Like Computer? 1. Engineering. Computers are all special purpose devices. Many of the most important practical computer applications of the next few decades will be cognitive in nature: Natural language processing. Internet search. Cognitive data mining. Decent human-computer interfaces. Text understanding. We feel it will be necessary to have a cortex-like architecture (either software or hardware) to run these applications efficiently. 2. Science: Such a system, even in simulation, becomes a powerful research tool. It leads to designing models with a particular structure to match the brain-like computer. If we capture any of the essence of the cortex, writing good programs will give insight into the biology and cognitive science. If we can write good software for a vaguely brain like computer we may show we really understand something important about the brain. 3. Personal: It would be the ultimate cool gadget. A technological vision: In 2050 the personal computer you buy in Wal-Mart will have two CPU’s with very different architecture: First, a traditional von Neumann machine that runs spreadsheets, does word processing, keeps your calendar straight, etc. etc. What they do now. Second, a brain-like chip To handle the interface with the von Neumann machine, Give you the data that you need from the Web or your files (but didn’t think to ask for). Be your silicon friend, guide, and confidant. History : Technical Issues Many have proposed the construction of brain-like computers. These attempts usually start with massively parallel arrays of neural computing elements elements based on biological neurons, and the layered 2-D anatomy of mammalian cerebral cortex. Such attempts have failed commercially. The early connection machines from Thinking Machines,Inc.,(W.D. Hillis, The Connection Machine, 1987) was most nearly successful commercially and is most like the architecture we are proposing here. Consider the extremes of computational brain models. First Extreme: Biological Realism The human brain is composed of on the order of 1010 neurons, connected together with at least 1014 neural connections. (Probably underestimates.) Biological neurons and their connections are extremely complex electrochemical structures. The more realistic the neuron approximation the smaller the network that can be modeled. There is good evidence that for cerebral cortex a bigger brain is a better brain. Projects that model neurons are of scientific interest. They are not large enough to model or simulate interesting cognition. Neural Networks. The most successful brain inspired models are neural networks. They are built from simple approximations of biological neurons: nonlinear integration of many weighted inputs. Throw out all the other biological detail. Neural Network Systems Units with these approximations can build systems that can be made large, can be analyzed, can be simulated, can display complex cognitive behavior. Neural networks have been used to model important aspects of human cognition. Second Extreme: Associatively Linked Networks. The second class of brain-like computing models is a basic part of computer science: Associatively linked structures. One example of such a structure is a semantic network. Such structures underlie most of the practically successful applications of artificial intelligence. Associatively Linked Networks (2) The connection between the biological nervous system and such a structure is unclear. Few believe that nodes in a semantic network correspond in any sense to single neurons or groups of neurons. Physiology (fMRI) suggests that a complex cognitive structure – a word, for instance – gives rise to widely distributed cortical activation. Virtue of Linked Networks: connected nodes. They have sparsely In practical systems, the number of links converging on a node range from one or two up to a dozen or so. The Ersatz Brain Approximation: The Network of Networks. Received wisdom has it that neurons are the basic computational units of the brain. The Ersatz Brain Project is based on a different assumption. The Network of Networks model was developed in collaboration with Jeff Sutton (Harvard Medical School, now NSBRI). Cerebral cortex contains intermediate level structure, between neurons and an entire cortical region. Examples of intermediate structure are cortical columns of various sizes (mini-, plain, and hyper) Intermediate level brain structures are hard to study experimentally because they require recording from many cells simultaneously. Cortical Columns: Minicolumns “The basic unit of cortical operation is the minicolumn … It contains of the order of 80-100 neurons except in the primate striate cortex, where the number is more than doubled. The minicolumn measures of the order of 40-50 m in transverse diameter, separated from adjacent minicolumns by vertical, cell-sparse zones … The minicolumn is produced by the iterative division of a small number of progenitor cells in the neuroepithelium.” (Mountcastle, p. 2) VB Mountcastle (2003). Introduction [to a special issue of Cerebral Cortex on columns]. Cerebral Cortex, 13, 2-4. Figure: Nissl stain of cortex in planum temporale. Columns: Functional Groupings of minicolumns seem to form the physiologically observed functional columns. Best known example is orientation columns in V1. They are significantly bigger than minicolumns, typically around 0.3-0.5 mm. Mountcastle’s summation: “Cortical columns are formed by the binding together of many minicolumns by common input and short range horizontal connections. … The number of minicolumns per column varies … between 50 and 80. Long range intracortical projections link columns with similar functional properties.” (p. 3) Cells in a column ~ (80)(100) = 8000 Sparse Connectivity The brain is sparsely connected. (Unlike most neural nets.) A neuron in cortex may have on the order of 100,000 synapses. There are more than 1010 neurons in the brain. Fractional connectivity is very low: 0.001%. Implications: • Connections are expensive biologically since they take up space, use energy, and are hard to wire up correctly. • Therefore, connections are valuable. • The pattern of connection is under tight control. • Short local connections are cheaper than long ones. Our approximation makes extensive use of local connections for computation. Network of Networks Approximation We use the Network of Networks [NofN] approximation to structure the hardware and to reduce the number of connections. We assume the basic computing units are not neurons, but small (104 neurons) attractor networks. Basic Network of Networks Architecture: • 2 Dimensional array of modules • Locally connected to neighbors The activity of the nonlinear attractor networks (modules) is dominated by their attractor states. Attractor states may be built in or acquired through learning. We approximate the activity of a module as a weighted sum of attractor states.That is: an adequate set of basis functions. Activity of Module: x = Σ ciai where the ai are the attractor states. Elementary Modules The Single Module: BSB The attractor network we use for the individual modules is the BSB network (Anderson, 1993). It can be analyzed using the eigenvectors and eigenvalues of its local connections. Interactions between Modules Interactions between modules are described by state interaction matrices, M. The state interaction matrix elements give the contribution of an attractor state in one module to the amplitude of an attractor state in a module connected to it. In the linear region x(t+1) =Σ Msi + f weighted sum input from other modules + x(t) ongoing activity The Linear-Nonlinear Transition The first processing stage is linear and sums influences from other modules. The second processing stage (with limited values) is nonlinear. The linear to nonlinear transition is a powerful computational tool for cognitive applications. It also describes the processing path taken by many cognitive processes. Generalization from cognitive science: Sensory inputs (categories, concepts, words) Processing moves from continuous values to discrete entities. (McCulloch and Pitts had it backwards.) Binding Module Patterns Together. An associative Hebbian learning event will tend to link f with g through the local connections. There is a speculative connection to the important binding problem of cognitive science and neuroscience. The larger groupings will act like a unit. Responses will be stronger to the pair f,g than to either f or g by itself. Two adjacent modules interacting. Hebbian learning will tend to bind responses of modules together if f and g frequently co-occur. We can extend this associative binding model to larger scale groupings. It may become possible to suggest a natural way to bridge the gap in scale between single neurons and entire brain regions. Networks > Networks of Networks > Networks of (Networks of Networks) > Networks of (Networks of (Networks of Networks)) and so on … Scaling Interference Patterns We are using local transmission of (vector) patterns, not scalar activity level. We have the potential for traveling pattern waves using the local connections. This lateral information flow allows the potential for the formation of feature combinations in the interference patterns where two different patterns col Learning the Interference Pattern The individual modules are nonlinear learning networks. We can form new attractor states when an interference pattern forms when two patterns meet at a module. Module Evolution Module evolution with learning: From an initial repertoire of basic attractor states to the development of specialized pattern combination states unique to the history of each module. Geometry of Interference Patterns Pattern information travels laterally. Patterns converge on particular locations. Some spatial (topographic) patterns of module activation should be favored by NofN learning. X Examples: X --- X --- X / \ X---X These equal distance arrangements give good convergence. The topographic arrangement of the data and the computation becomes critical. “Topographic programming” becomes a potential useable feature of the software. Biological Evidence: Columnar Organization in IT Tanaka (2003) suggests a columnar organization of different response classes in primate inferotemporal cortex. There seems to be some internal structure in these regions: for example, spatial representation of orientation of the image in the column. IT Response Clusters: Imaging Tanaka (2003) used intrinsic visual imaging of cortex. Train video camera on exposed cortex, cell activity can be picked up. At least a factor of ten higher resolution than fMRI. Size of response is around the size of functional columns seen elsewhere: 300-400 microns. Columns: Inferotemporal Cortex Responses of a region of IT to complex images involve discrete columns. The response to a picture of a fire extinguisher shows how regions of activity are determined. Boundaries are where the activity falls by a half. Note: some spots are roughly equally spaced. Active IT Regions for a Complex Stimulus Note the large number of roughly equally distant spots (2 mm) for a familiar complex image. Histogram of Distances Were able to plot histograms of distances in a number of published IT intrinsic images of complex figures. Distances computed from data in previous figure (Dimitriadis) Generalization Simple transformations of some complex images (here rotation of a face) are stored in adjacent cortical locations. Note the smooth translation of activity along the cortical surface. Revised Columnar Structure Tanaka suggested this might be general. Implications: Area TE in IT stores “theme plus variations”, that is, an image plus its most common and natural transformations. Generalization is hard: Here are “regions” representing useful generalizations. Network of Networks Functional Summary. • The NofN approximation assumes a two dimensional array of attractor networks. • The attractor states dominate the output of the system at all levels. • Interactions between different modules are approximated by interactions between their attractor states. • Lateral information propagation plus nonlinear learning allows formation of new attractors at the location of interference patterns. • There is a linear and a nonlinear region of operation in both single and multiple modules. • The qualitative behavior of the attractor networks can be controlled by analog gain control parameters. Engineering Hardware Considerations We feel that there is a size, connectivity, and computational power “sweet spot” at the level of the parameters of the network of network model. If an elementary attractor network has 104 actual neurons, that network display 50 attractor states. Each elementary network might connect to 50 others through state connection matrices. A brain-sized system might consist of 106 elementary units with about 1011 (0.1 terabyte) numbers specifying the connections. If 100 to 1000 elementary units can be placed on a chip there would be a total of 1,000 to 10,000 chips in a cortex sized system. These numbers are large but within the upper bounds of current technology. Proposed Basic System Architecture Our basic computer architecture consists of a potentially huge (millions) number of simple CPUs connected locally to each other and arranged in a two dimensional array. The (sparse) longer range connections are simulated in software. We assume each CPU can be identified with a single attractor network in the Network of Networks model. A Software Example: Sensor Fusion One potential application is to sensor fusion. Sensor fusion means merging information from different sensors into a unified interpretation. Involved in such a project in collaboration with Texas Instruments and Distributed Data Systems, Inc. The project was a way to do the de-interleaving problem in radar signal processing using a neural net. In a radar environment the problem is to determine how many radar emitters are present and whom they belong to. Biologically, this corresponds to the behaviorally important question, “Who is looking at me?” (To be followed, of course, by “And what am I going to do about it?”) Radar A receiver for radar pulses provide several kinds of quantitative data: • • • • • frequency, intensity, pulse width, angle of arrival, and time of arrival. The user of the radar system wants to know qualitative information: • • • • How many emitters? What type are they? Who owns them? Has a new emitter appeared? Concepts The way we solved the problem was by using a concept forming model from cognitive science. Concepts are labels for a large class of members that may differ substantially from each other. (For example, birds, tables, furniture.) We built a system where a nonlinear network developed an attractor structure where each attractor corresponded to an emitter. That is, emitters became discrete, valid concepts. Human Concepts One of the most useful computational properties of human concepts is that they often show a hierarchical structure. Examples might be: animal > bird > canary > Tweetie or artifact > motor vehicle > car > Porsche > 911. A weakness of the radar concept model is that it did not allow development of these important structures. Sensor Fusion with the Ersatz Brain. We can do simple sensor fusion in the Ersatz Brain. The data representation we develop is directly based on the topographic data representations used in the brain: topographic computation. Spatializing the data, that is letting it find a natural topographic organization that reflects the relationships between data values, is a technique of great potential power. Spatializing the problem provides a way of “programming” a parallel computer. Topographic Data Representation Low Values Medium Values High Values ••++++•••••••••••••••••••••••••••••••••••••••••••• •••••••••••••••••••••••++++••••••••••••••••••••••• ••••••••••••••••••••••••••••••••••••••••••••++++•• We initially will use a simple bar code to code the value of a single parameter. The precision of this coding is low. This loss of precision disturbed traditional radar engineers: we deliberately threw out their hard won precision. But we didn’t care about quantitative precision: qualitative analysis. We wanted For our demo Ersatz Brain program, we will assume we have four parameters derived from the source. An “object” is characterized by values of these four parameters, coded as bar codes on the edges of the array of CPUs. We assume local linear transmission of patterns from module to module. Demo Each pair of input patterns gives rise to an interference pattern, a line perpendicular to the midpoint of the line between the pair of input locations. There are places where three or four features meet at a module. The higher-level combinations represent relations between the individual data values in the input pattern. The higher level combinations have literally fused spatial relations of the input data, Formation of Hierarchical Concepts. This approach allows the formation of what look like hierarchical concept representations. Suppose we have three parameter values that are fixed for each object and one value that varies widely from example to example. The system develops two different types of spatial data. In the first, some high order feature combinations are fixed since the three fixed input (core) patterns never change. In the second there is a varying set of feature combinations corresponding to the details of each specific example of the object. The specific examples all contain the common core pattern. Core Representation The group of coincidences in the center of the array is due to the three input values arranged around the left, top and bottom edges. Left are two examples where there is a different value on the right side of the array. Note the common core pattern (above). Development of A “Hierarchy” Through Spatial Localization. The coincidences due to the core (three values) and to the examples (all four values) are spatially separated. We can use the core as a representation of the examples since it is present in all of them. The core represents relations between the data values, not the data itself. It acts as the higher level in a simple hierarchy: all examples contain the core. The many-to-one relationship here – many low level examples, fewer high level examples -- is typical of a hierarchical semantic networks. Conclusions The Ersatz Brain Project has led us down an interesting path. If we start to require software to use brain-like constraints,then new ways to tackle old problems emerge. • New “analog” control structures: We can use spatial “programming patterns” to do arithmetic. • We can spatialize the computation, the data and the solutions through initial representations and feature combinations. Conclusions • Potential emergence of hierarchical structure. • We can use related techniques to do disambiguation using context and semantic networks. These ideas might be of value for current computers. I feel that their real domain of application will be to the computers of the future.