Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
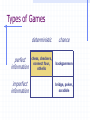
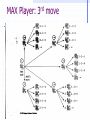
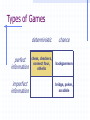
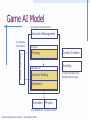
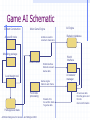
Search Can we apply the recently discussed search methods too all problems? Why or why not? How does the search change when there are multiple actors involved? Game Playing A second player (or more) is an adversary Examples: chess, checkers, go, tic-tac-toe, connect four, backgammon, bridge, poker Adversarial search. Players take turns or alternate play Unpredictable opponent. Solution specifies a move for every possible opponent move. Turn time limits How might they affect the search process? Types of Games perfect information imperfect information deterministic chance chess, checkers, connect four, othello backgammon bridge, poker, scrabble Example Game: Nim Deterministic, Opposite Turns Two players One pile of tokens in the middle of the table. At each move, the player divides a pile into two non-empty piles of different sizes. Player who cannot move looses the game. Example Game: Nim 7 Max attempts to maximize the advantage and win. 5-2 min Assume a pile of seven tokens. Min always tries to move to a state that is the worst for Max. 6-1 5-1-1 4-2-1 4-3 3-1-1-1-1 3-3-1 min 3-2-2 3-2-1-1 4-1-1-1 max 2-2-2-1 max 2-2-1-1-1 min 2-1-1-1-1-1 max Perfect Decision, Two person games Two players MAX and MIN MAX moves first; alternate turns thereafter. Formal definition of game Initial State Successor Function Terminal Test Utility Function No one player has full control, must develop a strategy. Minimax Algorithm: Basics 3 3 3 MAX 0 9 0 MIN 2 7 2 MAX 6 MIN 2 3 5 9 0 7 4 2 1 5 6 Process of Backing up: minimax decision Assumption: Both players are knowledgeable and play the best possible move Minmax Algorithm • Generate game tree to all terminal states. • Apply utility function to each terminal state. • Propagate utility of terminal states up one level. • MAX’s turn: MAX tries to maximize utility value. • MIN’s turn: MIN minimizes utility value. • Continue backing-up values toward root, one layer at a time. • At root node, MAX chooses the value with highest utility. Minimax Search What is the time complexity of the minimax algorithm? Minimax decision: maximizes utility for a player assuming that the opponent will play perfectly and minimize its utility. m – looking ahead m moves in game tree Search can be done in a depth first manner i.e. traverse down a path till terminal node reached, then back up value using minimax decision function. Minimax: Applied to Nim 1 0 6-1 5-1-1 0 7 1 5-2 1 4-2-1 4-1-1-1 min 1 1 0 3-2-2 1 3-2-1-1 1 4-3 max 1 3-3-1 min 0 2-2-2-1 max 2-2-1-1-1 min 3-1-1-1-1 What do we observe from tree? max 0 2-1-1-1-1-1 0 Partial Search What were our concerns with the other search algorithms we have discussed? • How do those concerns apply to games? • Full game tree may be too large to generate. Example: Partial Search for Tic-Tac-Toe • Generate tree to intermediate depth. • Calculate utility/evaluation function for leaf nodes. • Back up values to the root node so MAX player can make a decision. Example: Partial Search for Tic-Tac-Toe Position p: win for Max, u(p) = loss for MAX, u(p) = – otherwise, u(p) = (# of complete rows, cols, & diags still open for MAX) – (# of complete rows, cols, and diags still open for MIN) Tic-Tac-Toe Move 2 MAX Player: 3rd move Question If we apply an evaluation function to non-terminal nodes of a game tree, why generate a partial tree at all? Why not just compute an evaluation function to all states generated by applying valid operators (moves) to the current state, and selecting the one with the highest utility value? Assumption: An evaluation function applied to successor nodes produces more reliable (accurate) values. In other words, these configurations contain more information on how the game will likely end. Each level of game tree – termed a ply. Complex games What happens if Minimax is applied to large complex games? What happens to the search space? Example, chess: decent amateur program 1000 moves /second 150 seconds /move (tournament play) Look at approx. 150,000 moves Chess branching factor of 35 generating trees that are 3-4 ply, Resultant play – pure amateur Complex Games • Can we make search process more intelligent, and explore more promising parts of tree in greater depth? MAX Player: 3rd move Search starts depth first Back up value immediately MIN Do not need to generate these nodes! Why? The alpha-beta pruning procedure Node A generated first Alpha-Beta Pruning Definitions value – lower bound on MAX node value – upper bound on MIN node Observations value on MAX nodes never decrease values on MIN nodes never increase Application Search is discontinued below any MIN node with minvalue v : cut off Search is discontinued below any MAX node with max-value v : cut off Alpha-Beta Search Example MAX a b c d f e MIN g MAX MIN 1 2 3 4 Node ab d e c f 5 7 Alpha Beta -∞ 3 1 2 3 -∞ 4 -∞ 3 3 Completed 1 0 2 3 ∞ ∞ 3 CUT-OFF ∞ 3 CUT-OFF ∞ 6 1 5 Function Node V Return Max A -∞, 3 +∞ -∞, 3 3, 2 Min B -∞ +∞, 3 +∞, 3 3, 4 Max D -∞,1,2,3 +∞ -∞,1,2,3 1,2,3 Min 1 -∞ +∞ Min 2 1 +∞ Min 3 2 +∞ Max E -∞ 3 -∞, 4 4 Min 4 -∞ 3 Min C 3 +∞, 6 +∞, 6 6 Max F 3,4,5,6 +∞ -∞,4,5,6 4,5,6 Min 4 3 +∞ Min 5 4 +∞ Min 6 5 +∞ Max G 3 6 -∞, 6 6 Min 6 3 6 Cutoff 5 & 7 Cutoff 1 & 5 Key: -∞ = negative infinity; +∞ = positive infinity The last value in a square is the final value assigned to the specific variable, i.e. at the end of the search Node A’s = 3. Alpha-Beta Search Algorithm Computing and value of MAX node = current largest final backedup value of its successors. value of MIN node = current smallest final backedup value of its successors. Start with AB(n; -, +) Alpha-Beta Search Algorithm Alpha-Beta-Search(state) returns an action v = MAX-VALUE(state,-∞, +∞) return the action in SUCCESSORS(state) with value v MAX-VALUE(state, , ) if TERMINAL-TEST(state) then return UTILITY(state) v = -∞ for a, s in SUCCESSORS(state) do v = MAX(v, MIN-VALUE(s, , )) if v >= then return v = MAX(, v) return v (a utility value) MIN-VALUE(state, , ) if TERMINAL-TEST(state) then return UTILITY(state) v = +∞ for a, s in SUCCESSORS(state) do v = MIN(v, MAX-VALUE(s, , )) if v <= then return v = MIN(, v) return v (a utility value) Alpha-Beta Search Example 2 MAX a b d h c f e j i l k MIN g MAX m n MIN MAX 7 4 2 5 5 1 0 2 8 7 3 0 1 2 Alpha-Beta Search Example 3 MAX a b d h c f e j i MIN l k m g MAX n o MIN MAX 5 1 1 2 0 -1 -5 0 -1 0 -4 -3 3 1 1 4 Alpha-Beta Search Performance Uses depth-first search procedure Search effectiveness depends on node ordering Worst case occurs if worst moves generated first Best case occurs if best moves generated first: min value first for MIN nodes, and max value first for MAX nodes. (Is this always possible?) Alpha-Beta Search Performance Search tree of depth d, b moves per node bd tip nodes: Minimax search - O(bd) Best case: look at only O(bd/2) tip nodes Effective branching factor reduces to b so can double the depth of the search. Average case: Number of nodes examined: 3d O (b 4 ) Search depth increase 4/3 Pruning does not affect final result Games with chance Example, Games with dice Backgammon: white can decide what his/her legal moves are, but can’t determine black’s because that depends on what black rolls. Game tree must include chance nodes. How to pick best move? Cannot apply minimax directly. Games with Chance For each possible move, compute an average or expected value. Expectiminimax (n) UTILITY ( n ) max min sSuccessors( n ) sSuccessors( n ) sSuccessors(n) if n is a terminal state Expectiminimax ( s ) if n is a Max node Expectiminimax ( s ) if n is a Min node P(s)*Expectiminimax( s ) if n is a chance node Complexity – O(bmnm) where n is the number of distinct values (e.g. dice rolls) Expectimax example Types of Games perfect information imperfect information deterministic chance chess, checkers, connect four, othello backgammon bridge, poker, scrabble Game AI Model AI is given processor time Execution Management World Interface AI receives information Group AI Content Creation Strategy Scripting Character AI Decision Making Movement Animation Physics AI is turned into on-screen action Artificial Intelligence for Games – Ian Millington 2006 AI has implications for Related technologies Game AI Schematic Content Construction Main Game Engine AI specific tools AI data is used to construct characters Modeling package Level Loader World interface Extracts relevant Game data Game engine Calls AI each frame Package level data Artificial Intelligence for Games – Ian Millington 2006 Behavior database World Interface Level design tool Per-frame processing AI Engine Results of AI Are written back To game data AI behavior manager AI receives data from the game and from its internal information AI in Games Types of AI in games Hacks Heuristics Common Heuristics Most Constrained Do the most difficult thing first Try the most promising thing first Algorithms Artificial Intelligence for Games – Ian Millington 2006 AI in Games Path following Collision avoidance Finding paths World Representations Movement planning Decision making Tactical analysis Terrain analysis Artificial Intelligence for Games – Ian Millington 2006 Coordinating action Learning Board Games Best AI agents for Chess, Backgammon and Reversi employ dedicated hardware, algorithms and optimizations. Basic underlying algorithms are common across games. Most popular AI for board games is minimax family. Recently Memory-enhanced test driver (MTD) algorithms are gaining favor. Artificial Intelligence for Games – Ian Millington 2006 Transposition Tables Transposition Tables (memory) Multiple board positions that are identical. Table contains board positions and results of a search from that position. Artificial Intelligence for Games – Ian Millington 2006 Transposition Tables Hash game states An hashing algorithm can work but… Zobrist Keys: a set of fixed-length random bit patterns stored for each possible state of each possible location on the board. Chess: 64 x 2 x 6 = 768 entries For each non-empty square, the Zobrist key is located and XORed with a running hash total. Artificial Intelligence for Games – Ian Millington 2006 Transposition Tables What to store Minimax: Store value and the depth used to calculate the value. Alpha-Beta: store the value, if the value is accurate or “fail-soft” (because of pruning). Alpha pruning: fail-low value Beta pruning: fail-high value Artificial Intelligence for Games – Ian Millington 2006 Transposition Tables Issues Path Dependency Some games have scores dependent upon the sequence of moves. Repetitions will be identically scored, so algorithm may disregard a winning move. Fix by using a Zorbist key for “number of repeats”. Artificial Intelligence for Games – Ian Millington 2006 Transposition Tables Issues Instability The stored values fluctuate during the same search since values may be over written. Not guaranteed to get the same value on each lookup. In rare cases, could have an oscillating value situation. Artificial Intelligence for Games – Ian Millington 2006 Memory-Enhanced Test (MT) Algorithm Require an efficient transposition table that acts as memory. Implemented as a zero-width AB negamax with a transition table. Negamax swaps and inverts the alpha and beta values and checks and prunes only against the Beta value. Artificial Intelligence for Games – Ian Millington 2006 MTD Algorithm The driver routine repeatedly calls the MT Algorithm to “zoom in” on the correct minimax value and determine the next move. – Memoryenhanced Test Drivers. Artificial Intelligence for Games – Ian Millington 2006 MTD Algorithm Track the upper bound on the score value – Gamma Let Gamma be the first guess of the score. Calculate another guess by calling the MT algorithm for the current board position, the maximum depth, zero for the current depth, and the gamma value. If the returned guess is not the same as gamma, then calculate another guess in order to confirm that the guess is correct. (usually limit the number of iterations) Return the guess as the score. Artificial Intelligence for Games – Ian Millington 2006 Opening Books An opening book is a set of moves combined with information regarding how good the average outcome is when using the moves. Typically at the start of the game. Play books – certain games have stages where plays can be employed. State of the Art: Games Traditional games Chess: HITECH (Berliner, CMU) – alpha-beta, horizon effect, 10 million positions per move, accurate evaluation functions: defeated human grandmaster in 1987 Deep Thought: Hsu, Ananthraman, and others at CMU: generated 720,000 chess positions per second – won World Computer Chess Championship in 1989 Hsu, Campbell and others, CMU to IBM: more focus on fast computation – parallel processing to solve complex problems: evolution from Deep Thought to Deep Blue (1993) Deep Blue – massively parallel 32 node RISC system + distributed memory built by IBM. Each node has 8 VLSI chess processors – therefore, 256 processors working in tandem. First played Kasparov in 1996, won game 1, but eventually lost to Kasparov. State of the Art: Games May 1997 (Deeper Blue) rematch. Processor speed doubled, evaluation functions improved with help from a multitude of grandmasters (chief advisor: Joel Benjamin, US chess champ) Deep(er) Blue was generating and evaluating up to 200 million chess positions per sec, i.e., 200 billion moves every 3 minutes. Typical grandmaster computes only 500 moves in 3 minutes. Result: Deep Blue: won 2, lost 1, drew 3. Ques: Was Deep Blue really intelligent? State of the Art: Games Chess: (continued) … Quote from Feng-hsuing Hsu: “The previous version of Deep Blue, lost a match to Gary Kasparov in Philadelphia in 1996. But 2/3rds of the way into that match, we had played to a tie with Kasparov. That old version of Deep Blue was already faster than the machine I had conjectured in 1985, and yet it was not enough. There was more to solving the Computer Chess Problem than just increasing the hardware speed. Since that match, we rebuilt Deep Blue from scratch, going through every match problem, and engaging grandmasters extensively in our preparations. Somehow, all that work cause Grandmaster Joel Benjamin, our chess advisor, to say, “You know, sometimes Deep Blue plays chess.” Joel could not distinguish with certainty Deep Blue’s moves from the moves of top grandmasters.” State of the Art: Games Checkers: Big breakthrough in AI: Samuels in 1952 at IBM; played itself thousands of times and learned its own evaluation functions. Evaluation function was a weighted sum of a set of functions. Best checkers programs now – as good as human champions Othello: human players refuse to play computer games, who can play perfectly. Go: branching factor of game > 300, so straight search doesn’t work. Have to use pattern knowledge bases. Does not match up to human champions 20 (21 20)3 1.2 109 State of the Art Games Backgammon: 2 dice 20 legal moves (can be 6000 with 1-1 roll) depth 4 = as depth increases, probability of reaching nodes decreases, so value of look ahead is diminished. (alpha-beta not a great idea). best backgammon game: uses depth 2 search + very good evaluation function. plays at world championship level.