Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
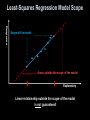
Lesson 4 - R Chapter 4 Review More about Relationships Between Two Variables Objectives • Identify settings in which a transformation might be necessary in order to achieve linearity. • Use transformations involving powers and logarithms to linearize curved relationships. • Explain what is meant by a two-way table, and describe its parts. • Give an example of Simpson’s paradox. • Explain what gives the best evidence for causation. • Explain the criteria for establishing causation when experimentation is not feasible. Vocabulary • None new Residuals ● One difference between math and stat is that statistics assumes that the measurements are not exact, that there is an error or residual ● The formula for the residual is always Residual = Observed – Predicted ● This relationship is not just for this chapter … it is the general way of defining error in statistics ● The least squares regression line minimizes the sum of the square of the residuals Residual on the Scatter Diagram The model line The residual The observed value y The predicted value y The x value of interest Least-Squares Regression Model Scope Response Scope of the model Areas outside the scope of the model Explanatory Linear relationship outside the scope of the model is not guaranteed! Things to Remember • In the Least Square Regression model: – R² gives us the % of the variation in the response variable explained by the model – the mean of the response variable depends on the linearity of the explanatory variable – the residuals must be normally distributed with constant error variance – the εi will be normally distributed (0,σ²) – we are estimating two values (b0 b1) and therefore lose 2 degrees of freedom in the t-statistic – the prediction interval for an individual response will be wider than the confidence interval for a mean response – procedures are robust Things to Remember • In Multiple Regression models: – the adjusted R² gives us the % of the variation in the response variable explained by the model • R² is adjusted based on # of sample and number of explanatory variables in the model – multicollinearity may be a problem if a high linear correlation exists between explanatory variables • Rule: |correlation| > 0.7 then multicollinearity possible – the procedure used in our book for multiple regression modeling is called backwards step-wise regression • Rule: remove explanatory variable with highest p-value and then rerun the model check adjusted R² values Multiple Regression Model yi = β0 + β1x1i + β2x2i + … + βkxki + εi where yi is the value of the response variable for the ith individual β0, β1, β2, , βk ,are the parameters to be estimated based on the sample data x1i is the ith observation for the first explanatory variable, x2i is the ith observation for the second explanatory variable and so on εi is am independent random error term that is normally distributed with mean 0 and variance = σ² i = 1, 2, 3, …, n, where n is the sample size • The adjusted R² is used in multiple regression models – The adjusted R² will decrease if a variable is added to the model that does little to explain the variation in the response variable. – The adjusted R² will increase if a variable is taken from the model that does little to explain the variation in the response variable. ANOVA • We use the Analysis of Variance (ANOVA) method to compare three or more means • ANOVA analyzes the differences in the sample means using sums of squares and an F test • One-way ANOVA analyzes models where there is only one factor that differentiates the groups • Two-way ANOVA analyzes models where there are two factors that differentiate the groups Summary and Homework • Summary • Homework – pg