Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Fundamentals of
Statistics
EBB 341
Statistics?
A collection of quantitative data from a
sample or population.
The science that deals with the
collection, tabulation, analysis,
interpretation, and presentation of
quantitative data.
Statistic types
Deductive or descriptive statistics
describe and analyze a complete data set
Inductive statistics
deal with a limited amount of data
(sample).
Conclusions: probability?
Population
A population is any entire collection of
people, animals, plants or things from
which we may collect data.
It is the entire group we are interested in,
which we wish to describe or draw
conclusions about.
For each population there are many
possible samples.
Sample
A sample is a group of units selected from
a larger group (population).
By studying the sample it is hoped to draw
valid conclusions about population.
The sample should be representative of the
general population.
The
best way is by random sampling.
Parameter
A parameter is a value, usually
unknown (and which therefore has to
be estimated), used to represent a
certain population characteristic.
For
example, the population mean is a
parameter that is often used to indicate
the average value of a quantity.
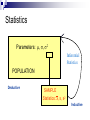
Statistics
Parameters: 2
Inferential
Statistics
POPULATION
Deductive
SAMPLE
Statistics: x, s, s2
Inductive
Inferential Statistics
Statistical Inference makes use of
information from a sample to draw
conclusions (inferences) about the
population from which the sample was
taken.
Types of data
Variables data
quality
characteristics that are measurable values.
measurable and normally continuous;
may take on any value - eg. weight in kg
Attribute data
quality
characteristics that are observed to be either
present or absent, conforming or nonconforming.
countable and normally discrete; integer - eg: 0, 1, 5,
25, …, but cannot 4.65
Accurate and Precise
Data life of light bulb: 995.6 h
The
value of 995.632 h, is too accurate &
unnecessary
Keyway spec: lower limit 9.52 mm, upper
limit 9.58 mm – data collected to the
nearest 0.001 mm, and rounded to nearest
0.01 mm.
Accurate and Precise
Measuring instruments may not give a
true reading because of problems due to
accuracy and precision.
Data: 0.9532, 0.9534 = 0.953
Data: 0.9535, 0.9537 = 0.954
If the last digit is 5 or greater, rounded up
Describing the Data
Graphical:
Plot
or picture of a frequency distribution.
Analytical:
Summarize
data by computing a measure of
central tendensy and dispersion.
Sampling Methods
Sampling methods are methods for selecting a sample
from the population:
Simple random sampling - equal chance for each member of
the population to be selected for the sample.
Systematic sampling - the process of selecting every n-th
member of the population arranged in a list.
Stratified sample - obtained by dividing the population into
subgroups and then randomly selecting from each subgroups.
Cluster sampling - In cluster sampling groups are selected
rather than individuals.
Incidental or convenience sampling - Incidental or
convenience sampling is taking an intact group (e.g. your own
forth grade class of pupils)
Frequency Distribution
Consider the following set
of data which are the
high temperatures
recorded for 30
consequetive days.
We wish to summarize
this data by creating a
frequency distribution of
the temperatures.
Data Set - High
Temperatures for 30 Days
50
45
49
50
43
49
50
49
45
49
47
47
44
51
51
44
47
46
50
44
51
49
43
43
49
45
46
45
51
46
To create a frequency distribution
Identify the highest and lowest values (51 & 43).
Create a column with variable, in this case temp.
Enter the highest score at the top, and include all
values within the range from highest score to
lowest score.
Create a tally column to keep track of the scores.
Create a frequency column.
At the bottom of the frequency column record the
total frequency.
To create a frequency distribution
Frequency Distribution for High Temperatures
Temperature
Tally
Identify the highest
and lowest
valuesFrequency
(51 & 43).
51
////
4
Create a column with variable, in this case temp.
50
////
4
Enter the highest score at the top, and include all
49
//////
6
values within the range from highest score to
48
0
lowest score.
47
///
3
Create a tally column to keep track of the scores.
46
///
3
Create a frequency
column.
45
////
4
At the bottom of the
the
44 frequency///column record
3
total frequency. 43
///
3
N=
30
Frequency Distribution
Frequency Distribution for High Temperatures
Temperature
51
50
49
Tally
////
////
//////
48
47
46
45
44
43
Frequency
4
4
6
0
///
///
////
///
///
3
3
4
3
3
N=
30
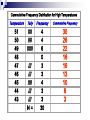
Cummulative Frequency Distribution
A cummulative freq distribution can be created by
adding an additional column called "Cummulative
Frequency."
The cum. frequency for a given value can be obtained by
adding the frequency for the value to the cummulative
value for the value below the given value.
For example: The cum. frequency for 45 is 10 which is
the cum. frequency for 44 (6) plus the frequency for 45
(4).
Finally, notice that the cum. frequency for the highest
value should be the same as the total of the frequency
column.
Cummulative Frequency Distribution for High Temperatures
Temperature
Tally
Frequency
Cummulative Frequency
51
50
49
48
47
46
45
44
43
////
////
//////
4
4
6
0
3
3
4
3
3
30
30
26
22
16
16
13
10
6
3
///
///
////
///
///
N=
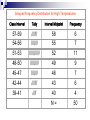
Grouped frequency distribution
In some cases it is necessary to group the values of the
data to summarize the data properly.
Eg., we wish to create a freq. distribution for the IQ
scores of 30 pupils.
The IQ scores in the range 73 to 139.
To include these scores in a freq. distribution we would
need 67 different score values (139 down to 73).
This would not summarize the data very much.
To solve this problem we would group scores together
and create a grouped freq. distribution.
If data has more than 20 score values, we should create
a grouped freq. distribution by grouping score values
together into class intervals.
To create a grouped frequency
distribution:
select an interval size (7-20 class intervals)
create a class interval column and list each of the class
intervals
each interval must be the same size, they must not
overlap, there may be no gaps within the range of class
intervals
create a tally column (optional)
create a midpoint column for interval midpoints
create a frequency column
enter N = sum value at the bottom of the frequency
column
Grouped frequency
Look at the following data of
high temperatures for 50 days.
The highest temperature is 59
and the lowest temperature is
39.
We would have 21
temperature values.
This is greater than 20 values
so we should create a grouped
frequency distribution.
Data Set - High Temperatures for
50 Days
57
39
52
52
43
50
53
42
58
55
58
50
53
50
49
45
49
51
44
54
49
57
55
59
45
50
45
51
54
58
53
49
52
51
41
52
40
44
49
45
43
47
47
43
51
55
55
46
54
41
Grouped Frequency Distribution for High Temperatures
Class Interval
Tally
Interval Midpoint
Frequency
57-59
//////
58
6
54-56
///////
55
7
51-53
///////////
52
11
48-50
/////////
49
9
45-47
///////
46
7
42-44
//////
43
6
39-41
////
40
4
N=
50
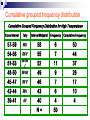
Cumulative grouped frequency distribution
Cumulative Grouped Frequency Distribution for High Temperatures
Class Interval
Tally
Interval Midpoint
Frequency
Cumulative Frequency
57-59
54-56
51-53
48-50
45-47
42-44
39-41
//// /
58
55
52
49
46
43
40
6
7
11
9
7
6
4
50
44
37
26
17
10
4
N=
50
//// //
//// ////
/
//// ////
//// //
//// /
////
To create a histogram from this
frequency distribution
Arrange the values along the abscissa (horizonal
axis) of the graph
Create a ordinate (vertical axis) that is
approximately three fourths the length of the
abscissa, to contain the range of scores for the
frequencies.
Create the body of the histogram by drawing a bar
or column, the length of which represents the
frequency for each age value.
Provide a title for the histogram.
Frequency
High temperatures for 50 days
Temperatures
Histograms
Constructing
a Histogram for Discrete Data
First, determine the frequency and relative
frequency of each x value.
Then mark possible x value on a horizontal scale.
Cara Menyediakan Histogram Grouped Data
Tentukan nilai perbezaan, R = nilai terbesar – nilai
terkecil atau R = Xh - Xl
Dapatkan bilangan turus histogram,
t N
Kira lebar turus, h = R/t
Nilai permulaan turus = nilai terkecil data – (h/2)
atau Xl – (h/2)
Lukis histogram.
Histograms
Constructing a Histogram for Continuous Data: equal class
width
Number of classes number of observatio ns
Data
Relative frequency
Bar Graph
A bar graph is similar to a histogram except that the
bars or columns are seperated from one another by
a space rather than being contingent to one another.
The bar graph is used to represent categorical or
discrete data, that is data at the nominal or ordinal
level of measurement.
The variable levels are not continuous.
Bar Graph
Major
Frequenc
y
Counseling
11
Ed Admin
3
Elem Educ
1
Music Educ
1
Reading
2
Social
Work
Special
Educ
1
N=
24
5
Descriptive statistics
Measures of Central Tendency
Describes
the center position of the data
Mean, Median, Mode
Measures of Dispersion
Describes
the spread of the data
Range, Variance, Standard deviation
Measures of central tendency:
Mean
N
Arithmetic mean: x =
1
xi
N i 1
where xi is one observation, means
“add up what follows” and N is the
number of observations
So, for example, if the data are : 0,2,5,9,12 the
mean is (0+2+5+9+12)/5 = 28/5 = 5.6
Mean for a Population
Science Test Scores
17 23 27 26 25
Frequency Distribution of Ages for Children in
After School Program
Age
11
10
9
8
7
6
5
N=
Frequency
2
4
8
7
3
0
1
25
fX
22
40
72
56
21
0
5
216
30 19 24 29 18
25 26 23 22 21
Mean for a Sample
Ungrouped data:
n
Xi
X X ... X
i
1
2
n
X
1
n
n
Grouped data:
h
X
f X
i 1
i
n
i
f 1 X 1 f 2 X 2 ... f h X h
f 1 f 2 ... f h
n= number of
observed values
n = sum of the
frequencies
h= number of cells
or number
observed values
Xi = cell midpoint
Example: - ungrouped data
Resistance of 5 coils: 3.35, 3.37, 3.28,
3.34, 3.30 ohm.
The average:
n
Xi
3.35 3.37 3.28 3.34 3.30
X
3.33
n
5
i 1
Example: - grouped data
Frequency Distributions of the life of 320 tires in 1000 km
Boundaries
Midpoint, Xi
Frequency, fi
Computation, fiXi
23.6-26.5
25.0
4
100
26.6-29.5
28.0
36
1008
29.6-32.5
31.0
51
1581
32.6-35.5
34.0
63
35.6-38.5
37.0
58
38.6-41.5
40.0
52
41.6-44.5
43.0
34
1462
44.6-47.5
46.0
16
736
47.6-50.5
49.0
6
294
n = 320
fiXi = 11549
Total
h
X
i 1
2142
f i X2146
i
11,549
36.1
2080
n
320
Measures of Location
Data:
• Central tendency
x1 , x2 ,..., xn
• sample mean
x x ... xn 1
x 1 2
n
n
n
x
i
i 1
• sample median
x( n 1) / 2
if n is odd
~
x
{xn / 2 x( n / 2) 1} / 2 if n is even
e.g. data: 2, 2, 3, 4, 15
x 5.2, ~
x 3
Provided that data is
in increasing order
• Median is less sensitive
to outliers.
Median - mode
Median = the observation in the ‘middle’ of
sorted data
Mode = the most frequently occurring
value
Median and mode
100 91 85 84 75 72 72 69 65
Mode
Median
Mean = 79.22
Median
Grouped data:
n
cfm
i
Md Lm 2
fm
Lm= lower boundary with the median
cfm= cumulative freq. all cells below Lm
fm= freq. median
i = cell interval
Median - Grouped technique
Use data from table above (Frequency Distributions of the
life of 320 tires in 1000 km).
The halfway point (320/2 = 160) is reached in the cell with
midpoint value of 37.0 and a lower limit of 35.6.
The cumulative frequency is 4+36+51+63 is 154, the cell
interval is 3, and the frequency of the median cell is 58:
320
154
3 35.9
Md 35.6 2
58
Median = 35.9 x 1000 km = 35900 km.
Measures of dispersion: range
The range is calculated by taking the
maximum value and subtracting the
minimum value.
2 4 6 8 10 12 14
Range = 14 - 2 = 12
Measures of dispersion:
variance
Calculate the deviation from the mean for
every observation.
Square each deviation
Add them up and divide by the number of
n
2
observations
2
( xi
i 1
n
Variance for a population
The formula for the variance for a
population using the deviation score
method is as follows:
The mean = 28/7 = 4
The population variance:
Worksheet for Calculating the
Variance for 7 scores
5
1
1
3
-1
1
4
0
0
4
0
0
3
-1
1
4
0
0
5
1
1
28
4
Measures of dispersion:
standard deviation
The standard deviation is the square root
of the variance.
The variance is in “square units” so the
standard deviation is in the same units as
x.
n
( xi
i 1
n
2
Standard Deviation for a Sample
General formula/ungrouped data:
n
s
(X
i 1
i
X )2
n 1
For computation purposes:
n X X i
i 1
i 1
s
n(n 1)
n
n
2
i
2
Standard Deviation for a Sample
Grouped data:
n ( f i X ) f i X i
i 1
i 1
s
n(n 1)
h
h
2
i
2
Example- ungrouped data
Sample: Moisture content of kraft paper
are 6.7, 6.0, 6.4, 6.4, 5.9, and 5.8 %.
6(231.26) (37.2)
s
0.35
6(6 1)
2
Sample standard deviation, s = 0.35 %
Calculating the Sample Standard
Deviation - Grouped technique
Standard deviation for a grouped sample:
n ( f i X ) f i X i
i 1
s i 1
n (n 1)
h
2
i
h
Table: Car speeds in km/h
2
Average:
Boundaries
Xi
fi
fiXi
fiXi2
72.6-81.5
77.0
5
385
29645
81.6-90.5
86.0
19
1634
140524
90.6-99.5
95
31
2945
279775
99.6-108.5
104.0
27
2808
292032
108.6-117.5
113
14
1582
178766
96
9354
920742
n
fi X i
X i 1
s
n
9354
97.4
96
96(920,742) (9354)
9.9
96(96 1)
2
Total
Skewness
h
a3
fi ( X i X ) / n
3
i 1
s
3
a3 = 0, symmetrical
a3 > 0 (positive), the data are skewed to the right,
means that long the long tail is to right
a3 < 0 (negative), skewed to the left, means that
long the long tail is to left
h
Kurtosis
a4
fi ( X i X ) / n
4
i 1
s
4
Leptokurtic (more peaked) distribution
Platykurtic (flatter) distribution
Mesokurtic (between these 2 distribution – normal
distribution.
For example,
if a normal distribution, mesokurtic, has a4 = 3,
a4 > 3 is more peaked than normal
a4 < 3 is less peaked than normal.
Example:
Xi
fi
Xi - X
fi (Xi-X )3
fi (Xi- X )4
1
4
(1-7) =
-6
-864
5184
4
24
(4-7) =
-3
-648
1944
7
64
(7-7) =
0
0
0
10
32
(10-7)
= +3
+864
2592
-648
9720
124
648 / 124
a3
0
.
43
3
2.30
That data are skewed to the left
9720 / 124
a4
2.80
4
2.30
Standard deviation and curve
shape
If is small, there is a high probability for
getting a value close to the mean.
If is large, there is a correspondingly
higher probability for getting values further
away from the mean.
The Normal Curve
The normal curve or the normal frequency
distribution or Gaussian distribution is a
hypothetical distribution that is widely used in
statistical analysis.
The characteristics of the normal curve make
it useful in education and in the physical and
social sciences.
Characteristics of the
Normal Curve
The normal curve is a symmetrical distribution of
data with an equal number of data above and below
the midpoint of the abscissa.
Since the distribution of data is symmetrical the
mean, median, and mode are all at the same
point on the abscissa.
In other words, mean = median = mode.
If we divide the distribution up into standard
deviation units, a known proportion of data lies
within each portion of the curve.
34.13% of data lie between and 1 above the mean ().
34.13% between and 1 below the mean.
Approximately two-thirds (68.28 %) within 1 of the mean.
13.59% of the data lie between one and two standard
deviations
Finally, almost all of the data (99.74%) are within 3 of the
mean.
The normal curve
If x follows a bell-shaped (normal)
distribution, then the probability that x is
within
1
standard deviation of the mean is 68%
2 standard deviations of the mean is 95 %
3 standard deviations of the mean is 99.7%
Standardized normal value, Z
When a score is expressed in standard deviation
units, it is referred to as a Z-score.
A score that is one standard deviation above the
mean has a Z-score of 1.
A score that is one standard deviation below the
mean has a Z-score of -1.
A score that is at the mean would have a Z-score of
0.
The normal curve with Z-scores along the abscissa
looks exactly like the normal curve with standard
deviation units along the abscissa.
Z-value
Deviation IQ Scores, sometimes called Wechsler IQ scores,
are a standard score with a mean of 100 and a standard
deviation of 15.
What percentage of the general population have deviation IQs
lower than 85?
So an IQ of 85 is equivalent to a z-value of –1.
So 50 % - 34.13 % = 15.87% of the population has IQ
scores lower than 85.
Frequency Polygon
A frequency polygon is what you may think
of as a curve.
A frequency polygon can be created with
interval or ratio data.
Let's create a frequency polygon with the
data we used earlier to create a histogram.
To create a frequency polygon
Arrange the values along the abscissa (horizonal axis).
Arrange the lowest data on the left & the highest on the
right.
Add one value below the lowest data and one above the
highest data.
Create a ordinate (vertical axis).
Arrange the frequency values along the abscissa.
Provide a label for the ordinate (Frequency).
Create the body of the frequency polygon by placing a
dot for each value.
Connect each of the dots to the next dot with a straight
line.
Provide a title for the frequency polygon.
To create a frequency polygon