Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Scientific Methods 1
‘Scientific evaluation, experimental design
& statistical methods’
COMP80131
Lecture 11: Statistical MethodsIntro to PCA & Monte Carlo Methods
Barry & Goran
www.cs.man.ac.uk/~barry/mydocs/MyCOMP80131
13 Dec 2011
COMP80131-SEEDSM11
1
Correlation & covariance
Correlation coeff for two samples of M variables
M
(x
m 1
m
meanx )( ym meany )
Lies between -1 & 1
varx var y
Covariance between two samples of M variables:
1 M
( xm meanx )( ym meany ) or
M 1 m 1
1
M
M
...
m 1
Use 1/(M-1) if meanx is sample-mean & 1/M if meanx is pop-mean
13 Dec 2011
COMP80131-SEEDSM11
2
In vector notation
(1/(varx.vary)) xT y
x=
1
2
2
3
3
y=
(1/M) xTy
or
when means have been
subtracted
-3
-4
5
5
4
6
1
Both measure similarity between 2 columns of numbers (vectors).
13 Dec 2011
COMP80131-SEEDSM11
3
Principal Components Analysis
• PCA converts samples of M variables into samples of a
smaller number of variables called principal components.
• Produces shorter columns.
• Exploits interdependency or correlation among the M variables
in each col.
• Evidence is the similarity between columns as seen in lots of
examples.
• If there is none, PCA cannot reduce the number of variables.
• First princ comp has the highest variance.
• It accounts for as much variability as possible.
• Each succeeding princ comp has the highest variance possible
while being orthogonal to (uncorrelated with) the previous
ones.
13 Dec 2011
COMP80131-SEEDSM11
4
PCA
• Reduces number of variables (dimensionality)
- without significant loss of information
• Also named:
‘discrete Karhunen–Loève transform (KLT)’,
‘Hotelling transform’
‘proper orthogonal decomposition (POD)’.
Related to (but not the same as): ‘Factor analysis’
13 Dec 2011
COMP80131-SEEDSM11
5
Example
Assume 5 observations of behaviour of 3 variables x1, x2, x3:
x1: 1 2 3 1 4
sample-mean = 11/5 = 2.2
x2: 2 1 3 -1 2
sample-mean = 1.4
x3: 3 4 7 1 8
sample mean = 4.6
Subtract means:
x1' : -1.2 -0.2 0.8 -1.2 1.8
x2' : 0.6 -0.4 1.6 -2.4 0.6
call this matrix X
x3' : -1.6 -0.6 2.4 -3.6 3.4
Calculate ‘Covariance Matrix’ (C):
x1 '
x2' x3'
x1' : 1.7 1.15 3.6
cov(x1',x2') = average value of x1'.x2'
x2' : 1.15 2.3 3.45
= (-1.20.6 +0.20.4 + 0.81.6 +1.22.4+1.80.6)
x3' : 3.6 3.45 8.3
= 4.6/4 = 1.15
13 Dec 2011
COMP80131-SEEDSM11
6
Eigenvalues & eigenvectors
[U, diagV] = eig(C);
0.811 0.458 0.364
0.324 -0.87
0.372
-0.487 0.184 0.854
u3
u2
U
13 Dec 2011
u1
0
0
0
0
0
0.964 0
0
11.34
3 0
0
0 2 0
0 0
1
COMP80131-SEEDSM11
D
7
Transforming the measurements
• For each column of matrix X, multiply by UT to transform it to a
different set of numbers.
• For each column x’ transform it to UTx’
• Or do it all at once by calculating Y = UT*X.
• We get:
0
0
0
0
0
Y = -1.37 0.146 -0.583 0.874 0.929
-1.58 -0.734 2.936 -4.404 3.781
• First column of X is now expressed as:
0 u1 -1.37 u2 – 1.58 u3
• Similarly for all the other four columns of X.
• Each column is now expressed in terms of the eigenvectors of C.
13 Dec 2011
COMP80131-SEEDSM11
8
Reducing dimensionality
UT C U = D therefore C = U D UT ( since UT is inverse of U)
Now we can express:
C = 1 (u1 u1T) + 2 (u2 u2T) + 3 (u3 u3T)
Now look at the eigenvalues 1, 2, 3
Strike out zero valued ones (3) with corresponding eigenvectors (u3).
Leaves u1 & u2 as princ components.
Can represent all the data, without loss, with just these two.
Can remove smaller eigenvalues (such as 2) with its eigenvector.
(If they do not affect C much they should not affect X)
Whole data can represented by just u1 without serious loss of accuracy.
13 Dec 2011
COMP80131-SEEDSM11
9
Reconstructing orig data from princ comps
• Because Y = UT*X, then X = U*Y.
• So if we don’t strike out any eigenvals & eigenvecs, this gets
us back to orig data.
• If we strike out row 1 of Y and u1 (first col of U), we still get
back to orig data.
• If we strike out row 2 of Y and u2, we get back something
close to orig data.,
• We do not lose much info by keeping just one princ. comp
• Dimensionality reduces from 3 to 2 or 1.
• (Normally eigenvals reordered in decreasing magnitude, but I
have not done that here)
13 Dec 2011
COMP80131-SEEDSM11
10
In MATLAB
clear all; origData = [1 2 3 1 4 ; 2 1 3 -1 2 ; 3 4 7 1 8]
[M,N] = size(origData);
meanofCols = mean(origData,2); % subtract off mean for EACH dimension
zmData = origData - repmat(meanofCols,1,N)
covarMat = 1 / (N-1) * (zmData * zmData')
% find the eigenvectors and eigenvalues of covarMat
[eigVecs, diagV] = eig(covarMat)
eigVals = diag(diagV)
[reigVals, Ind] = sort(eigVals,'descend'); % sort the variances in decreasing order
reigVecs = eigVecs(:,Ind); % Reorder eigenvectors accordingly
proj_zmData = reigVecs' * zmData
disp('Approx to original data taking just a few principal components');
nPC = input('How many PCs do you need (look at eigenvals to decide):');
PCproj_zmData = proj_zmData(1:nPC,:)
PCVecs = reigVecs(:,1:nPC) %Only keep the first few reordered eigVecs
RecApprox_zmData = PCVecs * PCproj_zmData
RecApprox_origData = RecApprox_zmData + repmat(meanofCols,1,N)
13 Dec 2011
COMP80131-SEEDSM11
11
Monte Carlo Methods
• Use of repeated random sampling of the behaviour of highly
complex multidimensional mathematical equations describing
real or simulated systems, to determine their properties.
• The repeated random sampling produces observations to
which statistical inference can be applied.
13 Dec 2011
COMP80131-SEEDSM11
12
Pseudo-random processes
• Name Monte Carlo refers to the famous casino.
• Gambling requires a random process such as the spinning of a
roulette wheel.
• Monte Carlo methods use pseudo-random processes implemented
in software.
• ‘Pseudo-random’ processes are not truly random.
• The variables produced can be predicted by a person who knows
the algorithm being used.
• However, they can be used to simulate the effects of true
randomness.
• Simulations are not required to be numerically identical to real
processes.
• Aim is to produce statistical results such as averages & distributions.
• Requires a ‘sampling’ of the population of all possible modes of
behaviour of the system.
13 Dec 2011
COMP80131-SEEDSM11
13
Illustration
• Monte Carlo methods may be used to evaluate multidimensional integrals.
• Consider the problem of calculating the area of an ellipse by
generating a set of N pseudo-random number pairs (xi,yi)
uniformly covering the area -1<x<1, -1<y<1 as illustrated
next:
13 Dec 2011
COMP80131-SEEDSM11
14
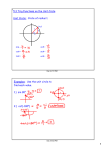
Area of an ellipse
y
1
Area of square is 2 2 = 4
If there are N points and M of
them fall inside the ellipse,
area of ellipse 4 M / N
x
-1
13 Dec 2011
as N
(Frequentist approach)
1
COMP80131-SEEDSM11
15
Simplicity of MC methods
• This example illustrates the simplicity of MC techniques, but
not their computational advantages.
• We could have use a regularly placed grid of points rather
than randomly placed points in the rectangle as on next slide
13 Dec 2011
COMP80131-SEEDSM11
16
Regular grid
y
1
x
-1
13 Dec 2011
1cm
COMP80131-SEEDSM11
17
Multi-dimensional integration
• In fact there are no advantages for such a 2-dimensional
dimensional problem.
• Consider a multi-dimensional integration
b1 b2 b3
bL
a1 a2 a3
aL
I
13 Dec 2011
...
f ( x1 , x2 , x3 ,..., xL )dx1dx2 dx3 ...dxL
COMP80131-SEEDSM11
18
Disadvantage of regular grid
• f(x1, x2, …, xL) may be evaluated at regularly spaced points as a
means of evaluating the integral.
• Number of regularly spaced points, N, must increase exponentially
with dimension L if error is not to increase exponentially with L.
• If N = 100 when L=2, then adjacent points will be 0.2 cm apart.
• If L increases to 3, we need N=103 points to maintain the same
separation between them.
• When L = 4, we need N= 104 etc. – ‘Curse of dimensionality’
• Look at this another way:
• Assume N remains fixed with regular sampling, and L increases.
• Each dimension must be sampled more & more sparsely
- and less and less efficiently.
• More & more points with same value in each dimension.
• Error increases in proportion to N-2/L
13 Dec 2011
COMP80131-SEEDSM11
19
Advantage of random sampling
• Uniformly distributed random points in L-dimensional space.
• Avoids the inefficiency of the rectangular grids created by
regular sampling by using a purely random sample of N points
uniformly distributed
• For high dimensions K, error is proportional to 1/(N)
• To reduce the error by a factor of 2, the sample size N must be
increased by a factor of 4 regardless of the dimensionality.
• There are ways of decreasing the Monte Carlo error to make
the technique still more efficient.
• One approach is to use ‘quasi-random’ or ‘low-discrepancy’
sampling.
• The use of such quasi-random sampling for numerical
integration is referred to as “quasi–Monte Carlo” integration.
13 Dec 2011
COMP80131-SEEDSM11
20
MATLAB: Area of Semicircle
for N=1:200
M=0;
for i=1:N
x=2*rand -1; y=rand*1.0;
I = sqrt(1-x*x);
if y <= I, M=M+1; end;
%if y <= I point (x,y) is below curve !!!
end;
Int(N)=M*2/N;
end; % of N loop
figure(6); plot(Int); title('Area of semicircle');
xlabel('Number of points');
13 Dec 2011
COMP80131-SEEDSM11
21
Convergence as N
Area of sdemicircle
2
1.9
1.8
1.7
1.6
1.5
1.4
1.3
0
13 Dec 2011
20
40
60
80
100
120
Number of points
140
COMP80131-SEEDSM11
160
180
200
22
MATLAB code for scatter plot
•
•
•
•
•
•
•
•
•
•
•
•
clear; N=6000;
M=0;
for i=1:N
x(i)=rand*2-1; y(i)=rand*1.0;
I = sqrt(1-x(i)*x(i));
if y(i)<=I, M=M+1; C(i) = 2; else C(i)=1; end;
end;
scatter(x,y,6,C,'filled');
Int = M*2/N ;
title(sprintf('Scatter of MC area method: N=%d, Int=%d',N,Int));
disp('Red if I<= y, blue if I>y');
xlabel('x Plot red if y <= I'); ylabel('y');
13 Dec 2011
COMP80131-SEEDSM11
23
Integration of circle – scatter plot
Scatter of MC area method: N=6000, Int=1.574000e+000
1
0.9
0.8
0.7
y
0.6
0.5
0.4
0.3
0.2
0.1
0
-1
13 Dec 2011
-0.8
-0.6
-0.4
-0.2
0
0.2
x Plot red if y <= I
0.4
0.6
COMP80131-SEEDSM11
0.8
1
24