Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Decomposition
• Data Decomposition
– Dividing the data into subgroups and assigning
each piece to different processors
– Example: Embarrassingly parallel applications
• Functional Decomposition
– Dividing an algorithm into its functional pieces
and executing the pieces in separate processors
– Example: Pipelining
Pipelined Computations
• Divide a problem into a series of tasks
• A processor completes a task sequentially and
pipes the results to the next processor
zero
P0
P1
P2
P3
P4
P5
∑A[i0]
∑A[i1]
∑A[i2]
∑A[i3]
∑A[i4]
∑A[i5]
P0
P1
P2
P3
P4
P5
Example of Summing Groups of Numbers
Question: Is this data or is it functional decomposition?
total
Where is Pipelining Applicable?
Type 1
– More than one instance of a problem
– Example: Multiple simulations with different parameter settings
Type 2
– Series of data items with multiple operations
– Example: Signal Filter or Eratosthenes Sieve
Type 3
– Partial results passed on while processing continues
– Example: Solving sets of linear equations
Considerations
–
–
–
–
Are there a series of sequential tasks?
Is the processing of each tack approximately equal?
Can items be grouped to minimize communication cost
If stages exceed processors
o Group stages
o Wrap last stage back to the first
– Determine where the result will be at the end of the process
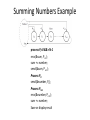
Summing Numbers Example
process Pi>0 && <N-1
recv(&sum, Pi-1);
sum += number;
send(&sum, Pi+1);
Process P0
send(&number, P1);
Process PN-1
recv(&number, Pn-2);
sum += number;
Save or display result
Application
• Remove frequencies from a signal
– Sequential Algorithm: Fourier Analysis (O(N lg(N))
– Parallel: Apply filters to the signal (O(N*FilterLength)) with convolution.
– Filter Examples: Chebyshev, ButtorWorth, etc.
– Derive filter: Set Z-domain poles and zeroes, perform inverse tranformation.
– Filters can be useful to manipulate signals, detect patterns, etc.
Chebyshev Filter Design
Chebyshev in the z-domain
Chebyshev Frequency Response
Note: Depending on the placement of the poles (+)
and zeroes (0), the filter will effect a signal differently
Type 1: Multiple Instances
Space Time Diagram
Instance 1
Instance 2
Instance 3
Instance 4
Instance 5
P0
P1
P2
P3
P4
P5
P0
P1
P2
P3
P4
P5
P0
P1
P2
P3
P4
P5
P0
P1
P2
P3
P4
P5
P0
P1
P2
P3
P4
P5
Time
Sequential execution: t1 = m*tm
Parallel Processing: (m + p – 1)*tm/p
Parallel Communication:
(m+p-1)*(tstart+n*tdata)
Speed up:
tp= m*tm/((m+p-1)*(tm/p+tstart+n*tdata))
Notation
1. m = instances, p = processors
2. tstart = latency tdata = bandwidth
3. n = data transmitted /instance
4. tm = total time to process an
instance
5. Total pipeline cycles = m + p – 1
6. Assume: Equal processing per stage
Type 2: Multiple Data Elements
d9d 8d7d6d5d4d3d2d1d0
P0
P0
P0
P0
P0
P0
Example: Signal Filter
Each process removes one or more frequencies from a digitized signal
Filter f1
Filter f0
Unfiltered
Signal
P0
Filter f3
Filter f2
P1
P2
Filter f5
Filter f4
P3
P4
P5
Filtered
Signal
Type 2 Timing Diagram
Type 3: Partial Processing
• The next stage receives information to continue processing
• Additional processing continues at the source processor
P5
P5
P4
P3
P2
P4
P3
= Idle
P2
= Executing
P1
P1
P0
P0
Linear Equations
A More Balanced Load
Question: How do we determine speed-up?
Operation at each processor
Types 1 and 2
• Processor with rank r = 0
– Generate the instance (type 1) or the data (type 2) to process
– Process appropriately
– Send message to the processor with rank 1
• Processors with rank r = 1, 2, p-2
– Receive message from the processor with rank r-1
– Process appropriately
– Send message to the processor with rank r+1
• Processor with rank r = p-1
– Receive message from processor with rank r-1
– Process appropriately
Examples
– Output final results
1) Adding Numbers: n1 -> n1+n2 -> n1+n2+n3 -> . . .
2) Frequency removal: f(t) -> f0; f(t-f0)-> f1; f(t-f0-f1)->
...
Parallel
Pipeline
Sort
• Pseudo code
Receive xi
IF xi < xmax
Send xi
ELSE
Send xmax
xmax = xi
Step Numbers
P0
P1
P2
1
4, 3, 1, 2, 5
2
4, 3, 1, 2
5
3
4, 3, 1
5
4
4, 3
5
5
4
5
P3
P4
2
1
3
4
2
2
1
2
6
5
7
5
4
8
5
4
3
9
5
4
3
2
10
5
4
3
2
3
Note: Processors can hold blocks of numbers for better efficiency
3
1
2
1
2
1
1
1
Bi-Directional Pipeline
• Use the pipeline to return results to the master
– Useful for line topologies, ring, or hypercube
P0
P1
Example: Sorting
• Sort Phase
P2
P3
P4
P5
P4
P3
P2
P1
P0
If (myid == 0) generate number
Else receive(&number, pmyid-1)
If (number > max and myid<P-1)
{ send(max,pmyid+1); maximuSoFar=number;}
• Gather phase
If (myid < P-1) receive sorted numbers from pmyid+1
If (myid > 0) send sorted numbers to pmyid-1
Time
Sorting Phase
Gather Phase
Phases
• N(generate steps);
• N-1 (propagate steps);
• N-1 (return steps) = 3N-2
Sieve of Eratosthenes
Prime Number Generation
Sieve of Eratosthenes (Type 2 pipeline)
• Concept
– Each processor filters blocks of non-primes from the flow of data
– The “potential” prime numbers pass through to the next
processor
• Pseudo-code
The Master processor generates an array of odd n numbers
In a loop after receiving a group of numbers
Filter a group of numbers; pass unfiltered numbers down the pipeline
Gather all of the primes
• Notes
– Wrapping the pipeline in a ring could help maintain load balance
– A termination message determines when the pipeline empties
Question: What range of numbers should each processor get?
Implementation
Sequential code
for (i = 2; i < n; i++)
prime[i] = 1;
for (i = 2; i <= sqrt_n; i++)
if (prime[i] == 1)
for (j = i + i; j < n; j = j + i)
prime[j] = 0
Sequential Time O(n2)
Parallel Code
Processor pi > 0
Recv(number, rank-1);
PRIME = TRUE;
FOR (int x=MIN; x<MAX; x+=MIN)
IF ((number % x) == 0)
PRIME = FALSE and BREAK
IF (PRIME) send(number, rank+1);
Termination
recv(number, rank-1);
send(number, rank+1)
IF (number == terminator) break;
Upper Triangular Matrix
All entries below the diagonal are zero
Useful for solving N equations and N unknowns
Solving Sets of Linear Equations
This is a type 3 pipeline example
•
•
Upper Triangular Form
an-1,0x0 + an-1,1x1 + … + an-1,n-1xn-1 = bn-1
an-2,0x0 + an-2,1x1 + … + an-2,n-2xn-1 = bn-2
a1, 0x0 + a1,1x1 = b1
a0,0x0 = b0
Back Substitution
x0=b0/a0,0
x1=(b1-a1,0x0)/a1,1
x2=(b2-a2,0x0-a2,1x1)/a2,2
• Parallel code for pi where 1<=i<n
sum = 0
For (j=0; j<i; j++)
{ receive(&x[j], pi-1); sum += ai,j * xj;
send(xj,pi+1)
}
xi = (bi – sum)/ai,i
Note: ai,j and bi are constants
• General solution for xi
xi= (bi – ∑j=0 to i-1 ai,j xj)/ai,I
• Sequential code
x[0] = b0/a0,0,
FOR (i=1; i<n; i++)
sum=0;
FOR (j=0; j<i; j++)
sum += ai,I xj
xi= (bi – sum)/ai,I
• Parallel Pseudo code
for (j = 0; j < i; j++)
recv(x[j], p-1); send(x[j], p+1);
sum = 0;
for (j = 0; j < i; j++)
sum = sum + a[i][j]*x[j]
x[i] = (b[i] - sum)/a[i][i];
send(x[i], p+1);
Pipeline Solution
DO
IF p ≠ master, receive xj from previous processor
IF p ≠ P-1, send xj to next processor
back substitute xj
UNTIL xi evaluated
IF p ≠ P-1send xi to the next processor
• Notes:
1. Processing continues after sending values
down the pipeline
2. Is the load imbalanced?
Illustration of Type 3 Solution
P0
Compute x0
P1
x0
P5
P4
P3
P2
P1
P0
x0
Compute x1 x1
P2
P3
Compute x2
x0
x1
x2
Compute x3
How balanced is
This load?
Time
x0
x1
x2
x3