Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Grammars, Languages
and Parse Trees
Language
•
•
•
•
Let V be an alphabet or vocabulary
V* is set of all strings over V
A language L is a subset of V*, i.e., L V*
L may be finite or infinite
• Programming language
– Set of all possible programs (valid, very long string)
– Programs with syntax errors are not in the set
– Infinite number of programs
Language Representation
•
Finite
–
•
Enumerate all sentences
Infinite language
–
–
Cannot be specified by enumeration
Use a generative device, i.e., a grammar
• Specifies the set of all legal sentences
• Defined recursively (or inductively)
Sample Grammar
• Simple arithmetic expressions (E)
• Basis Rules:
– A Variable is an E
– An Integer is an E
• Inductive Rules:
– If E1 and E2 are Es, so is (E1 + E2)
– If E1 and E2 are Es, so is (E1 * E2)
• Examples: x, y, 3, 12, (x + y), (z * (x + y)),
((z * (x + y)) + 12)
Production Rules
• Use symbols (aka syntactical categories) and
meta-symbols to define basis and inductive
rules
• For our example:
EV
EI
E (E + E)
E (E * E)
Basis Rules
Inductive
Rules
Formal Definition of a Grammar
G = (VN, VT, S, ), where
– VN , VT , sets of non-terminal and terminal symbols
– SVN, a start symbol
– = a finite set of relations from
(VT VN)+ to (VT VN)*
An element (, ) of , is written as and
is called a production rule or a rewrite rule
Sample Grammar Revisited
1. E V | I | (E + E) | (E * E)
2. V L | VL | VD
3. I D | ID
4. D 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
5. L x | y | z
VN: E, V, I, D, L
VT: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, x, y, z
S=E
: rules 1-5
Another Simple Grammar
• Symbols:
S: sentence
V: verb
O: object
A: article
N: noun
SP: subject phrase
VP: verb phrase
NP: noun phrase
• Rules:
S SP VP
SP A N
A a | the
N monkey | banana | tree
VP V O
V ate | climbs
O NP
NP A N
Context-Free Grammar
• A context-free grammar is a grammar with the
following restriction:
– The relation is a finite set of relations from
VN to (VT VN)+
• The left hand side of a production is a single non-terminal
• The right hand side of any production cannot be empty
• Context-free grammars generate context-free
languages. With slight variations, essentially all
programming languages are context-free languages.
We will focus on context-free grammars
More Grammars
Which are context-free?
G1 = (VN, VT, S, ), where:
VN = {S, B}
VT = {a, b, c}
S=S
= { S aBSc ,
S abc ,
Ba aB ,
Bb bb }
G3 = (VN, VT, S, ), where:
VN = {S, A, B }
VT = {a, b}
S=S
G2 = (VN, VT, S, ), where:
VN = {I, L, D}
VT = {a, b, …, z, 0, 1, …,
9}
S=I
= { I L | ID | IL ,
La|b|…|z,
D0|1|…|9 }
= { S aA ,
A aA | bB ,
B bB | }
Direct Derivative
Let G = (VN, VT, S, ) be a grammar
Let α, β (VN VT)*
β is said to be a direct derivative of α, written α
β, if there are strings 1 and 2 such that:
α = 1L 2,
β = 1λ 2,
L VN and
L λ is a production of G
We go from α to β using a single rule
Examples of Direct Derivatives
G = (VN, VT, S, ), where:
VN = {I, L, D}
VT = {a, b, …, z, 0, 1, …, 9}
S=I
= { I L | ID | IL
La|b|…|z
D0|1|…|9 }
α
β
Rule Used
1
2
I
L
IL
Ib
Lb
IL
b
Lb
ab
La
b
IDD
I0D
D0
I
D
Derivation
Let G = (VN, VT, S, ) be a grammar
A string α produces ω, or α reduces to ω, or ω is a
derivation of α, written α + ω, if there are
strings 1, …, n (n≥1) such that:
α 1 2 … n-1 n ω
We go from α to ω using several rules
Example of Derivation
1.
2.
3.
4.
5.
E V | I | (E + E) | (E * E)
V L | VL | VD
I D | ID
D0|1|2|3|4|5|6|7|8|9
L x | y |z
( ( z * ( x + y ) ) + 12 ) ?
E(E+E)((E*E)+E)((E*(E+E))+E)((V*(V+V))+I)
( ( L * ( L + L ) ) + ID ) ( ( z * ( x + y ) ) + DD ) ( ( z * ( x + y ) ) + 12 )
How about:
(x+2)
( 21 * ( x4 + 7 ) )
3*z
2y
Grammar-generated Language
• If G is a grammar with start symbol S, a
sentential form is any derivative of S
• A language L generated by a grammar G is
the set of all sentential forms whose
symbols are all terminals:
L(G) = { | S + and VT*}
Example of Language
• Let G = (VN, VT, S, ), where:
VN = {I, L, D}
VT = {a, b, …, z, 0, 1, …, 9}
S=I
= { I L | ID | IL
La|b|…|z
D0|1|…|9 }
I ID
IDD
ILDD
ILLDD
LLLDD
aLLDD
abLDD
abcDD
abc1D
abc12
• L(G) = {abc12, x, m934897773645, a1b2c3, …}
Syntax Analysis: Parsing
• The parse of a sentence is the construction of a
derivation for that sentence
• The parsing of a sentence results in
– acceptance or rejection
– and, if acceptance, then also a parse tree
• We are looking for an algorithm to parse a
sentence (i.e., to parse a program) and produce
a parse tree
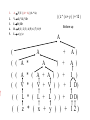
Parse Trees
• A parse tree is composed of
– interior nodes representing elements of VN
– leaf nodes representing elements of VT
• For each interior node N, the transition from
N to its children represents the application
of one production rule
Parse Tree Construction
• Top-down
– Start with the root (start symbol)
– Proceed downward to leaves using productions
• Bottom-up
– Start from leaves
– Proceed upward to the root
• Although these seem like reasonable approaches to
develop a parsing algorithm, we’ll see later that
neither is ideal we’ll find a better way!
1.
2.
3.
4.
5.
A V | I | (A + A) | (A * A)
V L | VL | VD
I D | ID
D0|1|2|3|4|5|6|7|8|9
L x | y |z
(
( ( A *
( ( z * ( x + y ) ) + 12 )
Top down
A
A
A
+
) +
A)
A)
( ( A * ( A + A ) ) +
( ( V * ( V + V ) ) +
I)
ID)
( ( L * ( L + L ) ) +
DD)
( ( z * ( x + y ) ) + 12)
1.
2.
3.
4.
5.
A V | I | (A + A) | (A * A)
V L | VL | VD
I D | ID
D0|1|2|3|4|5|6|7|8|9
L x | y |z
(
( ( A *
( ( z * ( x + y ) ) + 12 )
Bottom up
A
A
A
+
) +
A )
A )
( ( A * ( A + A ) ) + I )
( ( V * ( V + V ) ) + I D)
( ( L * ( L + L ) ) +
D D)
( ( z * ( x + y ) ) + 12)
Lexical Analyzer and Parser
• Lexical analyzers
– Input: symbols of length 1
– Output: classified tokens
• Parsers
– Input: classified tokens
– Output: parse tree (i.e., syntactically correct
program)
A syntactically correct program will run. Will it do what you want?
[a monkey ate a banana / a banana climbs the tree]
Backus-Naur Form (BNF)
• A traditional meta-language to represent
grammars for programming languages
– Every non-terminal is enclosed in < and >
– Instead of the symbol , we use ::=
• Example
I L | ID | IL
La|b|…|z
D0|1|…|9
<I> ::= <L> | <I><D> | <I><L>
<L> ::= a | b | … | z
<D> ::= 0 | 1 | … | 9
WHY?