Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Reducing Leakage Power in Peripheral
Circuits of L2 Caches
Houman Homayoun and Alex Veidenbaum
Dept. of Computer Science, UC Irvine
{hhomayou, alexv}@ics.uci.edu
ICCD 2007
L2 Caches and Power
L2 caches in high-performance processors are large
2 to 4 MB is common
They are typically accessed relatively infrequently
Thus L2 cache dissipates most of its power via leakage
Much of it was in the SRAM cells
Many architectural techniques proposed to remedy this
Today, there is also significant leakage in the
peripheral circuits of an SRAM (cache)
In part because cell design has been optimized
The problem
How to reduce power dissipation in the peripheral
circuits of the L2 cache?
Seek an architectural solution with a circuit assist
Approach:
Reduce peripheral leakage when circuits are unused
Use architectural techniques to minimize “wakeup” time
By applying “sleep transistor” techniques
During an L2 miss service, for instance
Will assume that an SRAM cell design is already
optimized and will attempt to save power in cells
Miss rates and load frequencies
ammp
applu
apsi
art
bzip2
crafty
eon
equake
facerec
galgel
gap
gcc
gzip
DL1
DL1
miss L2miss %
miss L2
%
rate rate loads
rate miss rate loads
0.046 0.1872 0.22 lucas 0.0970.6657 0.15
0.056 0.6572 0.26 mcf 0.2390.4284 0.34
0.027 0.2778 0.22 mesa 0.0030.2674 0.26
0.414 0.0001 0.17 mgrid 0.0360.4587 0.30
0.017 0.0417 0.24 parser 0.0200.0688 0.22
0.002 0.0087 0.28 perlbmk 0.0050.4576 0.31
0.000 1
0.26 sixtrack 0.0120.0012 0.22
0.017 0.6727 0.25 swim 0.0890.6308 0.21
0.034 0.3121 0.21 twolf 0.0540.0003
0.054 0.0003 0.23
0.037 0.0057 0.22 vortex 0.0030.2314 0.24
0.007 0.5506 0.21 vpr
0.0230.1476 0.30
0.046 0.0367 0.21 wupwise0.0120.674 0.17
0.007 0.0468 0.20 Average 0.0520.3131680.24
SPEC2K benchmarks
128KB L1 cache
5% average L1 miss rate,
Loads are 25% of instr.
In many benchmarks the
L2 is mostly idle
In some L1 miss rate is
high
Much waiting for data
L2 and CPU idle?
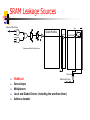
SRAM Leakage Sources
Addr Input Global Drivers
Bitline
addr0
Global Wordline
addr1
Decoder
Local Wordline
addr2
addr3
Predecoder and Global Wordline Drivers
addr
Sense amp
SRAM cell
Global Output Drivers
Sense Amps
Multiplexers
Local and Global Drivers (including the wordline driver)
Address decoder
Bitline
Leakage Energy Break Down in L2 Cache
Large, more leaky transistors used in peripheral circuits
High Vth, less leaky transistors in memory cells
global
address
input drivers
14%
global data
output
drivers
24%
global data
input drivers
25%
local data
output
drivers
20%
others
9%
local row
decoders
1%
global row
predecoder
7%
Circuit Techniques for Leakage Reduction
Gated-Vdd, Gated-Vss
Voltage Scaling (DVFS)
ABB-MTCMOS
Forward Body Biasing (FBB), RBB
Typically target cache SRAM cell design
But are also applicable to peripheral circuits
Architectural Techniques
Way Prediction, Way Caching, Phased Access
Drowsy Cache
Evict lines not used for a while, then power them down
Applying DVS, Gated Vdd, Gated Vss to memory cell
Keeps cache lines in low-power state, w/ data retention
Cache Decay
Predict or cache recently access ways, read tag first
Many architectural support to do that.
All target cache SRAM memory cell
What else can be done?
Architectural Motivation:
A load miss in the L2 cache takes a long time to service
prevents dependent instructions from being issued
dispatch
issue
When dependent instructions cannot issue
After a number of cycles the instruction window is full
ROB, Instruction Queue, Store Queue
The processor issue stalls and performance is lost
At the same time, energy is lost as well!
This is an opportunity to save energy
IPC during an L2 miss
Cumulative over the L2 miss service time for a program
Decreases significantly compared to program average
Issue Rate
3.25
sixtrack
3
mesa
crafty
galgel
eon
vortex
2.75
bzip2
2.5
average issue rate during cache miss period
gzip
2.25
program average issue rate
apsi
facerec
gcc
2
1.75
Average
parser
art
twolf
gap
wupwise
perlbmk
1.5
vpr
1.25
equake
applu
1
mgrid
ammp
0.75
lucas
apsi
0.5
galgel
bzip2
applu
0.25
crafty
0
vortex
vpr
mgrid
gcc
mcf
equake
gap
ammp
sixtrack
gzip
facerec
art
eon
swim
mesa
swim
parser
lucas
mcf
twolf
perlbmk
Average
wupwise
A New Technique
Idle time Management (IM)
Assert an L2 sleep signal (SLP) after an L2 cache miss
Puts L2 peripheral circuits into a low-power state
L2 cannot be accessed while in this state
De-assert SLP when the cache miss completes
Can also apply to the CPU
Use SLP for DVFS, for instance
But L2 idle time is only 200 to 300 clocks
It currently takes longer than that for DVFS
A Problem
• Disabling the L2 as soon as the miss is detected
• Prevents the issue of independent instructions
• In particular, of loads that may hit or miss in the L2
• This may impact the performance significantly
• Up to a 50% performance loss
Percentage (%)
60
lucas
50
mcf
40
applu
swim
30
mgrid
20
apsi
equake
vpr
10
Average
perlbmk
0
ammp
art
bzip2
crafty
eon
facerec
gap
galgel
gcc gzip
mesa
parser
twolf
sixtrack
wupwise
vortex
What are independent instructions?
Independent instructions do not depend on a load miss
Or any other miss occuring during the L2 miss service
Independent instructions can execute during miss service
Logarithmic Percentages (log %)
100
swim
mcf
applu
lucas
equake
facerec
gap
10
apsi
1
ammp
mgrid
wupwise
vpr
gcc
bzip2
perlbmk
mesa
parser
vortex
gzip
galgel
0.1
crafty
0.01
0.001
sixtrack
twolf
art
eon
Average
Two Idle Mode Algorithms
Static algorithm (SA)
put L2 in stand-by mode N cycles after a cache miss occurs
enable it again M cycles before the miss is expected to compete
Independent instructions execute during the L2 miss service
L2 can be accesses during the N+M cycles
L1 misses are buffered in an L2 buffer during stand-by
Adaptive algorithm (AA)
Monitor the issue logic and functional units of the processor
after an L2 miss
Put the L2 into stand-by mode if no instructions are issued AND
functional units have not executed any instructions in K cycles
The algorithm attempts to detect that there are no more instructions that
may access the L2
A Second Leakage Reduction Technique
Sometimes the L2 is not accessed much and is mostly idle
In this case it is best to use the Stand-By Mode (SM)
Start the L2 cache in stand-by, low-power mode
“Wake it up” on an L1 cache miss and service the miss
Return the L2 to stand-by mode right after the L2 access
However, this is likely to lead to performance loss
L1 misses are often clustered, there is a wake-up delay…
A better solution:
Keep the L2 awake for J cycles after it was turned on
increases energy consumption, but improves performance
Hardware Support
Add appropriately sized sleep
transistors in global drivers
Add delayed-access buffer to L2
allows L1 misses to be issued and
stored in this buffer at L2
L2 Cache
Write Buffer
Pre-decoder
Cell Array
Read Buffer
Access L2 when it get
enabled
SLP
Delayed- Access Buffer
10 entries(10*8bits)
assert SLP signal, insert
forthcoming Loads and
stores into Delayed
Access Buffer
System Description
L1 I-cache
128KB, 64 byte/line, 2 cycles
L1 D-cache
128KB, 64 byte/line, 2 cycles, 2 R/W ports
L2 cache
4MB, 8 way, 64 byte/line, 20 cycles
issue
4 way out of order
Branch predictor
64KB entry g-share,4K-entry BTB
Reorder buffer
96 entry
Instruction queue
64 entry (32 INT and 32 FP)
Register file
128 integer and 128 floating point
Load/store queue
32 entry load and 32 entry store
Arithmetic unit
4 integer, 4 floating point units
Complex unit
2 INT, 2 FP multiply/divide units
Pipeline
15 cycles (some stages are multi-cycles)
Performance Evaluation
% Time L2 Turned ON
IPC Degradation
100%
8%
90%
7%
80%
6%
70%
5%
60%
50%
INT
4%
INT
FP
40%
FP
3%
30%
2%
20%
1%
10%
0%
0%
SM_200
SM_500
SM_750
SM_1000
SM_1500
IM/SA
IM/AA
Fraction of total execution time
L2 cache was active using IM & SM
SM_200
SM_500
SM_750
SM_1000
SM_1500
IM/SA
IM/AA
IPC loss due to L2 not being
accessible under IM & SM
p2
m
cf
es
a
m
A
ve
w vpr
up
w
is
e
s
pe er
rlb
m
si k
xt
ra
ck
sw
im
tw
ol
f
vo
rt
ex
pa
r
gr
id
p
cf
es
a
m
m
A
ve
w vpr
up
w
is
e
s
pe er
rlb
m
si k
xt
ra
ck
sw
im
tw
ol
f
vo
rt
ex
pa
r
gr
id
m
p
as
lu
c
gz
i
gc
c
bz
ip
2
cr
af
ty
eo
eq n
ua
k
fa e
ce
re
c
ga
lg
el
ga
p
ar
t
ap
pl
u
ap
si
m
am
100%
m
p
as
lu
c
gz
i
gc
c
eq
ua
k
fa e
ce
re
c
ga
lg
el
ga
p
eo
n
af
ty
cr
bz
i
ar
t
ap
pl
u
ap
si
p
m
am
p2
cf
es
a
ve
A
w vpr
up
w
is
e
s
pe er
rlb
m
si k
xt
ra
ck
sw
im
tw
ol
f
vo
rt
ex
pa
r
gr
id
m
m
p
as
m
lu
c
gz
i
gc
c
eo
eq n
ua
k
fa e
ce
re
c
ga
lg
el
ga
p
af
ty
cr
bz
i
i
ar
t
ap
s
m
p
ap
pl
u
am
Power-Performance Trade Off
100%
Leakage Power Savings
80%
(a)
60%
40%
20%
IM/SA
IM/AA
SM
0%
Total Energy-Delay Reduction
80%
(b)
60%
40%
IM/SA
IM/AA
SM
20%
%
20%
Performance Degradation
16%
(c)
12%
8%
IM/SA
IM/AA
SM
4%
%
(IM): 18 to 22% leakage power reduction with 1% performance loss
(SM) : 25% leakage power reduction with 2% performance loss
Conclusions
Study break down of leakage in L2 cache components, show
peripheral circuit leaking considerably.
Architectural techniques address reducing leakage in memory
cell.
Present an architectural study on what is happening after an L2
cache miss occurred.
Present two architectural techniques to reduce leakage in the L2
peripheral circuits; IM and SM. (IM) achieves 18 or 22% average
leakage power reduction, with a 1% average IPC reduction. (SM)
achieves a 25% average savings with a 2% average IPC reduction.
two techniques benefit different benchmarks, indicates a possibility
adaptively selecting the best technique. This is subject of our ongoing
research