Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Reconfigurable Architectures
Andrea Lodi
ARCES University of Bologna
SoC trends
• Increasing mask cost (~ 3M$)
• Increasing design complexity
• Increasing design time (~ 3M$)
• Rapidly changing communication standards
• Low-power design in wireless environment
• Increasing algorithmic complexity
requirements
ARCES University of Bologna
Product life cycle
sales
Growth
Maturity
Decrease
LOSS
time
ARCES University of Bologna
Trends in wireless systems
• Increased on-chip Transistor
density
• Increased design complexity
Algorithm
complexity
Moore’s law
400
Millions of
transistors/Chip
300
200
Technology
(nm)
100
0
1997 1999 2001 2003 2005 2007 2009
• Demand for reusability and
flexibility
ARCES University of Bologna
1997 1999 2001 2003 2005 2007 2009
Battery
capacity
• Increased Algorithmic
complexity
• Low battery capacity growth
• Demand for high performance
and energy efficiency
Digital architecture design space
ARCES University of Bologna
Parallelism in computation
•
•
•
•
Thread level parallelism
Instruction level parallelism (ILP)
Pipeline (loop level)
Fine-grain parallelism (bit/byte-level)
ARCES University of Bologna
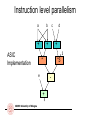
Instruction level parallelism
a
b
+
+
d
+
3
ASIC
Implementation
*
e
*3
*
-
+
ARCES University of Bologna
c
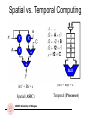
Spatial vs. Temporal Computing
Ax2 + Bx + c
(Ax + B)x + C
Spatial (ASIC)
Temporal (Processor)
ARCES University of Bologna
Superscalar/VLIW processors
• FU limitations
• Register file size limitation
• Crossbar inefficiency
ARCES University of Bologna
Byte-level parallelism in processors
• MMX technology: 57 new instructions
• Byte and half word parallel computation
• SIMD execution model
ARCES University of Bologna
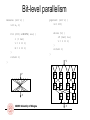
Bit-level parallelism
Reverse (int v) {
int x, r;
for (c=0; x<WIDTH; x++) {
r |= v&1;
v = v >> 1;
R = r << 1;
}
return r;
}
v
r
ARCES University of Bologna
popcount (int v) {
int r=0;
while (v) {
if (v&1) r++;
v = v >> 1;
}
return r;
}
v
+ + + +
+ + + +
+ + +
r
Pipeline parallelism
v
for (j=0; j<MAX; j++)
b[j] = popcount[a[j]];
= register
+ +
+ +
+ +
+ +
+
+ +
r
ARCES University of Bologna
FPGA
FPGA (Field-Programmable Gate Array) composed of 2 elements:
• Array of clbs (configurable logic blocks) composed of :
– 1 or few small size LUTs (4:1 or 3:1)
– Control logic: mux controlled by configuration bits
– Dedicated computational logic (carry chain …)
• Configurable routing network connecting clbs composed of:
– Different length wires
– Connection blocks connecting clbs to the routing network
– Switch blocks connecting routing wires
LUTs, configuration bits to program clbs and the routing network
represent the FPGA configuration, which determines the function
implemented
ARCES University of Bologna
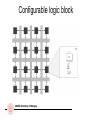
Configurable logic block
ARCES University of Bologna
Xilinx Clb
• Xilinx clb 4000 series:
–
–
–
–
ARCES University of Bologna
11 input 4 output bits
3 LUTs
Carry logic
2 output registers
Configurable routing network
ARCES University of Bologna
Example
ARCES University of Bologna
Density Comparison
ARCES University of Bologna
FPGA vs. Processor
FPGA
Processor
(computing in space)
• Parallel execution
• Configurable in 102-103 cycles
• Fine-grained data
• Application specific operators
• Large area (switches, SRAM)
• Entire applications don’t fit
• Slow synthesis, P&R tools
(computing in time)
• Sequential execution
• Programmable every cycle
• Fixed-size operands
• Basic operators (ALU)
• Compact
• Handles complex control flow
• Fast compilers
ARCES University of Bologna
Reconfigurable processors
But:
• 90% execution time spent in computational kernels:
– FPGAs 10-100x speed-up over processors
– FPGAs 10-100x denser than processors (bit-ops/2s)
• Reconfigurable processor: Risc + FPGA
ARCES University of Bologna
Reconfigurable processor architecture
• Hybrid architectures:
– RISC processor
– FPGA
ARCES University of Bologna
Computational models
• RC Array: IO Processor/Interface logic
• Attached processor
– Piperench, T-Recs
• ISA Extension
– Function unit:
• PRISC, OneChip, Chimaera
– Coprocessor
• Garp, NAPA, Molen
ARCES University of Bologna
IO Processor/Interface Logic
• Logic used in place of
– ASIC environment
customization
– external FPGA/PLD
devices
• Looks like IO peripheral
to processor
• Example
– protocol handling
– stream computation
• compression, encrypt
– peripherals
– sensors, actuators
ARCES University of Bologna
• Case for:
– Always have some system
adaptation to do
– Modern chips have
capacity to hold processor
+ glue logic
– reduce part count
– Glue logic vary
– many protocols, services
– only need few at a time
Example: Interface/Peripherals
• Triscend E5
ARCES University of Bologna
Instruction Set Extension
• Instruction Bandwidth
– Processor can only describe a small number of basic
computations in a cycle
• I bits 2I operations
– This is a small fraction of the operations one could do even
in terms of www Ops
• w22(2w) operations
– Processor could have to issue w2(2 (2w) -I) operations just to
describe some computations
– An a priori selected base set of functions could be very bad
for some applications
ARCES University of Bologna
Instruction Set Extension
• Idea:
– provide a way to augment the processor’s
instruction set
– with operations needed by a particular
application
ARCES University of Bologna
Architectural Models for I.S.A extension
XTENSA
PLEIADES
Good performance
Easy to program
Configured at
mask-level
High performance
Overdesigned for
most applications
Difficult to program
Cpu surrounded by a collection of
Application-specific Custom
Computing Devices
Zhang et al, 2000
ARCES University of Bologna
Risc CPU featuring application-specific
function units optionally inserted in the
processor pipeline
Tensilica inc, 2002
Dynamic ISA Extension models
Standard processor coupled with embedded programmable
logic where application specific functions are dynamically
re-mapped depending on the performed algorithm
1: Coprocessor model
ARCES University of Bologna
2: Function unit model
Coprocessor model: Garp
Explicit instructions moving
data to and from the array
High communication overhead
(long latency array operations)
Processor stalled each time the
array is active
Array performs at TASK level
(Very coarse grain)
10-20x on stream, feed-forward
operations
2-3x when data-dependencies
limit pipelining
ARCES University of Bologna
Callahan, Hauser, Wawrzynek, 2000
Function unit model: Prisc
Array fit in the risc pipeline
No communication overhead
Some degree of parallelism between
function units
Gate array performs combinatorial
instructions ONLY (very fine grain)
Low speedup figures (2x/3x)
Razdan, Smith 1994
ARCES University of Bologna
Function Unit Model: pros
• No communication overhead:
– Strict synergy between FPGA and other function units
– FPGA can be used frequently even for small functions
– Small reconfigurable array area
• Flow control handled by the core
• Memory access handled by the core
• Easy instruction set extension
• Configuration streams compiled from C
ARCES University of Bologna
EXTENDIBLE INSTRUCTION SET RISC ARCHITECTURE
32-bit load/store Risc architecture (5 stages pipeline)
Set of specialized functional units
•Multiply/Mac Unit
VLIW•Branch/Decrement
Elaboration
Unit
•Alu featuring
“MMX”
byte-wide of
concurrent
•Concurrent
fetch
and execution
two 32-bitoperations
instructions per cycle
Embedded
reconfigurable
dynamic ISA extension
•Fully bypassed,
to minimizedevice
pipelinefor
stalls
(Average of 10/20% for most computational cores)
•DSP-oriented reconfigurable functional unit (PiCoGA)
•Fully configurable at execution time
•Elaboration and configuration controlled by asm instructions inserted in
C source code
•PiCoGA used as a programmable Data-path with independent pipeline
structure
ARCES University of Bologna
XiRisc Architecture
ARCES University of Bologna
Dynamic Instruction Set Extension
ARCES University of Bologna
Dynamic Instruction Set Extension
Register File
Configuration
Memory
ARCES University of Bologna
…..
pgaload
…..
…..
…..
pgaop $3,$4,$5
…...
…...
Add $8, $3
PiCoGA Architecture
ARCES University of Bologna
Processor Interface
PiCoGA Control Unit
PiCoGA
(Pipelined Configurable Gate Array):
Embedded datapath
for dynamic i.s.a. extension
•Dynamically reconfigurable
•Structured in rows activated in dataflow fashion by the PiCoGA control
unit
• Can hold a state
• pGA-op latency depends on the
specific mapped function
• Functionality is determined from
DFG extracted from C code
PicoRow
(Synchronous Element)
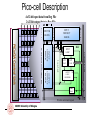
Pico-cell Description
4x32-bit input data from Reg File
2x32-bit output data to Reg File
INPUT
CONNECT
BLOCK
…
SWITCH
BLOCK
…
…
…
OUTPUT
CONNECT
BLOCK
…
LUT
16x2
LUT
16x2
OUTPUT
LOGIC,
REGISTERS
EN
CARRY
CHAIN
PiCoGA control unit signals
ARCES University of Bologna
Configuration bus
…
RLC
INPUT
LOGIC
Loop-back
INPUT
CONNECT
BLOCK
12 global lines to/from Reg File
PiCoGA Control Unit
…
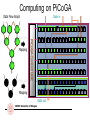
Computing on PiCoGA
Data Flow Graph
Mapping
Pga_op2
PiCoGA Control Unit
Pga_op1
Data in
Mapping
Data out
ARCES University of Bologna
Multi-context Array
PiCoGA
Configuration Cache
Func. 1
Func. 2
Func. 3
Func. 4
Func. n
While a plane is executing another may
Four
configuration
planes
are
available,
be reconfigured
No reconfiguration
Plane switch →
takes
just 1 clock cycle
onetime
of them
executing
overhead
ARCES University of Bologna
Architecture Flexibility
Parallelism to exploit ?
Yes
(Ex: Turbo Decod., Motion Est.)
No
Yes
Bit-level operations ?
(Ex: DES, Reed-Solomon)
No
Memory intensive ?
pGA (5x – 100x)
Yes
MAC intensive ?
(Ex: FFT, Scalar product)
No
Speed-up from
Yes
Speed-up from DSP
instructions and VLIW
(1.5x – 2x)
(Ex: DCT, Motion Est.)
Improvements for a large number of
Data & Signal Processing algorithms
ARCES University of Bologna
Programming XiRisc: Restrictions
• Fixed-point algorithms
• Variable size specification at the bit level
Not supported yet:
• Dynamic memory allocation
• Math library
• Operating System
ARCES University of Bologna
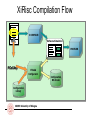
XiRisc Compilation Flow
C COMPILER
Software Simulation
File.c
PROFILER
PiCoGAop
PiCoGA
Configurator
Configuration
Library
ARCES University of Bologna
Configuration
Bit stream
Example: Motion Estimation
Sum of Absolute
Difference
(SAD)
High instruction-level
and inter-iteration
parallelism
ARCES University of Bologna
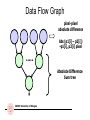
Data Flow Graph
pixel-pixel
absolute difference
Abs (p1[i] – p2[i])
•p1[i], p2[i] pixel
…..
Absolute Difference
Sum tree
ARCES University of Bologna
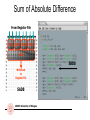
Sum of Absolute Difference
From Register File
AD1
AD2
AD3
AD4
SAD
SAD8
Writeback
to
Register File
SAD8
ARCES University of Bologna
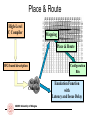
Place & Route
High-Level
C Compiler
Mapping
Place & Route
DFG-based description
Configuration
Bits
Griffy
Compiler
ARCES University of Bologna
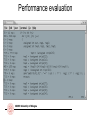
Emulation Function
with
Latency and Issue Delay
Performance evaluation
• Emulation function
• Latency and Issue-Delay back-annotation
• Profiling
ARCES University of Bologna
Motion Estimation: Results
Motion estimation:
• 16 SAD operations in parallel
• PiCoGA occupation: ~100%
• Speed-up: 7x (with respect to standard XiRisc)
MPEG preliminary result:
• H.261 standard QCIF (176x144): 10 frame/sec
ARCES University of Bologna
Reed-Solomon Encoder: Results
Encoder RS(15,9): 4-bit symbols
• PiCoGA occupation: ~25%
• Speed-up: 37x
• Throughput: 70.6 Mb/sec
Encoder RS(255,239) widely used: 8-bit symbols
• PiCoGA occupation: ~60%
• Speed-up: 135x
• Throughput: 187.1 Mb/sec
ARCES University of Bologna
Speed-up and Power Consumption
Energy consumption
reduction
(vs. std. XiRisc)
Speed-up
(vs. std. XiRisc)
DES encryption
89%
13.5x
Turbo decoder
75%
11.7x
Motion prediction
46%
4.5x
Median filter
60%
7.7x
CRC
49%
4.3x
Algorithm
ARCES University of Bologna